
Saudações habr.
Se alguém executa um sistema de grafite e encontra um problema de desempenho de armazenamento de sussurros (IO, consumo de espaço em disco), a chance de o ClickHouse ter sido lançado como um substituto deve ter como objetivo. Esta declaração implica que uma implementação de terceiros, como carbonwriter ou go-carbon, já é usada como métrica de recebimento do daemon.
ClickHouse resolve bem os problemas descritos. Por exemplo, após a transferência de dados 2TiB do whisper, eles se encaixam em 300GiB. Não vou me aprofundar na comparação em detalhes, há artigos suficientes sobre esse tópico. Além disso, até recentemente, tudo era perfeito com nosso armazenamento ClickHouse.
Problemas de consumo
À primeira vista, tudo deve funcionar bem. Após a documentação , criamos uma configuração para o esquema de armazenamento de métricas ( retention seguir) e, em seguida, criamos uma tabela de acordo com a recomendação do back-end selecionado para grafite-web: carbon-clickhouse + graphite-clickhouse ou graphouse , dependendo da pilha usada. E ... a bomba-relógio chega.
Para entender qual deles, você precisa saber como as inserções e a vida útil adicional dos dados nas tabelas da família de motores MergeTree ClickHouse * (diagramas retirados da apresentação de Alexei Zatelepin):
- Um

- Cada um desses blocos antes de gravar no disco é classificado de acordo com a chave
ORDER BY especificada ao criar a tabela. - Após a classificação, um dado é gravado no disco.
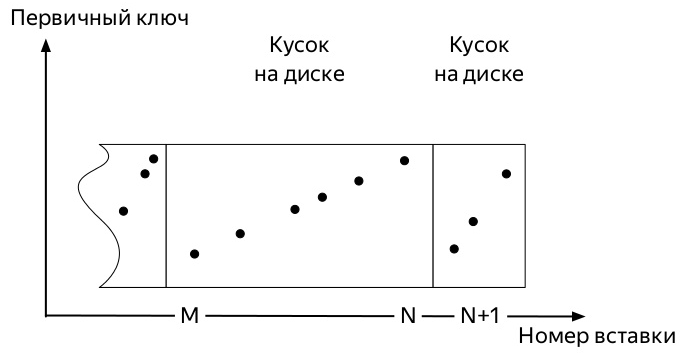
- O servidor monitora em segundo plano que não existem muitas dessas partes e inicia as
merge , a seguir mesclada).
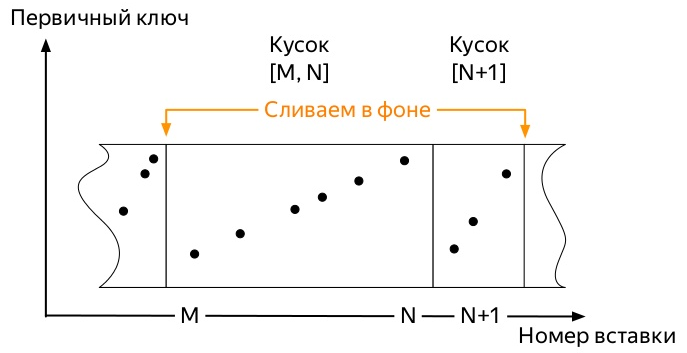

- O servidor para de executar as fusões por conta própria assim que os dados não
partition , mas você pode iniciar o processo manualmente com o comando OPTIMIZE . - Se houver apenas uma peça na partição, não será possível iniciar a mesclagem com o comando usual, você deverá usar
OPTIMIZE ... FINAL
Então, as primeiras métricas chegam. E eles ocupam um certo espaço. Os eventos subsequentes podem variar um pouco, dependendo de muitos fatores:
- A chave de particionamento pode ser muito pequena (dia) ou muito grande (vários meses).
- A configuração de retenção pode acomodar vários limites significativos de agregação de dados na partição ativa (para onde vai o registro de métricas), ou não.
- Se houver muitos dados, as partes mais antigas, que devido à mesclagem em segundo plano, já podem ser enormes (ao escolher uma chave de partição abaixo do ideal), não serão capazes de mexer em pequenas partes novas.
E tudo sempre termina da mesma maneira. O local ocupado pelas métricas no ClickHouse cresce apenas se:
- não aplique
OPTIMIZE ... FINAL manualmente ou - não insira dados em todas as partições continuamente para iniciar uma mesclagem em segundo plano mais cedo ou mais tarde
O segundo método parece o mais fácil de implementar e, portanto, ele está errado e foi testado primeiro.
Eu escrevi um script python bastante simples que enviava métricas falsas para todos os dias nos últimos 4 anos e era executado a cada hora pela coroa.
Como todo o trabalho do ClickHouse DBMS é baseado no fato de que este sistema fará todo o trabalho em segundo plano mais cedo ou mais tarde, mas não se sabe quando, eu não podia esperar até que as peças antigas enormes se unissem para começar a se fundir com as pequenas. Ficou claro que tínhamos que procurar uma maneira de automatizar otimizações forçadas.

Dê uma olhada na estrutura da tabela system.parts . Esta é uma informação abrangente sobre todas as partes de todas as tabelas no servidor ClickHouse. Ele contém, entre outras coisas, as seguintes colunas:
- Nome do
database ( database ); - nome da tabela (
table ); - Nome e ID da
partition ( partition & partition_id ); - quando a peça foi criada (
modification_time ); - data mínima e máxima de uma peça (a partição é feita por dia) (
min_date & max_date );
Há também uma tabela system.graphite_retentions , com os seguintes campos interessantes:
- Nome do banco de dados (
Tables.database ); - nome da tabela (
Tables.table ); - a idade da métrica em que a próxima agregação (
age ) deve ser aplicada;
Então:
- Temos uma tabela de peças e uma tabela de regras de agregação.
- Combine a interseção e obtenha todas as tabelas * GraphiteMergeTree.
- Estamos procurando todas as partições nas quais:
- mais de uma peça
- ou chegou a hora de aplicar a seguinte regra de agregação e
modification_time mais antigo que esse momento.
Implementação
Este pedido SELECT concat(p.database, '.', p.table) AS table, p.partition_id AS partition_id, p.partition AS partition,
retorna cada uma das partições das tabelas * GraphiteMergeTree cuja mesclagem deve liberar espaço em disco. Tudo o que resta é a pequena coisa: analise todos eles com a solicitação OPTIMIZE ... FINAL . A implementação final também levou em consideração o momento em que não há necessidade de tocar nas partições com um registro ativo.
É exatamente isso que o projeto grafite-ch-otimizer faz. Ex-colegas da Yandex.Market testaram no produto, o resultado do trabalho pode ser visto abaixo.

Se você executar o programa no servidor com ClickHouse, ele começará a funcionar no modo daemon. Uma vez por hora, uma solicitação será executada, verificando se há novas partições com mais de três dias que podem ser otimizadas.
Em um futuro próximo - para fornecer pelo menos pacotes deb e, se possível - também rpm.
UPD: os pacotes estão disponíveis nas versões do github e as imagens de trabalho podem ser encontradas no docker-hub no repositório innogames / graphite-ch-optimizer.
Em vez de uma conclusão
Nos últimos nove meses, passei muito tempo dentro da minha empresa InnoGames no cruzamento da ClickHouse e da grafite-web. Foi uma boa experiência, que tornou possível mudar rapidamente do whisper para o ClickHouse como um repositório de métricas. Espero que este artigo seja como o início de um ciclo sobre quais melhorias foram feitas por nós em várias partes dessa pilha e o que será feito no futuro.
Vários litros de cerveja e dias de administração foram gastos no desenvolvimento de pedidos junto com o v0devil , pelo qual quero expressar minha gratidão a ele. E também para revisar este artigo.
Página do projeto no github