Olá Habr! Meu nome é Roman e quero falar hoje sobre como nós, na Universidade de Innopolis, desenvolvemos uma bancada de testes e serviços para o sistema Acronis Active Restore, que em breve deverá se tornar parte da linha de produtos da empresa. Todo mundo que estiver interessado em como a universidade está construindo relacionamentos com parceiros industriais, convido você a prosseguir sob o comando cat.

O desenvolvimento do Active Restore começou dentro da Acronis, mas nós, como estudantes da Universidade de Innopolis, participamos desse processo como parte de um projeto de treinamento industrial. Meu curador (e agora colega) Daulet Tumbaev já escreveu sobre a idéia, bem como a arquitetura,
em seu post . Hoje vou falar sobre como preparamos o serviço em Innopolis.
Tudo começou no verão, quando fomos informados de que, no primeiro semestre, as empresas de TI viriam até nós e ofereceriam suas idéias para trabalhos práticos. Então, em dezembro de 2018, fomos presenteados com 15 projetos diferentes e, no final do mês, estabelecemos prioridades, descobrindo quem mais gosta.
Todos os estudantes de graduação preencheram um formulário onde era necessário escolher quatro projetos nos quais queríamos participar. Era necessário motivar por que eu e por que exatamente esses projetos. Por exemplo, apontei que já tenho experiência em programação e desenvolvimento de sistemas em C / C ++. Mas o mais importante, o projeto me permitiu desenvolver minhas habilidades e continuar a crescer.
Duas semanas depois, fomos designados e, a partir do início do segundo semestre, o trabalho em projetos começou. A equipe foi formada. Na primeira reunião, avaliamos os pontos fortes e fracos de cada um e os papéis atribuídos.
- Roman Rybkin é desenvolvedor de Python / C ++.
- Eugene Ishutin - desenvolvedor de Python / C ++, responsável por interagir com a empresa.
- Anastasia Rodionova é um desenvolvedor Python / C ++ responsável por escrever a documentação.
- Brandon Acosta - montando o ambiente, preparando o estande para experimentos e testes.
Nas duas primeiras semanas tivemos que iniciar o processo. Estabelecemos contatos com o cliente, formalizamos os requisitos do projeto, lançamos um processo iterativo e configuramos o ambiente para o trabalho.
A propósito, nosso trabalho com o cliente realmente começou a ferver quando começamos as eletivas. O fato é que Acronis lidera na Universidade de Innopolis (e não apenas) os assuntos de sua escolha. E Alexey Kostyushko, desenvolvedor líder da equipe do Kernel, ministra dois cursos continuamente: Engenharia Reversa e Arquitetura e Drivers do Kernel do Windows. Até onde eu sei, também está planejado um curso de programação de sistemas e computação multithread. Mas o principal é que todos esses cursos são projetados de forma a ajudar os alunos a lidar com projetos industriais. Eles realmente ajudam a entender a área de assunto e, assim, simplificam o trabalho no projeto.
Devido a isso, começamos com mais vigor do que outras equipes, e a interação com a própria Acronis se tornou mais densa. Alexey Kostyushko atuou por nós no papel de Product Owner, dele recebemos o conhecimento necessário na área de assunto. Graças às suas disciplinas eletivas, nossas habilidades e competências duraram muito, ficamos realmente prontos para cumprir a tarefa que nos confrontava.
Do pensamento ao projeto
O primeiro mês para todas as equipes foi o mais difícil possível. Todo mundo estava perdido, não sabia por onde começar - talvez com documentos ou, inversamente, mergulhando no código. A princípio, comentários conflitantes vieram de curadores e mentores da universidade e de representantes da empresa.
Quando tudo se encaixou (pelo menos na minha cabeça), ficou claro que os mentores da universidade nos ajudaram a construir relações internas na equipe e a preparar documentos. Mas o verdadeiro ponto de avanço foi a chegada de Daulet em março. Nós apenas nos sentamos e trabalhamos no projeto durante todo o fim de semana. Em seguida, repensamos a essência do projeto, reinicializamos, redistribuímos as prioridades das tarefas e rapidamente avançamos. Entendemos o que precisa ser feito para iniciar o experimento (um pouco mais tarde) e desenvolver o serviço. A partir desse momento, a ideia geral se transformou em um plano claro. O verdadeiro desenvolvimento do código começou e, em duas semanas, desenvolvemos a primeira versão da bancada de testes, incluindo máquinas virtuais, os serviços e o código necessários para automatizar o experimento e coletar dados.
Vale ressaltar que, paralelamente ao projeto industrial, foram realizados treinamentos que nos ajudaram a construir uma arquitetura competente para nossos projetos e a organizar a Gestão da Qualidade. No início, essas tarefas levavam 70 a 90% do tempo por semana, mas, como se viu, era necessário tempo para evitar problemas no processo de desenvolvimento. O objetivo da universidade era aprender a construir com competência o processo de desenvolvimento, e as empresas, como clientes, estavam mais interessadas no resultado. Isso, é claro, trouxe muita confusão, mas ajudou a combinar habilidades teóricas e práticas. Complexidade e carga suficientes garantiram a presença de motivação, o que resultou em um projeto bem-sucedido.
Inicialmente, duas pessoas em nossa equipe estavam envolvidas em puro desenvolvimento, uma pessoa assumiu os documentos e outra mergulhou na criação do ambiente. No entanto, mais tarde, mais três solteiros se juntaram a nós, com quem nos tornamos uma única equipe. A universidade decidiu lançar um projeto industrial de teste para estudantes do terceiro ano de estudo. A expansão da equipe de 4 para 7 pessoas acelerou muito o processo, porque nossos solteiros podiam facilmente executar tarefas relacionadas ao desenvolvimento. Ekaterina Levchenko ajudou a escrever código python e scripts em lote para o banco de testes. Ansat Abirov e Ruslan Kim atuaram como desenvolvedores, eles estavam envolvidos na seleção e otimização de algoritmos.
Trabalhamos nesse formato até o final de maio, quando o experimento foi lançado. Nesse momento, o projeto industrial para solteiros terminou. Dois deles começaram um estágio Acronis e continuaram a trabalhar conosco. Portanto, depois de maio, já trabalhamos como uma equipe de 6 pessoas.
Antes de nós era o terceiro semestre, que em Innópolis é livre de atividades acadêmicas. Tínhamos apenas duas disciplinas eletivas e o restante do tempo foi gasto em um projeto industrial. Foi no terceiro semestre que o trabalho no serviço foi intensivo. O processo de desenvolvimento caiu completamente nos trilhos, demonstrações e relatórios se tornaram regulares. Nesse formato, trabalhamos por 1,5 meses e, no final de julho, quase terminamos a parte de desenvolvimento do trabalho.
Detalhes técnicos
Primeiro, foram formulados os requisitos para um serviço, que deveriam interagir adequadamente com o driver do minifiltro do sistema de arquivos (que é o que você pode ler
aqui ) e sua arquitetura foi pensada. De olho na simplicidade de mais suporte a código, fornecemos imediatamente uma abordagem modular. Nosso serviço inclui vários gerentes, agentes e manipuladores e, mesmo antes do início da codificação, a capacidade de trabalhar em modo paralelo foi estabelecida.
No entanto, depois de discutir a arquitetura em uma reunião com os funcionários da Acronis, decidiu-se realizar um experimento primeiro e depois assumir o serviço em si. Como resultado, o desenvolvimento levou apenas 2,5 meses. No restante do tempo, realizamos um experimento para encontrar a lista mínima suficiente de arquivos nos quais o Windows poderia ser executado. Em um sistema real, esse conjunto de arquivos é gerado usando o driver, no entanto, decidimos encontrá-lo heuristicamente, usando o método de meia divisão, para verificar a operação do driver.
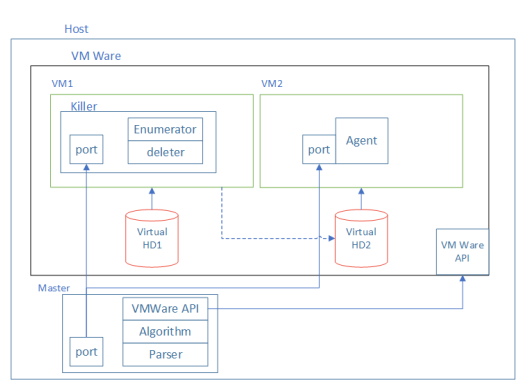 A posição do experimento.
A posição do experimento.
Para fazer isso, montamos um suporte em Python a partir de duas máquinas virtuais. Um deles trabalhava no Linux e o segundo carregava o Windows. Dois discos foram configurados para eles: HD1 Virtual e HD2 Virtual. Ambas as unidades foram conectadas à VM1 na qual o Linux foi instalado. Nesta máquina virtual no HD1, foi instalado o aplicativo Killer, que "danificou" o HD2. Dano refere-se à exclusão de alguns arquivos do disco. HD2 era um disco de inicialização para VM2 que funcionava no Windows. Após o "dano" ao disco, tentamos iniciar o VM2. Se fosse possível, os arquivos excluídos do disco eram considerados desnecessários para execução.
Para automatizar esse processo, tentamos excluir arquivos não aleatoriamente, mas como parte de uma abordagem pré-pensada. O algoritmo consistiu em 3 etapas:
- Divida a lista de arquivos ao meio.
- Exclua um dos metade dos arquivos.
- Tente iniciar o sistema. Se o sistema foi iniciado, adicione os arquivos excluídos à lista de desnecessários. Caso contrário, retornaremos à etapa 1.
Primeiro, decidimos simular o algoritmo. Suponha que haja 1.000.000 de arquivos no sistema de arquivos. Nesse caso, a pesquisa mais eficaz de arquivos críticos ocorreu nos casos em que os arquivos críticos representavam cerca de 15% do total.
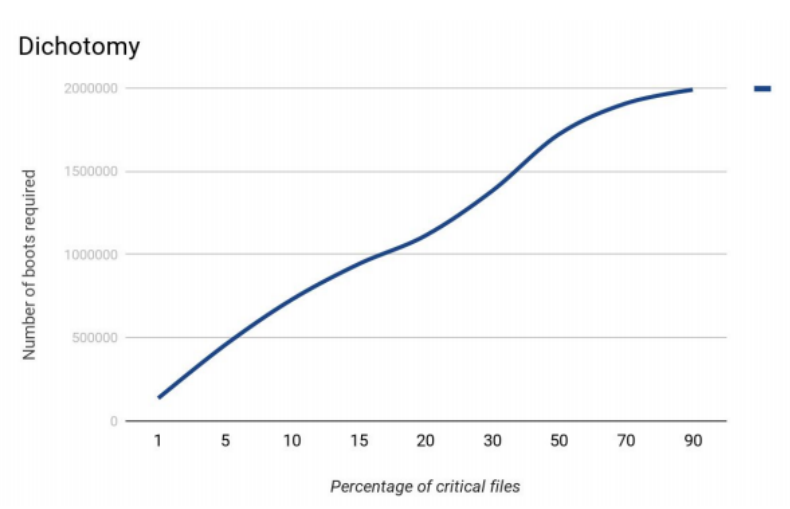 Método de meia divisão.
Método de meia divisão.No começo, havia muitos problemas com o experimento. Durante 2-3 semanas, uma bancada de testes estava pronta. E outros 1-1,5 meses eu tive que pegar bugs, adicionar o código e aplicar vários truques para fazer o suporte funcionar.
O mais difícil foi encontrar um bug associado às operações de armazenamento em disco em cache. O experimento funcionou por 2 dias e produziu resultados muito otimistas várias vezes mais rápidos que as simulações. No entanto, o teste do arquivo crítico falhou, o sistema não foi iniciado. Aconteceu que durante o desligamento forçado da máquina virtual, as operações de exclusão que foram armazenadas em cache pelo sistema de arquivos não foram executadas e, portanto, o disco não foi completamente apagado. Como resultado, o algoritmo recebeu resultados incorretos e, por alguns dias, esforçamos todas as nossas convoluções para descobrir tudo.
Em um determinado momento, percebemos que durante a operação contínua o algoritmo foi enterrado em um dos segmentos do sistema de arquivos e começou a tentar excluir os mesmos arquivos (na esperança de um novo resultado). Isso acontecia às vezes quando o algoritmo ficava nas regiões onde a maioria era necessária, enquanto se escolhia o intervalo errado para exclusão. Nesse ponto, decidimos adicionar uma lista de arquivos de reorganização. Ou seja, depois de algumas iterações, a lista de arquivos foi embaralhada. Isso ajudou a tirar o algoritmo dessas varas.
Quando tudo estava pronto, lançamos essas duas VMs por três dias. No total, foram aprovadas cerca de 600 iterações, entre as quais houve mais de 20 lançamentos bem-sucedidos. Ficou claro que esse experimento pode ser executado por um longo período de tempo, bem como em máquinas mais poderosas, para encontrar o tamanho ideal de arquivo para a execução do Windows. Além disso, o algoritmo pode ser distribuído por várias máquinas para acelerar ainda mais esse processo
No nosso caso, além do Windows, havia apenas Python e nosso serviço no disco. Em três dias, conseguimos reduzir o número de arquivos de 70 mil para 50 mil. A lista de arquivos foi reduzida em apenas 28%, mas ficou claro que essa abordagem está funcionando e permite determinar o conjunto mínimo de arquivos necessários para carregar o sistema operacional.
Estrutura de serviço
Vamos tocar em uma pequena estrutura de serviço. O módulo de serviço principal é um gerenciador de filas. Como obtemos uma lista de arquivos do driver, precisamos restaurar os arquivos dessa lista. Para isso, criamos um turno com prioridades.
Temos uma lista de arquivos que são restaurados por sua vez. E se novas solicitações de acesso aparecerem, os arquivos necessários com urgência serão restaurados com prioridade. Devido a isso, no início da fila, haverá os arquivos que o usuário realmente precisa agora e no final da linha - os arquivos que poderão ser necessários no futuro. Mas com o trabalho ativo do usuário, uma “fila de objetos extraordinários” pode ser formada, bem como uma lista de arquivos que estão sendo restaurados no momento. Além disso, a operação de pesquisa deveria ter sido aplicada a todas essas filas ao mesmo tempo. Infelizmente, não encontramos uma implementação dessa fila que pudesse definir várias prioridades de arquivo, enquanto apoiava a pesquisa e também alterava as prioridades em tempo real. Não queríamos nos adaptar às estruturas de dados existentes e, portanto, tivemos que escrever nossas próprias e configurar a capacidade de trabalhar com elas.
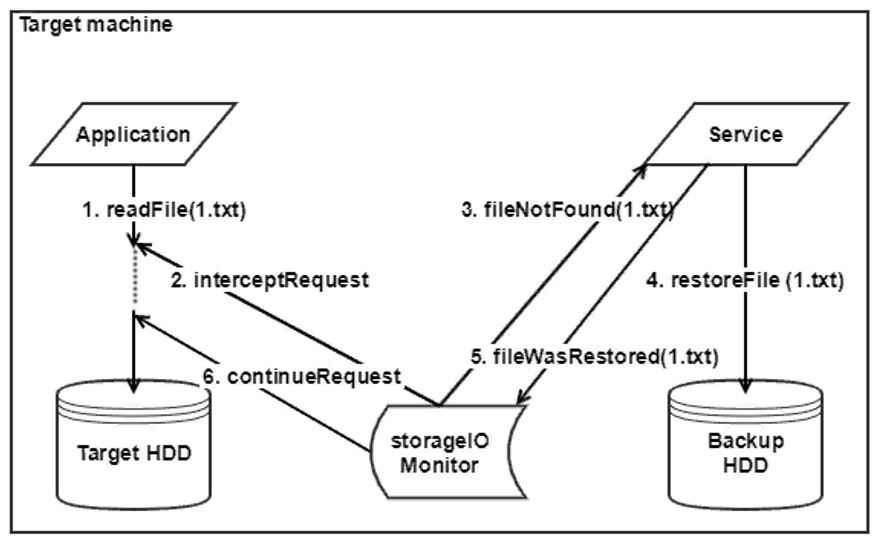
Nosso serviço precisará se comunicar primeiro com o driver em que Daulet trabalhou e, em seguida, com os componentes responsáveis pela restauração de arquivos ... Portanto, para iniciantes, decidimos criar nosso próprio pequeno emulador do sistema de recuperação, que poderia emitir arquivos de uma unidade externa para que eles pudessem ser restaurar e testar o serviço.
No total, foram fornecidos dois modos de operação - normal e recuperação. No modo normal, o driver nos envia uma lista de arquivos afetados pela inicialização do SO. Em seguida, enquanto o sistema está em execução, o driver monitora todas as operações de arquivo e envia notificações para o nosso serviço e, por sua vez, altera a lista de arquivos. No modo de recuperação, o driver notifica o serviço que a recuperação do sistema é necessária. O serviço enfileira arquivos, executa agentes de software que solicitam arquivos de backup e inicia o processo de recuperação.
Diploma, convite para trabalho e novos projetos
Quando o serviço estava pronto e testado, tivemos a última atividade no projeto. Foi necessário atualizar e estruturar todos os artefatos que acumulamos, além de apresentar nossos resultados ao cliente e à universidade. Para a empresa, este foi mais um passo em direção à implementação do projeto, para a universidade com nossa tese de graduação.
Após a apresentação, uma proposta foi feita aos alunos. Depois de algumas semanas, vou trabalhar na Acronis. Os resultados do projeto levaram os desenvolvedores a pensar que é possível tornar o serviço mais eficiente, diminuindo-o para o nível do Aplicativo Windows Nativo. Mas mais sobre isso no próximo artigo.