Buffers de operações de medo ...
Usando uma pequena consulta como exemplo, considere algumas abordagens universais para otimizar consultas no PostgreSQL. Para usá-los ou não, é sua escolha, mas você deve saber sobre eles.
Em algumas versões futuras do PG, a situação pode mudar com a "sabedoria" do planejador, mas para a 9.4 / 9.6 ela se parece com o mesmo, como exemplos aqui.
Aceito uma solicitação muito real:
SELECT TRUE FROM "" d INNER JOIN "" doc_ex USING("@") INNER JOIN "" t_doc ON t_doc."@" = d."" WHERE (d."3" = 19091 or d."" = 19091) AND d."$" IS NULL AND d."" IS NOT TRUE AND doc_ex.""[1] IS TRUE AND t_doc."" = '' LIMIT 1;
sobre os nomes de tabelas e camposOs nomes "russos" de campos e tabelas podem ser tratados de maneira diferente, mas isso é uma questão de gosto. Como não temos desenvolvedores estrangeiros
no “Tensor” , o PostgreSQL nos permite dar nomes mesmo com hieróglifos, se eles estiverem
entre aspas , preferimos nomear objetos de forma clara e sem ambiguidade, para que não haja mal-entendidos.
Vejamos o plano resultante:
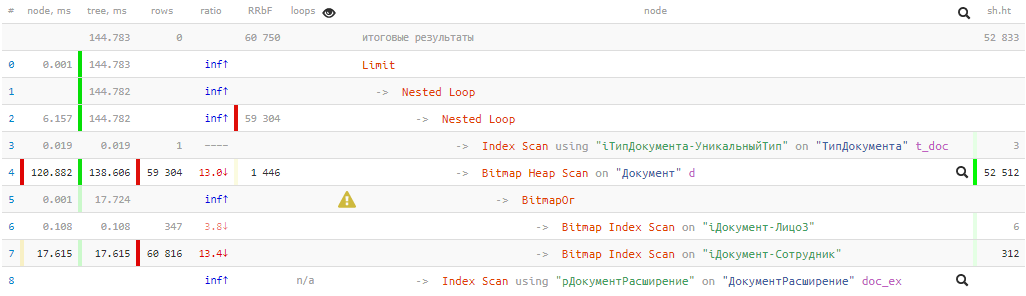 [veja em explicar.tensor.ru]144ms e quase 53K de buffer
[veja em explicar.tensor.ru]144ms e quase 53K de buffer - ou seja, mais de 400MB de dados! E temos sorte se todos eles estiverem no cache no momento da nossa solicitação, caso contrário, serão várias vezes maiores quando subtraídos do disco.
O algoritmo é mais importante!
Para otimizar de alguma forma qualquer solicitação, você deve primeiro entender o que ela deve fazer.
Por enquanto, deixamos o desenvolvimento da estrutura do banco de dados fora do escopo deste artigo e concordamos que podemos relativamente "de forma barata"
reescrever a consulta e / ou rolar no banco de dados quaisquer
índices necessários.
Portanto, a solicitação é:
- verifica a existência de pelo menos algum documento
- na condição que precisamos e de um certo tipo
- onde o autor ou executor é o funcionário de que precisamos
JOIN + LIMIT 1
Muitas vezes, é mais fácil para um desenvolvedor escrever uma consulta em que, inicialmente, um grande número de tabelas é unido e, em seguida, de todo esse conjunto, há apenas um registro. Mas mais fácil para o desenvolvedor - não significa mais eficiente para o banco de dados.
No nosso caso, havia apenas 3 tabelas - e que efeito ...
Para começar, vamos nos livrar da conexão com a tabela "TypeDocument" e, ao mesmo tempo, informar ao banco de dados que nosso
registro de tipo é único (sabemos disso, mas o planejador não tem idéia):
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' LIMIT 1 ) ... WHERE d."" = (TABLE T) ...
Sim, se a tabela / CTE consistir em um único campo de um único registro, no PG você poderá escrever mesmo assim, em vez de
d."" = (SELECT "@" FROM T LIMIT 1)
Computação preguiçosa nas consultas do PostgreSQL
BitmapOr vs UNION
Em alguns casos, o Bitmap Heap Scan nos custará muito dinheiro - por exemplo, em nossa situação, quando registros suficientes caem sob a condição necessária. Obtivemos isso por causa da
condição OR, que se transformou em uma operação
BitmapOr no plano.
Vamos voltar à tarefa original - você precisa encontrar um registro que corresponda a
qualquer uma das condições - ou seja, não há necessidade de pesquisar todos os 59K registros para ambas as condições. Existe uma maneira de descobrir uma condição e
ir para a segunda somente quando nada foi encontrado na primeira . Este design nos ajudará a:
( SELECT ... LIMIT 1 ) UNION ALL ( SELECT ... LIMIT 1 ) LIMIT 1
O LIMITE 1 "Externo" garante que a pesquisa termine quando o primeiro registro for encontrado. E se ele já estiver no primeiro bloco, o segundo não será
executado (
nunca executado no plano).
Condições difíceis "Ocultando-se no CASO"
Há um momento extremamente inconveniente na solicitação inicial - verificando o status usando a tabela vinculada "Extensão de documento". Independentemente da veracidade das condições restantes na expressão (por exemplo,
d. “Excluído” NÃO É VERDADEIRO ), essa conexão é sempre realizada e “vale os recursos”. Mais ou menos deles serão gastos - depende do tamanho desta tabela.
Mas você pode modificar a solicitação para que a pesquisa pelo registro relacionado ocorra apenas quando for realmente necessário:
SELECT ... FROM "" d WHERE ... AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END
Como
não precisamos de nenhum dos campos para o resultado da tabela vinculada, podemos transformar o JOIN em uma condição para uma subconsulta.
Deixamos os campos indexados "fora dos colchetes" do CASE, adicionamos condições simples do registro ao bloco WHEN - e agora a consulta "pesada" é executada apenas ao mudar para THEN.
Meu sobrenome é "Total"
Coletamos a consulta resultante com toda a mecânica descrita acima:
WITH T AS ( SELECT "@" FROM "" WHERE "" = '' ) ( SELECT TRUE FROM "" d WHERE ("3", "") = (19091, (TABLE T)) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) UNION ALL ( SELECT TRUE FROM "" d WHERE ("", "") = ((TABLE T), 19091) AND CASE WHEN "$" IS NULL AND "" IS NOT TRUE THEN ( SELECT ""[1] IS TRUE FROM "" WHERE "@" = d."@" ) END LIMIT 1 ) LIMIT 1;
Personalizar índices [abaixo]
O olho treinado percebeu que as condições indexadas nas subunidades UNION são ligeiramente diferentes - isso ocorre porque já temos os índices apropriados na tabela. E se eles não estavam lá, valeria a pena criar:
Documento (Pessoa3, Tipo de Documento) e
Documento (Tipo de Documento, Funcionário) .
sobre a ordem dos campos em condições ROWDo ponto de vista do planejador, é claro, você pode escrever (A, B) = (constA, constB) e (B, A) = (constB, constA) . Porém, ao escrever na ordem dos campos no índice , essa solicitação é simplesmente mais conveniente para depurar mais tarde.
Qual é o plano?
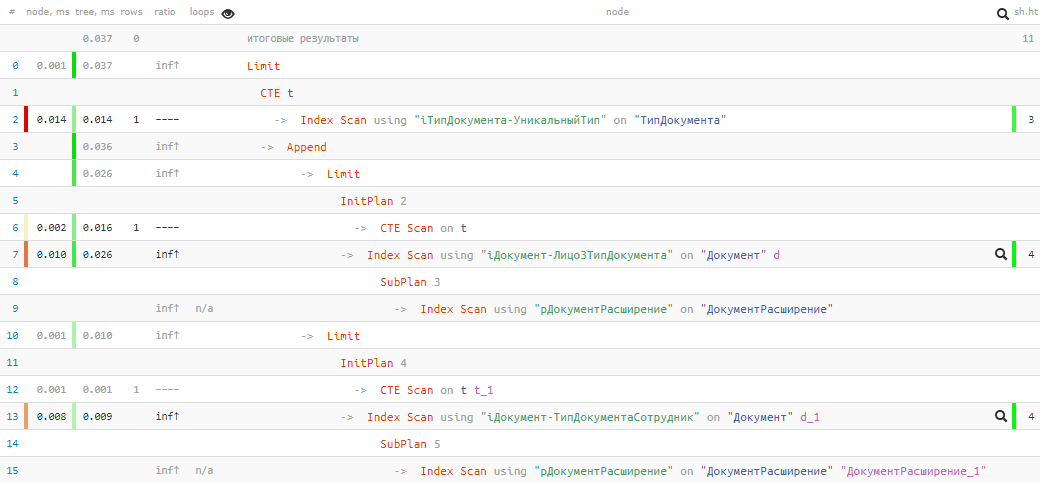 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]Infelizmente, não tivemos sorte e nada foi encontrado no primeiro bloco UNION, portanto o segundo foi executado. Mas mesmo assim - apenas
0,037ms e 11 buffers !
Aceleramos a solicitação e reduzimos o "bombeamento" de dados na memória em
vários milhares de vezes , usando métodos bastante simples - um bom resultado com uma pequena pasta de copiar. :)