Infa será útil para desenvolvedores de JS que desejam entender profundamente a essência de trabalhar com Node.js e Event Loop. Você pode controlar de forma consciente e flexível o fluxo do programa (servidor da web).
Compilei este artigo com base no meu relatório recente para colegas.
No final do artigo, existem materiais úteis para estudo independente.
Como é o Node.js. Recursos assíncronos
Vejamos este código: ele demonstra perfeitamente a sincronização da execução do código no Node.js. Uma solicitação é feita em algum lugar no GitHub, em seguida, um arquivo é lido e o resultado é exibido no console. O que está claro nesse código síncrono?
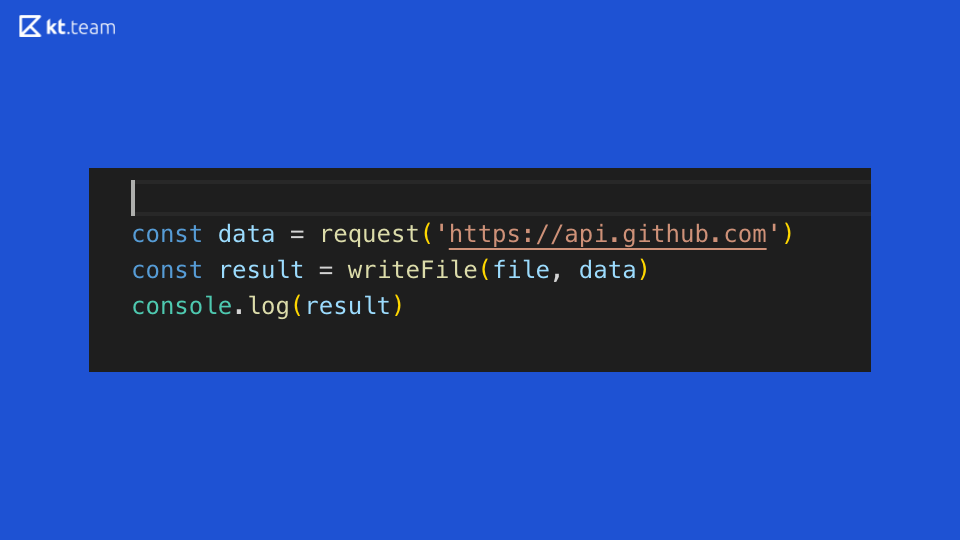
Suponha que este seja um servidor da web abstrato que execute operações em um roteador. Se uma solicitação de entrada chegar neste roteador, solicitamos mais, lemos o arquivo e o imprimimos no console. Consequentemente, o tempo gasto em solicitar e ler um arquivo, o servidor será bloqueado, não poderá processar outras solicitações de entrada nem realizará outras operações.
Quais são as opções para resolver este problema?
- Multithreading
- E / S sem bloqueio
Para a primeira opção (multithreading), há um bom exemplo com o servidor da web Apache vs Nginx.
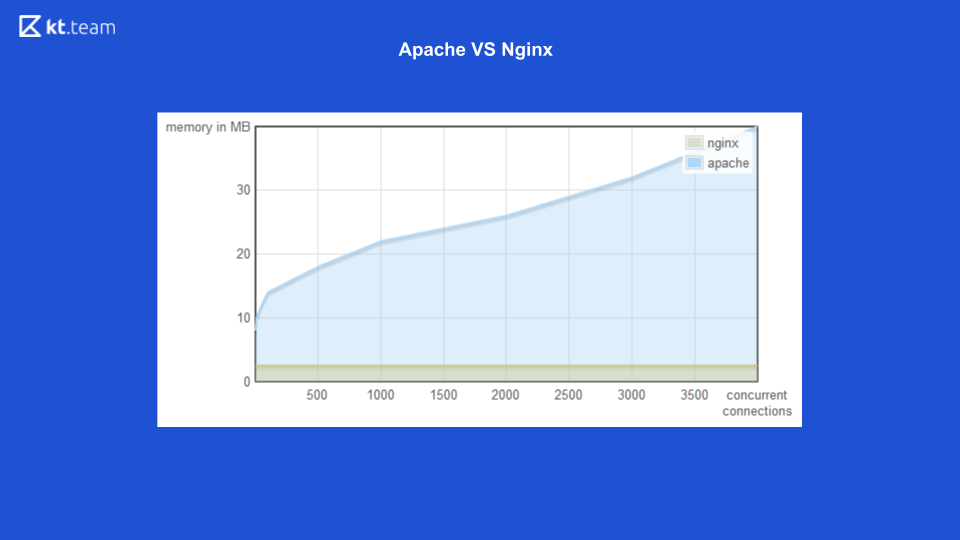
Anteriormente, o Apache gerava um fluxo para cada solicitação recebida: quantas solicitações havia, o mesmo número de threads. No momento, o Nginx tinha a vantagem de usar E / S sem bloqueio. Aqui você pode ver que, com um aumento no número de solicitações recebidas, a quantidade de memória consumida pelo Apache aumenta e, no próximo slide, o número de solicitações processadas por segundo com o número de conexões para o Nginx é maior.
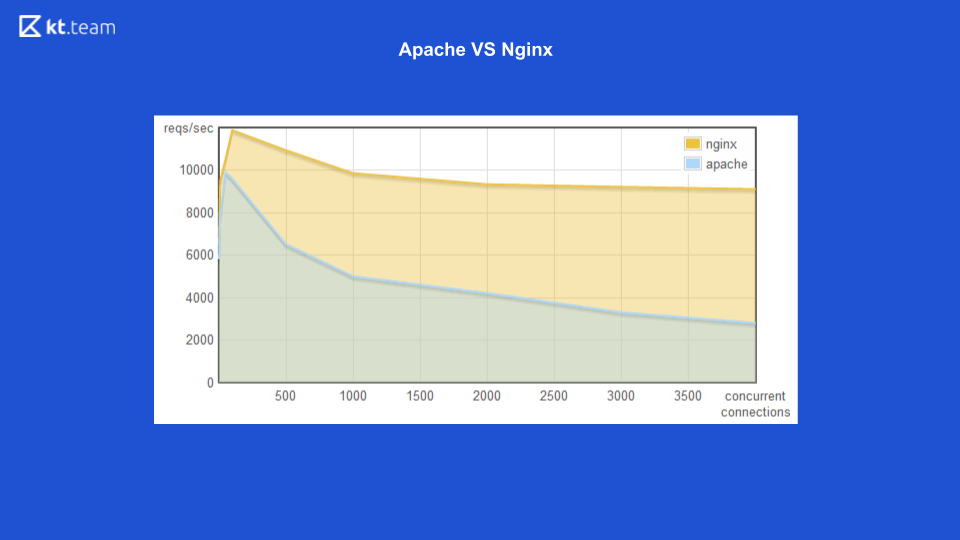
É claramente mostrado que a entrada / saída sem bloqueio é mais eficiente.
A entrada / saída sem bloqueio é possível graças aos sistemas operacionais modernos que fornecem esse mecanismo - um desmultiplexador de eventos.
Um desmultiplexador é um mecanismo que recebe uma solicitação de um aplicativo, registra e executa.
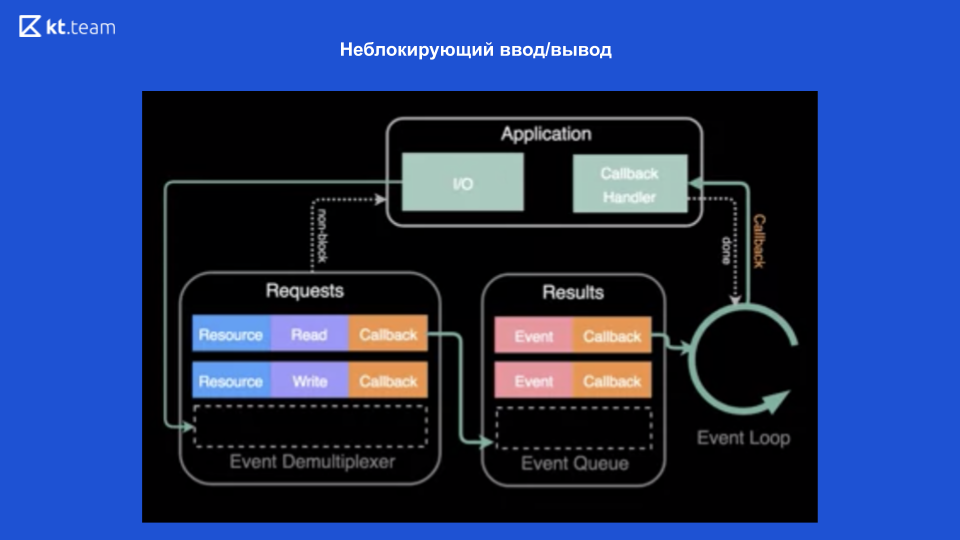
Na parte superior do diagrama, é visto que temos um aplicativo e as operações são executadas nele (seja lendo um arquivo). Para isso, é feita uma solicitação ao desmultiplexador de eventos, um recurso é enviado aqui (link para o arquivo), a operação desejada e o retorno de chamada. O desmultiplexador de eventos registra essa solicitação e retorna o controle diretamente ao aplicativo - portanto, não é bloqueado. Em seguida, ele executa operações no arquivo e, depois disso, quando o arquivo é lido, o retorno de chamada é registrado na fila de execução. Em seguida, o loop de eventos processa gradualmente de forma síncrona cada retorno de chamada dessa fila. E, consequentemente, retorna o resultado ao aplicativo. Além disso (se necessário), tudo é feito novamente.
Assim, graças a essa E / S sem bloqueio, o Node.js pode ser assíncrono.
Esclarecemos que, nesse caso, é o sistema operacional que nos fornece entrada / saída sem bloqueio. Para entrada / saída sem bloqueio (geralmente, em princípio, para operações de entrada / saída), incluímos solicitações de rede e trabalhamos com arquivos.
Esse é o conceito geral de E / S sem bloqueio. Quando surgiu a oportunidade, Ryan Dahl, desenvolvedor do Node.js., foi inspirado pela experiência do Nginx, que usava E / S sem bloqueio, e decidiu criar uma plataforma específica para desenvolvedores. A primeira coisa que ele precisava fazer era "fazer amigos" em sua plataforma com um desmultiplexador de eventos. O problema era que o desmultiplexador era implementado de maneira diferente em cada sistema operacional e ele precisava escrever um wrapper, que mais tarde ficou conhecido como libuv. Esta é uma biblioteca escrita em C. Ele fornece uma interface única para trabalhar com esses desmultiplexadores de eventos.
Recursos da biblioteca Libuv
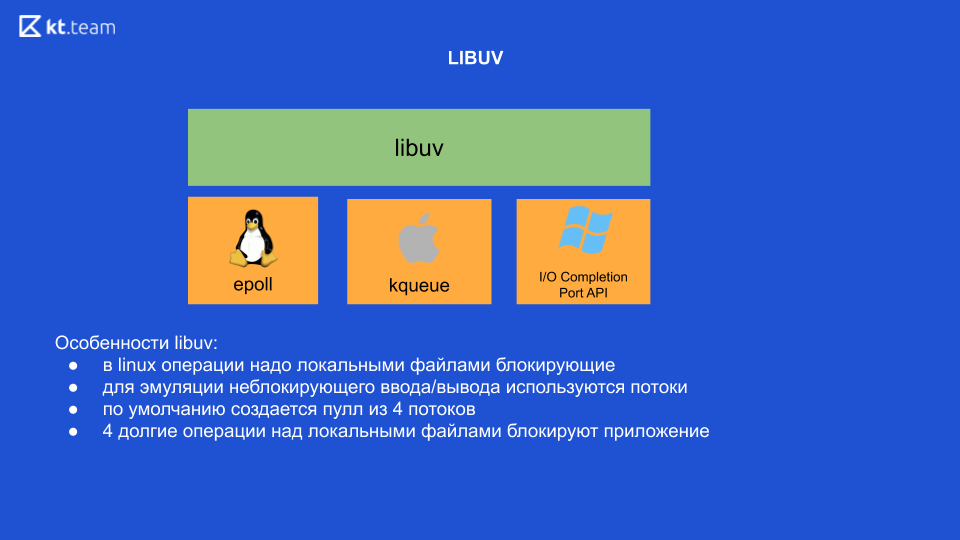
No Linux, em princípio, no momento, todas as operações com arquivos locais estão bloqueando. Ou seja, parece que há entrada / saída sem bloqueio, mas é precisamente ao trabalhar com arquivos locais que a operação ainda está bloqueando. É por isso que o libuv usa threads internamente para emular E / S sem bloqueio. Quatro threads surgem da caixa e aqui precisamos tirar a conclusão mais importante: se executarmos 4 operações pesadas em arquivos locais, bloquearemos todo o aplicativo (é no Linux, outros sistemas operacionais não).
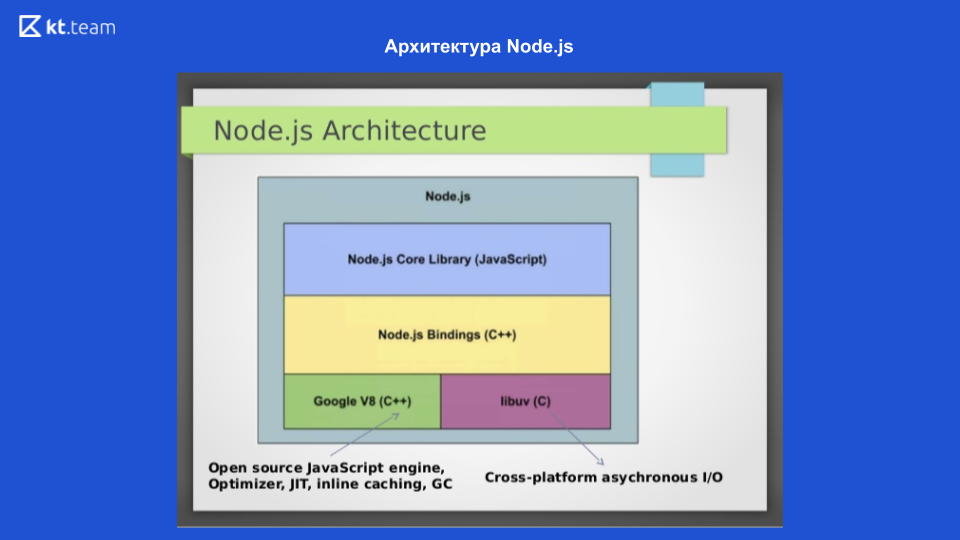
Neste slide, vemos a arquitetura do Node.js. Para interagir com o sistema operacional, a biblioteca libuv escrita em C é usada; Para compilar o código JavaScript no código da máquina, é usado o mecanismo do Google V8, há também uma biblioteca Node.jb Core, que contém módulos para trabalhar com solicitações de rede, um sistema de arquivos e um módulo para registro. Que tudo isso interagiu, as Ligações do Node.js são gravadas. Esses 4 componentes compõem a estrutura do Node.js. O próprio mecanismo de loop de eventos está em libuv.
Loop de eventos
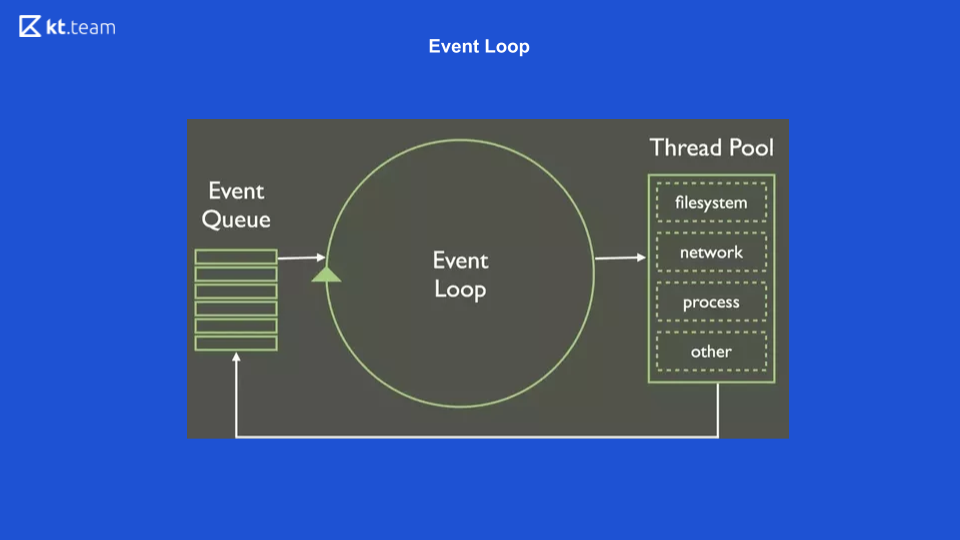
Esta é a representação mais simples da aparência do Event Loop. Há uma certa fila de eventos, há um ciclo interminável de eventos que executa operações de forma síncrona a partir da fila e as distribui ainda mais.
Este slide mostra como o Loop de Eventos fica diretamente no Node.js.
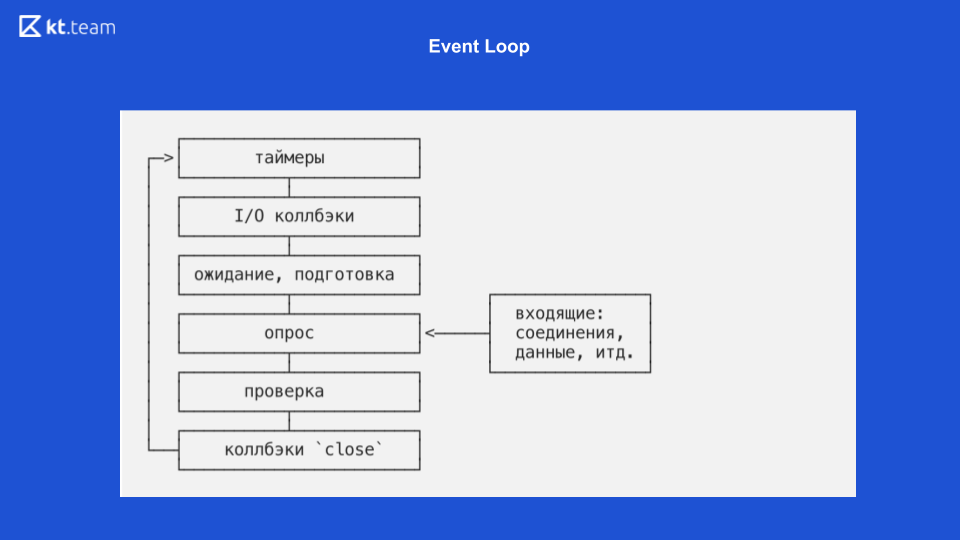
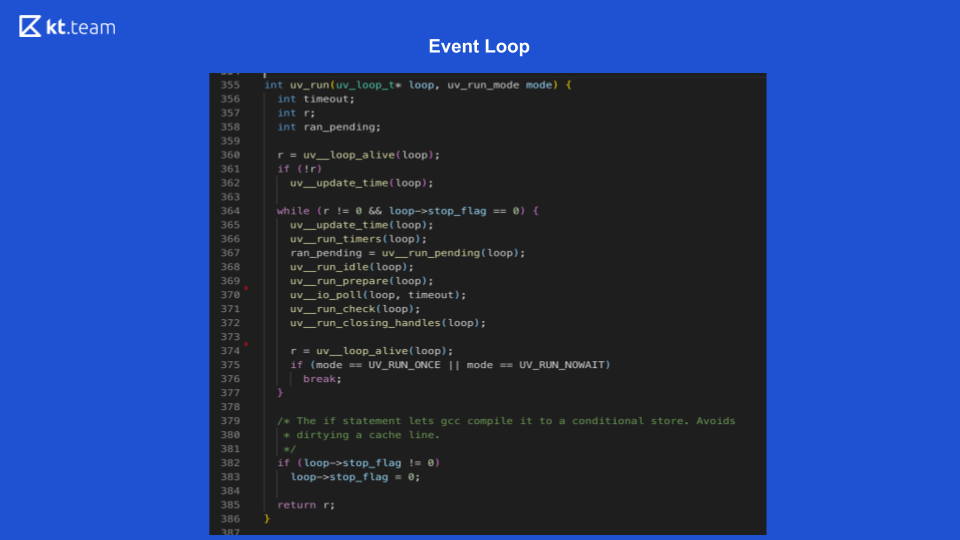
Lá, a implementação é mais interessante e mais complicada. Essencialmente, um loop de eventos é um loop de eventos e é infinito desde que haja algo a ser feito. O loop de eventos no Node.js é dividido em várias fases. (As fases do slide 8 devem ser comparadas com o código-fonte do slide 9.)
Fase 1 - Temporizadores
Essa fase é realizada diretamente pelo Event Loop. (Trecho de código com uv_update_time) - aqui o horário em que o loop de eventos começou a funcionar é simplesmente atualizado.
uv_run_timers - nesse método, a próxima ação do timer é executada. Há uma certa pilha, mais precisamente, um monte de cronômetros, que é essencialmente o mesmo da fila em que os cronômetros estão localizados. O cronômetro com o menor tempo é obtido, comparado com o horário atual do loop de eventos e, se estiver na hora de executar esse cronômetro, seu retorno de chamada é executado. Vale a pena notar aqui que o Node.js possui uma implementação de setTimeout e existe setInterval. Para libuv, isso é essencialmente a mesma coisa, apenas setInterval ainda tem um sinalizador de repetição.
Portanto, se esse cronômetro tiver um sinalizador de repetição, ele será novamente colocado na fila de eventos e processado da mesma maneira.
Fase 2 - retornos de chamada de E / S
Aqui, precisamos retornar ao diagrama sobre entrada / saída sem bloqueio.
Quando o desmultiplexador de eventos lê um arquivo e coloca na fila o retorno de chamada, ele apenas corresponde ao estágio de retorno de chamada de E / S. Aqui, os retornos de chamada são realizados para entrada / saída sem bloqueio, ou seja, essas são exatamente as funções usadas após uma solicitação para um banco de dados ou outro recurso ou para ler / gravar um arquivo. Eles são realizados precisamente nesta fase.
No slide 9, a execução da função de retorno de chamada de E / S inicia a linha 367: ran_pending = uv_run_pending (loop).
Fase 3 - espera, preparação
Essas são operações internas para retornos de chamada, de fato, não podemos influenciar a fase, apenas indiretamente. Existe um processo.nextTick, seu retorno de chamada pode ser inadvertidamente executado na fase de preparação em espera. process.nextTick é executado na fase atual, ou seja, process.nextTick pode funcionar em absolutamente qualquer fase. Não há ferramenta pronta para executar o código na fase "aguardando, preparando" no Node.js.
No slide 9, as linhas 368, 369 correspondem a esta fase:
uv_run_idle (loop) - aguarde;
uv_run_prepare (loop) - preparação.
Fase 4 - pesquisa
É aqui que todo o código que escrevemos em JS é executado. Inicialmente, todas as solicitações que fazemos chegam aqui e é aqui que o Node.js pode ser bloqueado. Se qualquer operação de computação pesada chegar aqui, nesse estágio, nosso aplicativo poderá congelar e aguardar até que essa operação seja concluída.
No slide 9, a função de pesquisa está na linha 370: uv_io_poll (loop, timeout).
5 fase - verificação
Há um timer setImmediate no Node.js, seus retornos de chamada são executados nesta fase.
No código fonte, esta é a linha 371: uv_run_check (loop).
6 fases (última) - eventos de retorno de chamada fechados
Por exemplo, um soquete da web precisa fechar a conexão; nessa fase, um retorno de chamada desse evento será chamado.
No código fonte, esta é a linha 372: uv_run_closing_handless (loop).
E, no final, o Event Loop Node.js é o seguinte
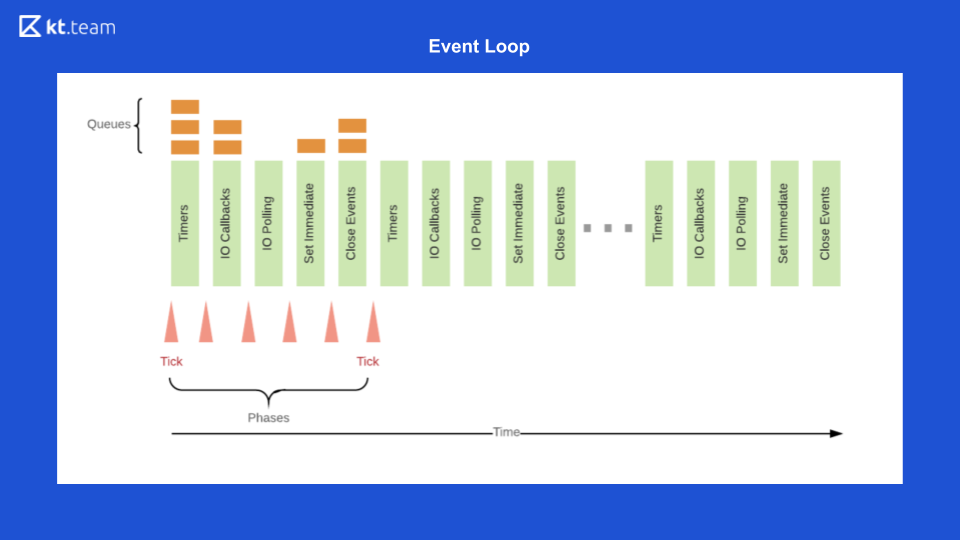
Primeiro, na fila do cronômetro, o cronômetro é executado, cujo período se aproxima.
Em seguida, os retornos de chamada de E / S são executados.
Em seguida, o código é a base, depois setImmediate e os eventos de fechamento.
Depois disso, tudo se repete em um círculo. Para demonstrar isso, vou abrir o código. Como será realizado?
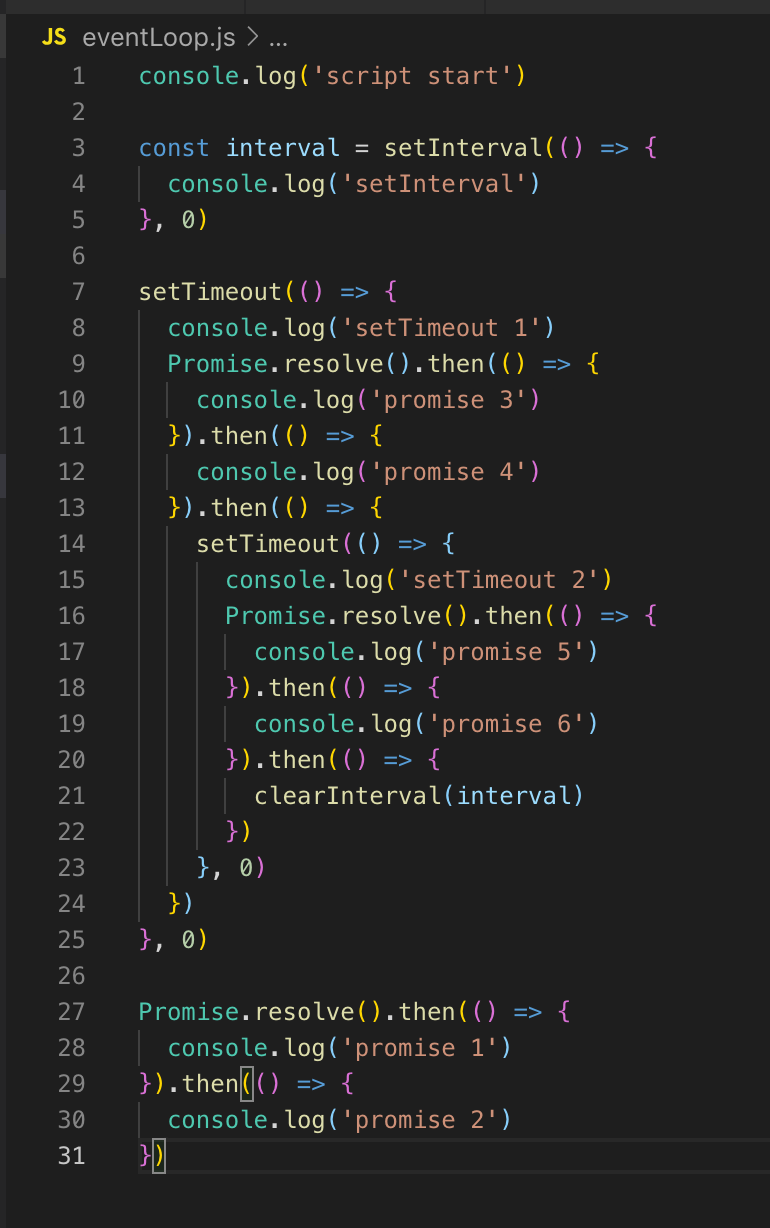
Como não temos temporizadores na linha, o loop de eventos continua. Também não há retorno de chamada de E / S, portanto, imediatamente entramos na fase de pesquisa. Todo o código que está aqui é executado inicialmente na fase de pesquisa. Portanto, primeiro imprimimos script_start, setInterval é colocado na fila do timer (não executado, apenas colocado). setTimeout também é colocado na fila do cronômetro e, em seguida, as promessas são executadas: primeiro prometa 1 e depois prometa 2.
No próximo tick (loop de evento), retornamos ao estágio do timer, aqui na fila já existem 2 temporizadores: setInterval e setTimeout. Ambos estão com atraso 0, respectivamente, estão prontos para execução.
SetInterval é executado (saída para o console) e setTimeout 1. Não há retornos de chamada de E / S sem bloqueio, haverá uma fase de polling, a promessa 3 e a promessa 4 são exibidas no console.
Em seguida, o temporizador setTimeout é registrado. Isso encerra o tick, passa para o próximo tick. Existem temporizadores novamente, a saída para o console é setInterval e setTimeout 2, depois a promessa 5 e a promessa 6 são exibidas.
Analisamos o Event Loop e agora podemos falar com mais detalhes sobre multithreading.
Threading - módulo worker_threads
O encadeamento apareceu no Node.js, graças ao módulo worker_threads na versão 10.5. E na 10ª versão, foi lançada exclusivamente com a chave - experimental-worker, e a partir da 11ª versão foi possível iniciar sem ela.
O Node.js também possui um módulo de cluster, mas não gera threads - gera vários outros processos. Escalabilidade de aplicativos é seu objetivo principal.
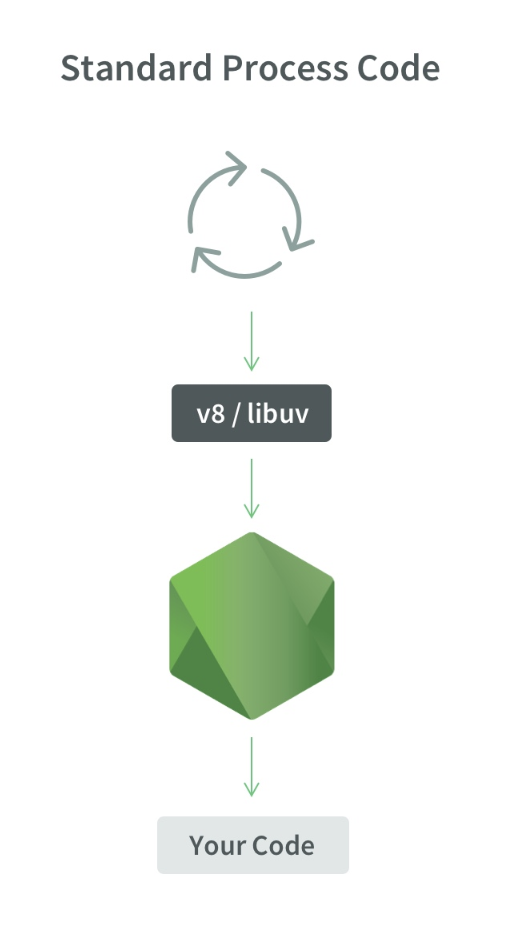
Como é o processo 1:
1 processo Node.js, 1 encadeamento, 1 loop de evento, 1 mecanismo V8 e libuv.
Se iniciarmos os threads X, ficará assim:
1 processo Node.js, X threads, X Event Loops, mecanismos X V8 e X libuv.
Esquematicamente, tem a seguinte aparência
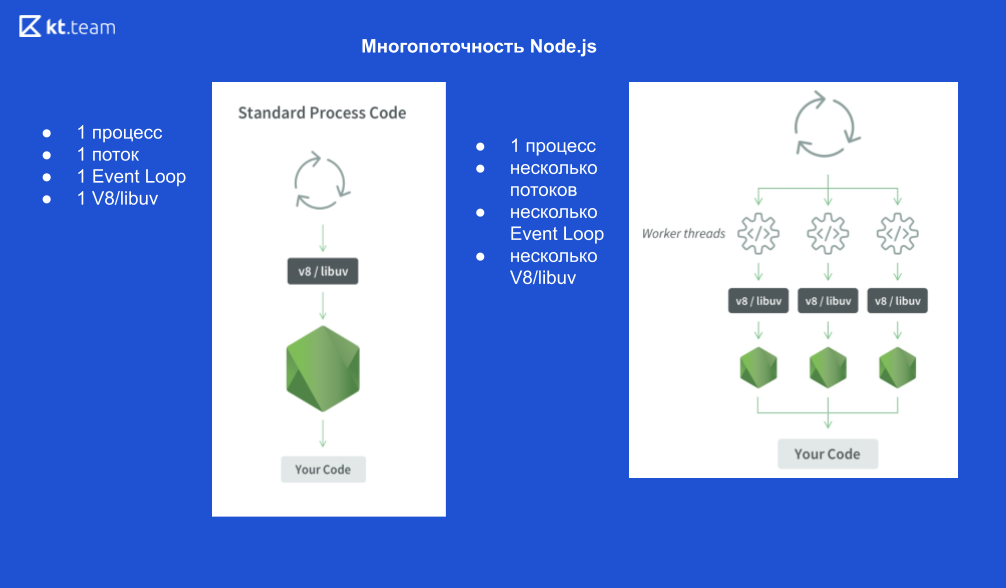
Vamos dar um exemplo.
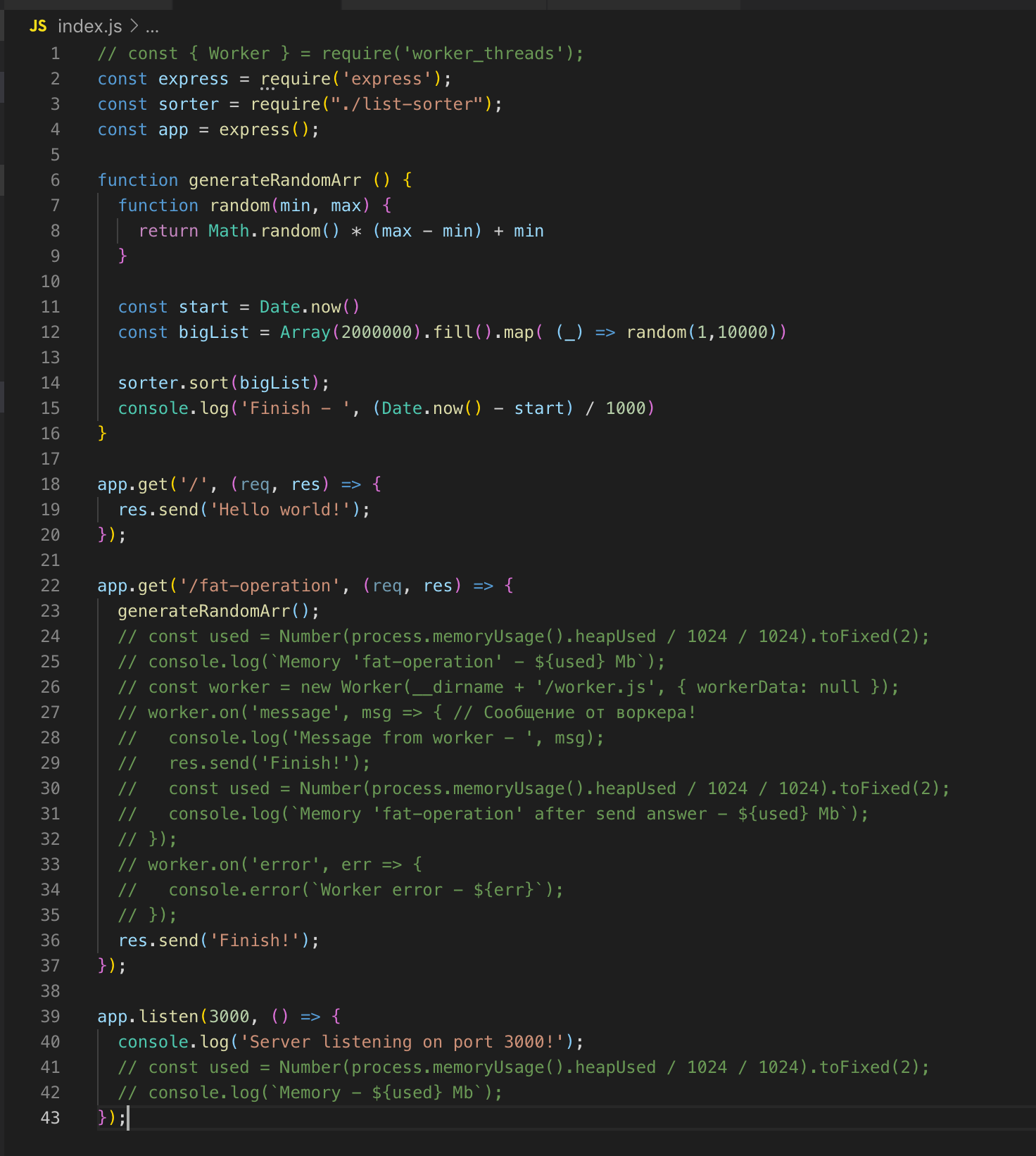
O servidor da Web mais simples no Express. Existem 2 rotas'a - / e / operação de gordura.
Há também uma função generateRandomArr (). Ela preenche a matriz com dois milhões de registros e os classifica. Vamos iniciar o servidor.
Nós fazemos um pedido para / fat-operation. E naquele momento em que a operação de classificação da matriz é executada, enviamos outra solicitação para rotear /, mas para obter a resposta, precisamos esperar até que a matriz seja classificada. Esta é uma implementação clássica de thread único. Agora conectamos o módulo worker_threads.
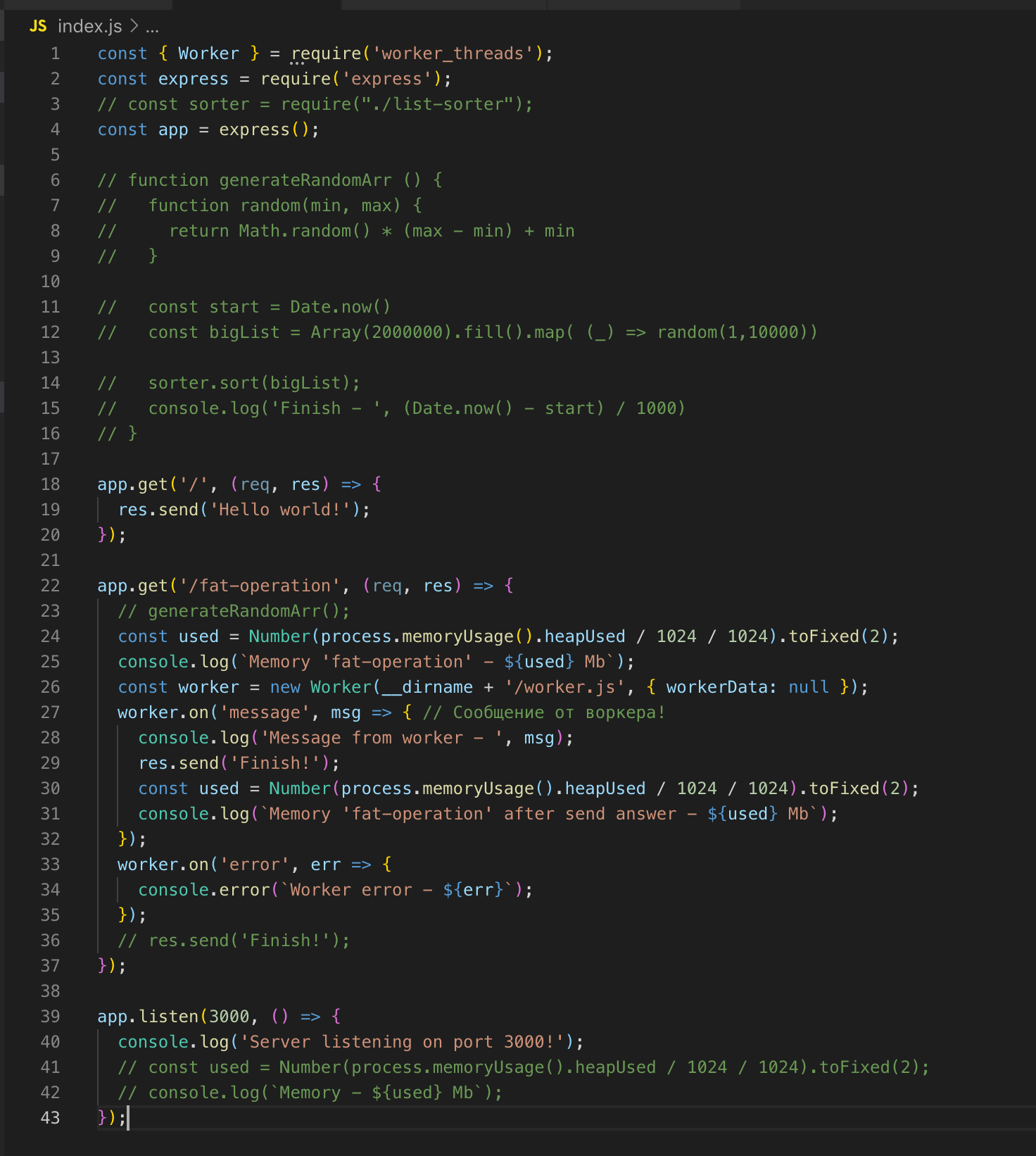
Nós fazemos um pedido para / fat-operation e então - para /, do qual obtemos imediatamente a resposta - Olá, mundo!
Para a operação de classificação da matriz, criamos um thread separado que possui sua própria instância do Event Loop, e isso não afeta a execução do código no thread principal.
Um encadeamento será "destruído" quando não tiver operações para executar.
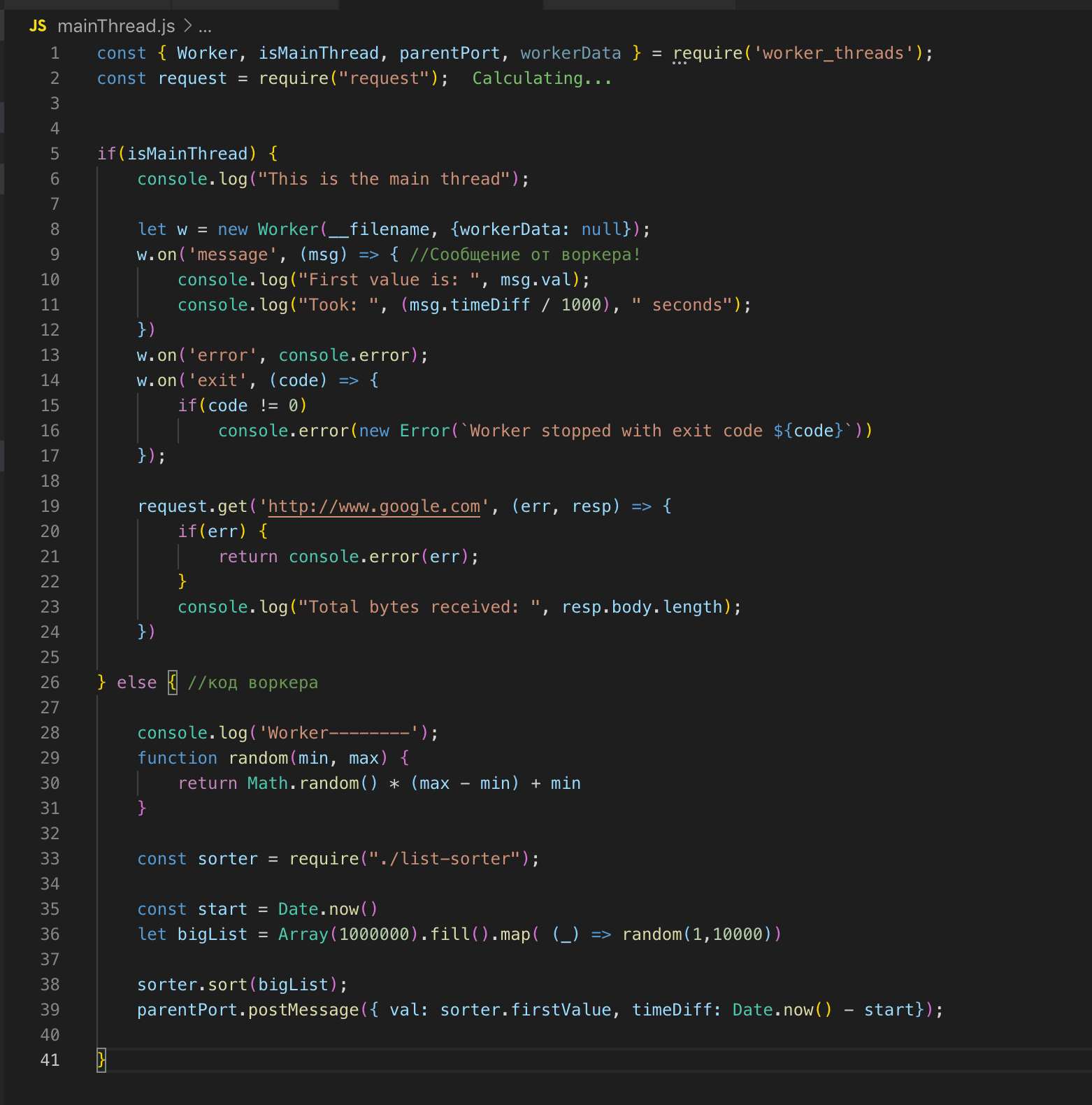
Nós olhamos para o código fonte. Registramos o trabalhador na linha 26 e, se necessário, passamos os dados para ele. Nesse caso, não estou transmitindo nada. E então assinamos eventos: um erro e uma mensagem. No trabalhador, a função é chamada, uma matriz de dois milhões de registros é classificada. Assim que é ordenado, enviamos o resultado para o fluxo principal ok através de post_message.
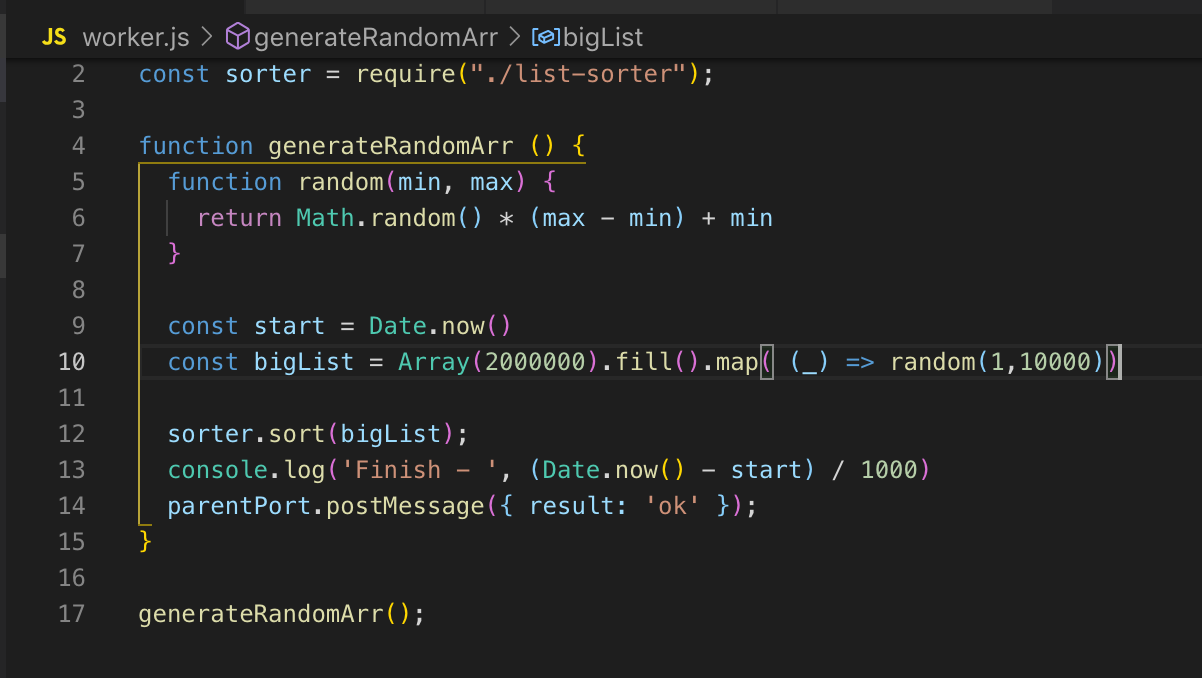
No thread principal, captamos essa mensagem e enviamos o resultado para finalizar. O trabalhador e o thread principal têm memória comum, portanto, temos acesso a variáveis globais de todo o processo. Quando transferimos dados do fluxo principal para o worker, o worker recebe apenas uma cópia.
Podemos descrever o fluxo principal e o fluxo de trabalho em um arquivo. O módulo worker_threads fornece uma API através da qual podemos determinar em qual thread o código está executando no momento.
Compartilho links para recursos úteis e um link para a apresentação de Ryan Dahl quando ele apresentou o Event Loop (interessante ver).
Loop de eventos
- Tradução de um artigo da documentação do Node.js.
- https://blog.risingstack.com/node-js-at-scale-understanding-node-js-event-loop/
- https://habr.com/en/post/336498/
Worker_threads
- https://nodejs.org/api/worker_threads.html#worker_threads_worker_workerdata - API
- https://habr.com/ru/company/ruvds/blog/415659/
- https://nodesource.com/blog/worker-threads-nodejs/
- Slides originais da apresentação de Ryan Dahl (por VPN)