Parte um, suplementada.
Cotans, oi.
Eu sou Sasha e me entrego a neurônios.
A pedido dos trabalhadores, finalmente reuni meus pensamentos e decidi dividir uma série de instruções curtas e quase passo a passo.
Instruções sobre como treinar e implantar sua rede neural do zero, ao mesmo tempo fazendo amizade com o bot de telegrama.
Instruções para bonecos como eu.
Hoje vamos escolher a arquitetura de nossa rede neural, testá-la e coletar nosso primeiro conjunto de dados de treinamento.
Escolha da arquitetura
Após o lançamento relativamente bem-sucedido do
selfie2anime bot (usando o modelo
UGATIT pronto), eu queria fazer o mesmo, mas o meu. Por exemplo, um modelo que transforma suas fotos em quadrinhos.
Aqui estão alguns exemplos do meu
photo2comicsbot , e faremos algo semelhante.



Como o modelo
UGATIT era muito pesado para minha placa de vídeo,
chamei a atenção para uma analogia mais antiga, mas menos voraz -
CycleGANNesta implementação, existem várias arquiteturas de modelo e uma exibição visual conveniente do processo de aprendizado no navegador.
O CycleGAN, como
arquiteturas para transferir estilos em uma única imagem, não requer imagens emparelhadas para treinamento. Isso é importante, porque, caso contrário, teríamos que redesenhar todas as fotos em quadrinhos para criar um conjunto de treinamento.
A tarefa que definiremos para o nosso algoritmo consiste em duas partes.
Na saída, devemos ter uma imagem que:
a) semelhante a uma história em quadrinhos
b) semelhante à imagem original
O ponto “a” pode ser implementado usando o GAN usual, onde o Crítico treinado será responsável por “parecer com quadrinhos”.
Mais sobre GAN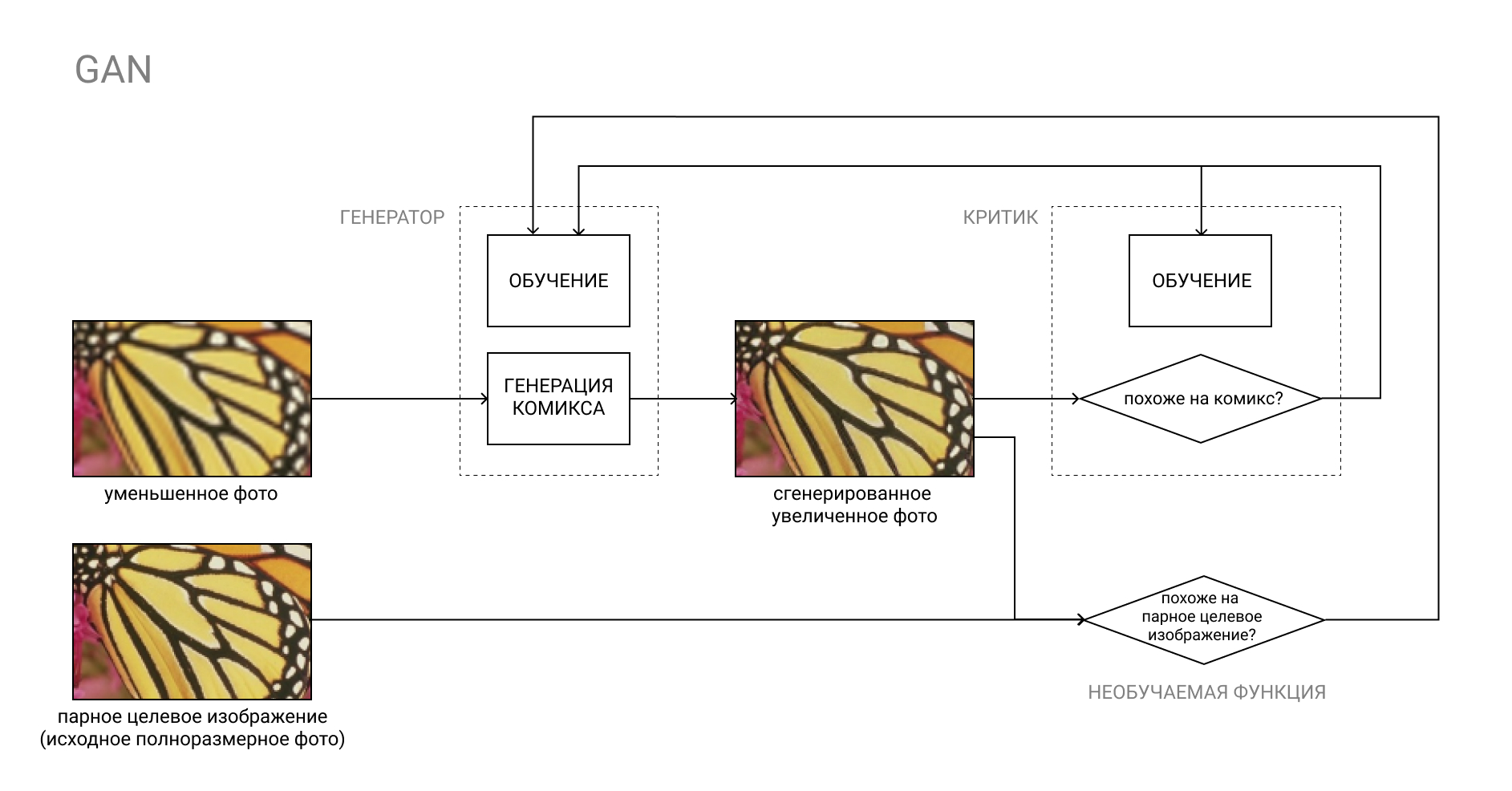
A GAN, ou Rede Adversária Generativa, é um par de duas redes neurais: Gerador e Crítico.
O gerador converte a entrada, por exemplo, de uma foto em uma história em quadrinhos, e o crítico compara o resultado "falso" resultante com uma história em quadrinhos real. O trabalho do gerador é enganar o crítico e vice-versa.
No processo de aprendizagem, o Gerador aprende a criar quadrinhos cada vez mais semelhantes aos reais, e o Crítico aprende a distinguir melhor entre eles.
A segunda parte é um pouco mais complicada. Se tivéssemos fotos emparelhadas, onde haveria fotografias no conjunto “A” e no conjunto “B”, elas foram redesenhadas em quadrinhos (ou seja, o que queremos obter do modelo), poderíamos apenas para comparar o resultado produzido pelo gerador com a imagem emparelhada do conjunto "B" do nosso conjunto de treinamento.
No nosso caso, os conjuntos “A” e “B” não estão de forma alguma conectados um ao outro. No conjunto “A” - fotos aleatórias, no conjunto “B” - quadrinhos aleatórios.
Não faz sentido comparar uma história em quadrinhos falsa com outra história aleatória do conjunto “B”, pois isso duplicará a função do Crítico, sem mencionar o resultado imprevisível.
É aqui que a arquitetura CycleGAN vem em socorro.
Em suma, este é um par GAN, o primeiro deles converte a imagem da categoria "A" (por exemplo, uma foto) para a categoria "B" (por exemplo, uma história em quadrinhos) e o segundo, da categoria "B" para a categoria "A".
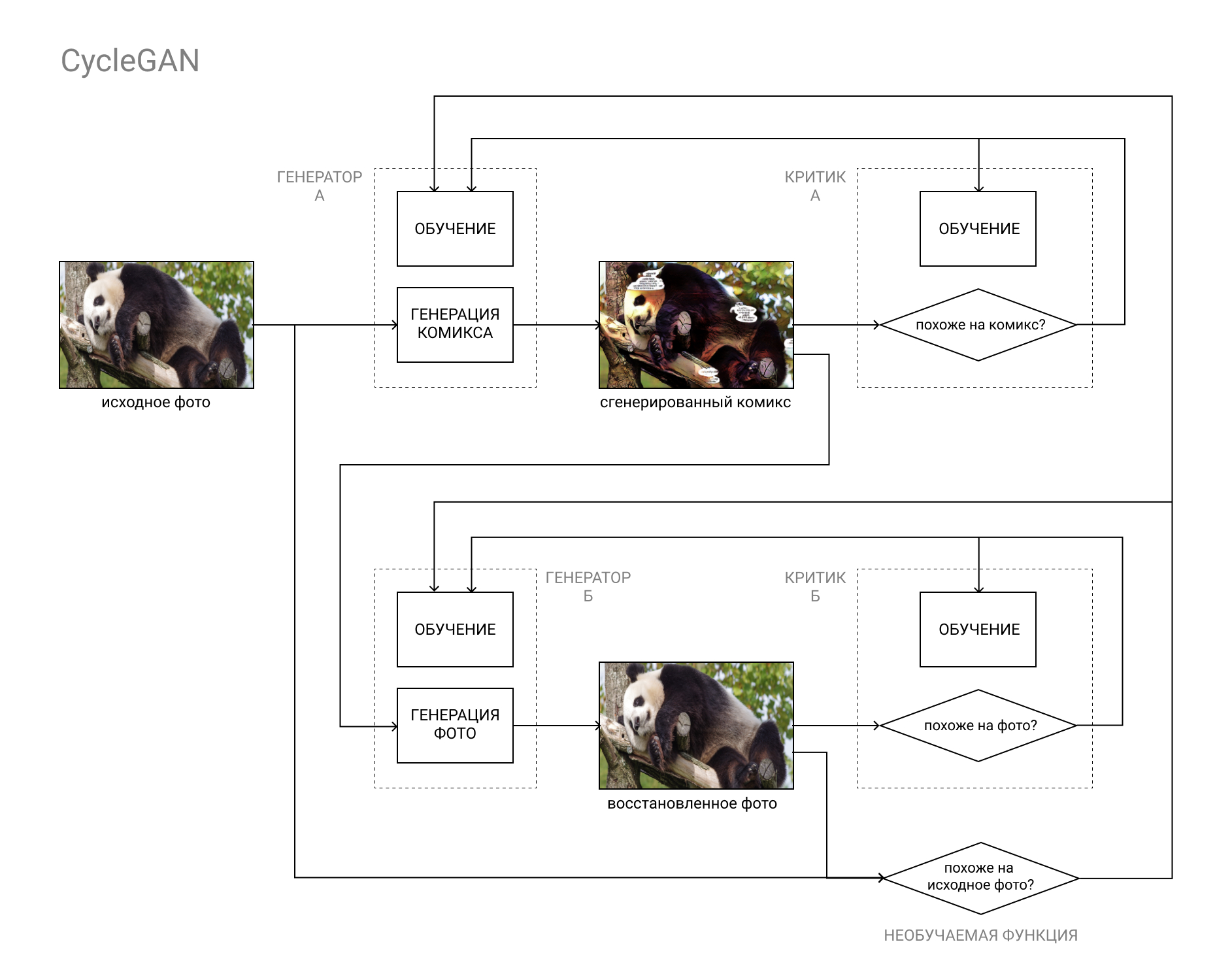
Os modelos são treinados com base na comparação da foto original com a restaurada (como resultado do ciclo "A" - "B" - "A", "foto-história em quadrinhos) e nos dados dos críticos, como em uma GAN comum.
Isso torna possível concluir as duas partes de nossa tarefa: gerar uma história em quadrinhos que não se distingue dos outros quadrinhos e que ao mesmo tempo se assemelha à foto original.
Instalação e verificação do modelo
Para implementar nosso plano astuto, precisamos:
- Placa gráfica habilitada para CUDA com 8 GB de RAM
- SO Linux
- Miniconda / Anaconda com Python 3.5 ou superior
Placas de vídeo com menos de 8 GB de RAM também podem funcionar se você conjurar com as configurações. Também funcionará no Windows, mas, mais lentamente, tive uma diferença de pelo menos 1,5 a 2 vezes.
Se você não possui uma GPU com suporte CUDA ou está com preguiça de configurar tudo, sempre pode usar o Google Colab. Se houver um número suficiente de pessoas que desejam, eu preencherei o tutorial e como iniciar todos os itens a seguir em uma nuvem do Google.Miniconda pode ser tomada aquiInstruções de instalaçãoApós instalar o Anaconda / Miniconda (a seguir denominado conda), crie um novo ambiente para nossos experimentos e ative-o:
(Os usuários do Windows precisam iniciar o Anaconda Prompt primeiro no menu Iniciar)conda create --name cyclegan conda activate cyclegan
Agora todos os pacotes serão instalados no ambiente ativo sem afetar o restante do ambiente. Isso é conveniente se você precisar de certas combinações de versões de vários pacotes, por exemplo, se usar o código antigo de outra pessoa e precisar instalar pacotes obsoletos sem prejudicar sua vida e seu ambiente de trabalho principal.
Em seguida, basta seguir as instruções README.MD da distribuição:
Salve a distribuição CycleGAN:
(ou faça o download do arquivo no GitHub) git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-and-pix2pix
Instale os pacotes necessários:
conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing conda install pytorch torchvision -c pytorch conda install visdom dominate -c conda-forge
Faça o download do conjunto de dados concluído e do modelo correspondente:
bash ./datasets/download_cyclegan_dataset.sh horse2zebra bash ./scripts/download_cyclegan_model.sh horse2zebra
Preste atenção em quais fotos estão no conjunto de dados baixado.
Se você abrir os arquivos de script do parágrafo anterior, poderá ver que existem outros conjuntos de dados e modelos prontos para eles.
Por fim, teste o modelo no conjunto de dados baixado:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
Os resultados serão salvos na pasta / results / horse2zebra_pretrained /
Criando um conjunto de treinamento
Uma etapa igualmente importante após escolher a arquitetura do modelo futuro (e procurar uma implementação concluída no github) é compilar um conjunto de dados, ou um conjunto de dados, no qual iremos treinar e testar nosso modelo.
Quase tudo depende dos dados que usamos. Por exemplo, UGATIT para o bot selfie2anime foi treinado em selfies femininas e rostos femininos de anime. Portanto, com fotos masculinas, ela se comporta pelo menos engraçada, substituindo homens barbudos brutais por meninas de gola alta. Na foto, seu humilde servo depois que ele descobriu que estava assistindo um anime.

Como você já entendeu, vale a pena selecionar as fotos / quadrinhos que você deseja usar na entrada e obter a saída. Você está planejando processar selfies - adicione selfies e close-ups de rostos de quadrinhos, fotos de prédios - adicione fotos de prédios e páginas de quadrinhos com prédios.
Como exemplo de fotos, usei o
DIV2K e o
Urban100 , com fotos de estrelas do Google para aumentar a diversidade.
Peguei quadrinhos do universo Marvel, a página inteira, lançando anúncios e anúncios onde a imagem não parece uma história em quadrinhos. Não consigo anexar o link por razões óbvias, mas, a pedido da Marvel Comics, você pode encontrar facilmente opções digitalizadas em seus sites favoritos com quadrinhos, se é que me entende.
É importante prestar atenção ao desenho, que difere em diferentes séries e o esquema de cores.

Eu tinha muito deadpool e homem aranha, então a pele fica muito vermelha.
Uma lista incompleta de outros conjuntos de dados públicos pode ser encontrada
aqui .
A estrutura de pastas em nosso conjunto de dados deve ser a seguinte:
selfie2comics
├── trainA
├── trainB
Test── testA
└── testB
trainA - nossas fotos (cerca de 1000pcs)
testA - algumas fotos para testes de modelo (30pcs será suficiente)
trainB - nossos quadrinhos (cerca de 1000 peças).
testB - quadrinhos para testes (30pcs.)
É desejável colocar o conjunto de dados em um SSD, se possível.
Isso é tudo por hoje. Na próxima edição, começaremos a treinar o modelo e obter os primeiros resultados!
Certifique-se de escrever se algo der errado com você, isso ajudará a melhorar a liderança e aliviar o sofrimento dos leitores subsequentes.
Se você já tentou treinar o modelo, sinta-se à vontade para compartilhar os resultados nos comentários. Até breve!
⇨ Próxima parte