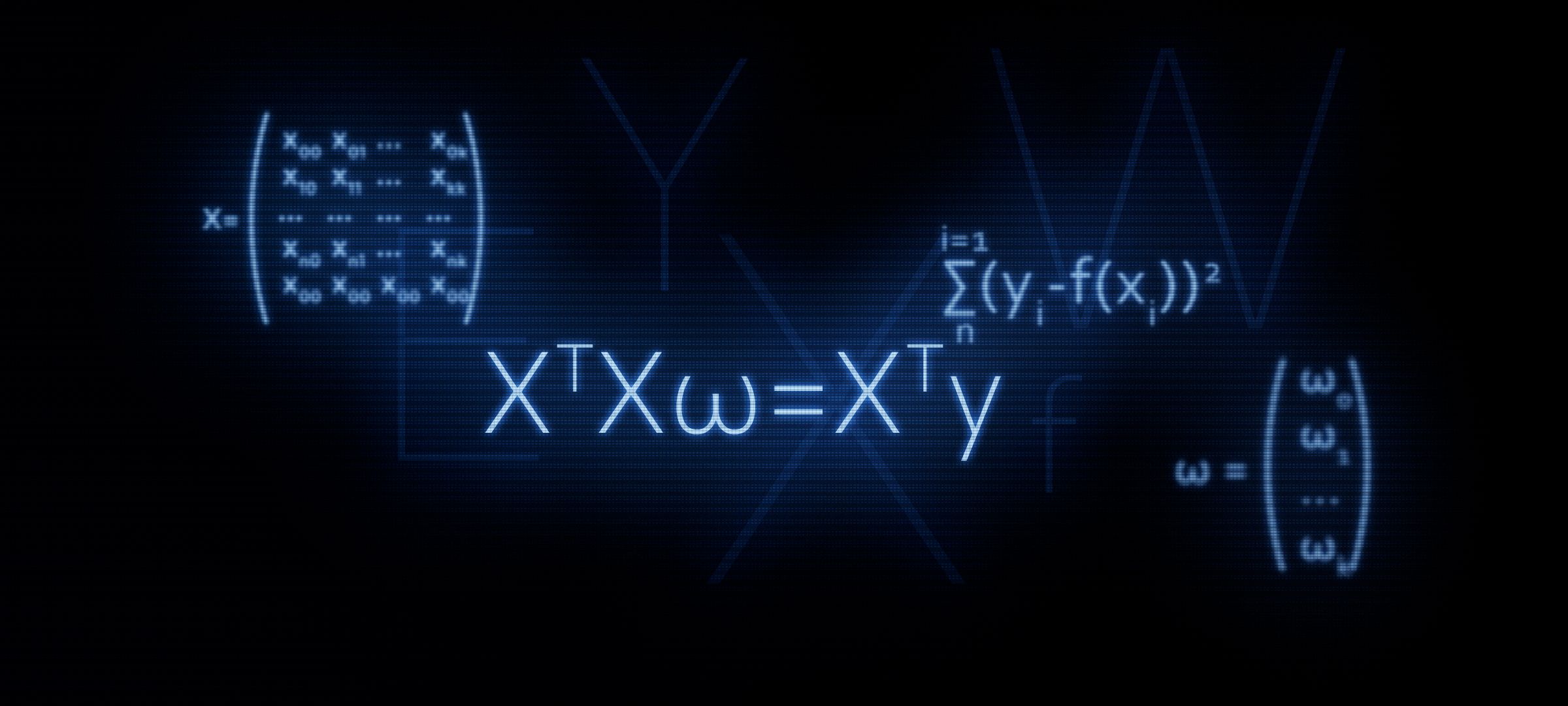
O objetivo do artigo é fornecer suporte a dataintists iniciantes. No
artigo anterior, examinamos nos dedos três métodos para resolver a equação de regressão linear: solução analítica, descida em gradiente, descida em gradiente estocástico. Em seguida, para a solução analítica, aplicamos a fórmula
XTX vecw=XT vecy . Neste artigo, como segue no título, justificaremos o uso dessa fórmula ou, em outras palavras, derivaremos independentemente.
Por que faz sentido prestar mais atenção à fórmula
XTX vecw=XT vecy ?
É com a equação da matriz que, na maioria dos casos, se inicia a regressão linear. Ao mesmo tempo, cálculos detalhados de como a fórmula foi derivada são raros.
Por exemplo, nos cursos de aprendizado de máquina Yandex, quando os alunos são introduzidos à regularização, eles sugerem o uso das funções da biblioteca
sklearn , enquanto nenhuma palavra é mencionada sobre a representação matricial do algoritmo. É nesse momento que alguns ouvintes podem querer entender esse problema com mais detalhes - escrever código sem usar funções prontas. E para isso, devemos primeiro apresentar a equação com o regularizador em forma de matriz. Este artigo permitirá que aqueles que desejam dominar essas habilidades. Vamos começar.
Linha de base
Metas
Temos vários valores-alvo. Por exemplo, a meta pode ser o preço de um ativo: petróleo, ouro, trigo, dólar etc. Ao mesmo tempo, por vários valores do indicador de objetivo, queremos dizer o número de observações. Tais observações podem ser, por exemplo, preços mensais do petróleo para o ano, ou seja, teremos 12 valores-alvo. Começamos a introduzir a notação. Designamos cada valor-alvo como
yi . Total que temos
n observações, o que significa que podemos imaginar nossas observações como
y1,y2,y3...yn .
Regressores
Assumimos que existem fatores que, em certa medida, explicam os valores do indicador de meta. Por exemplo, a taxa de câmbio do par dólar / rublo é fortemente influenciada pelo preço do petróleo, pela taxa do Fed etc. Esses fatores são chamados de regressores. Ao mesmo tempo, cada valor do indicador de meta deve corresponder ao valor do regressor, ou seja, se tivermos 12 metas para cada mês em 2018, também devemos ter 12 regressores para o mesmo período. Indique os valores de cada regressor por
xi:x1,x2,x3...xn . Deixe no nosso caso, existe
k regressores (ou seja,
k fatores que influenciam o valor do alvo). Portanto, nossos regressores podem ser representados da seguinte forma: para o primeiro regressor (por exemplo, o preço do petróleo):
x11,x12,x13...x1n , para o segundo regressor (por exemplo, a taxa do Fed):
x21,x22,x23...x2n para
k th "regressor:
xk1,xk2,xk3...xknDependência de alvos em regressores
Assumir dependência de destino
yi dos regressores "
i -a "observação pode ser expressa através da equação de regressão linear da forma:
f(w,xi)=w0+w1x1i+...+wkxki
onde
xi - "
i th "valor do regressor de 1 a
n ,
k - o número de regressores de 1 a
kw - coeficientes angulares que representam a quantidade pela qual o indicador de meta calculado mudará em média quando o regressor for alterado.
Em outras palavras, somos a favor de todos (exceto
w0 ) do regressor, determinamos o coeficiente "nosso"
w , multiplique os coeficientes pelos valores dos regressores "
i -ª "observação, como resultado, temos uma certa aproximação"
i th "alvo.
Portanto, precisamos selecionar esses coeficientes
w para os quais os valores da nossa função de aproximação
f(w,xi) será localizado o mais próximo possível dos valores dos alvos.
Estimativa da qualidade da função de aproximação
Determinaremos a estimativa de qualidade da função de aproximação pelo método dos mínimos quadrados. A função de avaliação da qualidade, neste caso, assumirá a seguinte forma:
Err= soma limitesni=1(yi−f(xi))2 rightarrowmin
Precisamos escolher esses valores dos coeficientes $ w $ para os quais o valor
Err será o menor.
Traduzimos a equação em forma de matriz
Vista vetorial
Primeiro, para facilitar sua vida, você deve prestar atenção à equação de regressão linear e observar que o primeiro coeficiente
w0 não multiplicado por nenhum regressor. Além disso, quando traduzimos os dados em forma de matriz, a circunstância acima complicará seriamente os cálculos. Nesse sentido, propõe-se a introdução de outro regressor para o primeiro coeficiente
w0 e igualar a um. Ou melhor, cada "
i o "valor" desse regressor para igualar a unidade - porque, quando multiplicado pela unidade, nada mudará em termos do resultado dos cálculos e, do ponto de vista das regras para o produto das matrizes, nosso tormento será reduzido significativamente.
Agora, por um tempo, para simplificar o material, suponha que tenhamos apenas um "
i th "observação. Então, imagine os valores dos regressores"
i th observação como um vetor
vecxi . Vetor
vecxi tem dimensão
(k vezes1) isso é
k linhas e 1 coluna:
vecxi= beginpmatrixx0ix1i...xki endpmatrix qquad
Os coeficientes desejados podem ser representados como um vetor
vecw tendo dimensão
(k vezes1) :
vecw= beginpmatrixw0w1...wk endpmatrix qquad
A equação de regressão linear para "
i -a "observação assumirá a forma:
f(w,xi)= vecxiT vecw
A função de avaliação da qualidade do modelo linear assumirá a forma:
Err= soma limitesni=1(yi− vecxiT vecw)2 rightarrowmin
Observe que, de acordo com as regras de multiplicação de matrizes, é necessário transpor o vetor
vecxi .
Representação matricial
Como resultado da multiplicação de vetores, obtemos o número:
(1 vezesk) pontocentral(k vezes1)=1 vezes1 como esperado. Este número é a aproximação "
i -ésimo "alvo. Mas precisamos aproximar não um valor do alvo, mas todos. Para fazer isso, escrevemos tudo"
i regressores matriciais
X . A matriz resultante tem a dimensão
(n vezesk) :
exibição $$ $$ X = \ begin {pmatrix} x_ {00} e x_ {01} e ... & x_ {0k} \\ x_ {10} e x_ {11} e ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} e x_ {n1} e ... & x_ {nk} \ end {pmatrix} \ qquad $$ display $$
Agora a equação de regressão linear assumirá a forma:
f(w,X)=X vecw
Indique os valores dos indicadores alvo (todos
yi ) por vetor
vecy dimensão
(n vezes1) :
vecy= beginpmatrixy0y1...yn endpmatrix qquad
Agora podemos escrever no formato de matriz a equação para avaliar a qualidade de um modelo linear:
Err=(X vecw− vecy)2 rightarrowmin
Na verdade, a partir desta fórmula, obtemos ainda a fórmula conhecida por nós
XTXw=XTyComo isso é feito? Os colchetes são abertos, a diferenciação é realizada, as expressões resultantes são transformadas, etc., e é isso que vamos fazer agora.
Transformações matriciais
Expanda os colchetes
(X vecw− vecy)2=(X vecw− vecy)T(X vecw− vecy)=(X vecw)TX vecw− vecyTX vecw−(X vecw)T vecy+ vecyT vecyPrepare uma equação para diferenciação
Para isso, realizamos algumas transformações. Nos cálculos subsequentes, será mais conveniente para nós se o vetor
vecwT será apresentado no início de cada trabalho na equação.
Conversão 1
vecyTX vecw=(X vecw)T vecy= vecwTXT vecyComo isso aconteceu? Para responder a essa pergunta, basta olhar para os tamanhos das matrizes multiplicadas e ver que, na saída, obtemos um número ou não
const .
Escrevemos as dimensões das expressões da matriz.
vecyTX vecw:(1 vezesn) pontocentral(n vezesk) pontocentral(k vezes1)=(1 vezes1)=const(X vecw)T vecy:((n vezesk) pontocentral(k vezes1))T pontocentral(n vezes1)=(1 vezesn) centerdot(n vezes1)=(1 vezes1)=const vecwTXT vecy:(1 vezesk) pontocentral(k vezesn) pontocentral(n vezes1)=(1 vezes1)=constConversão 2
(X vecw)TX vecw= vecwTXTX vecwEscrevemos de maneira semelhante à transformação 1
(X vecw)TX vecw:((n vezesk) pontocentral(k vezes1))T pontocentral(n vezesk) pontocentral(k vezes1)=(1 vezes1)=const vecwTXTX vecw:(1 vezesk) pontocentral(k vezesn) pontocentral(n vezesk) pontocentral(k vezes1)=(1 vezes1)=constNa saída, obtemos uma equação que precisamos diferenciar:
Err= vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyDiferenciamos a função de avaliar a qualidade do modelo
Diferenciar por vetor
vecw :
fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw
( vecwTXTX vecw)′−(2 vecwTXT vecy)′+( vecyT vecy)′=02XTX vecw−2XT vecy+0=0XTX vecw=XT vecyPerguntas por que
( vecyT vecy)′=0 não deveria ser, mas as operações para determinar as derivadas nas outras duas expressões, analisaremos mais detalhadamente.
Diferenciação 1
Revelamos a diferenciação:
fracd( vecwTXTX vecw)d vecw=2XTX vecwPara determinar a derivada de uma matriz ou vetor, você precisa ver o que eles têm dentro. Nós olhamos:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
vecw= beginpmatrixw0w1...wk endpmatrix qquad$ inline $ X ^ T = \ begin {pmatrix} x_ {00} e x_ {10} e ... & x_ {n0} \\ x_ {01} & x_ {11} e ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} e x_ {1k} e ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
$ inline $ X = \ begin {pmatrix} x_ {00} e x_ {01} e ... & x_ {0k} \\ x_ {10} e x_ {11} e ... & x_ {1k} \\ ... & ... & ... & ... \\ x_ {n0} & x_ {n1} & ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
Denotar o produto de matrizes
XTX através da matriz
A . Matrix
A quadrado e, além disso, é simétrico. Essas propriedades serão úteis para nós ainda mais, lembre-se delas. Matrix
A tem dimensão
(k vezesk) :
$ inline $ A = \ begin {pmatrix} a_ {00} e a_ {01} e ... & a_ {0k} \\ a_ {10} e a_ {11} e ... & a_ {1k} \\ ... & ... & ... & ... \\ a_ {k0} & a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad $ inline $
Agora, nossa tarefa é multiplicar corretamente os vetores pela matriz e não obter "duas vezes dois cinco", para que possamos nos concentrar e ser extremamente cuidadosos.
$ inline $ \ vec {w} ^ TA \ vec {w} = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad \ times \ begin {pmatrix} a_ {00} e a_ {01} & ... & a_ {0k} \\ a_ {10} & a_ {11} & ... & a_ {1k} \\ ... & ... & ... & ... \ \ a_ {k0} e a_ {k1} & ... & a_ {kk} \ end {pmatrix} \ qquad \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
$ inline $ = \ begin {pmatrix} w_0a_ {00} + w_1a_ {10} + ... + w_ka_ {k0} & ... & w_0a_ {0k} + w_1a_ {1k} + ... + w_ka_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ w_k \ end {pmatrix} \ qquad = $ inline $
= beginpmatrix(w0a00+w1a10+...+wkak0)w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10mu(w0a0k+w1a1k+...+wkakk)wk endpmatrix==w20a00+w1a10w0+wkak0w0 mkern10mu+ mkern10mu... mkern10mu+ mkern10muw0a0kwk+w1a1kwk+...+w2kakkNo entanto, temos uma expressão complexa! De fato, temos um número - um escalar. E agora, já de verdade, passamos à diferenciação. É necessário encontrar a derivada da expressão obtida para cada coeficiente
w0w1...wk e obtenha o vetor de dimensão na saída
(k vezes1) . Apenas no caso, descreverei os procedimentos para as ações:
1) diferenciar por
wo nós obtemos:
2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwk2) diferenciar por
w1 nós obtemos:
w0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk3) diferenciar por
wk nós obtemos:
w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakkNa saída, o vetor prometido de tamanho
(k vezes1) :
beginpmatrix2w0a00+w1a10+w2a20+...+wkak0+a01w1+a02w2+...+a0kwkw0a01+2w1a11+w2a21+...+wkak1+a10w0+a12w2+...+a1kwk.........w0a0k+w1a1k+w2a2k+...+w(k−1)a(k−1)k+ak0w0+ak1w1+ak2w2+...+2wkakk endpmatrix
Se você olhar mais de perto o vetor, notará que os elementos esquerdo e direito do vetor correspondentes podem ser agrupados de forma que, como resultado, o vetor possa ser distinguido do vetor apresentado
vecw o tamanho
(k vezes1) . Por exemplo
w1a10 (elemento esquerdo da linha superior do vetor)
+a01w1 (o elemento direito da linha superior do vetor) pode ser representado como
w1(a10+a01) e
w2a20+a02w2 - como
w2(a20+a02) etc. em cada linha. Grupo:
beginpmatrix2w0a00+w1(a10+a01)+w2(a20+a02)+...+wk(ak0+a0k)w0(a01+a10)+2w1a11+w2(a21+a12)+...+wk(ak1+a1k).........w0(a0k+ak0)+w1(a1k+ak1)+w2(a2k+ak2)+...+2wkakk endpmatrix
Retire o vetor
vecw e na saída temos:
exibição $$ $$ \ begin {pmatrix} 2a_ {00} e a_ {10} + a_ {01} e a_ {20} + a_ {02} e ... & a_ {k0} + a_ {0k} \\ a_ {01} + a_ {10} e 2a_ {11} e a_ {21} + a_ {12} e ... & a_ {k1} + a_ {1k} \\ ... & ... & .. . & ... & ... \\ ... & ... & ... & ... & ... \\ ... & ... & ... & ... & .. & .. . \\ a_ {0k} + a_ {k0} e a_ {1k} + a_ {k1} e a_ {2k} + a_ {k2} & ... & 2a_ {kk} \ end {pmatrix} \ times \ begin {pmatrix} w_0 \\ w_1 \\ ... \\ ... \\ ... \\ w_k \ end {pmatrix} \ qquad $$ display $$
Agora, vamos dar uma olhada na matriz resultante. Uma matriz é a soma de duas matrizes
A+AT :
exibição $$ $$ \ begin {pmatrix} a_ {00} e a_ {01} e a_ {02} e ... & a_ {0k} \\ a_ {10} e a_ {11} e a_ {12} e ... & a_ {1k} \\ ... & ... & ... & ... & ... \\ a_ {k0} & a_ {k1} e a_ {k2} & ... & a_ {kk} \ end {pmatrix} + \ begin {pmatrix} a_ {00} e a_ {10} e a_ {20} e ... & a_ {k0} \\ a_ {01} e a_ {11} e a_ {21} & ... & a_ {k1} \\ ... & ... & ... & ... & ... \\ a_ {0k} e a_ {1k} e a_ {2k} & ... & a_ {kk} \ end {pmatrix} \ qquad $$ display $$
Lembre-se que, um pouco antes, observamos uma propriedade importante da matriz
A - é simétrico. Com base nessa propriedade, podemos afirmar com confiança que a expressão
A+AT é igual a
2A . Isso é fácil de verificar, revelando o produto matriz por elemento
XTX . Não faremos isso aqui, aqueles que desejarem podem realizar uma verificação por conta própria.
Vamos voltar à nossa expressão. Após nossas transformações, aconteceu como queríamos vê-lo:
(A+AT) times beginpmatrixw0w1...wk endpmatrix qquad=2A vecw=2XTX vecw
Então, lidamos com a primeira diferenciação. Passamos para a segunda expressão.
Diferenciação 2
fracd(2 vecwTXT vecy)d vecw=2XT vecyVamos seguir o caminho batido. Será muito mais curto que o anterior, portanto, não vá longe da tela.
Nós revelamos os vetores e a matriz elemento a elemento:
$ inline $ \ vec {w} ^ T = \ begin {pmatrix} w_0 & w_1 & ... & w_k \ end {pmatrix} \ qquad $ inline $
$ inline $ X ^ T = \ begin {pmatrix} x_ {00} e x_ {10} e ... & x_ {n0} \\ x_ {01} & x_ {11} e ... & x_ {n1} \\ ... & ... & ... & ... \\ x_ {0k} e x_ {1k} e ... & x_ {nk} \ end {pmatrix} \ qquad $ inline $
vecy= beginpmatrixy0y1...yn endpmatrix qquadPor um tempo, removemos o empate dos cálculos - ele não desempenha um grande papel, depois o devolvemos ao seu lugar. Multiplique os vetores pela matriz. Primeiro de tudo, multiplicamos a matriz
XT em vetor
vecy , aqui não temos restrições. Obtenha o vetor de tamanho
(k vezes1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Execute a seguinte ação - multiplique o vetor
vecw para o vetor resultante. Na saída, um número nos espera:
beginpmatrixw0(x00y0+x10y1+...+xn0yn)+w1(x01y0+x11y1+...+xn1yn) mkern10mu+ mkern10mu... mkern10mu+ mkern10muwk(x0ky0+x1ky1+...+xnkyn) endpmatrix qquad
Nós então o diferenciamos. Na saída, obtemos um vetor de dimensão
(k vezes1) :
beginpmatrixx00y0+x10y1+...+xn0ynx01y0+x11y1+...+xn1yn...x0ky0+x1ky1+...+xnkyn endpmatrix qquad
Parece algo? Tudo bem! Este é o produto da matriz.
XT em vetor
vecy .
Assim, a segunda diferenciação foi concluída com sucesso.
Em vez de uma conclusão
Agora sabemos como surgiu a igualdade.
XTX vecw=XT vecy .
Por fim, descrevemos uma maneira rápida de transformar as principais fórmulas.
Estime a qualidade do modelo de acordo com o método dos mínimos quadrados: sum limitsni=1(yi−f(xi))2 mkern20mu= mkern20mu sum limitsni=1(yi− vecxiT vecw)2==(X vecw− vecy)2 mkern20mu= mkern20mu(X vecw− vecy)T(X vecw− vecy) mkern20mu= mkern20mu vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecyDiferenciamos a expressão resultante: fracd( vecwTXTX vecw−2 vecwTXT vecy+ vecyT vecy)d vecw=2XTX vecw−2XT vecy=0XTX vecw=XT vecy leftarrow Trabalho anterior do autor - “Resolvemos a equação da regressão linear simples” rightarrow O próximo trabalho do autor - "Chewing Regression Logistic"Literatura
Fontes da Internet:1)
habr.com/en/post/2785132)
habr.com/ru/company/ods/blog/3220763)
habr.com/en/post/3070044)
nabatchikov.com/blog/view/matrix_derLivros didáticos, coleções de tarefas:1) Notas de aula sobre matemática superior: curso completo / D.T. Escrito - 4ª ed. - M: Iris Press, 2006
2) Análise de Regressão Aplicada / N. Draper, G. Smith - 2a ed. - M .: Finanças e estatística, 1986 (traduzido do inglês)
3) Tarefas para resolver equações matriciais:
function-x.ru/matrix_equations.html
mathprofi.ru/deistviya_s_matricami.html