
Já falamos sobre o Tarantool Cartridge , que permite desenvolver aplicativos distribuídos e embalá-los. Tudo o que resta é aprender a implantar esses aplicativos e gerenciá-los. Não se preocupe, nós fornecemos tudo! Reunimos todas as melhores práticas para trabalhar com o Tarantool Cartridge e escrevemos uma função ansiosa que decompõe o pacote em servidores, lança as instâncias, combina-as em um cluster, configura a autorização, inicia o vshard, ativa o failover automático e corrige a configuração do cluster.
Interessante? Então eu peço um corte, vamos contar e mostrar tudo.
Vamos começar com um exemplo.
Consideraremos apenas parte da funcionalidade de nossa função. Você sempre pode encontrar uma descrição completa de todos os seus recursos e parâmetros de entrada na documentação . Mas é melhor tentar uma vez do que ver centenas de vezes, então vamos instalar um aplicativo pequeno.
O Tarantool Cartridge tem um tutorial sobre a criação de um pequeno aplicativo de cartucho que armazena informações sobre clientes bancários e suas contas e também fornece uma API para gerenciar dados por meio de HTTP. Para fazer isso, o aplicativo descreve duas funções possíveis: api e storage , que podem ser atribuídos às instâncias.
O cartucho em si não diz nada sobre como iniciar processos, apenas fornece a capacidade de configurar instâncias já em execução. O usuário deve fazer o resto: decompor os arquivos de configuração, iniciar os serviços e configurar a topologia. Mas não faremos tudo isso, Ansible fará isso por nós.
Observe que, se você estiver desenvolvendo seu aplicativo no OS X, empacotá-lo em uma máquina local e falhar na instalação no Centos ou Debian não funcionará, pois o pacote conterá módulos de rochas e arquivos executáveis específicos para o OS X. Nesse caso, será necessário faça embalagens no sistema de destino.
Das palavras às ações
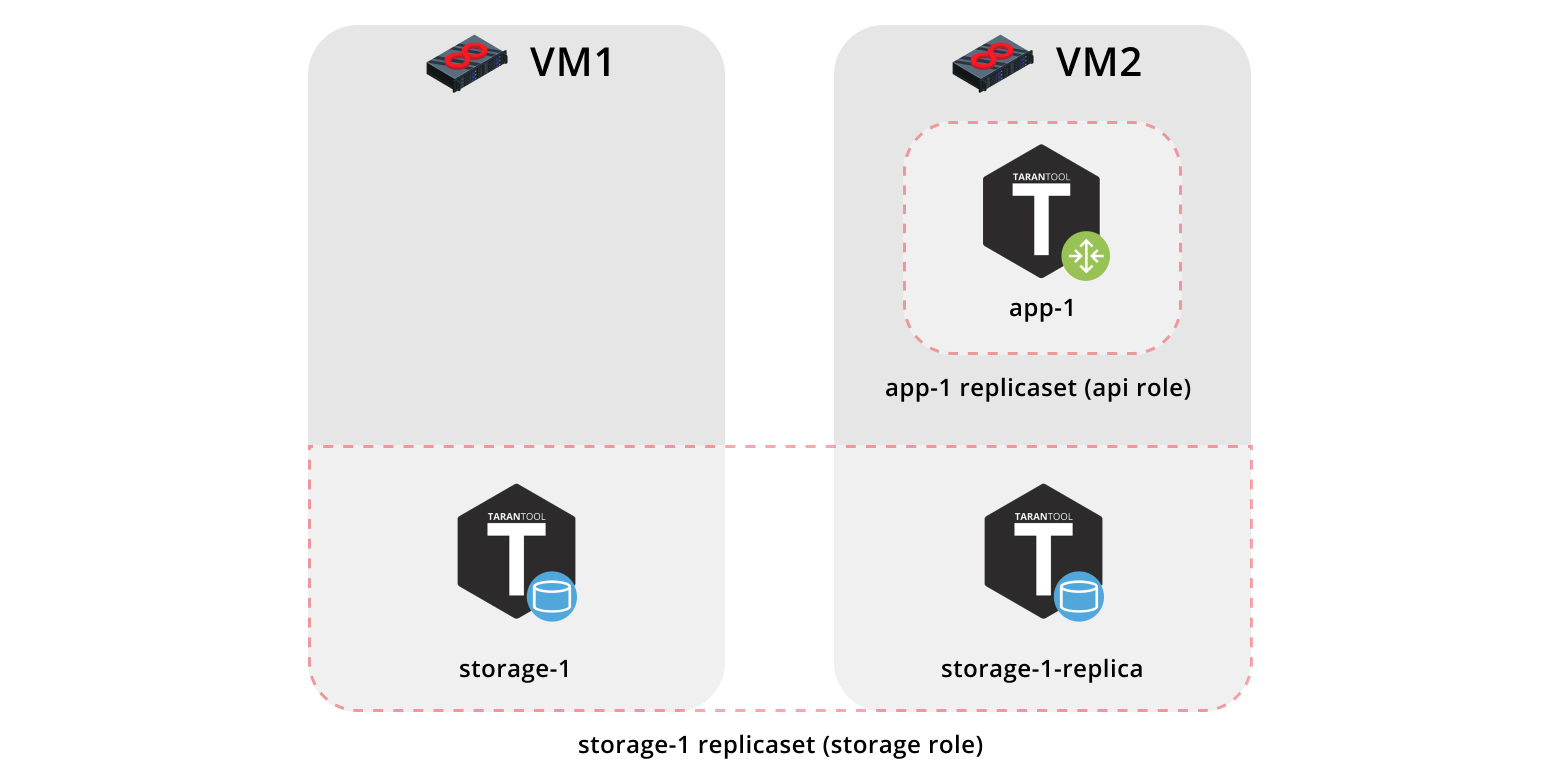
Então, vamos instalar nosso aplicativo em duas máquinas virtuais e configurar uma topologia simples:
- O replicaet
app-1 implementará a função api , que inclui a função vshard-router . Haverá apenas uma instância. - O replicaset
storage-1 implementa a função de storage (e ao mesmo tempo vshard-storage ), aqui adicionamos duas instâncias de máquinas diferentes.
Para executar o exemplo, precisamos do Vagrant e do Ansible (versão 2.8 ou posterior).
O papel em si é na Galáxia Ansible . Este é um repositório que permite compartilhar suas melhores práticas e usar funções prontas.
Clonamos o repositório com um exemplo:
$ git clone https://github.com/dokshina/deploy-tarantool-cartridge-app.git $ cd deploy-tarantool-cartridge-app && git checkout 1.0.0
Crie máquinas virtuais:
$ vagrant up
Instale a função de cartucho Tarantool:
$ ansible-galaxy install tarantool.cartridge,1.0.1
Execute a função instalada:
$ ansible-playbook -i hosts.yml playbook.yml
Estamos aguardando a conclusão do manual, vá para http: // localhost: 8181 / admin / cluster / dashboard e aproveite o resultado:
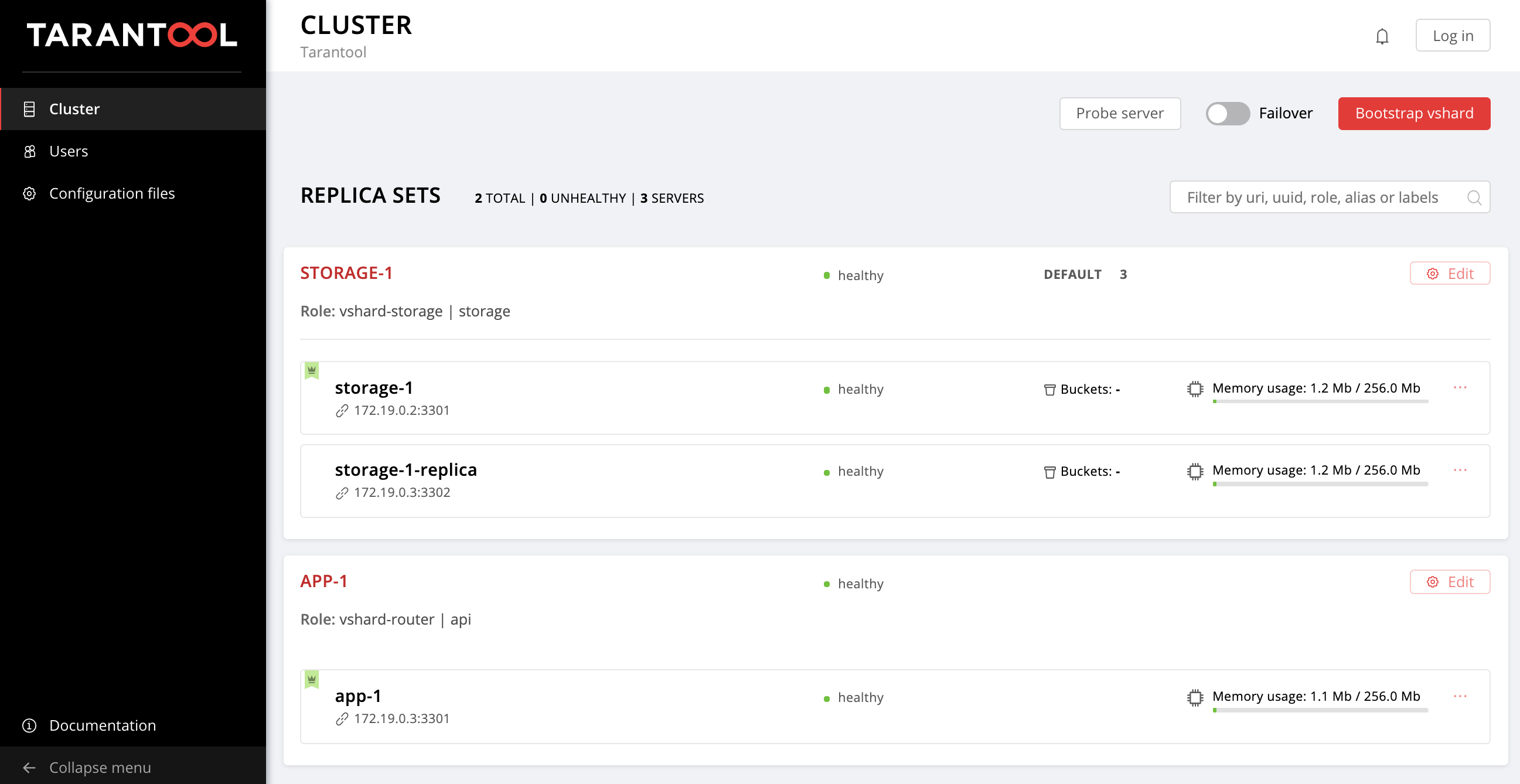
Você pode derramar dados. Legal, né?
Agora vamos descobrir como trabalhar com isso e, ao mesmo tempo, adicionar outra réplica definida à topologia.
Comece a entender
Então o que aconteceu?
Pegamos duas máquinas virtuais e lançamos o manual ansible que configurou nosso cluster. Vejamos o conteúdo do arquivo playbook.yml :
--- - name: Deploy my Tarantool Cartridge app hosts: all become: true become_user: root tasks: - name: Import Tarantool Cartridge role import_role: name: tarantool.cartridge
Nada de interessante acontece aqui, lançamos um papel tarantool.cartridge chamado tarantool.cartridge .
O mais importante (a configuração do cluster) está no arquivo de inventário hosts.yml :
--- all: vars: # common cluster variables cartridge_app_name: getting-started-app cartridge_package_path: ./getting-started-app-1.0.0-0.rpm # path to package cartridge_cluster_cookie: app-default-cookie # cluster cookie # common ssh options ansible_ssh_private_key_file: ~/.vagrant.d/insecure_private_key ansible_ssh_common_args: '-o IdentitiesOnly=yes -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no' # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 app-1: config: advertise_uri: '172.19.0.3:3301' http_port: 8182 storage-1-replica: config: advertise_uri: '172.19.0.3:3302' http_port: 8183 children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica: # GROUP INSTANCES BY REPLICA SETS replicaset_app_1: vars: # replica set configuration replicaset_alias: app-1 failover_priority: - app-1 # leader roles: - 'api' hosts: # replica set instances app-1: replicaset_storage_1: vars: # replica set configuration replicaset_alias: storage-1 weight: 3 failover_priority: - storage-1 # leader - storage-1-replica roles: - 'storage' hosts: # replica set instances storage-1: storage-1-replica:
Tudo o que precisamos fazer é aprender a gerenciar instâncias e replicasets modificando o conteúdo deste arquivo. Além disso, adicionaremos novas seções a ele. Para não ficar confuso sobre onde adicioná-los, você pode espiar a versão final deste arquivo, hosts.updated.yml , que está localizado no repositório com um exemplo.
Gerenciamento de instância
Em termos de Ansible, cada instância é um host (não deve ser confundido com um servidor de ferro), ou seja, Um nó de infraestrutura que o Ansible gerenciará. Para cada host, podemos especificar parâmetros de conexão (como ansible_host e ansible_user ), bem como a configuração da instância. A descrição das instâncias está na seção hosts .
Considere a configuração da instância de storage-1 :
all: vars: ... # INSTANCES hosts: storage-1: config: advertise_uri: '172.19.0.2:3301' http_port: 8181 ...
Na variável de config , especificamos os parâmetros da instância - advertise URI e HTTP port .
Abaixo estão os parâmetros da instância app-1 e storage-1-replica .
Precisamos fornecer parâmetros de conexão Ansible para cada instância. Parece lógico agrupar instâncias em grupos de máquinas virtuais. Para fazer isso, as instâncias são agrupadas nos host2 host1 e host2 e, em cada grupo na seção vars , os valores ansible_host e ansible_user para uma vars são indicados. E na seção hosts , há hosts (são instâncias) incluídos neste grupo:
all: vars: ... hosts: ... children: # GROUP INSTANCES BY MACHINES host1: vars: # first machine connection options ansible_host: 172.19.0.2 ansible_user: vagrant hosts: # instances to be started on the first machine storage-1: host2: vars: # second machine connection options ansible_host: 172.19.0.3 ansible_user: vagrant hosts: # instances to be started on the second machine app-1: storage-1-replica:
Começamos a mudar o hosts.yml . Adicione mais duas instâncias, storage-2-replica na primeira máquina virtual e storage-2 na segunda:
all: vars: ... # INSTANCES hosts: ... storage-2: # <== config: advertise_uri: '172.19.0.3:3303' http_port: 8184 storage-2-replica: # <== config: advertise_uri: '172.19.0.2:3302' http_port: 8185 children: # GROUP INSTANCES BY MACHINES host1: vars: ... hosts: # instances to be started on the first machine storage-1: storage-2-replica: # <== host2: vars: ... hosts: # instances to be started on the second machine app-1: storage-1-replica: storage-2: # <== ...
Execute o manual ansible:
$ ansible-playbook -i hosts.yml \ --limit storage-2,storage-2-replica \ playbook.yml
Preste atenção à opção --limit . Como cada instância do cluster é um host em termos de Ansible, podemos indicar explicitamente quais instâncias devem ser configuradas ao reproduzir um manual.
Novamente, acesse a interface do usuário da Web http: // localhost: 8181 / admin / cluster / dashboard e observe nossas novas instâncias:
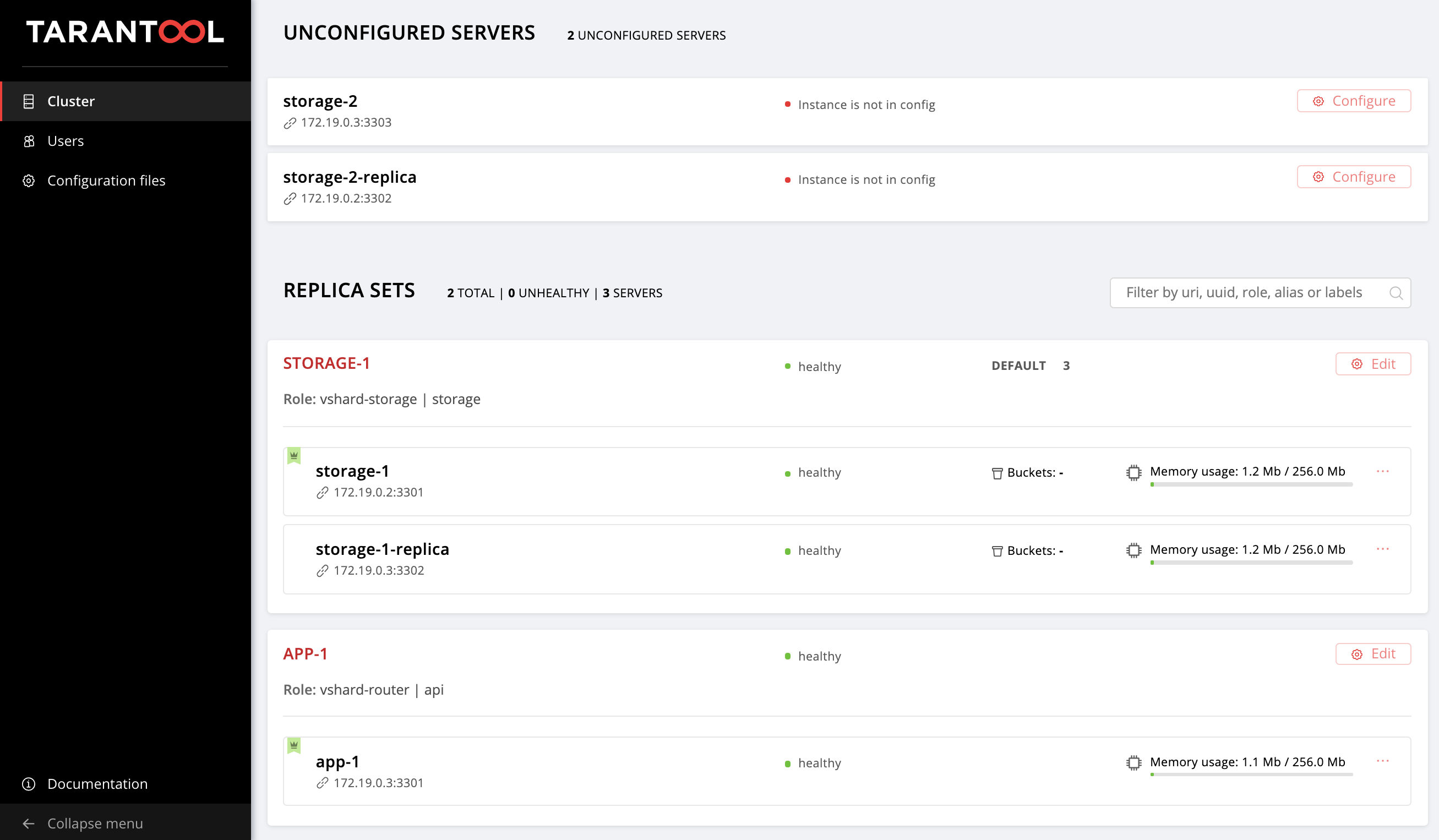
Não vamos nos debruçar sobre o que foi alcançado e dominar o gerenciamento da topologia.
Gerenciamento de topologia
Combine nossas novas instâncias no replicaset storage-2 . Adicione um novo grupo replicaset_storage_2 e descreva os parâmetros do replicaset em suas variáveis, semelhante a replicaset_storage_1 . Na seção hosts , indicamos quais instâncias serão incluídas neste grupo (ou seja, nosso conjunto de réplicas):
--- all: vars: ... hosts: ... children: ... # GROUP INSTANCES BY REPLICA SETS ... replicaset_storage_2: # <== vars: # replicaset configuration replicaset_alias: storage-2 weight: 2 failover_priority: - storage-2 - storage-2-replica roles: - 'storage' hosts: # replicaset instances storage-2: storage-2-replica:
Inicie o manual novamente:
$ ansible-playbook -i hosts.yml \ --limit replicaset_storage_2 \ --tags cartridge-replicasets \ playbook.yml
Dessa vez, passamos o nome do grupo que corresponde à nossa replicaset ao parâmetro --limit.
Considere a opção de tags .
Nossa função executa consistentemente várias tarefas, marcadas com as seguintes tags:
cartridge-instances : gerenciamento de instâncias (configuração, conexão com a associação);cartridge-replicasets : gerenciamento de topologia (gerenciamento de replicasets e exclusão permanente (expel) de instâncias do cluster);cartridge-config : gerenciamento dos parâmetros restantes do cluster (inicialização vshard, modo de failover automático, parâmetros de autorização e configuração do aplicativo).
Podemos indicar explicitamente que parte do trabalho queremos fazer, então a função pulará a execução das tarefas restantes. No nosso caso, queremos trabalhar apenas com a topologia, portanto, indicamos cartridge-replicasets .
Vamos avaliar o resultado de nossos esforços. Localize o novo conjunto de réplicas em http: // localhost: 8181 / admin / cluster / dashboard .
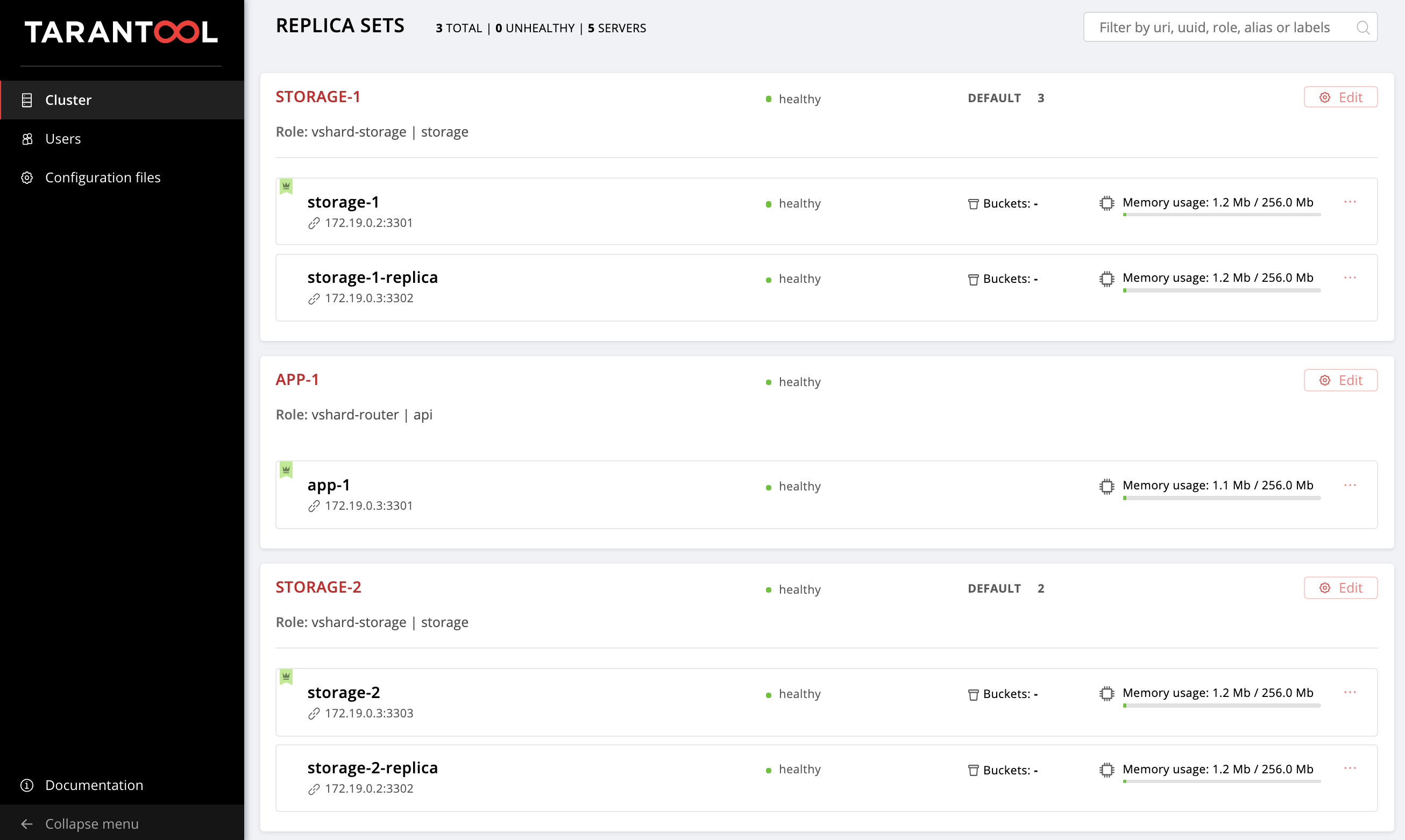
Viva!
Experimente alterar a configuração de instâncias e replicasets e veja como a topologia do cluster é alterada. Você pode experimentar vários cenários operacionais, por exemplo, atualização sem memtx_memory ou aumentar memtx_memory . A função tentará fazer isso sem reiniciar a instância para reduzir o possível tempo de inatividade do seu aplicativo.
Não se esqueça de iniciar a vagrant halt para parar vagrant halt quando terminar de trabalhar com elas.
E o que há sob o capô?
Aqui vou contar mais sobre o que aconteceu sob o capô do papel ansível durante nossas experiências.
Considere as etapas de implantação de um aplicativo de cartucho.
Instalando um Pacote e Iniciando Instâncias
Primeiro, você precisa entregar o pacote ao servidor e instalá-lo. Agora, a função pode trabalhar com pacotes RPM e DEB.
Em seguida, execute as instâncias. Tudo é muito simples aqui: cada instância é um serviço systemd separado. Eu digo com um exemplo:
$ systemctl start myapp@storage-1
Este comando iniciará a instância de storage-1 do myapp . A instância em execução procurará sua configuração em /etc/tarantool/conf.d/ . journald podem ser visualizados usando o journald .
O arquivo da unidade /etc/systemd/system/myapp@.sevice para o serviço systemd será entregue com o pacote.
O Ansible possui módulos internos para instalação de pacotes e gerenciamento de serviços systemd, aqui não inventamos nada de novo.
Configurar topologia de cluster
E aqui começa a diversão. Concordo, seria estranho se preocupar com uma função especial para instalar pacotes e executar o systemd services.
Você pode configurar o cluster manualmente:
- A primeira opção: abra a interface da Web e clique nos botões. Para um início único de várias instâncias, é bastante adequado.
- Segunda opção: você pode usar a API GraphQl. Aqui você já pode automatizar algo, por exemplo, escrever um script em Python.
- A terceira opção (para quem tem espírito forte): vamos ao servidor,
tarantoolctl connect a uma das instâncias usando tarantoolctl connect e executamos todas as manipulações necessárias com o módulo de cartridge Lua.
O principal objetivo de nossa invenção é fazer exatamente isso, a parte mais difícil do trabalho para você.
O Ansible permite que você escreva seu módulo e use-o em uma função. Nossa função usa esses módulos para gerenciar vários componentes de cluster.
Como isso funciona? Você descreve o estado desejado do cluster na configuração declarativa e a função alimenta sua seção de configuração na entrada de cada módulo. O módulo recebe o estado atual do cluster e o compara com o que veio. Em seguida, através do soquete de uma das instâncias, o código é iniciado, o que leva o cluster ao estado desejado.
Sumário
Hoje conversamos e mostramos como implantar seu aplicativo no Tarantool Cartridge e configurar uma topologia simples. Para isso, usamos o Ansible, uma ferramenta poderosa que é fácil de usar e permite configurar simultaneamente muitos nós de infraestrutura (no nosso caso, são instâncias de cluster).
Acima, descobrimos uma das muitas maneiras de descrever a configuração de cluster usando o Ansible. Depois de perceber que está pronto para seguir em frente, aprenda as práticas recomendadas para escrever playbooks. Você pode achar mais conveniente gerenciar a topologia com group_vars e host_vars .
Na próxima parte, aprenderemos como remover permanentemente (expulsar) instâncias da topologia, inicializar vshard, gerenciar o modo de failover automático, configurar a autorização e corrigir a configuração do cluster. Não pare por aí, continue estudando a documentação e experimente alterar os parâmetros do cluster.
Se algo não funcionar, informe- nos sobre o problema. Vamos destruir tudo rapidamente!