Por tipo de atividade, é preciso lidar com situações em que um desenvolvedor escreve uma solicitação e pensa "a
base é inteligente, pode lidar com tudo! "
Em alguns casos (em parte por desconhecimento dos recursos do banco de dados, em parte por otimizações prematuras), essa abordagem leva ao aparecimento de "Frankenstein".
Primeiro, darei um exemplo dessa consulta:
Para avaliar objetivamente a qualidade da solicitação, vamos criar alguns conjuntos de dados arbitrários:
CREATE TABLE tbl AS SELECT (random() * 1000)::integer key_a , (random() * 1000)::integer key_b , (random() * 10000)::integer fld1 , (random() * 10000)::integer fld2 FROM generate_series(1, 10000); CREATE INDEX ON tbl(key_a, key_b);
Acontece que a
leitura dos dados em si
levou menos de um quarto do tempo total de execução da consulta:
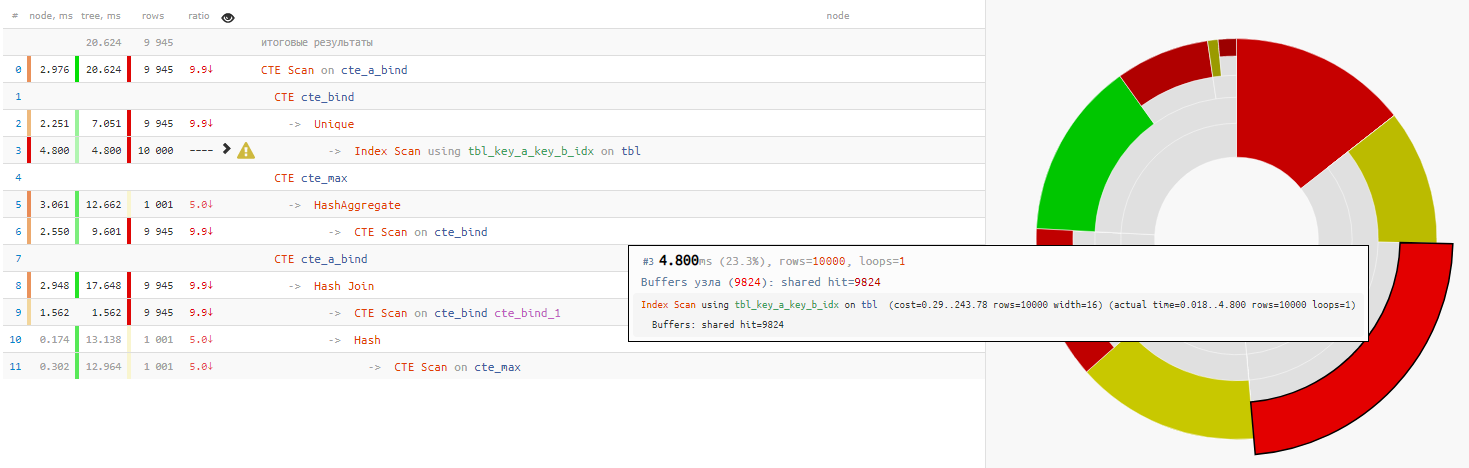 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]Desmonte pelos ossos
Examinaremos atentamente a solicitação e ficaremos confusos:
- Por que o WITH RECURSIVE está aqui, se não há CTEs recursivas?
- Por que agrupar valores mín. / Máx. Em um CTE separado, se eles ainda estão anexados à amostra original?
+ 25% do tempo - Por que, no final, usar releituras do CTE anterior através do incondicional 'SELECT * FROM'?
+ 14% do tempo
Nesse caso, tivemos muita sorte que o Hash Join foi escolhido para a conexão, e não o Nested Loop, porque não receberíamos um único passe de CTE Scan, mas 10K!
um pouco sobre o CTE ScanAqui, devemos lembrar que o CTE Scan é um análogo do Seq Scan - ou seja, sem indexação, mas apenas uma pesquisa exaustiva, que exigiria 10K x 0,3ms = 3000ms para ciclos cte_max ou 1K x 1,5ms = 1500ms para ciclos cte_bind !
Na verdade, o que você queria obter como resultado?
Sim, geralmente é esse tipo de pergunta que ele visita em algum lugar no quinto minuto da análise de solicitações de "três andares".Queríamos que cada par de chaves exclusivo removesse o
mínimo / máximo do grupo por key_a .
Então, vamos usar as
funções da
janela para isso:
SELECT DISTINCT ON(key_a, key_b) key_a a , key_b b , max(fld1) OVER(w) bind_fld1 , min(fld2) OVER(w) bind_fld2 FROM tbl WINDOW w AS (PARTITION BY key_a);
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]Como a leitura de dados em ambas as versões leva cerca de 4-5ms igualmente, todo o nosso ganho de tempo de
-32% é uma
carga pura
removida da CPU base , se essa solicitação for realizada com bastante frequência.
Em geral, você não deve forçar a base a "usar desgaste redondo, rolo quadrado".