Olá Habr! Hoje, queremos compartilhar com você um artigo do chefe do suporte técnico do IT-GRAD Alik Fakhrutdinov, no qual falaremos sobre como construímos um novo sistema de monitoramento como parte de uma colaboração com o MTS PJSC. Desta vez, omitimos os detalhes e as nuances técnicas e focamos na complexidade administrativa do processo. Sob o corte, falaremos sobre quais eventos nos levaram a construir um novo sistema de monitoramento (em vez de "estragar" o antigo), falaremos sobre novos chips de monitoramento como um serviço para os clientes e as dificuldades que encontramos no processo.

Como você deve saber, o conceito de provedor de nuvem unificado é atualmente representado por três marcas colaboradoras:
- #CloudMTS, criado pelo Centro de Inovação MTS;
- IT-GRAD Company, um provedor de IaaS baseado em nuvem;
- Serviço 1cloud.
Agora, todas as marcas desse conceito trabalham juntas e se complementam mutuamente, tentando fechar as solicitações de vários segmentos de nosso público. No entanto, durante a fusão, encontramos algumas dificuldades, uma das quais levou ao desenvolvimento de um novo sistema de monitoramento.
Após a transação, foi iniciado o processo de separação da infraestrutura de TI em nuvem do IT-GRAD em um segmento separado. Foi um período de transição difícil, durante o qual um grande número de equipamentos e data centers foram desconectados, que não foram incluídos no acordo. O roteamento das redes internas e externas mudou. Ao mesmo tempo, os prazos estavam se esgotando e os gatilhos no sistema de monitoramento nem sempre conseguiam atualizar a tempo. Isso levou à geração de muitos incidentes falsos a partir de equipamentos inexistentes.
No processo de reconfiguração global, os funcionários tiveram dificuldades. suporte - eles enfrentaram um fluxo tão grande de alertas falsos que foi extremamente difícil processar todos os eventos corretamente e em tempo hábil. Era necessário reconfigurar completamente o sistema de monitoramento, atualizando-o para as tarefas atuais e transformá-lo em um novo serviço, tanto para uso interno quanto para nossos clientes.
Como resultado, decidiu-se criar uma unidade de gerenciamento de eventos dedicada, que estabelecerá o sistema de monitoramento no IT-GRAD e, posteriormente, se tornará um único centro para monitorar o estado da infraestrutura do provedor de nuvem integrado.
Como resultado da transformação, os principais requisitos são:
- O sistema de monitoramento deve funcionar não apenas no IT-GRAD, mas também se tornar um serviço interno para o Unified Cloud Provider e um serviço para os clientes.
- Era necessária uma solução que coletasse estatísticas de toda a infraestrutura de TI.
- Como existem muitos sistemas, todos os eventos de monitoramento devem convergir em um único agregador de dados, onde eventos e gatilhos são verificados em um único CMDB e, se necessário, os usuários são notificados automaticamente.
Depois de coletar e analisar todos os dados disponíveis naquele momento, dividimos a implementação do projeto em várias etapas:
- Determinando os requisitos para um sistema de monitoramento.
- Preparação de modelos de serviços de “componentes de saúde”.
- Análise de requisitos de confiabilidade e tolerância a falhas do sistema de monitoramento.
- Teste e implementação consistente do sistema.
- Organização de monitoramento como serviço para clientes.
Para maior clareza, apresentamos esse processo na forma de um fluxograma.

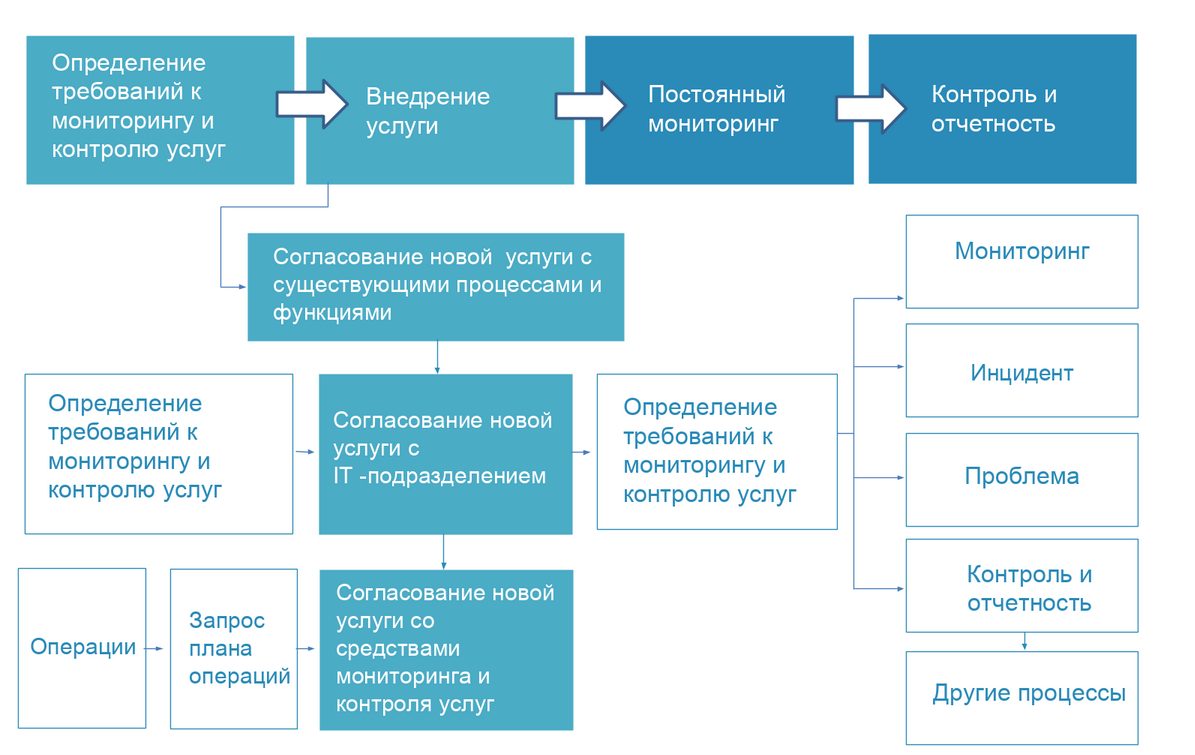
Dificuldades de crescimento
Obviamente, a introdução de um sistema tão complexo não pôde correr perfeitamente bem, e encontramos algumas dificuldades.
- O primeiro ponto é a formação de um novo departamento. Descobriu-se que encontrar especialistas altamente especializados que conhecem e têm experiência prática trabalhando com vários sistemas de monitoramento não é tão simples. Um de nossos requisitos era o entendimento do monitoramento como serviço, e não apenas como um dos componentes da infraestrutura de TI.
- Prazos para resolver o problema.
- Uma infraestrutura de TI geograficamente fragmentada que precisava ser levada a um único padrão.
- Um grande número de sistemas de monitoramento diferentes que precisavam ser combinados em um único sistema.
Monitoramento e relatórios no sistema de monitoramento

Socialismo: a infraestrutura de TI é contabilidade e controle. Nem um único evento, mesmo o mais insignificante, deve ser deixado sem atenção. No momento, conseguimos criar um processo de geração de relatórios e controle, incluindo:
- relatórios e estatísticas de rastreamento dos componentes de nossos clientes;
- Conduzir uma análise gerencial do “status operacional” de nossa infraestrutura interna;
- planejando melhorias no serviço com base nos relatórios coletados.
O único CMDB criado nos permite rastrear o status e o histórico de eventos em toda a infraestrutura como um todo e para cada componente individualmente.
Além disso, começamos a monitorar o status de serviços individuais, por exemplo, backups, ou seja, a correção das tarefas de backup. Se, por algum motivo, a tarefa falhar, o sistema registrará o incidente. Indica o servidor de backup, a tarefa em si e a máquina virtual - sabendo disso, podemos corrigi-lo rapidamente. Além disso, pelos serviços de monitoramento, podemos fornecer relatórios aos nossos clientes.

Abaixo, fornecemos uma captura de tela dos relatórios da Live Technologies.

Abaixo, você pode ver um relatório resumido sobre o número de incidentes agrupados por classe de unidades de configuração (KE) em termos do grau de influência na infraestrutura.

Resultados do sistema de monitoramento
O novo sistema de monitoramento já está operando ativamente e estamos prontos para compartilhar com você os resultados de seu trabalho e nossas próprias observações.
No momento, conseguimos restaurar completamente o monitoramento da infraestrutura do IT-GRAD e nos livrar da geração de incidentes falsos. O serviço para clientes está sendo testado e estará disponível em breve. No futuro, planejamos concluir a integração de infraestruturas conectando 1cloud e #CloudMTS a um único sistema de monitoramento IT-GRAD.
 Anteriormente,
Anteriormente, quando um gatilho de alerta era acionado, era gerado um incidente no suporte de 1 linha. O oficial de serviço a processou e notificou o cliente por telefone ou e-mail.
Agora tudo funciona de forma autônoma: quando o gatilho é acionado por 2 minutos, se necessário, o cliente é notificado automaticamente.
Vamos prestar um pouco de atenção em como os alertas funcionam.

No caso de uma alteração no estado do componente de TI, o sistema de monitoramento registra o evento no agregador de dados, que processa o evento através do corpo da carta e, dependendo do grau de criticidade do estado do componente especificado no alerta, gera uma solicitação, notificação ou incidente com a prioridade desejada. Além disso, o sistema, por meio do CMDB, determina a qual KE do cliente pertence e, de acordo com o modelo de integridade, ele alerta por email ou SMS. Além disso, no momento, um bot de telegrama especial para alertas está passando por um estágio de finalização e em breve estará disponível para todos os nossos clientes.

Agora, como parte do processo de monitoramento e controle de serviços, estamos monitorando o "estado de saúde" do ambiente de TI em funcionamento em tempo real, notificando automaticamente usuários externos e internos. O monitoramento do status da infraestrutura e dos serviços de TI, bem como dos dados coletados, permite que você tome ações proativas antes que algo dê errado.
Como você pode ver, o processo de construção de um sistema de monitoramento está repleto de armadilhas. No entanto, temos certeza de que, como resultado do trabalho conjunto de nossos engenheiros e analistas, obtivemos um excelente produto que resolve dois problemas de negócios de uma só vez: fornece monitoramento de alta qualidade e permite implementar o monitoramento como um serviço para os clientes.