Na
People & Screens , trabalhamos com empresas on-line há muitos anos como parceiro de publicidade. Quando tivemos a ideia de avaliar a contribuição da publicidade gráfica nas vendas de lojas on-line, ela parecia irrealizável e até louca. Assim que percebemos que todos os elementos do mosaico podem ser encontrados e reunidos, decidimos experimentá-lo. As primeiras hipóteses começaram a ser confirmadas, juntamente com o
Data Insight, aprofundamos essa história e, em poucos meses de trabalho meticuloso, criamos um estudo que, de fato, é uma ferramenta de trabalho aplicada - um modelo para avaliar a eficácia da publicidade em 12 categorias de produtos de comércio eletrônico. Neste artigo, falaremos sobre os resultados e os métodos de análise utilizados.
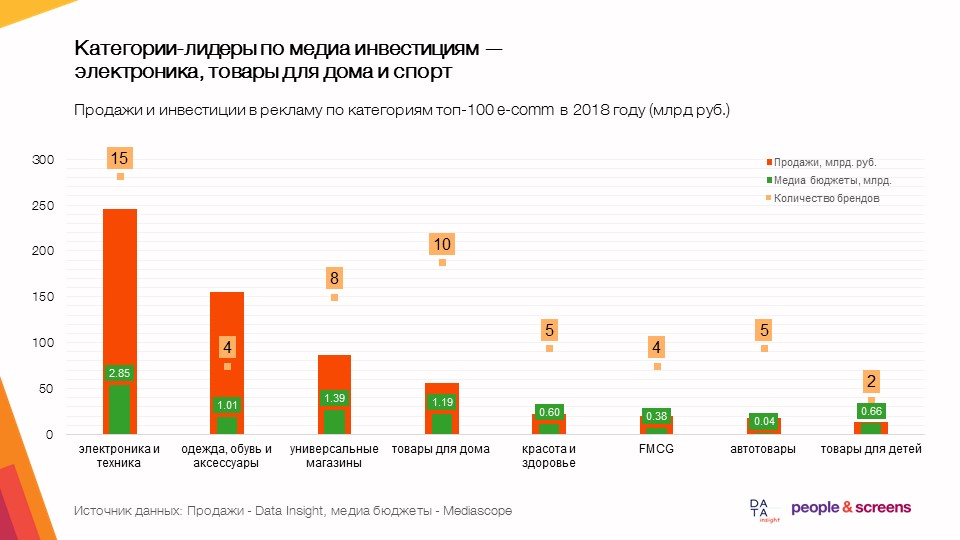
Objetivos e Resultados da Pesquisa
A principal hipótese do nosso estudo: a publicidade gráfica, desenvolvendo a marca de uma loja on-line, aumenta a conversão em todo o funil de vendas. Na análise dos dados de vendas, publicidade e dados externos nos últimos quatro anos, a hipótese foi confirmada. Como resultado, criamos modelos de vendas econométricos para 60 lojas on-line em 12 categorias de produtos.
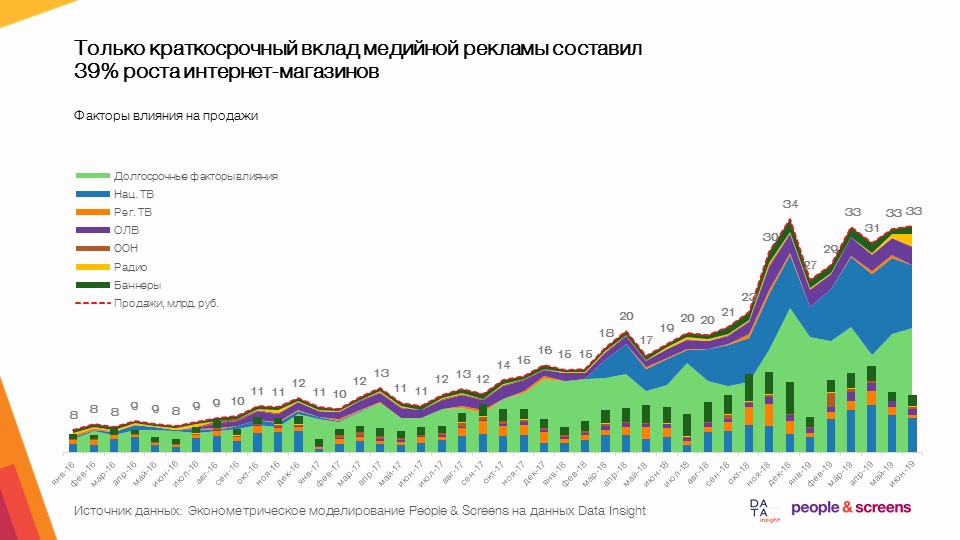
- Somente a contribuição de curto prazo da publicidade gráfica alcançou um crescimento de 39% nas lojas on-line, com uma dinâmica de mercado média de 50 a 60%.
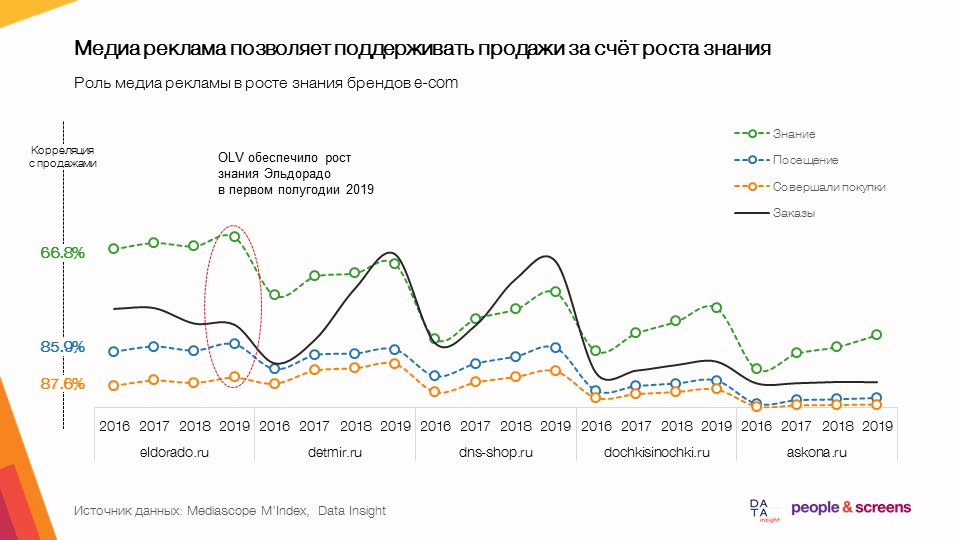
- A publicidade gráfica permite que você apóie as vendas por meio de um maior conhecimento.
- O maior retorno global do comércio eletrônico vem da publicidade em vídeo online.
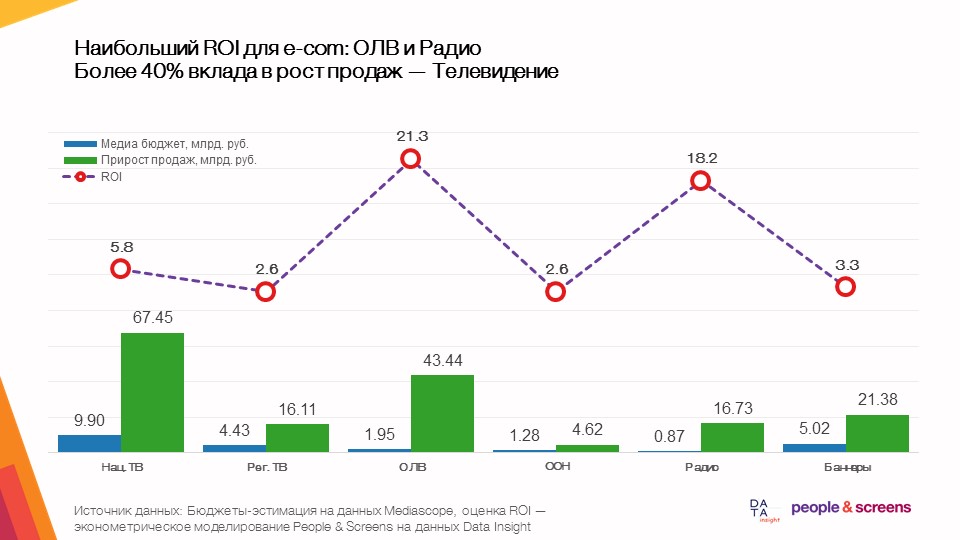
- A eficiência da mídia depende muito da categoria: nas categorias de vestuário e hipermercados on-line, a TV mostrou alta eficiência nos produtos eletrônicos e automotivos - publicidade em vídeo on-line.
O que analisamos
A coleta de dados para o estudo foi realizada pelas duas empresas participantes do estudo. Os seguintes dados foram coletados pela People & Screens:
- Saídas de anúncios gráficos. Usamos downloads dos bancos de dados Mediascope aos quais todos os grupos de anúncios têm acesso. Descarregamos os custos de publicidade de todos os contatos de mídia e publicidade para um grande público-alvo (Todos os 18 anos) em detalhes por dia (para publicidade na TV, rádio, imprensa, Internet) e por mês (para publicidade ao ar livre) no período de janeiro de 2016 até junho de 2019. Para maximizar a velocidade do trabalho nesta fase, usamos o desenvolvimento interno da Dentsu Aegis Network Russia para trabalhar com dados industriais, em particular a plataforma Atomizer.
- Descarregar dados do SimilarWeb diariamente nos últimos 18 meses. Examinamos a dinâmica em dias de visitas no computador / dispositivo móvel, a dinâmica em dias de tráfego de desktops por origem (canal) e a dinâmica de instalações no Android.
- Dinâmica do conhecimento / visitas / compras do banco de dados do TGI / Índice de Marketing para o período 2016-2019, por trimestres. Este é um download do software industrial Gallileo da Mediascope.
- Consultas de pesquisa do Google Trends de janeiro de 2016 a julho de 2019 na Rússia.
No lado do Data Insight, os seguintes dados foram coletados e fornecidos:
- A dinâmica dos pedidos para 72 lojas on-line do ranking TOP-100 por mês, para o período de janeiro de 2016 a agosto de 2019.
- Os dados do contador li.ru para o período de janeiro de 2018 a agosto de 2019 (tráfego para o site, total separadamente, apenas na Rússia e apenas dispositivos móveis) para sites TOP-11.
- Os dados do contador mail.ru para o período de junho de 2017 a setembro de 2019 para 53 sites.
- Dados do contador de passeador para o período de junho de 2017 a setembro de 2019 para 38 sites.
- Os dados de consulta de pesquisa do Yandex Wordstat por 24 meses, de outubro de 2017 a setembro de 2019.
- Avaliação das verificações médias das 100 melhores lojas online a partir de 2018.
Algoritmo de dados
A coleta de dados para o estudo foi realizada em várias etapas. Deixaremos fora do escopo do artigo o trabalho que nossos colegas do Data Insight realizaram para gerar os dados necessários para o estudo, mas informaremos o trabalho realizado no lado de Pessoas e telas:
- Pesquise todas as lojas on-line da classificação TOP-100 nos bancos de dados industriais disponíveis e compile dicionários de correspondência de nomes. Para isso, usamos o mecanismo de busca semântica do Elasticsearch .
- Formação de modelos e upload de dados neles. Nesse estágio, o mais importante era pensar previamente na arquitetura das tabelas de dados.
- Combinando dados de todas as fontes em um único conjunto de dados (conjunto de dados).
Para fazer isso, usamos o processamento dos dados carregados no Python usando os pacotes pandas e sqlalchemy . O conjunto de hacks de vida aqui é bastante padrão:
Ao processar dados brutos de tabelas csv maiores que 1 milhão de linhas, primeiro carregamos os nomes das colunas da tabela com uma consulta no formulário:
col_names = pd.read_csv(FILE_PATH,sep=';', nrows=0).columns
os tipos de dados foram adicionados pelo dicionário:
types_dict = {'Cost RUB' : int } types_dict.update({col: str for col in col_names if col not in types_dict})
e os próprios dados carregam a função
pd.read_csv(FILE_PATH, sep=';', usecols=col_names, dtype=types_dict, chunksize=chunksize)
Os resultados da conversão foram enviados para o PostgreSQL. - Validação cruzada da dinâmica de pedidos com base na análise da dinâmica de tráfego, consultas de pesquisa e vendas reais no conjunto de clientes da agência People & Screens. Aqui, construímos matrizes de correlação usando df.corr () em diferentes conjuntos de dados em um site fixo, depois analisamos detalhadamente a série "suspeita" com discrepâncias. Essa é uma das etapas principais do estudo, na qual verificamos a confiabilidade da dinâmica dos indicadores estudados.
- Construção de modelos econométricos em dados validados. Aqui, usamos as transformadas diretas e inversas de Fourier do pacote numpy ( funções np.fft.fft e np.fft.ifft ) para extrair a sazonalidade, uma aproximação suave para estimar a tendência e o modelo de regressão linear ( linear_model ) do pacote sklearn para estimar a contribuição da publicidade. Ao escolher uma classe de modelos para esta tarefa, partimos do fato de que o resultado da simulação deve ser facilmente interpretado e usado para avaliar numericamente a eficácia da publicidade, levando em consideração a qualidade dos dados. Investigamos a confiabilidade dos modelos, dividindo os dados em amostras de treinamento e teste de um intervalo de tempo variável. I.e. comparamos como o modelo treinado em dados de janeiro de 2016 a dezembro de 2018 se comporta no intervalo de tempo de teste de janeiro a agosto de 2019; depois, treinamos o modelo no intervalo de tempo de janeiro de 2016 a janeiro de 2019 e analisamos como o modelo se comporta nos dados de fevereiro a agosto de 2019 Agosto de 2019. A qualidade dos modelos foi estudada pela estabilidade da contribuição de fatores de publicidade em diferentes amostras de treinamento conforme a previsão na amostra de teste
- O passo final foi preparar uma apresentação com base nos resultados. Aqui estabelecemos uma ponte de modelos matemáticos para conclusões práticas de negócios e mais uma vez testamos os modelos do ponto de vista do senso comum dos resultados.
As especificidades da análise do comércio eletrônico e as dificuldades que surgem no processo
- Na fase de coleta de dados, surgiram dificuldades com a avaliação correta do interesse da pesquisa no recurso. No Google Trends, não há como agrupar consultas de pesquisa e usar palavras-chave negativas, como no Yandex Wordstat. Era importante estudar o núcleo semântico de cada loja online e fazer o upload da solicitação central. Por exemplo, o M.Video precisa ser escrito em russo - esta é a solicitação central para este site.
Para lojas que vendem mercadorias online e offline, os colegas do Data Insight adotaram a seguinte abordagem nos dados do wordstat Yandex:
Verifique se não há perguntas irrelevantes (o principal não é estimar o volume de demanda, mas acompanhar as mudanças na dinâmica). Nós somos suficientemente fortes para filtrar as palavras de pesquisa. Nos casos em que havia o risco do nome da marca de receber solicitações inadequadas, fizemos estatísticas sobre combinações de teclas. Por exemplo, "loja de ozônio" em vez de "ozônio" - com essa abordagem, a popularidade da pesquisa do varejista é subestimada, mas a dinâmica da demanda é medida de maneira mais confiável e limpa do "ruído". Em relação às estatísticas de pesquisa, há um problema metodológico que aparentemente não possui uma solução confiável - para muitos varejistas, essas estatísticas são distorcidas por ferramentas de SEO que otimizam os resultados da pesquisa por fatores comportamentais, mas distorcem as estatísticas da demanda real. - No estágio de combinar dados de diferentes fontes, tornou-se necessário trazer os dados para uma única granularidade: os dados sobre publicidade e tráfego de TV da SimilarWeb eram diários, os dados para consultas de pesquisa eram semanais e os dados de pedidos e medidores eram mensais. Como resultado, formamos um banco de dados separado com campos de data que permitem agregar dados no nível exigido e um banco de dados mensal de agregação em cache para trabalhar mais com todos os detalhes dos dados de vendas.
- No estágio de validação cruzada dos dados, encontramos discrepâncias visíveis na dinâmica das vendas com nossos próprios dados. Isso exigiu uma discussão da situação com colegas do Data Insight. Como resultado, graças a um entendimento preciso dos meses em que ocorrem os maiores erros, os analistas identificaram dois erros que estão no fundo do algoritmo para avaliar a dinâmica mensal de vendas.
- No estágio de desenvolvimento do modelo, várias dificuldades surgiram. Para avaliar corretamente o efeito da publicidade, foi necessário isolar fatores externos. Qualquer dinâmica de vendas (e o comércio eletrônico não são exceções) está associada não apenas à publicidade, mas também a muitos outros fatores: alterações de UX / UI no site, preços, variedade, concorrência, flutuações cambiais etc.
Para resolver esse problema, usamos uma abordagem baseada na análise de regressão de dados por um longo período - de janeiro de 2016 a agosto de 2019. Como parte dessa abordagem, analisamos mudanças (oscilações) na dinâmica de pedidos que podem ser atribuídos à publicidade nesse período.
É importante entender que, se em algum momento um anúncio foi iniciado, mas o valor esperado de vendas, de acordo com o modelo, não era superior ao valor real, o modelo mostrará que esse anúncio não funcionou durante esse período. Obviamente, esse comportamento de vendas pode ser uma superposição de vários fatores (por exemplo, aumentos de preços / lançamento de concorrentes ao mesmo tempo em que a campanha publicitária começa, ou o site "caiu" devido ao fluxo de clientes).
Como calculamos a média dos efeitos durante um longo período de tempo em um grande número de marcas, o efeito dessas coincidências aleatórias deve ser nivelado em uma amostra grande, embora possa levar a efeitos superestimados ou subestimados para marcas individuais. Como resultado, isso nos permitiu determinar regras e padrões gerais para a categoria de comércio eletrônico como um todo. Ao mesmo tempo, para uma análise detalhada da influência da publicidade em marcas individuais, é claro, ainda é necessário estudar todo o conjunto de fatores de influência.
Conclusão
Como parte deste estudo, estabelecemos o objetivo de obter os resultados mais confiáveis com base em dados de fontes heterogêneas. Por si mesmos, esses dados não são valores exatos, mas apenas uma avaliação desses valores por meio de monitoramento de terceiros (monitoramento de saídas de publicidade, dinâmica de tráfego, interesse de pesquisa e, finalmente, pedidos).
Cada link tem limitações na qualidade dos dados, e esse é um problema que analistas e pesquisadores enfrentam em uma escala ou outra todos os dias. Esperamos que, no âmbito deste artigo, tenhamos sido capazes de mostrar quais métodos podem garantir a confiabilidade das conclusões de um estudo analítico, preservando o poder explicativo dos resultados.