Oi Habr!
O crédito à habitação é um sistema grande e muito dinâmico, que às vezes é difícil de acompanhar. Para ajudar os funcionários a acompanhar todas as novidades e mudanças e acompanhar o ritmo em todos os lugares, estamos introduzindo ativamente algoritmos de aprendizado de máquina. Em nosso banco, os bots de bate-papo já fazem parte do trabalho dos operadores, as análises de clientes são analisadas não apenas por especialistas, mas também por algoritmos inteligentes para o processamento de linguagem natural.
Hoje vou contar como ajudamos os especialistas na operação de serviços bancários a se livrarem da necessidade de olhar constantemente para os painéis dos sistemas de monitoramento, ou seja, eles pediram que o aprendizado de máquina o ajudasse. Foi o que conseguimos.

Como funciona o monitoramento manual?
O local de trabalho típico de um especialista em operações é semelhante à figura acima e ele passa a maior parte do tempo olhando para painéis. Qualquer atividade suspeita no sistema, por exemplo, quando a rede cair ou chover uma NullPointerException, atrairá imediatamente a atenção - uma investigação começará imediatamente.
O homem não é uma máquina. Ele pode se distrair, ir jantar, atender o telefone. E quando o número de gráficos excede cem, torna-se difícil amarrá-los todos e chegar ao fundo da essência.
Outro problema é que há uma família de erros que ocorrem constantemente, mas não afetam seriamente o comportamento do sistema. Por exemplo, um microsserviço de terceiros caiu e os painéis tremeram notavelmente, mas, na verdade, o sistema está fora de perigo. À primeira vista, nem sempre é claro como o comportamento anormal é crítico e o que está por trás dele. Para estabelecer os motivos em detalhes, você precisa ir ao servidor e aprofundar-se nos logs. Essa operação deve ser realizada dezenas de vezes ao dia. Vamos pelo menos confiá-la parcialmente no carro.
Aprendizado de máquina como um assistente inteligente
Existem três fontes principais de dados: Zabbix, ElasticSearch e um sistema interno de monitoramento de métricas de negócios. Usamos o Zabbix para monitorar o hardware, a rede e a disponibilidade de vários pontos de entrada nos sistemas. Usando o ElasticSearch, analise e extraia o log de mensagens. Vários erros, execuções e consultas são usados como métricas. Os analistas de negócios, no entanto, monitoram o desempenho dos usuários: o número de transferências, vendas e outras atividades de negócios. Os dados são coletados com uma frequência de uma vez por minuto e adicionados ao banco de dados. Bem, como os dados são coletados, é hora de escrever um monte de ifs para colocar o aprendizado de máquina em batalha.
Formulamos o problema da seguinte maneira: tendo as métricas do sistema na entrada, classificaremos o estado final do sistema: regular ou anormal. Nesse cenário, o problema se encaixa perfeitamente no paradigma da aprendizagem com um professor. Isso significa que todo o conjunto de dados de treinamento deve ser rotulado. Em outras palavras, cada minuto da operação do sistema deve ter um rótulo de 0 (comportamento normal) ou -1 (comportamento anômalo).
Na vida, acontece que nem tudo é tão róseo quanto gostaríamos. Como regra, nem todos os incidentes são registrados no JIRA, muito permanece no correio e não vai além, e às vezes os prazos da anomalia são borrados ou imprecisos. Acontece que criar um conjunto de dados de alta qualidade no campo de dados históricos não é uma tarefa trivial.
Enquanto os novos dados estão apenas começando a ser definidos, vamos tentar extrair os benefícios do que já temos. Nos casos em que os dados não possuem uma marcação, são utilizados algoritmos de aprendizado sem um professor. Prosseguiremos com o fato de que na maioria das vezes o sistema funciona corretamente, mas ocasionalmente acontecem imprevistos: bugs (onde sem eles), a base caiu, ou, por exemplo, a escavadeira Petr atingiu o cabo do data center. Portanto, reduzimos nossa tarefa à busca de anomalias, a saber, a busca de um novo comportamento do sistema (Novelty Detection).
Para fazer isso, use o algoritmo Floresta isolada. Ele já está implementado na biblioteca sklearn. Usaremos métricas dos sistemas de monitoramento como recursos.
clf = IsolationForest(behaviour='new', max_samples=100, random_state=rng, contamination='auto')
Treinaremos Floresta Isolada em dados históricos e usaremos os novos dados que já conseguimos marcar para avaliar a qualidade. Portanto, resta escolher os hiperparâmetros do modelo e o tamanho do conjunto de dados para treinamento.
Agora, os dados de status, coletados a cada minuto, são inseridos no modelo treinado e obtêm o rótulo 0 ou -1.
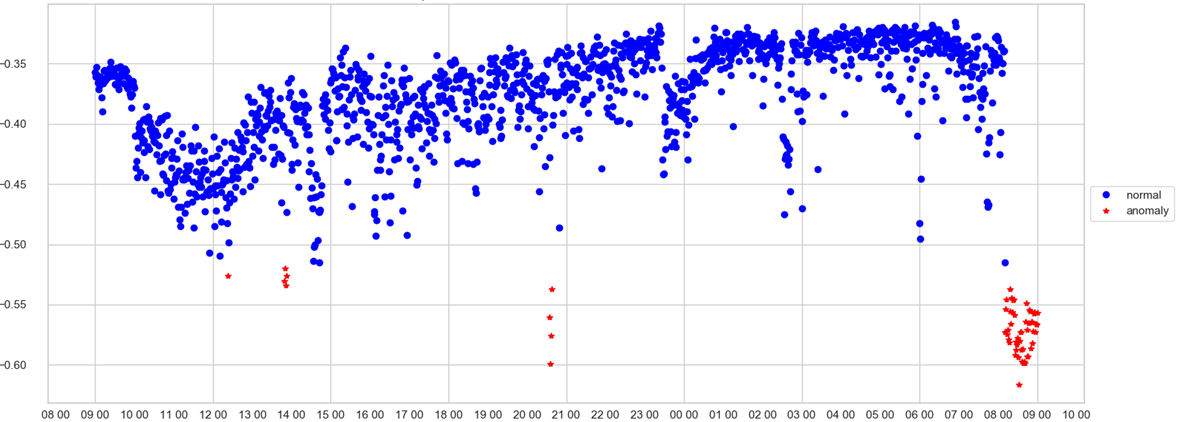
Um operador pode rastrear apenas uma programação. No eixo X - tempo, no escore da anomalia Y, isto é, com que intensidade o modelo considerou o estado do sistema neste minuto anormal. Se o valor da velocidade passou pelo compartimento do lixo (que o modelo seleciona por si mesmo), o ponto é colorido em vermelho e uma anomalia é registrada.
Agora aprendemos que o sistema opera em um modo incomum ou que uma situação de emergência aconteceu quase em tempo real. Isso é muito bom, mas e o operador na hora de receber o sinal sobre a anomalia? Qual painel olhar? Vamos tentar abrir a “caixa preta” do nosso modelo e entender como ele toma decisões.
Interpretando um modelo usando LIME
Existem diferentes abordagens sobre como abrir a caixa preta de um modelo treinado e entender o que está na mente da máquina. Com uma regressão logística ou uma árvore de decisão, tudo fica claro, não é difícil entender com base na qual a decisão foi tomada. Com a Floresta Isolada, as coisas são mais complicadas. Primeiro, há um acidente dentro do algoritmo e, segundo, é um algoritmo de aprendizado sem professor.
O primeiro candidato foi a biblioteca LIME, que utiliza a abordagem agnóstica do modelo, que ajuda a interpretar qualquer modelo, o principal é que a saída do modelo tem uma distribuição probabilística entre as classes. Ok, é claro, o resultado não é probabilidade, mas em breve, mas vamos tentar normalizá-los no intervalo de 0 a 1 e tratá-lo como probabilidade. Assim, conseguimos fornecer um formato de entrada compatível com o LIME.
A maneira como o LIME interpretou os resultados foi decepcionante. Em primeiro lugar, como interpretação, havia vários sinais mais importantes na saída e, na maioria dos casos, apenas um deles realmente refletia adequadamente a essência da decisão, e o restante acrescentava ruído. A segunda desvantagem era que a interpretação era instável e frequentemente produzia diferentes listas de sinais de uma corrida para outra. Para obter resultados mais estáveis, era necessário executar a interpretação várias vezes e, de alguma forma, calcular a média dos resultados. Eu realmente não queria fazer isso.
SHAP - ponte de pessoa para carro
Depois disso, nossos olhos se voltaram para outra biblioteca para a interpretação de modelos - SHAP. A idéia por trás da biblioteca veio da teoria dos jogos. A biblioteca também tem uma bela visualização. Depois de examinar os exemplos, percebemos com frustração que o SHAP não conseguia interpretar a Floresta Isolada, e realmente queríamos! Mas, por outro lado, o SHAP pode dissecar o XGBoost com confiança. Pensamos: e se formos ensinados a fazer o XGBoost a mesma coisa que a Floresta Isolada pode fazer? Para fazer isso, pegamos todo o conjunto de dados e o marcamos com Floresta isolada. Além disso, como alvo, eles não tiveram uma aula, mas uma pontuação, que foi atribuída à Floresta Isolada. Vamos prever por todas as métricas a velocidade que a Floresta Isolada daria, mas apenas com o XGBoot! Mal disse o que fez. Executaremos nosso conjunto de dados marcado através do XGBoost. E agora, agora ele sabe prever a velocidade da mesma maneira que a Floresta Isolada. Viva, agora podemos usar o SHAP!
A primeira etapa é criar um objeto TreeExplainer, passando o próprio modelo como parâmetro. Em seguida, os valores de shap são calculados, o que nos permite dar uma explicação de como o modelo tomou essa ou aquela decisão.
explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X)
O SHAP permite interpretar o modelo como um todo e os resultados para exemplos específicos. Por exemplo, você pode obter uma explicação para um exemplo específico usando o método force_plot (), que recebe os valores de entrada e os valores do próprio exemplo.
shap.force_plot(explainer.expected_value,shap_values[0,:], X.iloc[0,:])
O gráfico a seguir mostra quais recursos do modelo e o quanto influenciaram a decisão.

Ajudamos os negócios
Agora, sabendo quais métricas contribuíram significativamente para a taxa geral de anormalidade, torna-se possível estabelecer em que nível o problema surgiu e, o mais importante, se afetou os usuários finais do sistema.

Cada vez que uma anomalia é detectada, é obtida uma lista de métricas que têm maior impacto na decisão. Se a lista incluir métricas que rastreiam diretamente indicadores relacionados aos negócios, isso é mencionado no alerta de uma maneira especial, aumentando automaticamente a prioridade da anomalia.
Este é apenas o primeiro, mas importante, passo para fortalecer e automatizar o sistema de monitoramento usando o aprendizado de máquina, o que pode aumentar significativamente a velocidade de identificação das causas e influência do comportamento anormal do sistema.
Referências:scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.htmlgithub.com/marcotcr/limegithub.com/slundberg/shap