
Só não se surpreenda, mas o segundo cabeçalho deste post gerou uma rede neural, ou melhor, o algoritmo de sammarização. E o que é sammarização?
Esse é um dos principais e clássicos
desafios do Processamento de linguagem natural (PNL) . Consiste na criação de um algoritmo que recebe o texto como entrada e gera uma versão resumida dele. Além disso, a estrutura correta (correspondente às normas da língua) é preservada e a idéia principal do texto é transmitida corretamente.
Tais algoritmos são amplamente utilizados na indústria. Por exemplo, eles são úteis para os mecanismos de pesquisa: usando a redução de texto, você pode entender facilmente se a ideia principal de um site ou documento está relacionada a uma consulta de pesquisa. Eles são usados para procurar informações relevantes em um grande fluxo de dados de mídia e para filtrar o lixo de informações. A redução de texto ajuda na pesquisa financeira, na análise de contratos legais, anotação de artigos científicos e muito mais. A propósito, o algoritmo de sammarização gerou todos os subtítulos para este post.
Para minha surpresa, em Habré havia muito poucos artigos sobre sammarização, então decidi compartilhar minhas pesquisas e resultados nessa direção. Este ano, participei da pista de corridas da conferência
Dialogue e experimentei geradores de manchetes para notícias e poemas usando redes neurais. Neste post, irei primeiro abordar brevemente a parte teórica da sammarização e, em seguida, darei exemplos com a geração de títulos, explicarei quais dificuldades os modelos têm ao reduzir o texto e como esses modelos podem ser aprimorados para obter melhores títulos.
Abaixo está um exemplo de uma notícia e seu título de referência original. Os modelos sobre os quais falarei treinam para gerar cabeçalhos com este exemplo:

Segredos para cortar a arquitetura seq2seq de texto
Existem dois tipos de métodos de redução de texto:
- Extrativista . Consiste em encontrar as partes mais informativas do texto e construir a partir delas a anotação correta para o idioma especificado. Este grupo de métodos usa apenas as palavras que estão no texto de origem.
- Resumo Consiste na extração de links semânticos do texto, levando em consideração as dependências do idioma. Com a sammarização abstrata, as palavras de anotação não são selecionadas no texto abreviado, mas no dicionário (a lista de palavras para um determinado idioma) - reformulando assim a idéia principal.
A segunda abordagem implica que o algoritmo deve levar em conta as dependências da linguagem, reformular e generalizar. Ele também quer ter algum conhecimento do mundo real para evitar erros de fato. Por um longo tempo, isso foi considerado uma tarefa difícil, e os pesquisadores não conseguiram obter uma solução de alta qualidade - um texto gramaticalmente correto, preservando a idéia principal. É por isso que, no passado, a maioria dos algoritmos era baseada em uma abordagem de extração, pois a seleção de partes inteiras do texto e a transferência delas para o resultado permitem manter o mesmo nível de alfabetização da fonte.
Mas isso foi antes do boom das redes neurais e de sua penetração iminente na PNL. Em 2014, a arquitetura
seq2seq foi
introduzida com um mecanismo de atenção que pode ler algumas seqüências de texto e gerar outras (que depende do que o modelo aprendeu a produzir) (
artigo de Sutskever et al.). Em 2016, essa arquitetura foi aplicada diretamente à solução do problema de sammarização, realizando uma abordagem abstrata e obtendo um resultado comparável ao que uma pessoa competente poderia escrever (
artigo de Nallapati et al., 2016;
artigo de Rush et al., 2015; ) Como essa arquitetura funciona?
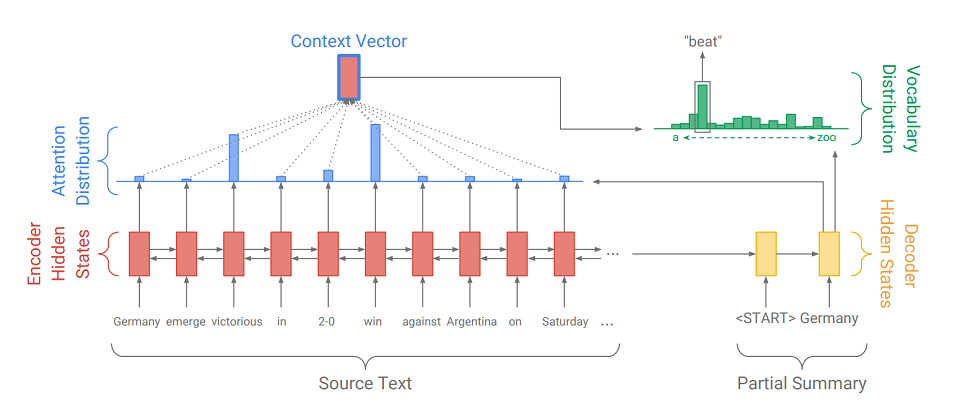
Seq2Seq consiste em duas partes:
- Codificador (Encoder) - um RNN bidirecional, usado para ler a sequência de entrada, ou seja, processa sequencialmente os elementos de entrada simultaneamente da esquerda para a direita e da direita para a esquerda para melhor considerar o contexto.
- decodificador (decodificador) - RNN unidirecional, que sequencialmente e por elementos produz uma sequência de saída.
Primeiro, a sequência de entrada é traduzida em uma sequência de incorporação (em resumo, incorporação é uma representação concisa de uma palavra como um vetor). Os casamentos passam pela rede recursiva do codificador. Portanto, para cada palavra, obtemos os estados ocultos do codificador (
indicados por retângulos vermelhos no diagrama ), e eles contêm informações sobre o próprio token e seu contexto, permitindo que levemos em consideração as conexões de idioma entre as palavras.
Após processar a entrada, o codificador transfere seu último estado oculto (que contém informações compactadas sobre o texto inteiro) para o decodificador, que recebe um token especial

e cria a primeira palavra da sequência de saída (
na imagem é "Alemanha" ). Em seguida, ele pega ciclicamente sua saída anterior, alimenta-a e exibe novamente o próximo elemento de saída (
assim, depois que "Alemanha" vier "bater" e depois de "bater" vir a palavra seguinte, etc. ). Isso é repetido até que um token especial seja emitido
. Isso significa o fim da geração.
Para exibir o próximo elemento, o decodificador, assim como o codificador, converte o token de entrada em incorporação, dá um passo na rede recursiva e recebe o próximo estado oculto do decodificador (
retângulos amarelos no diagrama ). Em seguida, usando uma camada totalmente conectada, é obtida uma distribuição de probabilidade para todas as palavras de um dicionário de modelo pré-compilado. As palavras mais prováveis serão deduzidas pelo modelo.
A adição de
um mecanismo de atenção ajuda o decodificador a utilizar melhor as informações de entrada. O mecanismo em cada etapa da geração determina a chamada
distribuição de atenção (os
retângulos azuis na figura são o conjunto de pesos correspondente aos elementos da sequência original, a soma dos pesos é 1, todos os pesos> = 0 ) e dele recebe a soma ponderada de todos os estados ocultos do codificador, formando assim vetor de contexto (
o diagrama mostra um retângulo vermelho com um traço azul ). Esse vetor concatena com a incorporação da palavra de entrada do decodificador no estágio de cálculo do estado latente e com o próprio estado latente no estágio de determinação da próxima palavra. Portanto, em cada etapa da saída, o modelo pode determinar quais estados do codificador são mais importantes para ele no momento. Em outras palavras, ele decide o contexto em que as palavras de entrada devem ser levadas em consideração ao máximo (por exemplo, na figura, exibindo a palavra "batida", o mecanismo de atenção atribui grandes pesos aos tokens "vitorioso" e "ganha", e o restante é quase zero).
Como a geração de cabeçalhos também é uma das tarefas de sammarização, apenas com a saída mínima possível (1-12 palavras), decidi aplicar o
seq2seq com o mecanismo de atenção para o nosso caso. Nós treinamos esse sistema em textos com títulos, por exemplo, nas notícias. Além disso, é aconselhável, no estágio de treinamento, submeter ao decodificador não sua própria produção, mas as palavras do cabeçalho real (forçar o professor), facilitando a vida para ele e o modelo. Como uma função de erro, usamos a função de perda de entropia cruzada padrão, mostrando quão próximas as distribuições de probabilidade da palavra de saída e da palavra do cabeçalho real são:
Ao usar o modelo treinado, usamos a pesquisa de raios para encontrar uma sequência de palavras mais provável do que o algoritmo ganancioso. Para fazer isso, em cada etapa da geração, derivamos não a palavra mais provável, mas ao mesmo tempo observamos o tamanho do feixe das seqüências de palavras mais prováveis. Quando eles terminam (cada um termina em
), derivamos a sequência mais provável.
Evolução do modelo
Um dos problemas do modelo no seq2seq é a incapacidade de citar palavras que não estão no dicionário. Por exemplo, o modelo não tem chance de deduzir "obamacare" do artigo acima. O mesmo vale para:
- sobrenomes e nomes raros
- novos termos
- palavras em outras línguas,
- diferentes pares de palavras conectados por um hífen (como um "senador republicano")
- e outros projetos.
Obviamente, você pode expandir o dicionário, mas isso aumenta muito o número de parâmetros treinados. Além disso, é necessário fornecer um grande número de documentos nos quais essas palavras raras são encontradas, para que o gerador aprenda a utilizá-las de maneira qualitativa.
Outra solução mais elegante para esse problema foi apresentada em um artigo de 2017 - “
Vá direto ao ponto: resumo com redes de geradores de ponteiros ” (Abigail See et al.). Ela adiciona um novo mecanismo ao nosso modelo -
um mecanismo de ponteiro, que pode selecionar palavras do texto de origem e inserir diretamente na sequência gerada. Se o texto contiver OOV (
fora do vocabulário - uma palavra que não está no dicionário ), o modelo, se considerar necessário, poderá isolar o OOV e inseri-lo na saída. Esse sistema é chamado de
“ gerador de ponteiro” (gerador de ponteiro ou pg) e é uma síntese de duas abordagens para a sammarização. Ela mesma pode decidir em que etapa deve ser abstrata e em que etapa - extrair. Como ela faz isso, vamos descobrir agora.
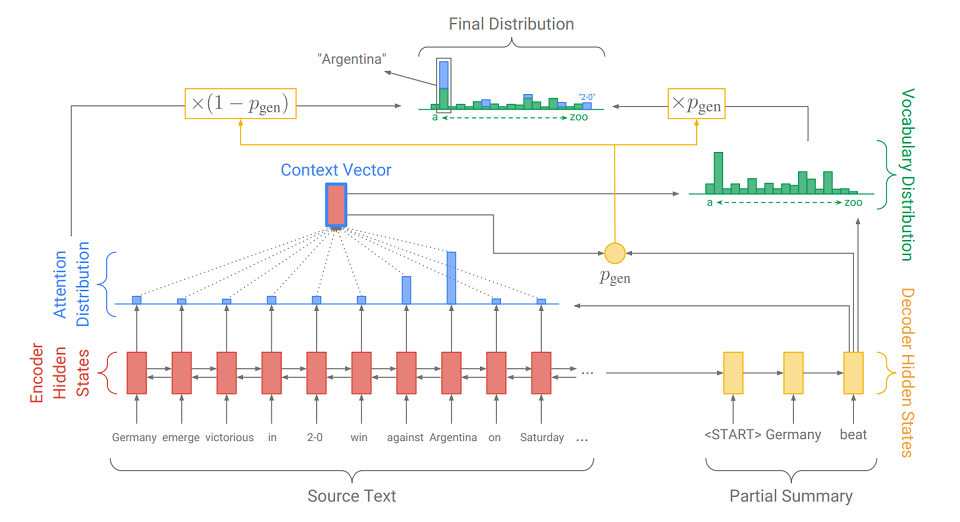
A principal diferença do modelo seq2seq usual é a ação adicional sobre a qual p
gen é calculado - a probabilidade de geração. Isso é feito usando o estado oculto do decodificador e o vetor de contexto. O significado da ação adicional é simples. Quanto mais próximo de
gen é 1, maior a probabilidade de o modelo emitir uma palavra do dicionário usando geração abstrata. Quanto mais próximo o p
gen for de 0, maior a probabilidade de o gerador extrair a palavra do texto, guiada pela distribuição da atenção obtida anteriormente. A distribuição de probabilidade final dos resultados da palavra é a soma da distribuição de probabilidade gerada das palavras (na qual não há OOV) multiplicada por p
gen e a distribuição da atenção (na qual OOV é, por exemplo, “2-0” na figura) multiplicada por (1 - p
gen ).

Além do mecanismo de apontar, o artigo apresenta
um mecanismo de cobertura , que ajuda a evitar a repetição de palavras. Também experimentei, mas não percebi melhorias significativas na qualidade dos títulos - não é realmente necessário. Provavelmente, isso se deve às especificidades da tarefa: como é necessário gerar um pequeno número de palavras, o gerador simplesmente não tem tempo para se repetir. Mas para outras tarefas de sammarização, por exemplo, anotação, pode ser útil. Se estiver interessado, você pode ler sobre isso no
artigo original.

Grande variedade de palavras em russo
Outra maneira de melhorar a qualidade dos cabeçalhos de saída é pré-processar adequadamente a sequência de entrada. Além da disposição óbvia de caracteres maiúsculos, também tentei converter palavras do texto de origem em pares de estilos e inflexões (ou seja, fundações e finais). Para dividir, use o Porter Stemmer.
Marcamos todas as inflexões com o símbolo “+” no início para distingui-las de outros tokens. Consideramos cada tópico e inflexão como uma palavra separada e aprendemos com eles da mesma maneira que nas palavras. Ou seja, obtemos incorporação deles e derivamos uma sequência (também dividida em fundações e finais) que pode ser facilmente transformada em palavras.
Essa conversão é muito útil quando se trabalha com idiomas morfologicamente ricos como o russo. Em vez de compilar dicionários enormes com uma grande variedade de formas de palavras em russo, você pode limitar-se a um grande número de hastes dessas palavras (elas são várias vezes menores que o número de formas de palavras) e a um conjunto muito pequeno de terminações (recebi muitas 450 inflexões). Assim, facilitamos o trabalho do modelo com essa “riqueza” e, ao mesmo tempo, não aumentamos a complexidade da arquitetura e o número de parâmetros.

Eu também tentei usar a transformação de lema + grama. Ou seja, a partir de cada palavra antes do processamento, você pode obter sua forma inicial e significado gramatical usando o pacote pymorphy (por exemplo, "was"
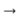
"Ser" e "VERBO | impf | passado | cantar | femn"). Assim, obtive um par de sequências paralelas (em uma - as formas iniciais, na outra - valores gramaticais). Para cada tipo de sequência, compilei minhas incorporações, que concatenaram e submeteram ao pipeline descrito anteriormente. Nele, o decodificador não aprendeu a dar uma palavra, mas um lema e gramáticas. Mas esse sistema não trouxe melhorias visíveis em comparação com a página sobre o assunto. Talvez fosse uma arquitetura excessivamente simples para trabalhar com valores gramaticais e valesse a pena criar um classificador separado para cada categoria gramatical na saída. Mas não experimentei modelos assim ou mais complexos.
Eu experimentei outra adição à arquitetura original do gerador de ponteiros, que, no entanto, não se aplica ao pré-processamento. Isso é um aumento no número de camadas (até 3) das redes recursivas do codificador e decodificador. Aumentar a profundidade da rede recorrente pode melhorar a qualidade da saída, pois o estado oculto das últimas camadas pode conter informações sobre uma subsequência de entrada muito mais longa do que o estado oculto de uma RNN de camada única. Isso ajuda a levar em consideração as conexões semânticas estendidas complexas entre os elementos da sequência de entrada. É verdade que isso custa um aumento significativo no número de parâmetros do modelo e complica o aprendizado.

Experiências do gerador de cabeçalho
Todas as minhas experiências com geradores de títulos podem ser divididas em dois tipos: experiências com artigos e versículos. Vou falar sobre eles em ordem.
Notícias Experiências
Ao trabalhar com notícias, usei modelos como seq2seq, pg, pg com hastes e inflexões - camada única e três camadas. Também considerei modelos que funcionam com gramas, mas tudo o que queria contar sobre eles já descrevi acima. Devo dizer imediatamente que todas as páginas descritas nesta seção usaram o mecanismo de revestimento, embora sua influência sobre o resultado seja duvidosa (pois sem ele não foi muito pior).
Treinei no conjunto de dados RIA Novosti, fornecido pela agência de notícias Rossiya Segodnya, para conduzir uma faixa de geração de manchetes na conferência Dialog. O conjunto de dados contém 1.003.869 notícias publicadas de janeiro de 2010 a dezembro de 2014.
Todos os modelos estudados usaram os mesmos embeddings (128), vocabulário (100k) e estados latentes (256) e treinados para o mesmo número de épocas. Portanto, apenas alterações qualitativas na arquitetura ou no pré-processamento podem afetar o resultado.
Modelos adaptados para trabalhar com texto pré-processado oferecem melhores resultados do que modelos que trabalham com palavras. Uma página de três camadas que usa informações sobre tópicos e inflexões funciona melhor. Ao usar qualquer página, a melhoria esperada na qualidade dos cabeçalhos em comparação com seq2seq também aparece, o que sugere o uso preferencial do ponteiro ao gerar cabeçalhos. Aqui está um exemplo da operação de todos os modelos:
Observando os cabeçalhos gerados, podemos distinguir os seguintes problemas dos modelos em estudo:
- Os modelos costumam usar formas irregulares de palavras. Modelos com hastes (como no exemplo acima) são mais aliviados dessa desvantagem;
- Todos os modelos, exceto aqueles que trabalham com temas, podem produzir cabeçalhos que parecem incompletos ou designs estranhos que não estão no idioma (como no exemplo acima);
- Todos os modelos estudados freqüentemente confundem as pessoas descritas, substituem datas incorretas ou usam palavras não muito adequadas.


Experimentos com versículos
Como a página de três camadas com os temas tem as menos imprecisões nos cabeçalhos gerados, esse é o modelo que eu escolhi para experimentos com versos. Eu a ensinei sobre o caso, composto por 6 milhões de poemas russos do site "stihi.ru". Eles incluem amor (cerca de metade dos versos são dedicados a este tópico), cívica (cerca de um quarto), poesia urbana e paisagística. Período de redação: janeiro de 2014 a maio de 2019. Vou dar exemplos de títulos gerados para os versículos:
O modelo acabou extraindo principalmente: quase todos os cabeçalhos são de uma única linha, geralmente extraídos da primeira ou da última estrofe. Em casos excepcionais, o modelo pode gerar palavras que não estão no poema. Isso se deve ao fato de um grande número de textos no caso ter realmente uma das linhas como nome.
, -, ,
«». — ABBYY, Natural Language Processing.
, : , , .
, NLP Group ABBYY