O Spring é um poderoso framework Java de código aberto. Decidi lhe dizer para quais tarefas o back-end do Spring é útil e quais são seus prós e contras em comparação com outras bibliotecas: Guice e Dagger 2. Considere a injeção de dependência e a inversão de controle - você aprenderá como começar a aprender esses princípios.
- Olá pessoal, meu nome é Cyril. Hoje vou falar sobre injeção de dependência.
Começaremos com o que meu relatório é chamado. "Em um certo reino, não em um estado" emergente "." Falaremos, é claro, sobre Spring, mas também quero ver tudo o que está além dele. Sobre o que especificamente falaremos?

Farei uma pequena digressão - diga em que estou trabalhando, qual é meu projeto, por que usamos Injeção de Dependência. Depois, vou lhe dizer o que é, comparar a Inversão de Controle e a Injeção de Dependências e falar sobre sua implementação nas três bibliotecas mais famosas.
Eu trabalho na equipe Yandex.Tracker. Fazemos um análogo de supermercado de Jira ou Trello. [...] Decidimos fazer nosso próprio produto, que foi o primeiro interno. Agora estamos vendendo. Cada um de vocês pode entrar, criar seu próprio Tracker e executar tarefas - por exemplo, educacional ou comercial.
Vamos olhar para a interface. Nos exemplos, usarei alguns termos da minha área. Vamos tentar criar um ticket e analisar os comentários que outros colegas deixarão para mim.
Para começar, o que é injeção de dependência em geral? Esse é um padrão de programação que atende ao velho ditado americano, o princípio de Hollywood: "Não nos ligue, nós mesmos ligaremos para você". As próprias dependências chegam até nós. Isso é principalmente um padrão, não uma biblioteca. Portanto, em princípio, esse padrão é comum em quase todos os lugares. Você pode até dizer que todos os aplicativos usam a Injeção de Dependências de uma maneira ou de outra.

Vamos ver como você pode criar a Dependency Injection se começarmos do zero. Suponha que eu decidisse desenvolver uma classe tão pequena na qual criaria um ticket por meio de nossa API. Por exemplo, crie uma instância da classe TrackerApi. Possui um método createTicket no qual enviaremos meu email. Criaremos um ticket na minha conta com o nome: "Preparar um relatório para o Java Meetup".

Vamos ver a implementação do TrackerApi. Aqui, por exemplo, podemos fazer o seguinte: crie uma instância httpClient. Em termos simples, criaremos um objeto através do qual iremos para a API. Através deste objeto, chamaremos o método execute nele.

Por exemplo, um personalizado. Eu escrevi um código externo dessas classes e ele será usado assim. Crio um novo TicketCreator e chamo o método createTicket nele.

Há um problema aqui - sempre que criamos um ticket, recriaremos e recriaremos o httpClient, embora, de um modo geral, não seja necessário. Os httpClients são muito sérios para criar.

Vamos tentar fazer isso. Aqui você pode ver o primeiro exemplo de injeção de dependência em nosso código. Preste atenção ao que fizemos. Pegamos nossa variável no campo e a preenchemos no construtor. O fato de preenchê-lo no construtor significa que dependências chegam até nós. Esta é a primeira injeção de dependência.

Nós transferimos a responsabilidade para os usuários do código, agora precisamos criar um httpClient, passando-o, por exemplo, para o TicketCreator.
Isso também não é muito bom aqui, porque agora, chamando esse método, criaremos novamente o httpClient a cada vez.

Portanto, novamente o levamos para o campo. E aqui, a propósito, há um exemplo não óbvio de injeção de dependência. Podemos dizer que sempre criamos tickets debaixo de mim (ou debaixo de outra pessoa). Criaremos cada objeto TicketCreator separado com usuários diferentes.
Por exemplo, este será criado sob mim quando o criarmos. E a linha que passamos para o construtor também é injeção de dependência.

Como vamos fazer agora? Crie uma nova instância do TrackerTicketCreator e chame o método Agora podemos até criar algum tipo de método personalizado que criará um ticket com texto personalizado para nós. Por exemplo, crie um ticket "Contrate um novo trainee".

Agora, vamos tentar ver como seria o nosso código se quiséssemos ler os comentários neste ticket da mesma maneira, debaixo de mim. É sobre o mesmo código. Nós chamaríamos o método getComments neste ticket.
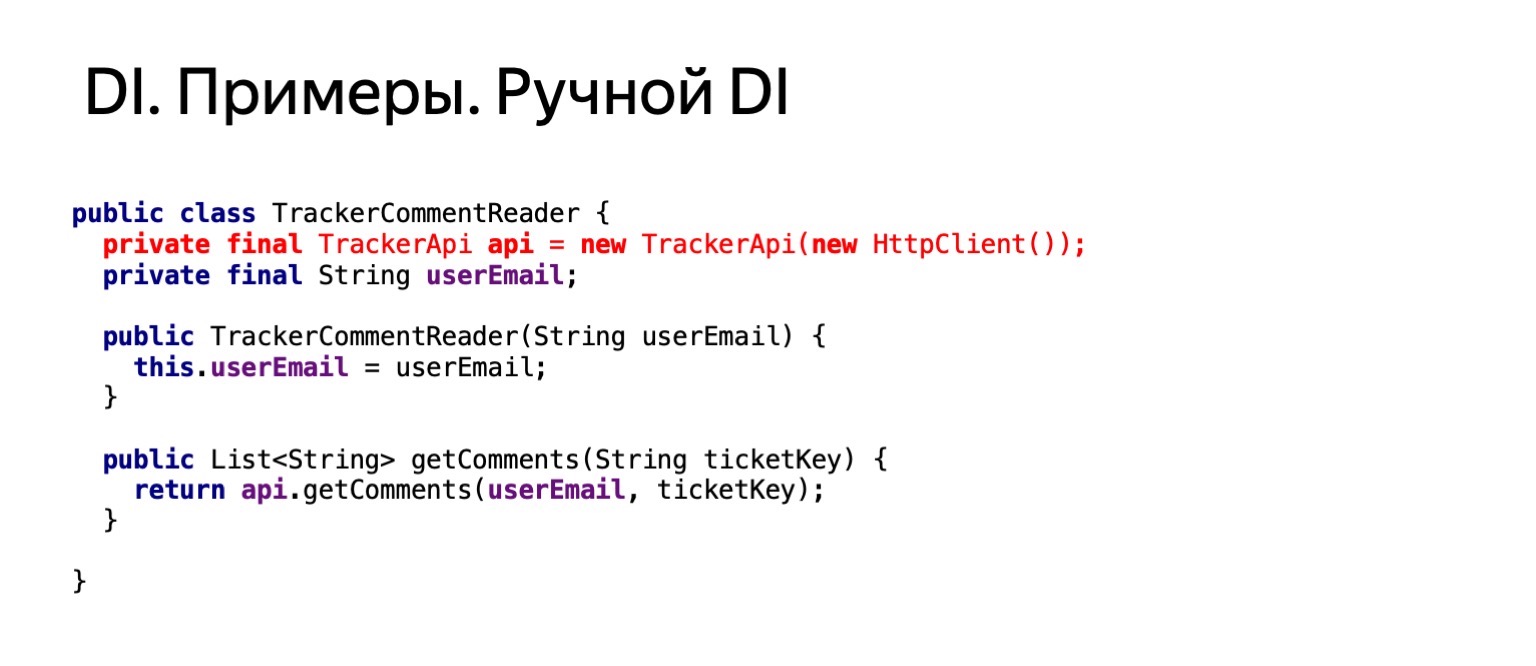
Como ele seria? Se pegarmos e duplicarmos essa funcionalidade em um leitor de comentários, duplicaremos a criação do httpClient. Isso não nos convém. Queremos nos livrar disso.

Bom Agora vamos encaminhar todos esses parâmetros como Injeção de Dependência, como parâmetros de construtor.

Qual é o problema aqui? Nós pulamos tudo, mas no código do usuário agora escrevemos "clichê". Esse é um tipo de código desnecessário que um usuário geralmente precisa escrever para executar uma ação relativamente pequena em termos de lógica. Aqui sempre teremos que criar o httpClient, uma API para ele e selecionar o email do usuário. Cada usuário do TicketCreator terá que fazer isso sozinho. Isto não está bem. Agora tentaremos ver como ficará nas bibliotecas quando tentarmos evitá-lo.
Agora, vamos nos desviar um pouco e ver o que é a Inversão de Controle, porque muitos associam a Injeção de Dependência a ela.

Inversão de controle é um princípio de programação em que os objetos que usamos não são criados por nós. Não afetamos o ciclo de vida deles. Normalmente, a entidade que cria esses objetos é chamada de contêiner de IoC. Muitos de vocês já ouviram falar da primavera aqui. A documentação do Spring diz que as IoCs também são conhecidas como Injeção de Dependência. Eles acreditam que este é o mesmo.

Quais são os princípios básicos? Os objetos são criados não pelo código do aplicativo, mas por algum contêiner de IoC. Nós, como usuários da biblioteca, não fazemos nada, tudo chega até nós por conta própria. Obviamente, a IoC é relativa. O próprio contêiner de IoC cria esses objetos, e isso não é mais aplicável a ele. Você pode pensar que a IoC implementa não apenas bibliotecas de DI. As conhecidas bibliotecas Java Servlets e Akka Actors, que agora são usadas no Scala e no código Java.

Vamos falar sobre bibliotecas. De um modo geral, muitas bibliotecas já foram escritas para Java e Kotlin. Vou listar os principais:
- Primavera, uma ótima estrutura. Sua parte principal é a Injeção de Dependência ou, como se costuma dizer, Inversão de Controle.
- Guice é uma biblioteca que foi escrita aproximadamente entre o segundo e o terceiro Spring, quando o Spring passou do XML para a descrição do código. Ou seja, quando a primavera ainda não era tão bonita.
- Dagger é o que as pessoas no Android costumam usar.
Vamos tentar reescrever nosso exemplo no Spring.

Tivemos o nosso TrackerApi. Não incluí o usuário aqui, para abreviar. Suponha que tentemos fazer injeção de dependência para httpClient. Para fazer isso, precisamos declará-lo com uma anotação.
Componente , toda a classe e, especificamente, o construtor, são declarados com a anotação
Autowired . O que isso significa para a primavera?

Temos essa configuração no código, que é indicada pela anotação da Verificação de
componentes . Isso significa que tentaremos percorrer toda a árvore de nossas classes no pacote em que está contida. E mais para o interior, tentaremos encontrar todas as classes marcadas na anotação de
componente .
Esses componentes cairão no contêiner de IoC. É importante para nós que tudo caia para nós. Marcamos apenas o que queremos anunciar. Para que algo chegue até nós, devemos declarar usando a anotação
Autowired no construtor.

TicketCreator marcamos exatamente da mesma maneira.

E CommentReader também.
Agora vamos olhar para a configuração. Como dissemos, o Component Scan colocará tudo em um contêiner de IoC. Mas há um ponto, o chamado método de fábrica. Temos o método httpClient, que não criamos como classe, porque o httpClient vem da biblioteca. Ele não entende o que é o Spring e assim por diante.Nós o criaremos diretamente na configuração. Para fazer isso, escrevemos um método que geralmente o constrói uma vez e o marcamos com a anotação Bean.

Quais são os prós e contras? A principal vantagem - a primavera é muito comum no mundo. O próximo sinal de mais e menos é a verificação automática. Não devemos declarar explicitamente em nenhum lugar que queremos adicionar um contêiner à IoC, além de anotações sobre as próprias classes. Anotações suficientes. E o menos é exatamente o mesmo: se, pelo contrário, queremos controle sobre isso, então o Spring não nos fornece isso. A menos que possamos dizer em nossa equipe: “Não, não faremos isso. Devemos prescrever claramente algo em algum lugar. Somente na configuração, como fizemos com os beans.
Além disso, por isso, ocorre um início lento. Quando o aplicativo é iniciado, o Spring precisa passar por todas essas classes e descobrir o que colocar no contêiner de IoC. Isso o atrasa. A maior desvantagem do Spring, me parece, é a árvore de dependência. Não está marcado na fase de compilação. Quando o Spring começa em algum momento, ele precisa entender se eu tenho essa dependência por dentro. Se mais tarde acontecer que não está na árvore de dependências, você receberá um erro no tempo de execução. E nós em Java não queremos um erro de tempo de execução. Queremos que o código seja compilado para nós. Isso significa que funciona.

Vamos dar uma olhada no Guice. Esta é uma biblioteca que, como eu disse, foi criada entre a segunda e a terceira primavera. A beleza que vimos não era. Havia XML. Para corrigir este problema, e foi escrito por Guice. E aqui você pode ver que, diferentemente da configuração, estamos escrevendo um módulo. Nele, declaramos explicitamente quais classes queremos colocar neste módulo: TrackerAPI, TrackerTicketCreator e todos os outros compartimentos. Um análogo à anotação do Bean aqui é o
Fornece , que cria o httpClient da mesma maneira.

Precisamos declarar cada um desses grãos. Vamos citar um exemplo de
Singleton . Mas especificamente,
Singleton dirá que esse bean será criado exatamente uma vez. Nós não o recriaremos constantemente. E
Inject , respectivamente, é um análogo da
Autowired .

Um pequeno tablet com o que pertence.

Quais são os prós e contras? Prós: é mais simples, parece-me, e compreensível que a versão XML do Spring. Inicialização mais rápida. E aqui estão os contras: requer declaração explícita dos beans usados. Deveríamos ter escrito Bean. Mas, por outro lado, isso é uma vantagem, como já dissemos. Esta é uma imagem espelhada do que a Spring possui. Claro, é menos comum que a primavera. Este é o seu menos natural. E existe exatamente o mesmo problema - a árvore de dependência não é verificada no estágio de compilação.
Quando os caras começaram a usar o Guice para Android, eles perceberam que ainda não tinham velocidade de lançamento. Portanto, eles decidiram escrever uma estrutura de Injeção de Dependências mais simples e mais primitiva que lhes permitirá iniciar rapidamente o aplicativo, porque para o Android é muito importante.

Aqui a terminologia é a mesma. O Dagger tem exatamente os mesmos módulos que o Guice. Mas eles já estão marcados com anotações, não como no caso de herança da classe. Portanto, o princípio é mantido.
O único ponto negativo é que devemos sempre indicar explicitamente no módulo como os beans são criados. No Guice, poderíamos criar o feijão dentro do próprio feijão. Não precisamos dizer que tipo de dependências precisamos encaminhar. E aqui precisamos dizer isso explicitamente.

No Dagger, como você não deseja fazer entradas manuais demais, existe o conceito de um componente. Um componente é algo que liga módulos quando queremos declarar uma posição de um módulo para que possa ser obtida em outro módulo. Este é um conceito diferente. Um bean de um módulo pode "injetar" um bean de outro módulo usando um componente.

Aqui está a mesma placa de resumo - o que mudou ou não no caso de Injeção ou módulos.

Quais são as vantagens? É ainda mais simples que Guice. O lançamento é ainda mais rápido que o Guice. E provavelmente não ficará mais rápido, porque Dagger abandonou completamente a reflexão. Essa é exatamente a parte da biblioteca em Java responsável por examinar o estado de um objeto, sua classe e métodos. Ou seja, obtenha o estado em tempo de execução. Portanto, ele não usa reflexão. Ele não vai e não verifica quais dependências alguém tem. Mas por causa disso, ele começa muito rapidamente.
Como ele faz isso? Usando geração de código.
Se olharmos para trás, veremos o componente da interface. Não implementamos nenhuma implementação dessa interface, o Dagger faz isso por nós. E será possível usar ainda mais a interface no aplicativo.
Naturalmente, é muito comum no mundo Android devido a essa velocidade. A árvore de dependência é verificada imediatamente na compilação, porque não há nada que iremos adiar em tempo de execução.
Quais são as desvantagens? Ele tem menos oportunidades. É mais detalhado que Guice e Spring.

Dentro dessas bibliotecas, surgiu uma iniciativa em Java - o chamado JSR-330. O JSR é uma solicitação para fazer uma alteração na especificação da linguagem ou complementá-la com algumas bibliotecas adicionais. Esse padrão foi proposto com base no Guice, e as anotações do
Inject foram adicionadas a esta biblioteca. Assim, Spring e Guice apoiam.
Que conclusões podem ser tiradas? Java possui muitas bibliotecas diferentes para DI. E você precisa entender por que escolhemos um deles específico. Se usarmos o Android, então já não há escolha, usamos o Dagger. Se formos para o mundo back-end, já estaremos olhando o que melhor nos convém. E para o primeiro estudo de Injeção de Dependência, parece-me que Guice é melhor que Spring. Não há nada supérfluo nele. Você pode ver como funciona, sentir.
Para um estudo mais aprofundado, sugiro que você se familiarize com a documentação de todas essas bibliotecas e a composição do JSR:
-
Primavera-
Guice-
Adaga 2-
JSR-330Obrigada