O PostgreSQL usa estatísticas acumuladas na distribuição de valores de dados nas tabelas de destino para selecionar o plano de execução de consulta mais eficiente.
Ele é atualizado executando explicitamente os comandos
ANALYZE e
VACUUM ANALYZE ou em segundo plano pelo processo
autovacuum / autoanalyze . Mas se as estatísticas não tiverem tempo para serem atualizadas - poderão ocorrer problemas.
Como detectar e corrigir esse problema?
A principal opção quando essa situação pode acontecer é se o conjunto de dados mudou drasticamente na tabela. Ou seja,
gerou um grande número de INSERT / UPDATE / DELETE ou simplesmente "derramou" os dados em uma tabela vazia - por exemplo,
ao restaurar a partir de um backup .
A ajuda do
utilitário de recuperação padrão
pg_restore diz explicitamente:
Após a recuperação, faz sentido executar ANALYZE para cada tabela restaurada para que o otimizador receba estatísticas atualizadas.
Portanto, se você estiver fazendo algo semelhante com o banco de dados - não seja preguiçoso, execute imediatamente
ANALYZE para as tabelas mais "ousadas" ou para o banco de dados inteiro.
Determinamos a presença de um problema
Qual é a aparência da situação "todo ruim" exatamente por causa disso? Geralmente algo como isto:
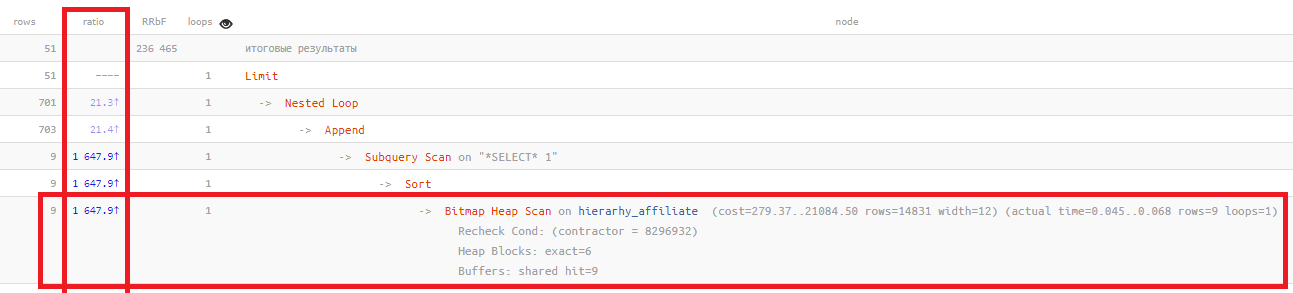
A coluna de
proporção mostra apenas a relação "às vezes" entre o número de registros planejados com base nas estatísticas e o número realmente lido:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
Quanto maior esse valor, pior as estatísticas refletem a situação real na sua tabela. Normalmente, geralmente
não excede centenas , neste exemplo,
mil e quinhentas vezes .
Isso leva à escolha de um plano ineficaz e, como resultado, à
carga mais selvagem da base . Para removê-lo rapidamente, basta ouvir as recomendações do manual e passar por
ANALYZE nas tabelas principais.
Aqui está a carga da CPU no servidor de banco de dados antes e depois desta operação, para o exemplo acima:
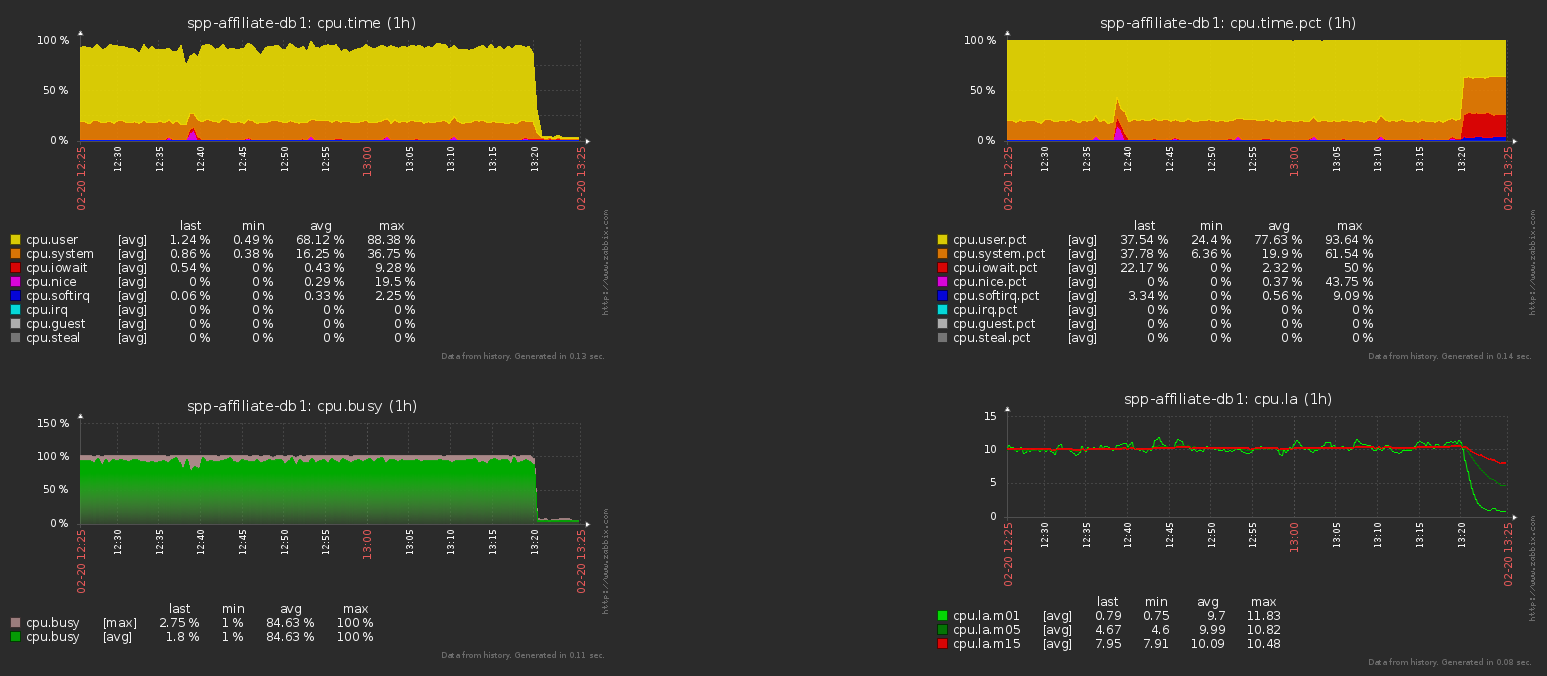
Tabela atualizada com freqüência
Mas e se a tabela realmente alterar um grande número de registros? Por exemplo, esse é algum tipo de buffer ou fila de processamento em que novos registros são adicionados constantemente e antigos são excluídos.
Nesse caso, os seguintes
parâmetros de configuração nos ajudarão:
autovacuum_naptime (número inteiro)
Define o atraso mínimo entre duas execuções de limpeza automática para um único banco de dados. O daemon de limpeza automática varre o banco de dados no intervalo de tempo especificado e emite os comandos VACUUM e ANALYZE quando necessário para as tabelas nesse banco de dados. Se esse valor for especificado sem unidades, será considerado definido em segundos. Por padrão, o atraso é de um minuto (1min). Este parâmetro pode ser definido apenas no postgresql.conf ou na linha de comandos quando o servidor iniciar.
autovacuum_analyze_threshold (número inteiro)
Define o número mínimo de tuplas adicionadas, modificadas ou excluídas nas quais o ANALYZE será executado para uma única tabela. O valor padrão é 50 tuplas. Este parâmetro pode ser definido apenas no postgresql.conf ou na linha de comandos quando o servidor iniciar. No entanto, esse valor pode ser substituído por tabelas selecionadas alterando suas configurações de armazenamento.
autovacuum_analyze_scale_factor (ponto flutuante)
Especifica a porcentagem do tamanho da tabela que será adicionada ao autovacuum_analyze_threshold quando o limite do comando ANALYZE for selecionado. O valor padrão é 0,1 (10% do tamanho da tabela). Você pode definir esse parâmetro apenas no postgresql.conf ou na linha de comandos quando o servidor iniciar. No entanto, esse valor pode ser substituído por tabelas selecionadas alterando suas configurações de armazenamento.
SWSS
Às vezes, ao configurar um servidor, o
autovacuum_naptime é "
compactado " para "uma vez por dia" (1d), para
que os autoVACUUMs circulem pelo banco de dados com menos frequência e
consumam menos recursos.
Às vezes, embora muito raramente, isso pode ser justificado - por exemplo, se você tiver
milhares de tabelas / seções em um banco de dados (mesmo que elas estejam dispostas em padrões diferentes).
Como a própria definição de quais tabelas específicas da lista inteira precisam ser processadas, durante a inicialização do processo de autovacuum, ela
pode ocupar um compartilhamento considerável de recursos e diminuir a velocidade do servidor .
Nesse caso, você terá problemas com uma tabela modificada com frequência.
Aqui - defina um intervalo de inicialização mais adequado ou siga ANALYZE de acordo com essa tabela no modo “manual” por alguns motivos aplicados (por exemplo, um timer externo ou após o final do próximo estágio do processamento da fila).
Camarada, mantenha as estatísticas atualizadas!