 Fonte
FonteOlá Habr! Meu nome é Maxim Pchelin e lidero o desenvolvimento do BI-DWH na MyGames (divisão de jogos do Mail.ru Group). Neste artigo, falarei sobre como e por que criamos um armazenamento DataLake orientado para o cliente.
O artigo consiste em três partes. Primeiro, explicarei por que decidimos implementar o DataLake. Na segunda parte, descreverei quais tecnologias e soluções usamos para que o armazenamento possa funcionar e ser preenchido com dados. E na terceira parte, descreverei o que fazemos para melhorar a qualidade de nossos serviços.
O que nos trouxe ao DataLake
Na
MyGames, trabalhamos no departamento BI-DWH e prestamos serviços de duas categorias: um repositório para analistas de dados e serviços regulares de relatório para usuários de negócios (gerentes, profissionais de marketing, desenvolvedores de jogos e outros).
Por que esse armazenamento não padrão?
Normalmente, o BI-DWH não implica a implementação do armazenamento DataLake; isso não pode ser chamado de uma solução típica. E como então esses serviços são construídos?
Normalmente, uma empresa tem um projeto - no nosso caso, isso é um jogo. O projeto possui um sistema de registro que grava mais frequentemente dados no banco de dados. No topo dessa base, as fachadas de lojas são criadas para agregados, métricas e outras entidades para análises futuras. Os relatórios regulares são criados com base nas vitrines das lojas, usando qualquer ferramenta de BI adequada, bem como nos sistemas de análise Ad-Hoc, começando com consultas simples do SQL e tabelas do Excel e terminando com o Jupyter Notebook para DS e ML. Todo o sistema é suportado por uma equipe de desenvolvimento.
Suponha que outra empresa nasça em uma empresa. Ter outra equipe de desenvolvimento e infra-estrutura é atraente, mas caro. Portanto, o projeto precisa ser "conectado". Isso pode ser feito de diferentes maneiras: no nível do banco de dados, no nível da loja ou pelo menos no nível de exibição - o problema foi resolvido.
E se a empresa tiver um terceiro projeto? O "compartilhamento" já pode terminar mal: pode haver problemas com a alocação de recursos ou direitos de acesso. Por exemplo, um dos projetos é realizado por uma equipe externa que não precisa saber nada sobre os dois primeiros. A situação está se tornando mais arriscada.
Agora imagine que não há três projetos, mas muito mais. E aconteceu que esse é exatamente o nosso caso.
A MyGames é uma das maiores divisões do Grupo Mail.ru, temos 150 projetos em nosso portfólio. Além disso, eles são todos muito diferentes: seu próprio desenvolvimento e adquiridos para operações na Rússia. Eles trabalham em várias plataformas: PC, Xbox, Playstation, iOS e Android. Esses projetos são desenvolvidos em dez escritórios em todo o mundo, com centenas de tomadores de decisão.

Para os negócios, isso é ótimo, mas complica a tarefa da equipe do BI-DWH.
Nos nossos jogos, muitas ações dos jogadores são registradas: quando ele entrou no jogo, onde e como conseguiu os níveis, com quem e com que sucesso ele lutou, com que moeda e por que comprou. Precisamos coletar todos esses dados para cada um dos jogos.
Precisamos disso para que a empresa possa receber respostas para suas perguntas sobre os projetos. O que aconteceu na semana passada após o lançamento da ação? Quais são as nossas previsões de receita ou uso das capacidades do servidor de jogos para o próximo mês? O que pode ser feito para influenciar essas previsões?
É importante que o MyGames não imponha um paradigma de desenvolvimento nos projetos. Cada estúdio de jogo registra dados por considerá-los mais eficientes. Alguns projetos geram logs no lado do cliente, outros no servidor. Alguns projetos usam o RDBMS para coletá-los, enquanto outros usam ferramentas completamente diferentes: Kafka, Elasticsearch, Hadoop, Tarantool ou Redis. E recorremos a essas fontes de dados para carregá-las no repositório.
O que você quer do nosso BI-DWH?
Primeiro, do departamento de BI-DWH, eles desejam receber dados de todos os nossos jogos para resolver tarefas operacionais diárias e estratégicas. Começando de quantas vidas para dar um monstro terrível no final do nível, e terminando com a forma de distribuir recursos dentro da empresa: quais projetos devem dar mais desenvolvedores ou quem deve alocar um orçamento de marketing.
A confiabilidade também é esperada de nós. Trabalhamos em uma grande empresa e não podemos viver de acordo com o princípio de "Ontem trabalhamos, mas hoje o sistema está em vigor e só aumentará em uma semana se surgir alguma coisa".
Eles querem economias de nós. Ficaríamos felizes em resolver todos os problemas comprando ferro ou contratando pessoas. Mas somos uma organização comercial e não podemos permitir isso. Tentamos fazer a empresa lucrar.
Importante, eles querem que o foco do cliente seja nosso. Neste caso, os clientes são nossos consumidores, clientes: gerentes, analistas, etc. Precisamos nos adaptar aos nossos jogos e trabalhar de forma que seja conveniente que os clientes cooperem conosco. Por exemplo, em alguns casos, quando compramos projetos no mercado asiático para operações, junto com o jogo, podemos obter bases com nomes em chinês. E a documentação para essas bases em chinês. Poderíamos procurar um desenvolvedor de ETL com conhecimento de chinês ou recusar-se a baixar dados do jogo, mas, em vez disso, a equipe e eu nos trancamos na sala de reuniões, pegamos o relógio e começamos a jogar. Entre e saia do jogo, compre, atire, morra. E olhamos, o que e quando aparece nesta ou naquela tabela. Em seguida, escrevemos a documentação e, com base nisso, criamos o ETL.
Nesse caso, é importante sentir a vantagem. Entrar no registro único de um jogo com um DAU de 50 pessoas, quando você precisa ajudar um projeto com um DAU de 500.000 nas proximidades, é um luxo inadmissível. Portanto, é claro, podemos dedicar muito esforço na criação de uma solução personalizada, mas apenas se os negócios realmente precisarem.
No entanto, assim que os desenvolvedores, especialmente os iniciantes, souberem que terão que se adaptar dessa maneira, eles desejam nunca mais fazer isso. Qualquer desenvolvedor quer criar uma arquitetura ideal, nunca alterá-la e escrever artigos sobre ela na Habr.
Mas o que acontece se pararmos de nos ajustar aos nossos jogos? Suponha que começemos a exigir que eles enviem dados para uma única API de entrada? O resultado será um - todos começarão a se dispersar.
- Alguns projetos começarão a cortar suas soluções de BI-DWH, com preferência e poetisas. Isso levará à duplicação de recursos e dificuldades na troca de dados entre sistemas.
- Outros projetos não puxarão a criação do BI-DWH, mas também não vão querer se adaptar ao nosso. E ainda outros vão parar de usar dados, o que é ainda pior.
- Bem, e mais importante, a gerência não terá informações sistemáticas atualizadas sobre o que está acontecendo nos projetos.
Poderíamos implementar o armazenamento de uma maneira simples?
150 projetos é muito. Implementar a solução imediatamente para todos é muito longo. As empresas não esperam um ano para que os primeiros resultados apareçam. Portanto, pegamos 3 projetos que geram receita máxima e implementamos o primeiro protótipo para eles. Queríamos coletar dados-chave e criar painéis básicos com as métricas mais populares - DAU, MAU, Receita, registros, retenção, além de um pouco de economia e previsões.
Não podemos usar as bases de jogo dos projetos para isso. Em primeiro lugar, isso tornaria a análise de projeto cruzado mais difícil devido à necessidade de agregar dados de vários bancos de dados. Em segundo lugar, os próprios jogos funcionam sobre esses bancos de dados, o que é importante para que os mestres e réplicas não sejam sobrecarregados. Finalmente, em algum momento, todos os jogos excluem todo o histórico de dados que eles não precisam em seus bancos de dados, o que é inaceitável para análises.
Portanto, a única opção é coletar tudo o que você precisa para análise em um único local. Nesse ponto, qualquer banco de dados relacional ou repositório de texto sem formatação nos convinha. Dane-se BI e construímos painéis. Existem muitas opções para combinações de tais soluções:

Mas entendemos que mais tarde precisaríamos cobrir todos os outros 150 jogos. Talvez algum banco de dados relacional de cluster possa lidar com a quantidade de dados gerados. Mas as fontes não estão localizadas apenas em sistemas completamente diferentes, mas também possuem estruturas de dados muito diferentes. Conhecemos estruturas relacionais, Data Vault e outras. Não funcionará para colocar tudo isso em um banco de dados sem truques complexos e trabalhosos.
Tudo isso nos levou a entender que precisamos construir um DataLake.
Implementação do DataLake
Primeiro de tudo, o armazenamento DataLake é adequado para nossas condições, pois permite armazenar dados não estruturados. O DataLake pode se tornar um ponto de entrada único para todas as fontes diversas, desde tabelas de RDBMS a JSON, que enviamos de Kafka ou Mongo. Como resultado, o DataLake pode se tornar a base para análises de design cruzado implementadas com base em interfaces para vários consumidores: SQL, Python, R, Spark e assim por diante.
Mudar para o Hadoop
Para o DataLake, escolhemos a solução óbvia - Hadoop. Especificamente, sua montagem de Cloudera. O Hadoop permite trabalhar com dados não estruturados e é facilmente escalável adicionando nós de dados. Além disso, este produto foi bem estudado, portanto, a resposta para qualquer pergunta pode ser encontrada no Stackoverflow e não gastar recursos em P&D.
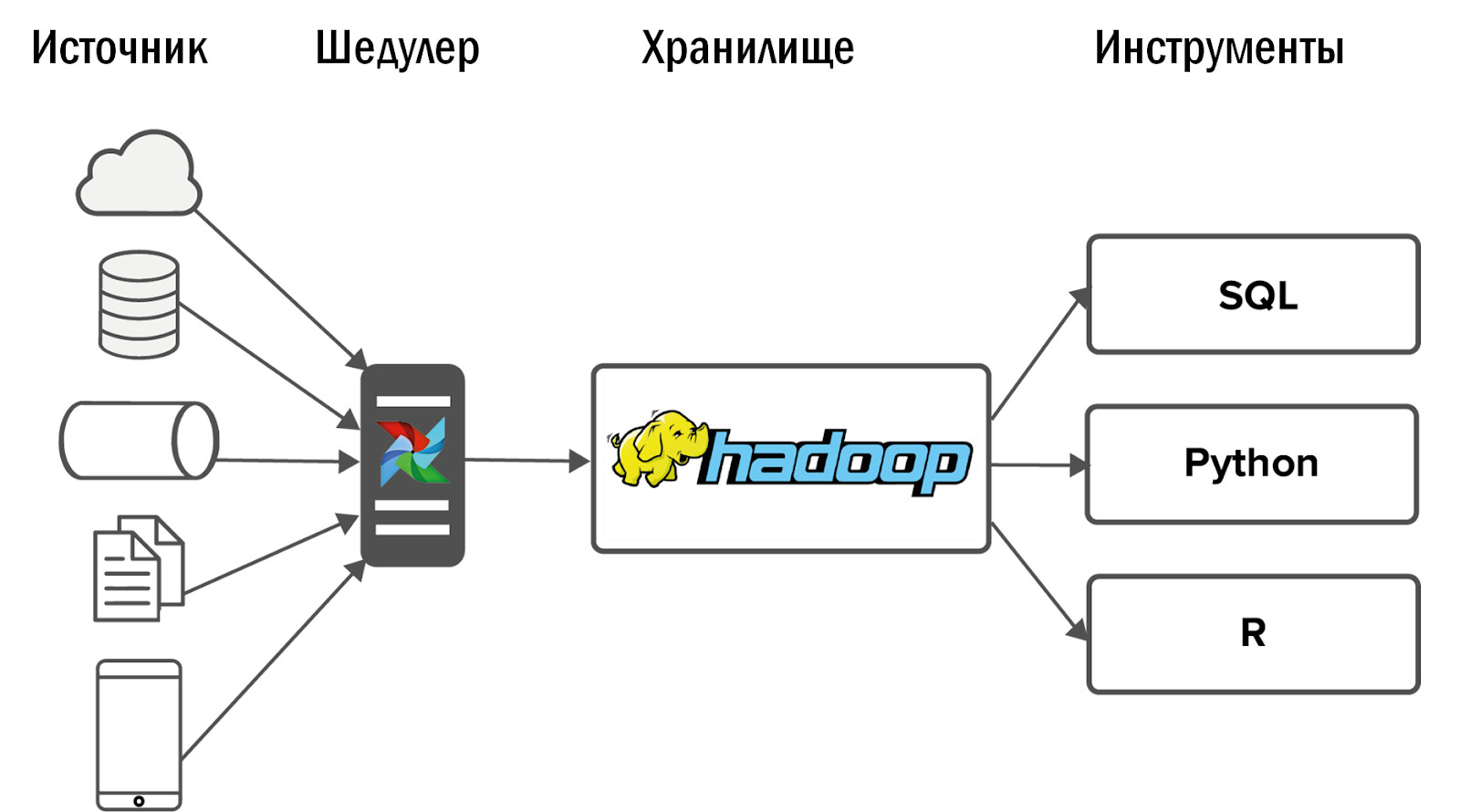
Após a implementação do Hadoop, obtivemos o seguinte diagrama do nosso primeiro armazenamento unificado:

Os dados foram coletados no Hadoop a partir de um pequeno número de fontes e, em seguida, várias interfaces foram inseridas nele: ferramentas e serviços de BI para análises Ad-Hoc.
Outros eventos se desenvolveram inesperadamente: nosso Hadoop começou perfeitamente e os clientes para os quais os dados fluíram para a loja abandonaram antigos sistemas analíticos e começaram a usar o novo produto diariamente para o trabalho.
Mas surgiu um problema: quanto mais você faz, mais eles querem de você. Muito rapidamente, os projetos que já estavam integrados ao Hadoop começaram a solicitar mais dados. E os projetos que ainda não foram adicionados começaram a pedir. Os requisitos de estabilidade começaram a crescer acentuadamente.
Ao mesmo tempo, não é razoável simplesmente aumentar a equipe linearmente. Se dois desenvolvedores de DWH lidam com dois projetos, em quatro projetos não podemos contratar mais dois desenvolvedores. Portanto, primeiro fomos para o outro lado.
Estabelecimento do processo
Com recursos limitados, a solução mais barata é ajustar os processos. Além disso, em uma grande empresa, é impossível criar uma arquitetura de armazenamento e implementá-la. Tem que negociar com um grande número de pessoas.
- Primeiro de tudo, com representantes de negócios que alocam recursos para análise. Você terá que provar que precisa implementar apenas as tarefas de seus clientes que beneficiarão os negócios.
- Você também precisa negociar com os analistas para que eles ofereçam algo em troca dos serviços que você fornece - análise do sistema, análise de negócios, testes. Por exemplo, demos a análise do sistema de nossas fontes de dados aos analistas. Obviamente, eles não estão felizes, mas, caso contrário, simplesmente não haverá ninguém para fazê-lo.
- Por último, mas não menos importante, você precisa negociar com os desenvolvedores de jogos: instalar SLAs e concordar com uma estrutura de dados. Se os campos estão constantemente desaparecendo, aparecendo e renomeando, não importa o tamanho da equipe, você sempre sentirá falta das suas mãos.
- Você também precisa negociar com sua própria equipe: procure um compromisso entre as soluções ideais que todos os desenvolvedores desejam criar e as soluções padrão que não são tão interessantes, mas que podem ser rebitadas de maneira barata e rápida.
- Será necessário concordar com os administradores no monitoramento da infraestrutura. Embora assim que você tenha recursos adicionais, é melhor contratar seu próprio especialista em DevOps na equipe de armazenamento.
Nesse ponto, eu poderia terminar o artigo se essa variante do repositório atender a todos os objetivos definidos para ele. Mas isso não é verdade. Porque
Antes do Hadoop, podíamos fornecer dados e estatísticas para cinco projetos. Com a implementação do Hadoop e sem um aumento na equipe, conseguimos cobrir 10 projetos. Após o estabelecimento dos processos, nossa equipe já atendeu 15 projetos. Isso é legal, mas temos 150 projetos e precisávamos de algo novo.
Implementação do fluxo de ar
Inicialmente, coletamos dados de fontes usando o Cron. Dois projetos são normais. 10 - dói, mas tudo bem. No entanto, agora cerca de 12 mil processos são carregados diariamente para carregar de 150 projetos no DataLake. Cron não é mais adequado. Para fazer isso, precisamos de uma ferramenta poderosa para gerenciar fluxos de download de dados.
Escolhemos o Airflow Task Manager de código aberto. Ele nasceu nas entranhas do Airbnb, após o qual foi transferido para o Apache. Esta é uma ferramenta para ETL controlado por código. Ou seja, você escreve um script em Python e ele é convertido em um DAG (gráfico acíclico direcionado). Os DAGs são ótimos para manter dependências entre tarefas - você não pode construir uma fachada usando dados que ainda não foram carregados.
O fluxo de ar possui um ótimo manipulador de erros. Se um processo falhar ou houver um problema com a rede, o expedidor reiniciará o processo o número de vezes que você especificar. Se houver muitas falhas, por exemplo, a tabela na origem foi alterada, uma mensagem de notificação chega.
O Airflow possui uma ótima interface do usuário: exibe convenientemente quais processos estão em execução, quais foram concluídos com sucesso ou com erro. Se as tarefas apresentarem erros, você poderá reiniciá-las a partir da interface e controlar o processo através do monitoramento sem entrar no código.
O fluxo de ar é personalizável, construído sobre operadores - esses são plugins para trabalhar com fontes específicas. Alguns operadores saem da caixa, muitos escreveram a comunidade Airflow. Se desejar, você pode criar seu próprio operador, a interface para isso é muito simples.
Como usamos o fluxo de ar?
Por exemplo, precisamos carregar uma tabela do PostgreSQL no Hadoop. A tarefa
sql_sensor_battle_log verifica se a fonte possui os dados que precisamos para ontem.
load_stg_data_from_battle_log caso, a tarefa
load_stg_data_from_battle_log dados do PG e os adiciona ao Hadoop. Finalmente,
load_oda_data_from_battle_log executa o processamento inicial: digamos, convertendo do Unix Time para o tempo legível por humanos.
Nessa cadeia de tarefas, os dados são obtidos de uma entidade em uma fonte:

E assim - de todas as entidades que precisamos de uma fonte:
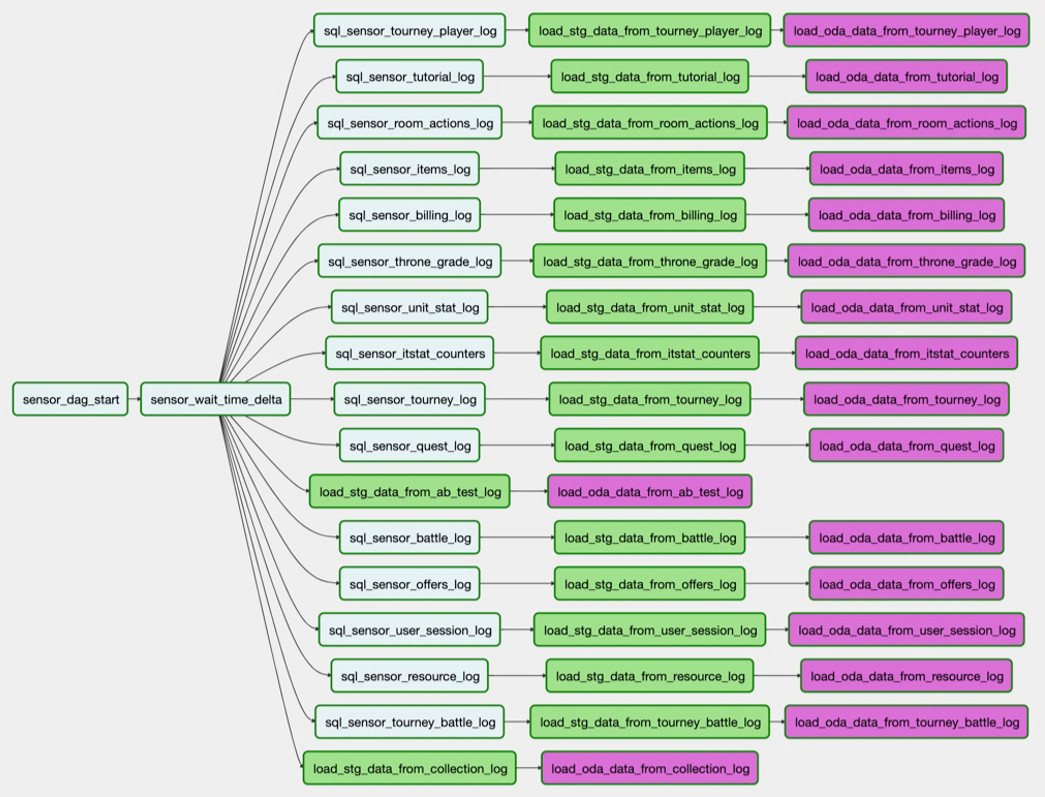
Esse conjunto de downloads é o DAG. No momento, temos 250 desses DAGs para carregar dados brutos, processar, transformar e criar fachadas de lojas.
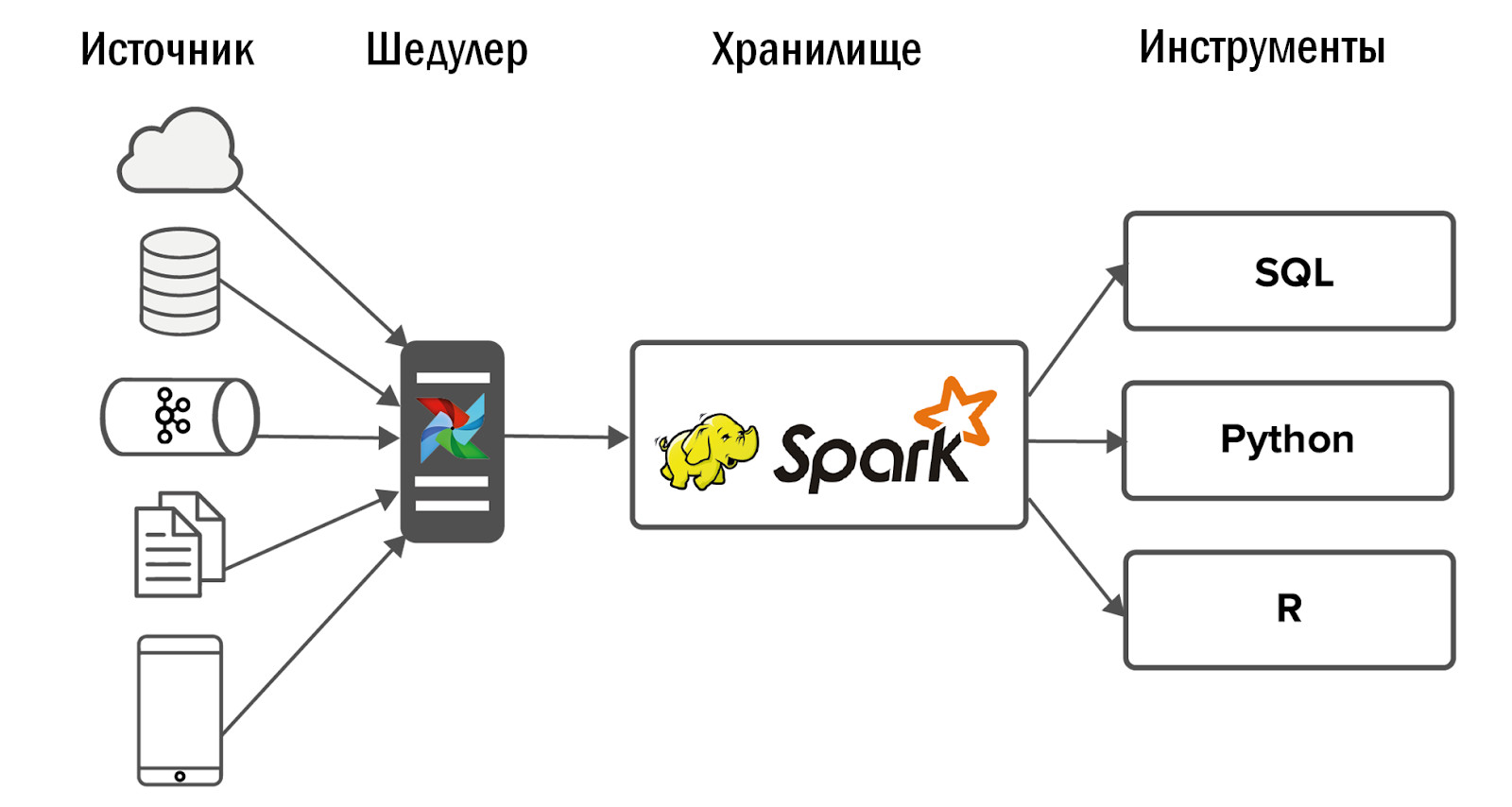
O esquema de armazenamento unificado atualizado é o seguinte:
- Após a introdução do Airflow, conseguimos um aumento acentuado no número de fontes - até 400 peças. As fontes de dados são internas (dos nossos jogos) e externas: sistemas estatísticos adquiridos, APIs heterogêneas. É o Airflow que nos permite executar e controlar diariamente 12 mil processos que processam dados de todos os nossos 150 jogos.
- Em mais detalhes sobre o nosso fluxo de ar, Dean Safina escreveu em seu artigo ( https://habr.com/ru/company/mailru/blog/344398/ ). E também participe da comunidade Airflow no Telegram ( https://t.me/ruairflow ). Muitas perguntas sobre o Airflow podem ser resolvidas com a ajuda da documentação, mas às vezes aparecem mais solicitações personalizadas: como posso incluir o Airflow na janela de encaixe, por que não funciona no terceiro dia e tudo mais. Isso pode ser respondido nesta comunidade.
O que melhorar no DataLake
Neste ponto, os desenvolvedores do DWH estão confiantes de que tudo está pronto e agora você pode se acalmar. Infelizmente ou felizmente, ainda há algo a ser reforçado no DataLake.
Qualidade dos dados
Com um grande número de tabelas no DataLake, a qualidade dos dados é a primeira a sofrer. Por exemplo, pegue uma tabela com pagamentos. Ele contém user_id, valor, data e hora do pagamento:
Cerca de 10 mil pagamentos ocorrem todos os dias:

Uma vez na tabela do dia, vieram apenas 28 entradas. Sim, e user_id está vazio:
Se algo de repente surgir em nossa fonte, graças ao Airflow, saberemos imediatamente. Porém, se formalmente houver dados, e mesmo no formato correto, não aprenderemos imediatamente sobre o detalhamento e já com os consumidores de dados. Não é realista checar nossas 5000 mesas com nossas próprias mãos.
Para evitar isso, desenvolvemos nosso próprio sistema de controle de qualidade de dados (DQ). Todos os dias, ele monitora downloads importantes em nosso repositório: rastreia mudanças repentinas no número de linhas, procura campos vazios e verifica a duplicação de dados. O sistema também aplica verificações personalizadas de analistas. Com base nisso, ela envia notificações por e-mail sobre o que deu errado e onde. Os analistas vão aos projetos e descobrem por que, por exemplo, há muito poucos dados, eliminam os motivos e recarregamos os dados.
Priorizar downloads
Com o crescente número de tarefas para carregar dados no DataLake, surge rapidamente um conflito de prioridades. A situação usual: algum projeto não tão importante consumia todos os recursos com seus downloads durante a noite e as tabelas necessárias para calcular as métricas para a alta gerência não têm tempo para carregar até o início do dia útil. Lidamos com isso de várias maneiras.
- Monitorando downloads de chaves. O Airflow possui seu próprio sistema de SLA, que permite determinar se todas as chaves chegaram a tempo. Se alguns dados não forem carregados, descobriremos isso algumas horas antes dos usuários e teremos tempo para corrigi-los.
- Configuração de prioridade. Para fazer isso, usamos a fila do Airflow e o sistema prioritário. Ele nos permite determinar a ordem de carregamento dos DAGs e o número de processos paralelos neles. Não faz sentido fazer upload de logs que são analisados uma vez por trimestre, antes de baixar dados para as métricas da alta gerência.
Monitorando a duração do lote noturno
Temos um armazenamento em lote. À noite, estamos construindo e é importante garantir que haja noite suficiente para processar o lote diário. Caso contrário, durante o horário de trabalho, os analistas não terão recursos de armazenamento suficientes para funcionar. Resolvemos esse problema regularmente de várias maneiras:
- Escala reversa. Não enviamos todos os dados, mas apenas o que os analistas precisam. Monitoramos todas as tabelas carregadas e, se uma delas não for usada por seis meses, desativamos o carregamento.
- Capacitação. Se entendermos que estamos limitados por recursos de rede, número de núcleos ou capacidade de disco, adicionaremos nós de dados ao Hadoop.
- Otimização do fluxo de ar dos trabalhadores. Estamos fazendo tudo para que cada parte do nosso sistema seja usada ao máximo em todos os momentos do tempo de construção do armazenamento.
- Refatoração de processos não ideais. Por exemplo, consideramos a economia de um jogo novo e levamos 5 minutos. Porém, após um ano, os dados aumentam e a mesma solicitação é processada por 2 horas. Em algum momento, precisamos nos reajustar ao recálculo incremental, embora no início isso possa parecer uma complicação desnecessária.
Controle de Recursos
É importante não apenas ter tempo para concluir a preparação do repositório para o início do dia útil, mas também monitorar a disponibilidade de seus recursos depois disso. Com isso, podem surgir dificuldades ao longo do tempo. Primeiro, o motivo é que os analistas escrevem consultas abaixo do ideal. Novamente, os próprios analistas estão se tornando cada vez mais. A coisa mais simples neste caso: aumentar a capacidade do hardware. No entanto, uma solicitação não ideal ainda ocupará todos os recursos disponíveis. Ou seja, mais cedo ou mais tarde você começará a gastar dinheiro em ferro sem benefícios significativos. Portanto, usamos várias outras abordagens.
- Cotação: deixamos aos usuários pelo menos um pouco de recursos. Sim, os pedidos serão executados lentamente, mas pelo menos serão.
- Monitoramento de recursos consumidos: quantos núcleos são usados por solicitações de usuários, que se esqueceram de usar partições no Hadoop e utilizaram toda a RAM, etc. ele. Se tivéssemos poucos projetos, rastrearíamos o consumo de recursos por conta própria. Mas com tantos, teríamos que contratar uma equipe de monitoramento em constante expansão, separada. E, a longo prazo, isso não é razoável.
- Treinamento voluntário e obrigatório para o usuário. O trabalho dos analistas não é escrever consultas de qualidade no seu repositório. O trabalho deles é responder a perguntas de negócios. E além de nós mesmos - a equipe de repositórios - ninguém se importa com a qualidade das solicitações dos analistas. Portanto, criamos perguntas frequentes e apresentações, realizamos palestras para nossos analistas, explicamos como podemos trabalhar com nosso DataLake e como não.
De fato, gastar tempo disponibilizando dados é muito mais importante do que preenchê-los. Se houver dados no armazenamento, mas eles não estiverem disponíveis, do ponto de vista comercial, eles ainda estarão lá e seus esforços para fazer o download já foram gastos.
Flexibilidade de arquitetura
É importante não esquecer a flexibilidade do DataLake construído e não ter medo de alterar a arquitetura ao alterar os fatores de entrada: quais dados precisam ser carregados no armazenamento, quem os usa e como. Não acreditamos que nossa arquitetura sempre permaneça inalterada.
Por exemplo, lançamos um novo jogo para celular. Ela escreve JSON no Nginx a partir de clientes, o Nginx lança dados para o Kafka, analisamos usando o Spark e os colocamos no Hadoop. Tudo funciona, a tarefa está encerrada.
Alguns meses se passaram e, no armazenamento, todos os processos do lote noturno começaram a durar mais. Estamos começando a descobrir qual é o problema: acontece que o jogo "disparou", 50 vezes mais dados foram gerados e o Spark não conseguiu lidar com a análise JSON, arrastando metade dos recursos de armazenamento. Inicialmente, todos os dados foram enviados para um tópico Kafka e o Spark os classificou em diferentes entidades. Pedimos aos desenvolvedores de jogos que compartilhassem dados de clientes com diferentes entidades e os incluíssem em tópicos separados do Kafka. Tornou-se mais fácil, mas não por muito tempo. Decidimos mudar da análise JSON diária para horária. No entanto, as instalações de armazenamento começaram a ser construídas não apenas à noite, mas 24 horas por dia, o que era indesejável para nós. Após essas tentativas, para resolver esse problema, abandonamos o Spark e implementamos o ClickHouse.

Ele possui um ótimo mecanismo de análise JSON que decompõe dados instantaneamente em tabelas. Primeiro enviamos informações do Kafka para o ClickHouse e, a partir daí, as coletamos no Hadoop. Isso resolveu completamente o nosso problema.
Obviamente, tentamos não criar sistemas zoológicos em nosso armazenamento DataLake, mas tentamos selecionar as tecnologias mais adequadas para tarefas específicas.
Valeu a pena?
Valeu a pena implantar o Hadoop, um sistema de controle de qualidade, lidar com o Airflow e estabelecer processos de negócios? Claro que valeu a pena:
- A empresa possui informações atualizadas sobre todos os projetos, disponíveis em serviços únicos.
- Os usuários do nosso sistema, de designers de jogos a gerentes, pararam de tomar decisões apenas com base na intuição e mudaram para as abordagens baseadas em dados.
- Demos aos analistas as ferramentas para criar sua própria ciência de foguetes. Agora, eles respondem a consultas comerciais complexas, criam modelos de previsão, sistemas de recomendação e aprimoram os jogos. Na verdade, para isso, trabalhamos em BI-DWH.