Desde a última publicação no mundo da linguagem Julia, muitas coisas interessantes aconteceram:
Ao mesmo tempo, há um aumento perceptível no interesse dos desenvolvedores, o que é expresso por um abundante benchmarking:
Apenas nos alegramos com ferramentas novas e convenientes e continuamos a estudá-las. Esta noite será dedicada à análise de texto, à busca de significado oculto nos discursos dos presidentes e à geração de texto no espírito de Shakespeare e de um programador de Julia, e, para a sobremesa, alimentamos uma rede recursiva de 40.000 tortas.
Recentemente, aqui em Habré, foi realizada a revisão de pacotes para Julia, permitindo realizar pesquisas no campo da PNL - Julia PNL. Nós processamos textos . Então, vamos aos negócios imediatamente e começaremos com o pacote TextAnalysis .
TextAnalisys
Deixe algum texto ser fornecido, que representamos como um documento de string:
using TextAnalysis str = """ Ich mag die Sonne, die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher. Ich mag den kalten Mond, wenn der Vollmond rund, Und ich mag dich mit einem Knebel in dem Mund. """; sd = StringDocument(str)
StringDocument{String}("Ich mag die ... dem Mund.\n", TextAnalysis.DocumentMetadata(Languages.Default(), "Untitled Document", "Unknown Author", "Unknown Time"))
Para um trabalho conveniente com um grande número de documentos, é possível alterar campos, por exemplo, títulos e também, para simplificar o processamento, podemos remover pontuação e letras maiúsculas:
title!(sd, "Knebel") prepare!(sd, strip_punctuation) remove_case!(sd) text(sd)
"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"
que permite criar n-gramas organizados para palavras:
dict1 = ngrams(sd) Dict{String,Int64} with 26 entries: "dem" => 1 "himmel" => 1 "knebel" => 1 "der" => 1 "schauen" => 1 "mund" => 1 "rund" => 1 "in" => 1 "mond" => 1 "dich" => 1 "einem" => 1 "ich" => 4 "hinterher" => 1 "wolken" => 1 "den" => 3 "das" => 1 "palmen" => 1 "kalten" => 1 "mag" => 4 "sonne" => 1 "vollmond" => 1 "die" => 2 "mit" => 1 "meer" => 1 "wenn" => 1 "und" => 2
É claro que sinais de pontuação e palavras com letras maiúsculas serão unidades separadas no dicionário, o que interferirá na avaliação qualitativa das ocorrências de frequência dos termos específicos de nosso texto, portanto, nos livramos deles. Para n-gramas, é fácil encontrar muitas aplicações interessantes, por exemplo, elas podem ser usadas para pesquisas nebulosas no texto , mas como somos apenas turistas, vamos dar exemplos de brinquedos, a saber, a geração de texto usando cadeias de Markov
Procházení modelového grafu
Uma cadeia de Markov é um modelo discreto de um processo de Markov que consiste em uma alteração em um sistema que leva em consideração apenas seu estado anterior (modelo). Figurativamente falando, pode-se perceber essa construção como um autômato celular probabilístico. N-gramas coexistem bastante com esse conceito: qualquer palavra do léxico está associada a qualquer outra conexão de diferentes espessuras, determinada pela frequência de ocorrência de pares específicos de palavras (gramas) no texto.

Cadeia de Markov para a cadeia "ABABD"
A implementação do algoritmo em si já é uma ótima atividade para a noite, mas Julia já possui um maravilhoso pacote Markovify , criado apenas para esses fins. Percorrendo cuidadosamente o manual em tcheco , prosseguimos para nossas execuções linguísticas.
Dividir texto em tokens (por exemplo, palavras)
using Markovify, Markovify.Tokenizer tokens = tokenize(str, on = words) 2-element Array{Array{String,1},1}: ["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."] ["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]
Compomos um modelo de primeira ordem (apenas os vizinhos mais próximos são levados em consideração):
mdl = Model(tokens; order=1) Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))
Em seguida, procedemos à implementação da função da frase geradora com base no modelo fornecido. Na verdade, é preciso um modelo, uma solução alternativa e o número de frases que você deseja obter:
Código function gensentences(model, fun, n) sentences = []
O desenvolvedor do pacote forneceu duas funções de desvio: walk e walk2 (o segundo funciona mais, mas oferece designs mais exclusivos), e você sempre pode determinar sua opção. Vamos tentar:
gensentences(mdl, walk, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher." "Ich mag den Wolken hinterher." "Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund." gensentences(mdl, walk2, 4) 4-element Array{Any,1}: "Ich mag den Wolken hinterher." "Ich mag dich mit einem Knebel in dem Mund." "Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher." "Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
Obviamente, é grande a tentação de experimentar textos em russo, especialmente em versos brancos. Para o idioma russo, devido à sua complexidade, a maioria das frases é ilegível. Além disso, como já mencionado , caracteres especiais requerem cuidados especiais; portanto, salvamos os documentos dos quais o texto codificado em UTF-8 é coletado ou usamos ferramentas adicionais .
Seguindo o conselho de sua irmã, depois de limpar alguns livros de Oster de caracteres especiais e quaisquer separadores e definir uma segunda ordem para n-gramas, obtive o seguinte conjunto de unidades fraseológicas:
", !" ". , : !" ", , , , ?" " !" ". , !" ". , ?" " , !" " ?" " , , ?" " ?" ", . ?"
Ela garantiu que era por essa técnica que os pensamentos eram construídos no cérebro feminino ... ah, e quem sou eu para argumentar ...
Analise
No diretório do pacote TextAnalysis, você pode encontrar exemplos de dados textuais, um dos quais é uma coleção de discursos de presidentes americanos antes do congresso

Código using TextAnalysis, Clustering, Plots
29-element Array{String,1}: "Bush_1989.txt" "Bush_1990.txt" "Bush_1991.txt" "Bush_1992.txt" "Bush_2001.txt" "Bush_2002.txt" "Bush_2003.txt" "Bush_2004.txt" "Bush_2005.txt" "Bush_2006.txt" "Bush_2007.txt" "Bush_2008.txt" "Clinton_1993.txt" ⋮ "Clinton_1998.txt" "Clinton_1999.txt" "Clinton_2000.txt" "Obama_2009.txt" "Obama_2010.txt" "Obama_2011.txt" "Obama_2012.txt" "Obama_2013.txt" "Obama_2014.txt" "Obama_2015.txt" "Obama_2016.txt" "Trump_2017.txt"
Depois de ler esses arquivos e formar um corpo deles, além de limpá-lo da pontuação, revisaremos o vocabulário geral de todos os discursos:
Código crps = DirectoryCorpus(pth) standardize!(crps, StringDocument) crps = Corpus(crps[1:29]);
remove_case!(crps) prepare!(crps, strip_punctuation) update_lexicon!(crps) update_inverse_index!(crps) lexicon(crps)
Dict{String,Int64} with 9078 entries: "enriching" => 1 "ferret" => 1 "offend" => 1 "enjoy" => 4 "limousines" => 1 "shouldn" => 21 "fight" => 85 "everywhere" => 17 "vigilance" => 4 "helping" => 62 "whose" => 22 "'" => 725 "manufacture" => 3 "sleepless" => 2 "favor" => 6 "incoherent" => 1 "parenting" => 2 "wrongful" => 1 "poised" => 3 "henry" => 3 "borders" => 30 "worship" => 3 "star" => 10 "strand" => 1 "rejoin" => 3 ⋮ => ⋮
Pode ser interessante ver quais documentos contêm palavras específicas, por exemplo, veja como lidamos com as promessas:
crps["promise"]' 1×24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29 crps["reached"]' 1×7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}: 12 14 15 17 19 20 22
ou com frequências de pronomes:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you") (0.010942182388035081, 0.005905479339070189)
Então provavelmente cientistas e jornalistas de estupro e há uma atitude perversa em relação aos dados que estão sendo estudados.
Matrizes
A semântica verdadeiramente distributiva começa quando textos, gramas e tokens se transformam em vetores e matrizes .
Um termo matriz de documentos ( DTM ) é uma matriz que possui um tamanho onde - o número de documentos no processo, e - tamanho do dicionário de corpus, ou seja, o número de palavras (únicas) encontradas em nosso corpus. Na i- ésima linha, a j- ésima coluna da matriz é um número - quantas vezes no i- ésimo texto a j- ésima palavra foi encontrada.
Código dtm1 = DocumentTermMatrix(crps)
D = dtm(dtm1, :dense) 29×9078 Array{Int64,2}: 0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0 0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0 0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0 0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0 0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0 0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31 2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0 2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0 0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0 0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0 0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0 0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0 1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1 1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1 0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0 1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1 0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7 2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0 1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0
Aqui as unidades originais são termos
m.terms[3450:3465] 16-element Array{String,1}: "franklin" "frankly" "frankness" "fraud" "frayed" "fraying" "fre" "freak" "freddie" "free" "freed" "freedom" "freedoms" "freely" "freer" "frees"
Espere um momento ...
crps["freak"] 1-element Array{Int64,1}: 25 files[25] "Obama_2013.txt"
Será necessário ler com mais detalhes ...
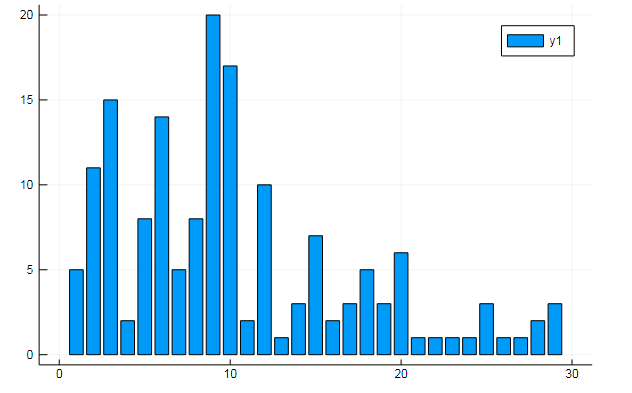
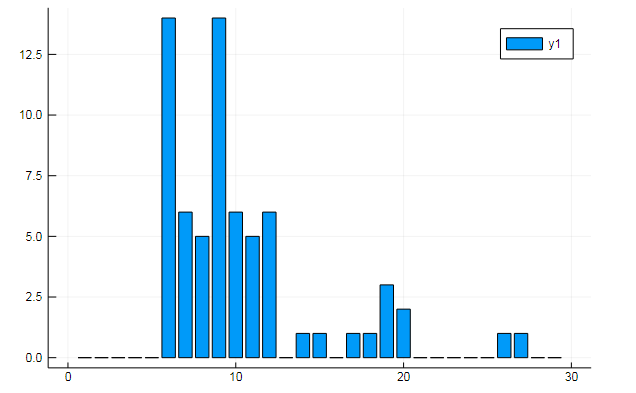
Você também pode extrair todos os tipos de dados interessantes do termo matrizes. Diga a frequência de ocorrência de palavras específicas em documentos
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"] (3452, 8101)
D[:, w1] |> bar
D[:, w1] |> bar
ou similaridade de documentos sobre alguns tópicos ocultos:
k = 3

Os gráficos mostram como cada um dos três tópicos é divulgado nos discursos.
ou agrupar palavras por tópico ou, por exemplo, a semelhança de vocabulário e a preferência de determinados tópicos em diferentes documentos
T = tf_idf(D) cl = kmeans(T, 5)
s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006") s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016") s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017") plot(s1, s2, s3, layout = (3,1), legend=false )
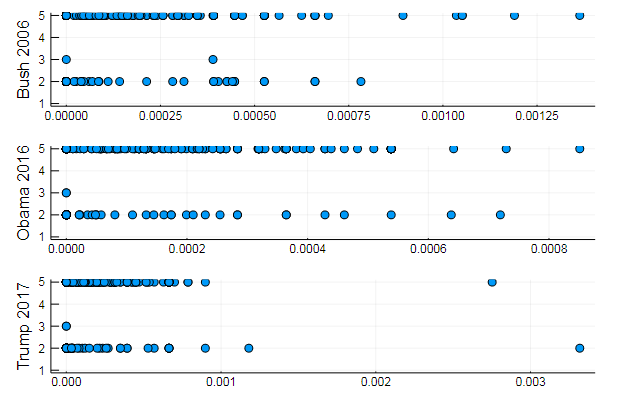
Resultados bastante naturais, performances do mesmo tipo. De fato, a PNL é uma ciência bastante interessante, e você pode extrair muitas informações úteis de dados corretamente preparados: você pode encontrar muitos exemplos sobre este recurso ( reconhecimento do autor nos comentários , uso da LDA etc.)
Bem, para não ir muito longe, geraremos frases para o presidente ideal:
Código function loadfiles(filenames) return ( open(filename) do file text = read(file, String)
7-element Array{Any,1}: "I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership." "I am asking all across our partners must be one very happy, indeed." "At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community." "Millions lifted from this Nation, and Jessica Davis." "It will expand choice, increase access, lower the Director of our aspirations, not working." "We will defend our freedom." "The challenges we will celebrate the audience tonight, has come for a record."
Memória de longo prazo
Bem, como pode ser sem redes neurais! Eles colecionam louros neste campo com velocidade cada vez maior, e o ambiente da linguagem Julia contribui para isso de todas as formas. Para os curiosos, você pode aconselhar o pacote Knet , que, diferente do Flux que examinamos anteriormente , não funciona com arquiteturas de redes neurais como construtor de módulos, mas na maioria das vezes funciona com iteradores e fluxos. Isso pode ser de interesse acadêmico e contribuir para uma compreensão mais profunda do processo de aprendizado, além de oferecer computação de alto desempenho. Ao clicar no link fornecido acima, você encontrará orientações, exemplos e materiais para auto-estudo (por exemplo, mostra como criar um gerador de texto shakespeariano ou código julíaco em redes recorrentes). No entanto, algumas funções do pacote Knet são implementadas apenas para a GPU; portanto, por enquanto, vamos continuar executando o Flux.
Um dos exemplos típicos da operação de redes de recorrência é frequentemente o modelo de alimentação simbólica dos sonetos de Shakespeare:
QUEN: Chiet? The buswievest by his seld me not report. Good eurronish too in me will lide upon the name; Nor pain eat, comes, like my nature is night. GRUMIO: What for the Patrople: While Antony ere the madable sut killing! I think, bull call. I have what is that from the mock of France: Then, let me? CAMILLE: Who! we break be what you known, shade well? PRINCE HOTHEM: If I kiss my go reas, if he will leave; which my king myself. BENEDICH: The aunest hathing rouman can as? Come, my arms and haste. This weal the humens? Come sifen, shall as some best smine? You would hain to all make on, That that herself: whom will you come, lords and lafe to overwark the could king to me, My shall it foul thou art not from her. A time he must seep ablies in the genely sunsition. BEATIAR: When hitherdin: so like it be vannen-brother; straight Edwolk, Wholimus'd you ainly. DUVERT: And do, still ene holy break the what, govy. Servant: I fearesed, Anto joy? Is it do this sweet lord Caesar: The dece
Se você apertar os olhos e não souber inglês, a peça parecerá bastante real .

É mais fácil entender em russo
Mas é muito mais interessante experimentar o grande e poderoso, e embora seja muito difícil lexicamente, você pode usar mais literatura primitiva como dados, a saber, mais recentemente conhecida como a corrente de vanguarda da poesia moderna - rimas-tortas.
Coleta de dados
Tortas e pós - quadras rítmicas, geralmente sem rima, digitadas em minúsculas e sem sinais de pontuação.
A escolha recaiu no site poetory.ru, no qual o camarada administrador hior . A longa falta de resposta à solicitação de dados foi o motivo para começar a estudar a análise do site. Uma rápida olhada no tutorial em HTML fornece uma compreensão rudimentar do design de páginas da web. A seguir, encontramos os meios da linguagem Julia para trabalhar nessas áreas:
- HTTP.jl - funcionalidade de cliente e servidor HTTP para Julia
- Gumbo.jl - analisando layouts de html e não apenas
- Cascadia.jl - Pacote Auxiliar para Gumbo

Em seguida, implementamos um script que transforma páginas da poesia e salva as tortas em um documento de texto:
Código using HTTP, Gumbo, Cascadia function grabit(npages) str = "" for i = 1:npages url = "https://poetory.ru/por/rating/$i"
Mais detalhadamente, é desmontado em um notebook de Júpiter . Vamos coletar as tortas e a pólvora em uma única linha:
str = read("pies.txt", String) * read("poroh.txt", String); length(str)
E veja o alfabeto usado:
prod(sort([unique(str)..., '_']) )

Verifique os dados baixados antes de iniciar o processo.
Ay-ah-ah, que vergonha! Alguns usuários violam as regras (às vezes as pessoas se expressam fazendo barulho nesses dados). Então, vamos limpar nossa caixa de símbolos do lixo
str = lowercase(str)
Conforme recomendado por rssdev10, o código é modificado usando expressões regulares
Tem um conjunto de caracteres mais aceitável. A maior revelação de hoje é que, do ponto de vista do código de máquina, existem pelo menos três espaços diferentes - é difícil para os caçadores de dados viverem.

Agora você pode conectar o Flux com a apresentação subsequente dos dados na forma de vetores onehot:
O fluxo entra em jogo using Flux using Flux: onehot, chunk, batchseq, throttle, crossentropy using StatsBase: wsample using Base.Iterators: partition texta = collect(str) println(length(texta))
Definimos o modelo a partir de duas camadas LSTM, um perceptron e softmax totalmente conectados, além de pequenas coisas do dia-a-dia, e para a função de perda e o otimizador:
Código m = Chain( LSTM(N, 256), LSTM(256, 128), Dense(128, N), softmax)
O modelo está pronto para o treinamento; portanto, executando a linha abaixo, você pode cuidar de seus próprios negócios, cujo custo é selecionado de acordo com a potência do seu computador. No meu caso, são duas palestras sobre filosofia que, por alguma coisa maldita, nos foram entregues tarde da noite ...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt, cb = throttle(evalcb, 30))
Depois de montar um gerador de amostras, você pode começar a colher os benefícios de seus trabalhos.
gerador barmaglot function sample(m, alphabet, len)
Ligeira decepção devido a expectativas um pouco elevadas. Embora a rede tenha apenas uma sequência de caracteres na entrada e possa operar apenas com as frequências de seu encontro um após o outro, capturou completamente a estrutura do conjunto de dados, destacou algumas semelhanças de palavras e, em alguns casos, até mostrou a capacidade de manter o ritmo. Possivelmente, a identificação da afinidade semântica ajudará na melhoria.

Os pesos de uma rede treinada podem ser salvos no disco e depois lidos facilmente
weights = Tracker.data.(params(model)); using BSON: @save
Também com prosa, apenas surgem psicodélicos cibernéticos abstratos. Houve tentativas de melhorar a qualidade da largura e profundidade da rede, bem como a diversidade e abundância de dados. Para o corpo de texto fornecido, um agradecimento especial ao maior popularizador do idioma russo

! . ? , , , , , , , , . , , , , . , . ? , , , , , ,
Mas se você treina uma rede neural no código-fonte da linguagem Julia, fica bem legal:
Somado a isso a possibilidade de metaprogramação , obtemos um programa que escreve e roda, talvez até nosso próprio código! Bem, ou será uma dádiva de Deus para os designers de filmes sobre hackers .
Em geral, o começo foi feito, e então já como a fantasia indica. Primeiro, você deve adquirir equipamentos de alta qualidade para que cálculos longos não sufoquem o desejo de experimentar. Em segundo lugar, precisamos estudar métodos e heurísticas mais profundamente, o que nos permitirá projetar modelos melhores e mais otimizados. Nesse recurso, basta encontrar tudo relacionado ao Processamento de linguagem natural, após o qual é perfeitamente possível ensinar à sua rede neural como gerar poesia ou ir a um hackathon para análise de texto .
Sobre isso, deixe-me me despedir. Dados para treinamento na nuvem , listagens no github , fogo nos olhos, um ovo em um pato e boa noite a todos!