Olá pessoal! Meu nome é Alexey Skorobogaty, sou arquiteto de sistemas na Lamoda. Em fevereiro de 2019, falei no Go Meetup enquanto ainda estava na posição de líder da equipe Core. Hoje, quero apresentar uma transcrição do meu relatório, que você também pode ver.
Nossa equipe se chama Core por um motivo: a área de responsabilidade inclui tudo relacionado a pedidos na plataforma de comércio eletrônico. A equipe foi formada por desenvolvedores e especialistas em PHP em nosso processamento de pedidos, que na época era um único monólito. Estávamos envolvidos e continuamos a lidar com sua decomposição em microsserviços.

Um pedido em nosso sistema consiste em componentes relacionados: existe uma unidade de entrega e uma cesta, unidades de desconto e pagamento e, no final, existe um botão que envia o pedido a ser coletado no armazém. É nesse momento que começa o trabalho do sistema de processamento de pedidos, onde todos os dados do pedido serão validados e as informações agregadas.
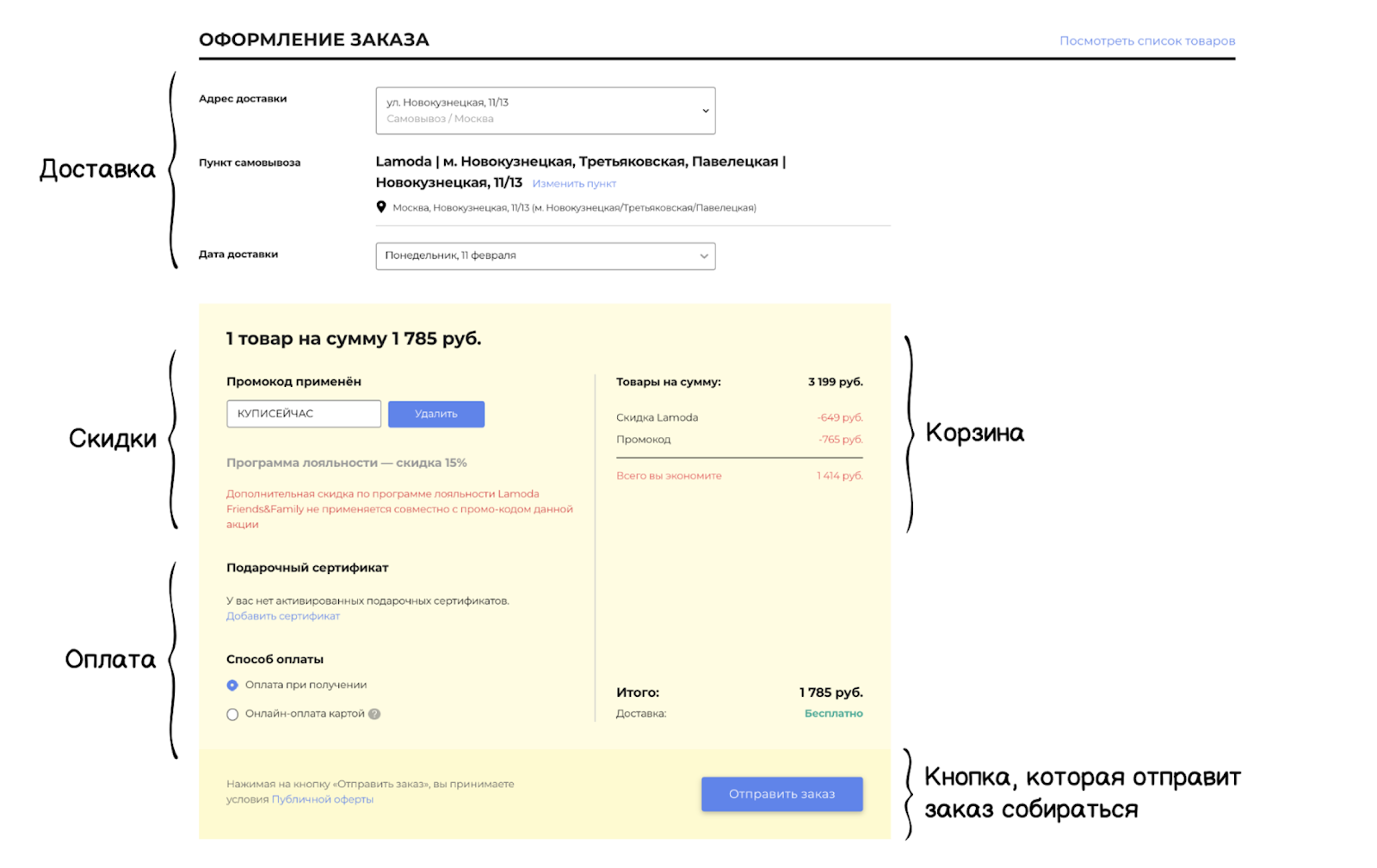
Dentro de tudo isso, está complexa lógica multicritério. Os blocos interagem entre si e se influenciam. Mudanças contínuas e constantes dos negócios aumentam a complexidade dos critérios. Além disso, temos diferentes plataformas através das quais os clientes podem criar pedidos: site, aplicativos, call center, plataforma B2B. Bem como critérios rigorosos de SLA / MTTI / MTTR (métricas de registro e resolução de incidentes). Tudo isso requer alta flexibilidade e estabilidade do serviço.
Patrimônio arquitetônico
Como eu já disse, no momento da formação de nossa equipe, o sistema de processamento de pedidos era um monólito - quase 100 mil linhas de código que descreviam diretamente a lógica de negócios. A parte principal foi escrita em 2011 usando a arquitetura MVC clássica de várias camadas. Foi baseado no PHP (framework ZF1), que foi gradualmente coberto de adaptadores e componentes symfony para interagir com vários serviços. Durante a sua existência, o sistema teve mais de 50 colaboradores e, embora tenhamos conseguido manter um estilo unificado de escrever código, isso também impôs suas limitações. Além disso, surgiu um grande número de contextos mistos - por várias razões, alguns mecanismos foram implementados no sistema que não estavam diretamente relacionados ao processamento de pedidos. Tudo isso levou ao fato de que, no momento, temos um banco de dados MySQL maior que 1 terabyte.
Esquematicamente, a arquitetura inicial pode ser representada da seguinte maneira:
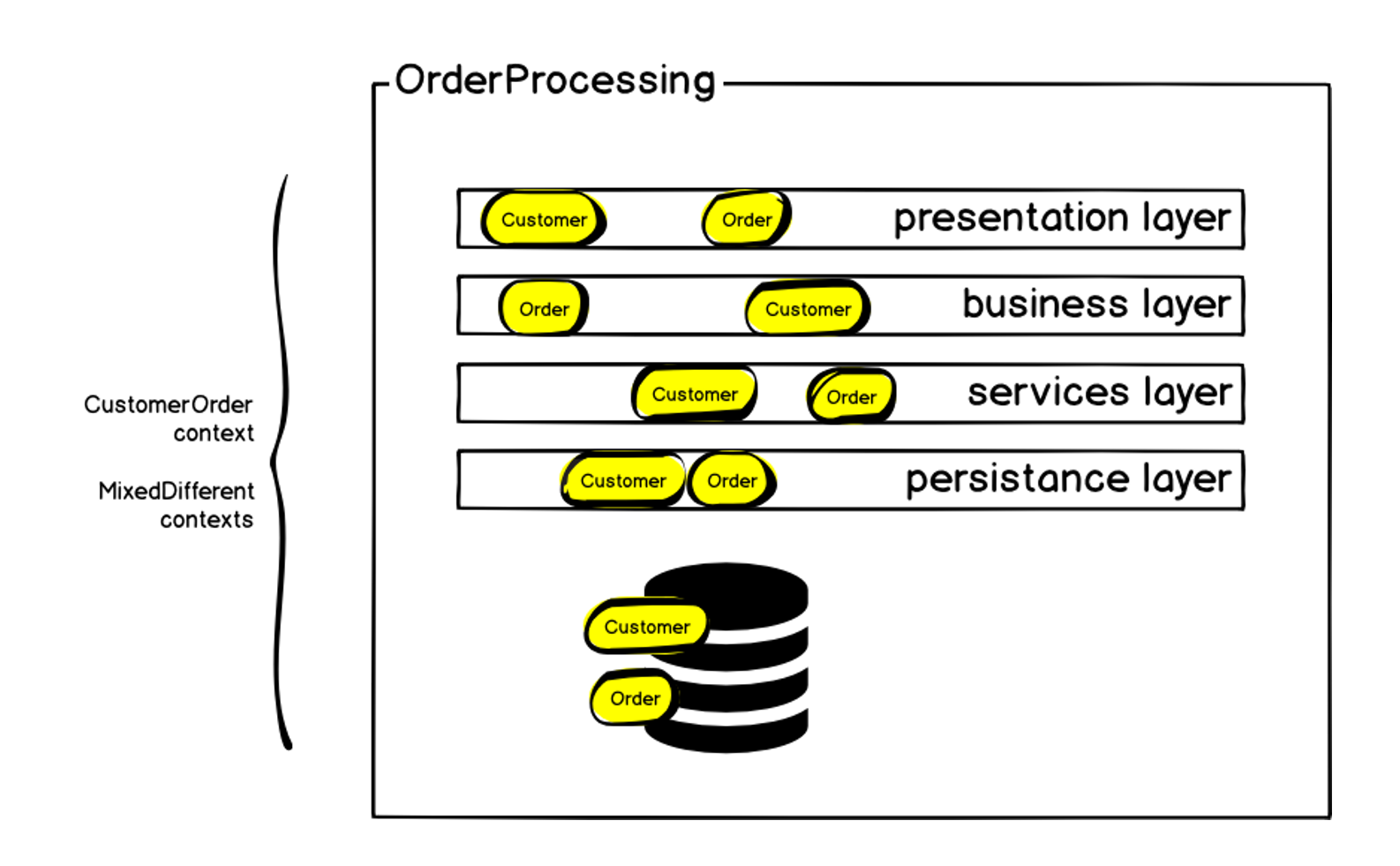
A ordem, é claro, estava em cada uma das camadas - mas, além da ordem, havia outros contextos. Começamos definindo o contexto delimitado do pedido e chamando-o de Pedido do Cliente, pois além do próprio pedido, existem os mesmos blocos que mencionei no início: entrega, pagamento, etc. Dentro do monólito, tudo isso era difícil de gerenciar: quaisquer alterações levavam a um aumento de dependências, o código era entregue ao produto por um período muito longo e a probabilidade de erros e falha do sistema aumentava o tempo todo. Mas estamos falando sobre a criação de um pedido, a principal métrica de uma loja online - se os pedidos não forem criados, o restante não será tão importante. A falha do sistema causa uma queda imediata nas vendas.
Portanto, decidimos transferir o contexto de Pedido do Cliente do sistema de Processamento de Pedidos para um microsserviço separado, chamado Gerenciamento de Pedidos.
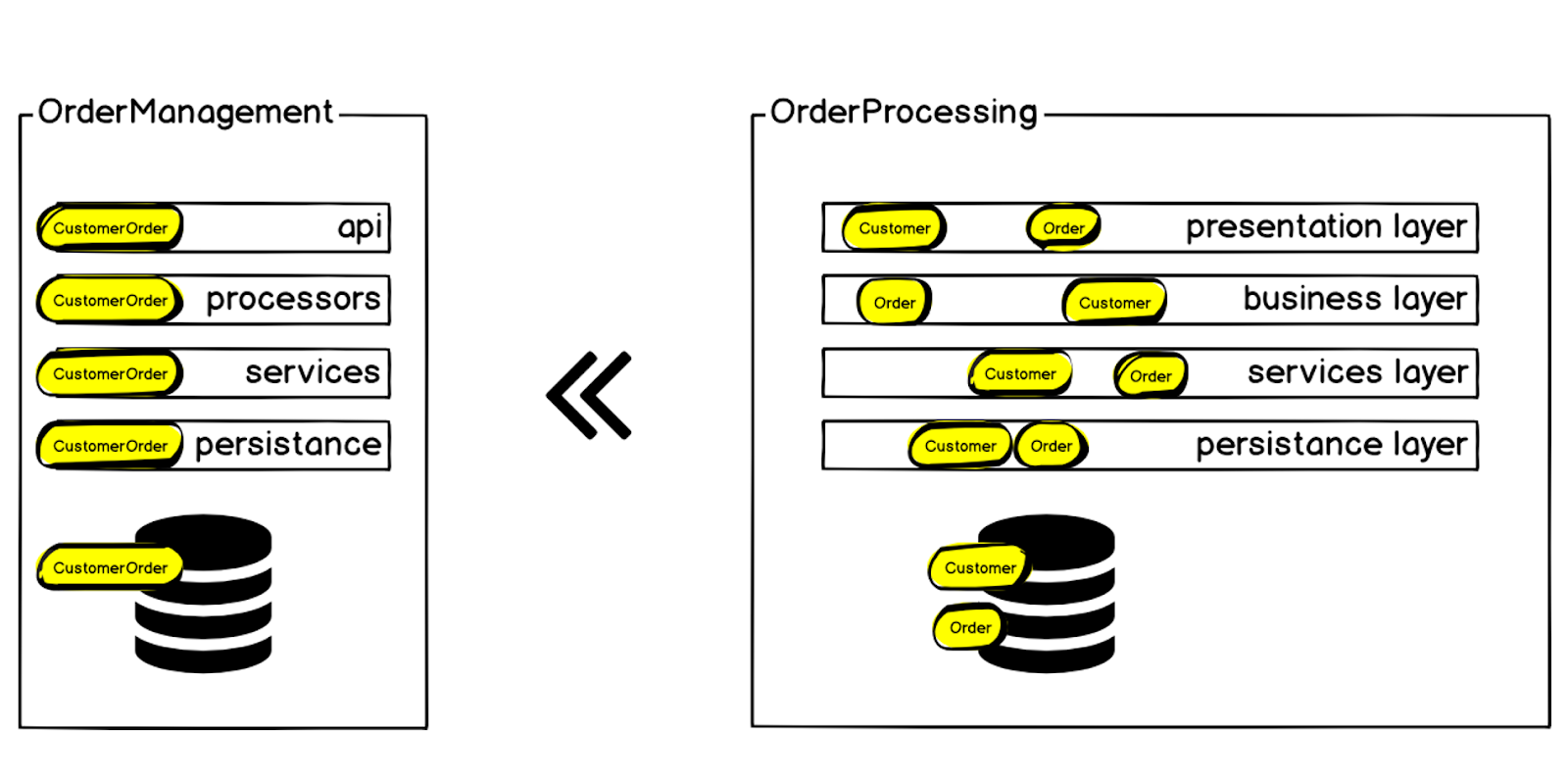
Requisitos e Ferramentas
Depois de determinar o contexto que decidimos remover do monólito, criamos os requisitos para o nosso serviço futuro:
- Desempenho
- Consistência dos dados
- Sustentabilidade
- Previsibilidade
- Transparência
- Incremento de mudança
Queríamos que o código fosse o mais claro e fácil de editar possível, para que a próxima geração de desenvolvedores pudesse fazer rapidamente as alterações necessárias para os negócios.
Como resultado, chegamos a uma certa estrutura que usamos em todos os novos microsserviços:
Contexto limitado . Cada novo microsserviço, começando com o Gerenciamento de pedidos, criamos com base nos requisitos de negócios. Deve haver explicações específicas sobre qual parte do sistema e por que é necessário colocá-lo em um microsserviço separado.
Infraestrutura e ferramentas existentes. Não somos a primeira equipe em Lamoda a começar a implementar o Go, fomos pioneiros diante de nós - a própria equipe do Go, que preparou a infraestrutura e as ferramentas:
- Gogi (swagger) é um gerador de especificação de swagger.
- Gonkey (teste) - para testes funcionais.
- Utilizamos o Json-rpc e geramos uma ligação cliente / servidor por meio do swagger. Também implantamos tudo isso no Kubernetes, coletamos métricas no Prometheus, usamos o ELK / Jaeger para rastreamento - tudo isso está incluído no pacote que o Gogi cria para cada novo microsserviço por especificação.
É assim que é o nosso novo microsserviço de Gerenciamento de Pedidos:
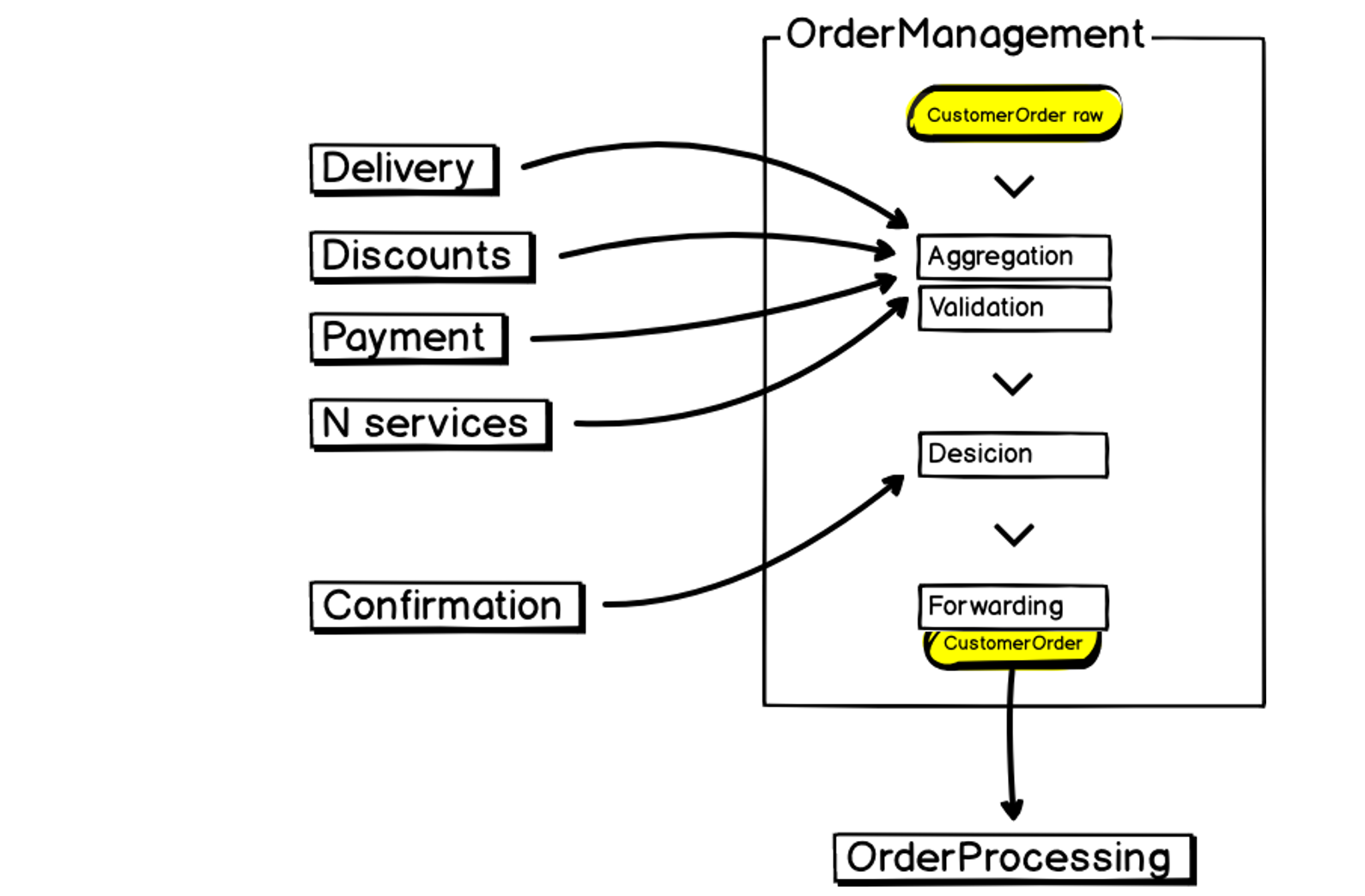
Na entrada, temos dados, agregamos, validamos, interagimos com serviços de terceiros, tomamos decisões e transferimos os resultados ainda mais para o Processamento de pedidos - o mesmo monólito grande, instável e que demanda recursos. Isso também precisa ser considerado ao criar um microsserviço.
Mudança de paradigma
Ao escolher Go, obtivemos imediatamente várias vantagens:
- A digitação forte estática corta imediatamente um certo intervalo de possíveis erros.
- O modelo de simultaneidade se encaixa bem em nossas tarefas, pois precisamos caminhar e pesquisar simultaneamente vários serviços.
- Composição e interfaces também nos ajudam nos testes.
- A "simplicidade" do estudo - foi aqui que descobriram não apenas vantagens óbvias, mas também problemas.
A linguagem Go limita a imaginação do desenvolvedor. Isso se tornou um obstáculo para nossa equipe, acostumada ao PHP quando mudamos para o desenvolvimento no Go. Estamos diante de uma verdadeira mudança de paradigma. Tivemos que passar por várias etapas e entender algumas coisas:
- Ir é difícil na construção de abstrações.
- Pode-se dizer que Go é baseado em objetos, mas não uma linguagem orientada a objetos, pois não há herança direta e outras coisas.
- O Go ajuda a escrever explicitamente, em vez de ocultar objetos atrás de abstrações.
- Go tem pipelining. Isso nos inspirou a construir cadeias de processadores de dados.
Como resultado, chegamos a entender que o Go é uma linguagem de programação procedural.

Dados primeiro
Eu estava pensando em como visualizar o problema que estávamos enfrentando e me deparei com esta imagem:
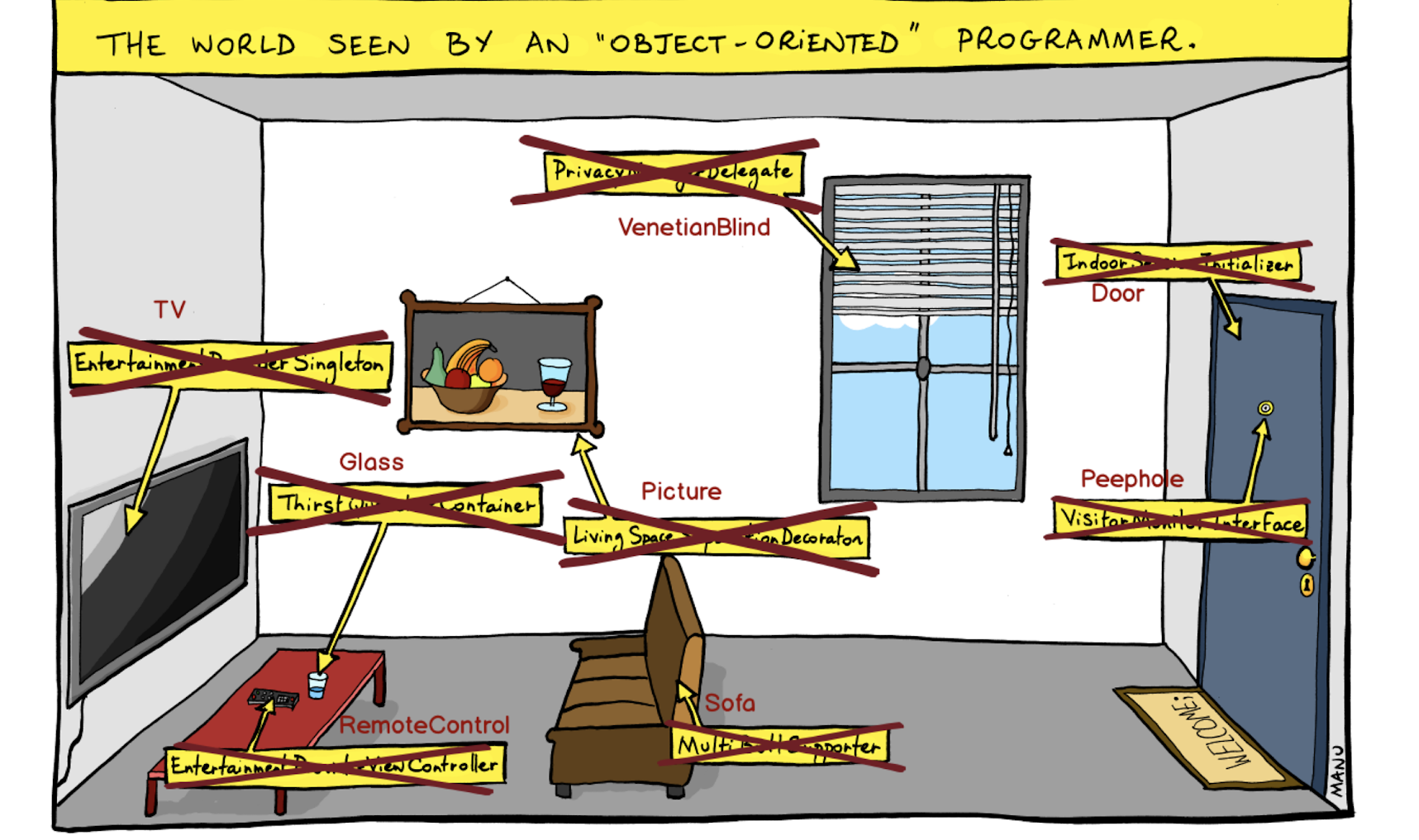
Esta é uma visão "orientada a objetos" do mundo, onde construímos abstrações e fechamos objetos por trás delas. Por exemplo, aqui não é apenas uma porta, mas um Inicializador de sessão interna. Não o aluno, mas a Interface do Monitor do Visitante - e assim por diante.
Abandonamos essa abordagem e colocamos as entidades em primeiro lugar, sem ficar obscurecidas pelas abstrações.
Raciocínio dessa maneira, colocamos os dados em primeiro lugar e obtivemos esse pipelining no serviço:

Inicialmente, definimos um modelo de dados que entra no pipeline do manipulador. Os dados são mutáveis e as alterações podem ocorrer sequencialmente e simultaneamente. Com isso, ganhamos em velocidade.
De volta ao futuro
De repente, desenvolvendo microsserviços, chegamos ao modelo de programação dos anos 70. Após os anos 70, surgiram grandes monólitos corporativos, onde apareceu a programação orientada a objetos e a programação funcional - grandes abstrações que tornaram possível manter o código nesses monólitos. Nos microsserviços, não precisamos de tudo isso, e podemos usar o excelente modelo de CSP ( comunicação de processos sequenciais ), cuja ideia foi apresentada nos anos 70 por Charles Choir.
Também usamos Sequência / Seleção / Interação - um paradigma de programação estrutural segundo o qual todo o código de programa pode ser composto pelas estruturas de controle correspondentes.
Bem, programação procedural, que era a corrente principal nos anos 70 :)
Estrutura do projeto

Como eu disse, em primeiro lugar, colocamos os dados. Além disso, substituímos a construção do projeto “da infraestrutura” por uma orientada para os negócios. Para que o desenvolvedor, inserindo o código do projeto, veja imediatamente o que o serviço está fazendo - essa é a própria transparência que identificamos como um dos requisitos básicos para a estrutura de nossos microsserviços.
Como resultado, temos uma arquitetura plana: uma pequena camada de API mais modelos de dados. E toda a lógica (que é limitada em nosso contexto pelos requisitos de negócios de um microsserviço) é armazenada nos processadores (manipuladores).
Tentamos não criar novos microsserviços separados sem uma solicitação clara da empresa - é assim que controlamos a granularidade de todo o sistema. Se existe uma lógica que está intimamente relacionada ao microsserviço existente, mas se refere essencialmente a um contexto diferente, concluímos primeiro nos chamados serviços. E somente quando uma necessidade constante de negócios surge, nós a transferimos para um microsserviço separado, que passamos a usar uma chamada rpc.
Para controlar a granularidade e não produzir microsserviços sem pensar, concluímos uma lógica que não está diretamente relacionada a esse contexto, mas que está intimamente relacionada a esse microsserviço, na camada de serviços. E então, se houver uma necessidade comercial, levamos para um microsserviço separado - e depois o usamos com a chamada rpc para acessá-lo.
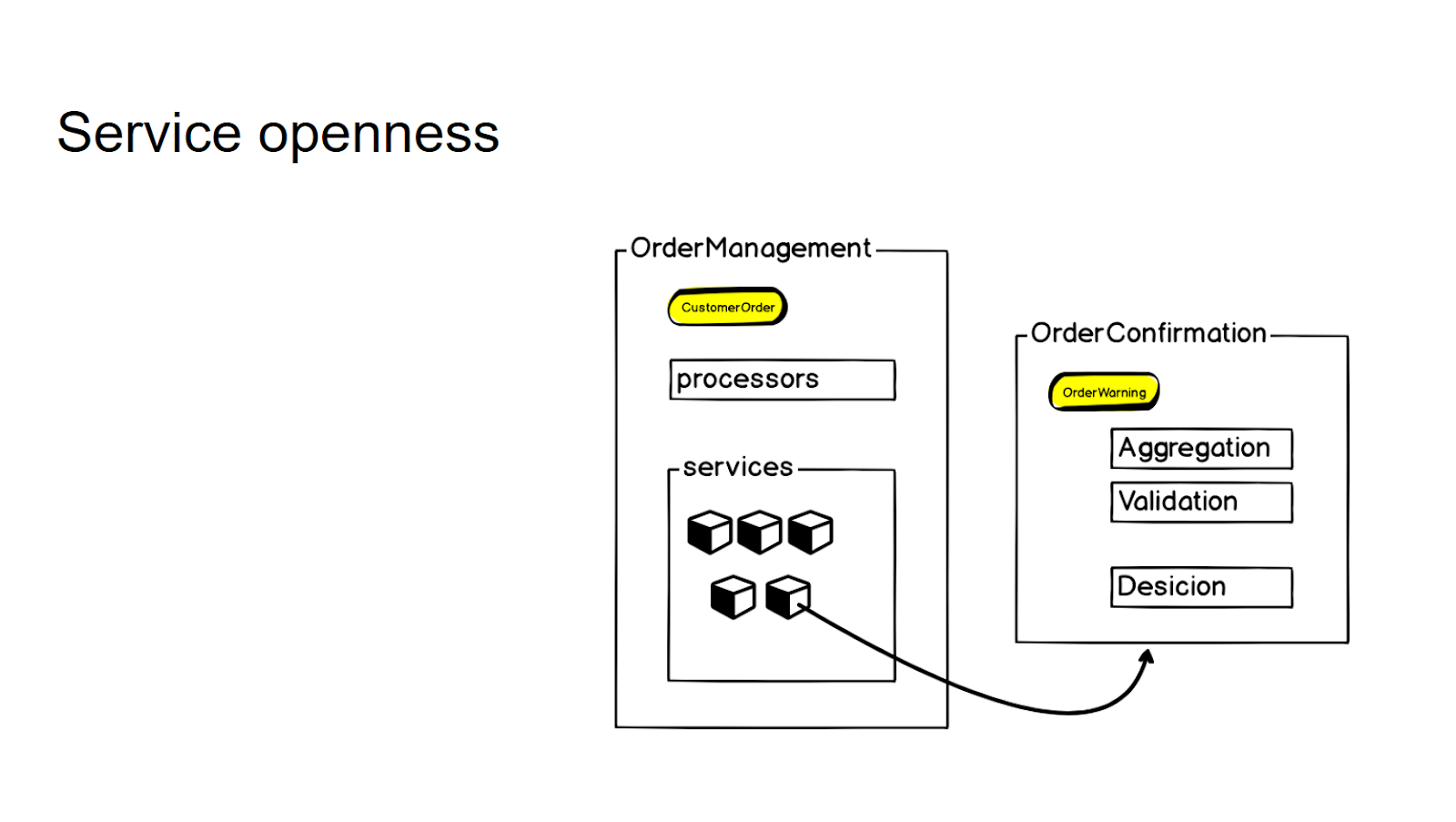
Portanto, para a API interna nos processadores do serviço, a interação não muda de forma alguma.
Sustentabilidade
Decidimos não usar bibliotecas de terceiros com antecedência, pois os dados com os quais trabalhamos são bastante sensíveis. Por isso, pedalamos um pouco :) Por exemplo, nós mesmos implementamos alguns mecanismos clássicos - para idempotência, trabalhador de filas, tolerância a falhas e transações de compensação. Nosso próximo passo é tentar reutilizá-lo. Enrole em bibliotecas, talvez em contêineres laterais nos Kubernetes Pods. Mas agora podemos aplicar esses padrões.
Implementamos em nossos sistemas um padrão chamado degradação graciosa: o serviço deve continuar funcionando, independentemente das chamadas externas nas quais agregamos informações. No exemplo da criação de um pedido: se o pedido entrar no serviço, criaremos um pedido em qualquer caso. Mesmo se o serviço vizinho cair, o que é responsável por parte da informação que devemos agregar ou validar. Além disso - não perderemos o pedido, mesmo que não possamos, a curto prazo, recusar o processamento do pedido, para onde devemos transferir. Esse também é um dos critérios pelos quais decidimos colocar a lógica em um serviço separado. Se o serviço não puder fornecer seu trabalho quando os seguintes serviços não estiverem disponíveis na rede, você precisará reprojetá-lo ou pensar se ele deve ser retirado do monólito.
Vá em frente!
Quando você escreve microsserviços de produtos orientados a negócios a partir de uma arquitetura clássica orientada a serviços, em particular o PHP, encontra uma mudança de paradigma. E isso deve ser passado, caso contrário, você pode entrar no rake sem parar. A estrutura de negócios do projeto nos permite não complicar o código mais uma vez e controlar a granularidade do serviço.
Uma de nossas principais tarefas era aumentar a estabilidade do serviço. Obviamente, o Go não fornece maior estabilidade apenas fora da caixa. Mas, na minha opinião, no ecossistema Go, ficou mais fácil criar todo o kit de Confiabilidade necessário, mesmo com suas próprias mãos, sem recorrer a bibliotecas de terceiros.
Outra tarefa importante foi aumentar a flexibilidade do sistema. E aqui posso dizer definitivamente que a taxa de introdução de mudanças exigidas pela empresa cresceu significativamente. Graças à arquitetura dos novos microsserviços, o desenvolvedor fica sozinho com os recursos de negócios; ele não precisa pensar em criar clientes, enviar monitoramento, enviar rastreamento e configurar o log. Deixamos para o desenvolvedor exatamente a camada de escrita da lógica de negócios, permitindo que ele não pense em todo o pacote de infraestrutura.
Vamos reescrever tudo no Go e abandonar o PHP?
Não, já que estamos nos afastando das necessidades dos negócios e há alguns contextos nos quais o PHP se encaixa muito bem - ele não precisa dessa velocidade e de todo o kit de ferramentas Go-go. Toda a automação das operações para entrega de pedidos e gerenciamento de estúdio de fotografia é feita em PHP. Mas, por exemplo, na plataforma de comércio eletrônico no lado do cliente, quase reescrevemos tudo no Go, pois é justificável.