Olá pessoal! Meu nome é Denis Oleynik, trabalho como diretor técnico na 1Service.
Em nossa empresa, dedicamos muito tempo ao trabalho com requisitos. À medida que ganhamos experiência, começamos a perceber que as ferramentas comumente usadas no desenvolvimento de produtos de software nos levam a um estado em que não podemos dizer que percebemos exatamente o que o cliente queria de nós. Precisamente porque em algum momento existe uma lacuna nos requisitos coletados inicialmente de sua implementação de software e testes subsequentes.
Essa linha está entre os requisitos registrados no Confluence e as tarefas para sua implementação no Jira. Outra linha vai entre os casos de teste na ferramenta de teste e os mesmos requisitos no Confluence, com atenção ao código associado às tarefas no Jira. A falta de respostas claras para as perguntas: “por que / por que fizemos dessa maneira” ou “fizemos tudo o que o cliente queria de nós” - causou-nos uma intensa preocupação.
E em algum momento nos pareceu que o conceito de "documentação é código" (documentação como código) nos permitirá encontrar respostas para essas perguntas. O conceito “documentação é código” pressupõe que armazenemos requisitos, soluções arquiteturais, instruções do usuário na forma de arquivos de texto simples que podem ser versionados usando sistemas da classe
(D) VCS ; idealmente, os modelos de dados de entrada e saída também devem ser armazenados em um apartamento forma de texto. Documentos reais “legíveis” (assim como módulos executáveis) aparecerão como resultado da montagem do projeto. Nesse caso, a documentação técnica será desenvolvida juntamente com o desenvolvimento de todo o projeto nos mesmos princípios de versionamento de código, o que permitirá atender aos critérios de rastreabilidade, verificação e relevância de ponta a ponta. Além disso, essa abordagem resolve nativamente o problema de organizar a chamada "versão básica dos requisitos" (linhas de base), que para muitos sistemas de gerenciamento de requisitos se torna um problema real. Em particular, no Confluence, recomenda-se resolver esse problema criando uma cópia do espaço original no qual os requisitos foram feitos, enquanto qualquer conexão e hereditariedade dos requisitos são perdidas. Na verdade, este artigo é dedicado à pesquisa de campo desse conceito em nossa empresa.
Antecedentes
O que, em nossa opinião, impede o amplo uso desse conceito entre as massas é a miséria de ferramentas para a representação visual e o gerenciamento de requisitos em forma de texto simples. Isso significa que você não mostrará os arquivos de texto simples, o Dono do produto, para que ele veja o escopo do projeto neles, não é possível exibir arquivos de texto na página de apresentação para as partes interessadas, elas não têm gráficos, tabelas e imagens na fase de edição - e isso já repugna os analistas de negócios que essencialmente deve gerar conteúdo. E apenas os desenvolvedores estão felizes e gritam: “legal! apenas hardcore! mais compromete! ”e outras heresias.
Há outro ponto bastante sutil. Por alguma razão, os apologistas do conceito “documentação é código” têm certeza de que, assim que a documentação estiver próxima ao código no repositório, isso levará à sua adaptação e sincronização obrigatórias com alterações no código, o que permitirá que seja mantido atualizado (
Seção 1.2.1 ) Mas, em nossa opinião, esse momento continuará sendo uma questão de disciplina, porque ninguém se incomoda em alterar o código, e a documentação não muda. Ou seja, a relevância da documentação com essa implementação do conceito é deixada para o gerenciamento do processo de desenvolvimento, onde a etapa obrigatória antes do lançamento é "verificar a relevância da documentação". Nesse caso, “a documentação é um código” não vai muito longe dos arquivos do Word, se você não levar em conta alguma automação em matéria de compilação dos documentos resultantes.
Bem, sim - em primeiro lugar, é "inconveniente, amado, seco" e, em segundo lugar, os chips técnicos "cobrem com um pano" o problema de atualizar a documentação. Existe um estereótipo comum: "estamos de prontidão - mas não precisamos de documentação!" Para dizer o mínimo, isso não é inteiramente verdade. Gosto de refutar esse erro comparando as abordagens de Caso de Uso e História de Usuário do excelente livro de Karl Wigers, “Desenvolvimento de Requisitos de Software” [4]. Se relacionarmos as abordagens de desenvolvimento baseadas nas Histórias de Usuários com a metodologia Agile, a Wigers formulará a evolução dos requisitos com base nas Histórias de Usuários desta maneira:
Histórico do usuário → (discussões) → Histórico do usuário atualizado (com critérios de aceitação) → (discussões) → Testes de aceitação
(p. 169, fig. 8-1). Portanto, a documentação de saída como resultado da evolução dos requisitos iniciais em projetos de desenvolvimento ágil são testes de aceitação. Hoje, uma técnica bastante comum para organizar testes de aceitação é usar scripts de teste escritos na linguagem
Gherkin [5], armazenados nos chamados arquivos de recursos (simples, texto).
Portanto,
para apoiar a implementação do conceito “documentação é código” em projetos ágeis, precisamos de uma ferramenta que acompanhe a evolução dos requisitos, desde o formato da História do Usuário até os testes de aceitação , que, como resultado de sua execução bem-sucedida, gerem documentação atualizada. Infelizmente, até o momento, não existe uma ferramenta que suporte totalmente esse processo (ou pelo menos postule seu desejo de apoiá-lo).
Arquitetura da ferramenta de pesquisa
Portanto, não há ferramenta, mas quero explorar o conceito. Do desespero, tivemos que desenvolvê-lo. Se uma ferramenta desse tipo (vamos chamá-la de StoryMapper) já existia, que tipo de arquitetura ela teria para se integrar de maneira discreta, com o mínimo de esforço, a um ecossistema existente do processo de desenvolvimento? Se esse já é um processo de desenvolvimento integrado, provavelmente o loop
CI / CD já está em execução nele, e o sistema de controle de versão, provavelmente baseado em git, certamente será usado. Nesse caso, o diagrama abaixo mostra o local do StoryMapper durante o processo de desenvolvimento:
Fig. 1 Lugar da ferramenta StoryMapper na estrutura do processo de desenvolvimentoAssim, o StoryMapper irá interagir diretamente com os serviços de hospedagem dos repositórios git e com o loop
CI / CD . A integração com os serviços de hospedagem git é necessária para obter a coleção atual de arquivos de recursos (se houver), bem como colocar os resultados das alterações nos arquivos de recursos, arquivos de serviços relacionados à documentação da estruturação, exemplos de dados de entrada e saída de volta ao repositório, etc. . etc. Interação com o
CI contorno
/ CD necessária para ser capaz de executar o teste de cenário de montagem (manual ou programada), e para os resultados dos testes posteriores - para combiná-los com um correspondente longas-arquivos (tais Obra th será verificar e verificar a relevância documentação).
Você precisa entender que o StoryMapper dificilmente precisa reivindicar o título de "mais um editor Gherkin". Sim, a capacidade básica de editar arquivos de recursos deve ser definida, mas estamos cientes de que, se
BA ou
QA optarem por VSC, Sublime, Notepad ++ ou até vi (por que não?), Convença-os a trabalhar com requisitos apenas no StoryMapper a tarefa não é tão ingrata, mas incorreta. Portanto, assumimos que a possibilidade de uso diversificado do StoryMapper deve ser estabelecida, em particular: o desenvolvimento de recursos em seu editor favorito e o StoryMapper é usado para estruturar arquivos de recursos prontos. Mais sobre isso na seção instruções de pesquisa.
Funcionalidade mínima exigida
Como o StoryMapper está atualmente no estado MVP, esses são os requisitos mínimos que fizemos para que ele possa realmente começar a ser usado:
- Mapeamento de histórias baseado em Git;
- Editor de pepino;
- Lançamento da montagem de testes de cenário (manualmente e de acordo com o cronograma);
- Reflexão dos resultados dos testes de cenário no mapa de histórias de usuários.
Não vou me debruçar sobre a funcionalidade da ferramenta, pois o tópico deste artigo é o curso da operação e não o bisturi do cirurgião.
Áreas de Pesquisa
A idéia principal é a seguinte:
se, usando o conceito de "documentação é código", você não atende aos requisitos do cliente e escreve algum tipo de documentação arbitrária ao escrever o código, essa documentação desaparece e se torna irrelevante tão rapidamente quanto a versão com arquivos no formato MS Word Portanto, queríamos pensar e explorar a opção de usar o conceito em relação ao ciclo completo de desenvolvimento. Por outro lado, também estávamos interessados no momento de transição em que a equipe não utiliza o conceito “documentação é um código”, mas há um desejo de aplicá-lo - como agir nesse caso?
Portanto, o StoryMapper é uma ferramenta, não regula o único caso de uso verdadeiro. Pelo contrário, cada usuário em potencial pode ver suas opções para usar a ferramenta. Focamos em três áreas principais:
- Desenvolvimento flexível: de um mapa da história a testes de aceitação;
- Estruturar e visualizar uma coleção de arquivos de recursos;
- Monitoramento de produtividade.
Abaixo, descreverei em detalhes os resultados que alcançamos em cada direção.
Desenvolvimento flexível: de cartões de histórias a testes de aceitação
Essa direção envolve o desenvolvimento de um novo produto ou o aprimoramento de um existente. O trabalho nessa direção ocorreu sob o codinome "BDDSM": como uma combinação da técnica de mapeamento de histórias e da metodologia de desenvolvimento do
BDD . E isso criou raízes.
Portanto, para iniciantes, um repositório git é criado para arquivos de recursos, uma ramificação é alocada nele para interagir com o StoryMapper. Um projeto é criado no StoryMapper, conectado a analistas de negócios que trabalharão no projeto. Comunicando-se com as partes interessadas, os analistas de negócios começam a formular uma visão comum do produto e corrigi-lo na forma de um esqueleto de um mapa de histórias de usuários [1,2], primeiro um esboço do primeiro nível de
UF :
 Fig. 6 esqueleto de nível superior do mapa de histórias de usuários (clicável)
Fig. 6 esqueleto de nível superior do mapa de histórias de usuários (clicável)E, gradualmente, preenchendo o segundo nível de atividades do usuário:
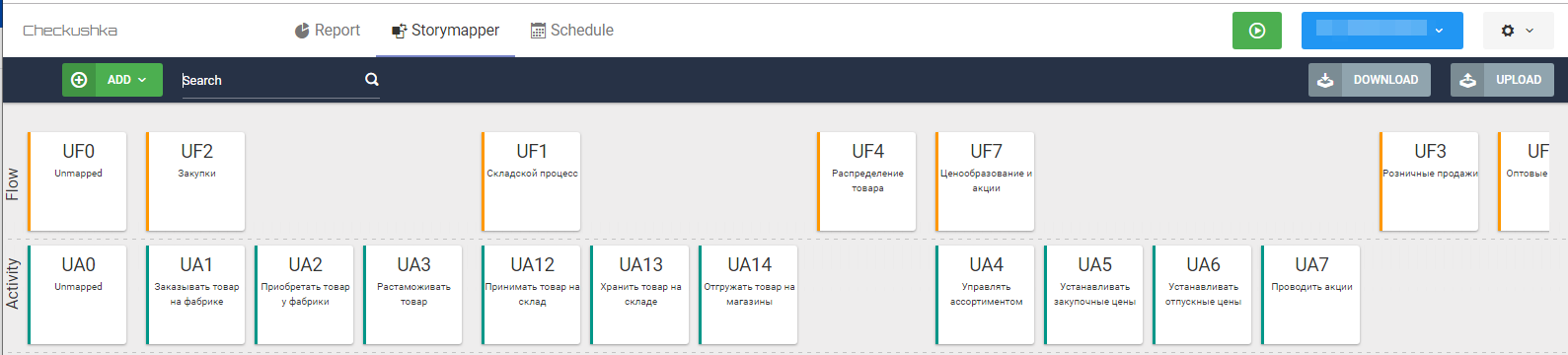 Fig. 7 Esqueleto de segundo nível do mapa de histórias de usuários
Fig. 7 Esqueleto de segundo nível do mapa de histórias de usuáriosComo cada cartão é um arquivo de texto, no estágio de coleta de requisitos (se o cartão for compilado no decorrer da comunicação com o usuário) ou no estágio de pós-processamento das entrevistas, os resultados da comunicação são transferidos diretamente para os cartões
UF e
UA . Essa é a base para uma decomposição adicional de requisitos ao nível de histórias de usuários.
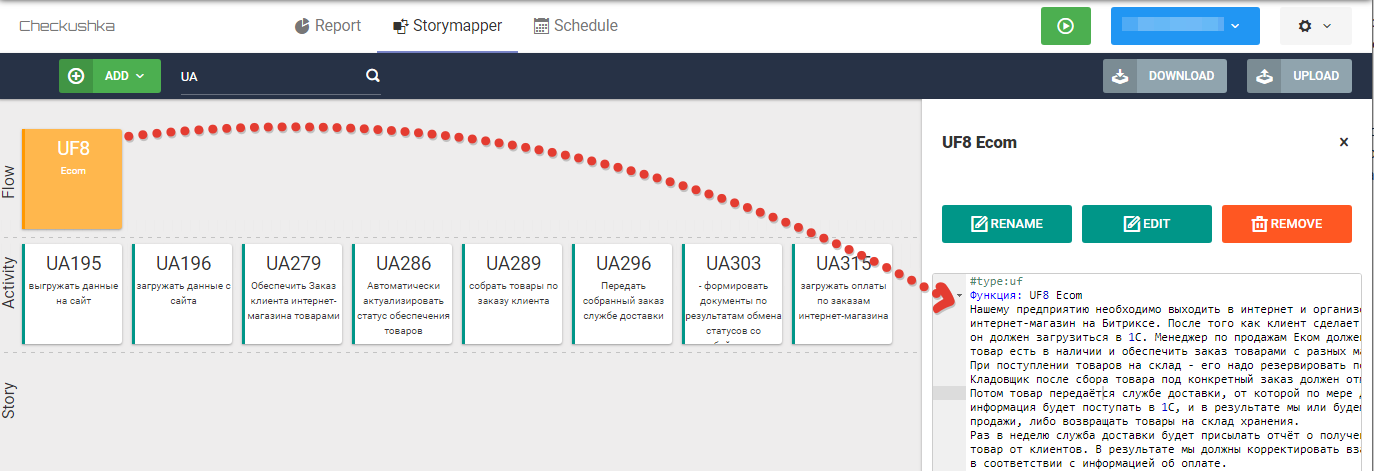 Fig. 8 Texto de requisitos sem sintaxe do Gherkin no nível de UF
Fig. 8 Texto de requisitos sem sintaxe do Gherkin no nível de UFEm seguida, os analistas de negócios percebem como decompor as atividades do usuário em histórias de usuários e formam um terceiro nível de mapa no StoryMapper -
EUA . O isolamento dos
EUA está associado à formulação de critérios de aceitação, ou seja, se "você como alguém deseja algo", verificaremos o fato de que você o recebeu [3]. Os critérios de aceitação para iniciantes também podem ser fixados nos
EUA como texto simples.
Depois que os critérios de aceitação são estabelecidos e acordados com as partes interessadas, os analistas de negócios os colocam na forma de scripts na linguagem Gherkin. De fato, o texto "Cenário: KP-No" é anexado a cada critério de aceitação, que transforma a história do usuário até então abstrata em um arquivo de recurso.
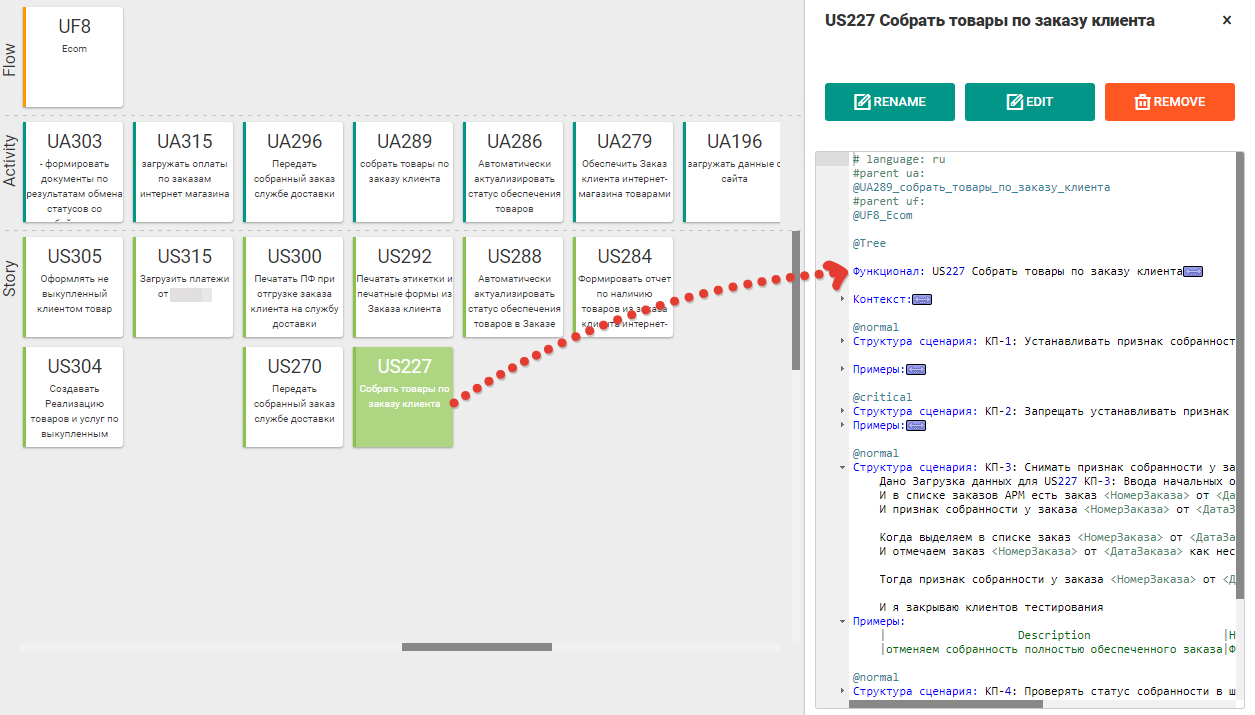 Fig. 8.1 Critérios de aceitação para histórias de usuários como scripts no Gherkin
Fig. 8.1 Critérios de aceitação para histórias de usuários como scripts no GherkinDepois disso, cada cenário é decifrado por várias etapas ampliadas que revelam como exatamente um critério de aceitação específico será verificado. Além disso, essas etapas são programadas pelos desenvolvedores ou digitadas na biblioteca de etapas da estrutura Gherkin usada e exportadas para exportar scripts.
Paralelamente, é organizado um banco de testes no qual o servidor de montagem executará testes funcionais e aguardará o momento em que os
EUA com scripts estiverem prontos. Como o produto e os cenários que implementam os critérios de aceitação estão prontos, o servidor de montagem começa a emitir relatórios no formato Allure e Pepino e enviá-los ao StoryMapper, que por sua vez projeta o resultado da montagem no formato Pepino no mapa do histórico do usuário:
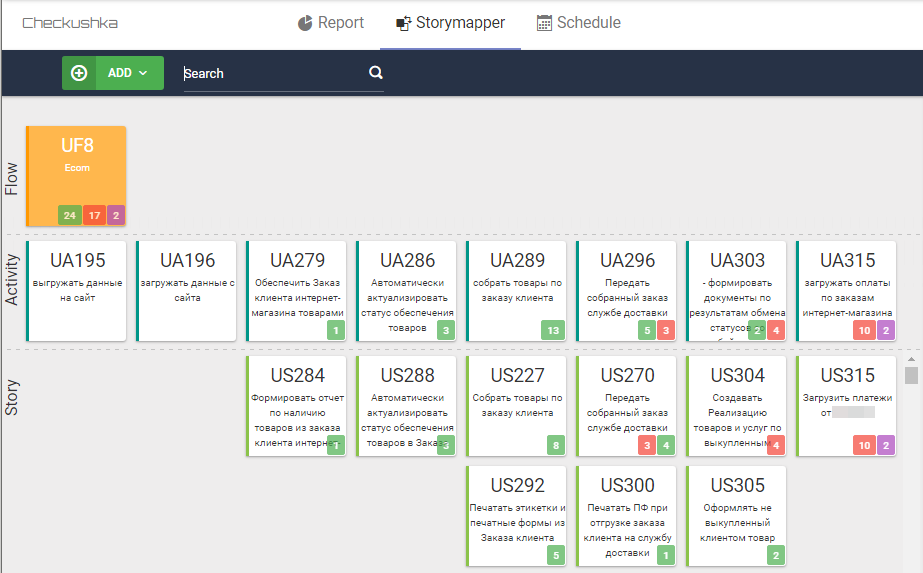 Fig. 9 Mapa de histórias de usuários com resultados de script
Fig. 9 Mapa de histórias de usuários com resultados de scriptAo mesmo tempo, o StoryMapper fornece três níveis de entendimento da prontidão do produto: UF é o nível superior que mostra o número de scripts funcionando corretamente (atendendo aos critérios de aceitação), trabalhando com erros e ainda não está pronto. De fato, o nível superior é um indicador da disponibilidade do produto e um indicador de quanto mais resta a ser feito (este é o nível do proprietário do produto). Os níveis mais baixos permitem descobrir exatamente que tipo de atividades do usuário existem dificuldades e onde é necessário fazer esforços para concluir o produto (este é o nível de mestres de scrum em maior extensão e o proprietário do produto em menor extensão). O nível mais baixo dos
EUA é o nível em que analistas de negócios, desenvolvedores e controle de qualidade interagem, desenvolvendo em conjunto exatamente o produto que as partes interessadas esperam deles.
Além disso, em uma das etapas finais da linha de montagem, a documentação automática é criada. Você pode ler mais sobre isso com os
colegas . Essa não é a única opção, planejamos incluir o pacote
Pickles em nossa ferramenta - o padrão de fato no mundo da “documentação ao vivo”.
Estruturando e visualizando uma coleção de arquivos de recursos
Trabalhando nessa direção, consideramos esse caso. A equipe de desenvolvimento, na esteira do hype em torno do tópico BDD, testes funcionais e padrões de desenvolvimento do setor, comprometeu-se a gravar arquivos de recursos. E rompendo com os espinhos, acumulou uma coleção bastante grande no repositório. No entanto, quando você possui 10 arquivos em sua coleção, o relatório no formato Allure ainda fornece uma imagem confiável do estado do produto. Mas se o número de arquivos de recursos for medido em dezenas e, às vezes, em centenas, mais cedo ou mais tarde você desejará estruturá-los de alguma forma. A primeira coisa que vem à mente é classificá-los em pastas temáticas. E para que? Por partes interessadas, por metadados, por subsistemas? Estas estão longe de ser perguntas ociosas. E se mais tarde se descobrir que os arquivos de recursos foram originalmente escritos como Deus colocaria na alma, e existem scripts relacionados a várias pastas ao mesmo tempo, então como?
Portanto, esse caso de uso implica em um desejo de limpar sua documentação para mudar de "recursos separadamente, documentação separadamente" para "documentação é um código". Quando esse repositório é conectado ao StoryMapper, todos os arquivos de recursos caem na primeira coluna em UF0 e UA0. O próximo passo na estruturação é compor o esqueleto da estrutura. No StoryMapper, eles são todos iguais
UF e
UA , mas ninguém insiste em considerá-los apenas desse ângulo. Eles podem ser considerados simplesmente como 2 níveis de hierarquia, sob os quais é possível colocar arquivos de recursos não estruturados anteriormente. Depois que a estrutura é definida, os arquivos de recursos da primeira coluna são separados sob o
UA correspondente. Sem dúvida, esse processo causa um ataque de reflexão e refatoração de recursos, porque à medida que você arrasta, toda a profundidade do caos que ocorreu durante a escrita inicial fica clara. Às vezes, basta transferir o script de um arquivo para outro, às vezes dividir um arquivo grande em vários para restaurar a conectividade semântica e, às vezes, jogá-lo no lixo, porque manuscritos antigos não executáveis estavam no repositório.
Se a linha de montagem já tiver sido configurada (bem, como existe um repositório de arquivos de recursos, eles devem ser coletados em algum lugar), será necessário adicionar uma etapa para enviar os resultados da montagem ao StoryMapper. O resultado final será a última imagem da seção anterior (Fig. 9): arquivos de recursos estruturados com marcas nos resultados de seus scripts.
Como usar essa imagem? Ele pode ser mostrado à equipe de gerenciamento para relatar os resultados da equipe e demonstrar o grau de prontidão / qualidade do produto. Ele pode ser usado pela equipe na condução de uma retrospectiva para corrigir o
Departamento de Defesa ou de alguma forma corrigir o processo. Ele pode ser usado para a preparação de pedidos em atraso, mas isso já requer trabalho de acordo com o cenário descrito na seção anterior, quando após a estruturação inicial dos requisitos, o desenvolvimento adicional será realizado em um ciclo completo através do StoryMapper (ou pelo menos levando em consideração).
Monitoramento de produtos
Outro caso de uso paralelo que se enraizou em nossa prática.
De fato, é um tópico moderno e elegante - testar diretamente no produto porque não. Afinal, não há erro, não, e sim eles o farão. Isso se torna especialmente relevante se a atividade de TI não for perfil para a empresa e o desenvolvimento for terceirizado, em particular, são lojas on-line de pequeno e médio porte.Como a vemos. Uma opção simples: no conjunto de testes funcionais, um determinado subconjunto de testes de banco de dados não modificáveis é selecionado para verificar o front-end. A segunda opção: os cenários que testam a lógica de negócios são destacados, enquanto a sessão na qual o teste é iniciado é iniciada em um modo especial de teste, onde a modificação de dados não é refletida no banco de dados, não estraga as estatísticas e não participa da troca com os sistemas de contabilidade. Quando esse conjunto de scripts é compilado, ele é vinculado a um agendamento e, com uma determinada frequência, é executado diretamente no produto. O resultado da execução também se reflete no StoryMapper e Allure, mas o mais importante é que, se houver erros nesse conjunto de testes, as pessoas interessadas na empresa receberão uma notificação por e-mail e, assim, poderão navegar on-lineenquanto o próximo lançamento de seus provedores de serviços de TI quebra sua principal ferramenta de negócios.Se as etapas dos scripts incluírem a verificação da duração de sua execução e, em caso de violação do tempo de controle, interromper a execução dos scripts com um erro, esses scripts refletirão requisitos de desempenho não-funcionais. Consequentemente, se alterações no código, aumento de carga e degradação do desempenho da hospedagem afetarem a velocidade do produto, uma pessoa financeiramente interessada na capacidade de trabalho será notificada sobre isso.Portanto, para organizar o monitoramento do produto, você precisa preparar:- repositório com um conjunto de scripts adaptados para o produto;
- uma linha de montagem que fornece scripts no produto, com um gancho configurado para execução;
- StoryMapper com um repositório conectado e um gancho configurado para receber resultados de teste;
- O StoryMapper configurou a programação de inicialização e a notificação de erro.
Instruções de desenvolvimento
Mais uma vez, o StoryMapper está atualmente no estado MVP. No entanto, ele permitiu realizar "experimentos com pessoas", que, na minha opinião, foram concluídos com mais êxito. Bem, na saída, é claro, veio o mesmo "apetite com comida". Aqui está uma lista incompleta do que eu gostaria de adicionar à ferramenta:- exibir na ferramenta a própria "documentação viva" que deve ser o resultado final do conceito de "documentação é código";
- discussão de cenários entre os participantes do projeto (comentários, colaboração etc.);
- exportar / importar cartões de histórias personalizados para / do Excel;
- algum tipo de integração com o Jira (mas há mais perguntas do que respostas).
Prevejo tal risco que a ferramenta de uso interno possa começar a dominar a metodologia e o conceito, e começaremos a nos envolver em autodisciplina e reflexão, em vez de gerar idéias interessantes e melhorar o processo de desenvolvimento. Portanto, em um futuro próximo, planejamos dar acesso ao instrumento em uma edição limitada para ser inspirado pelo feedback e revisar as próprias direções do desenvolvimento.Como posso tentar
Eu não espero diretamente um interesse explosivo nos tópicos mencionados aqui (embora eu esteja familiarizado com o termo "habraeffect"), por isso, se alguém de repente se interessar e quiser tocar o instrumento com as mãos, fale sobre a evolução e a verificação de requisitos (o que é mais interessante!) - bata no nosso telegrama Você pode concordar com tudo.Referências e referências
- Jeff Patton, histórias personalizadas. A arte do desenvolvimento ágil de software, São Petersburgo, Peter, 2017.
- Mike Cohn, histórias personalizadas. Desenvolvimento flexível de software, M.-SPb.-K, Williams, 2012.
- Gojko Adjic, Especificação por Exemplo, NY, Publicação Manning, 2011.
- Karl Wigers, Joy Beatty, Desenvolvimento de requisitos de software, M.: edição russa; SPb.: BHV-Petersburg, 2014.
- Artigo introdutório de Dan North no BDD “O que há em uma história”
- Informações sobre o conceito "Documentação é código" na comunidade "Escreva os documentos"
- A implementação do conceito de "Documentação - O presente código" no projeto " docToolchain "