Meu colega Rafael Grigoryan eegdude escreveu recentemente um artigo sobre por que a humanidade precisava do EEG e que fenômenos significativos podem ser registrados nele. Hoje, na continuação do tópico das interfaces neurais, usamos um dos conjuntos de dados abertos gravados em um jogo usando a mecânica P300 para visualizar o sinal de EEG, ver a estrutura dos potenciais chamados, construir os principais classificadores, avaliar a qualidade com a qual podemos prever a presença desse potencial chamado.
Deixe-me lembrá-lo de que o P300 é um potencial chamado (VP), uma resposta específica do cérebro associada à tomada de decisão e estímulos distintos (que veremos abaixo). Geralmente é usado para construir BCI moderno.
Para fazer a classificação EEG, você pode ligar para amigos, escrever um jogo sobre Guaxinins e Demônios em VR, escrever suas próprias reações e escrever um artigo científico (vou falar sobre isso outra vez), mas, felizmente, cientistas de todo o mundo conduzimos algumas experiências para nós e resta apenas fazer o download dos dados.
Uma análise de como criar uma interface neural no P300 com código e visualizações passo a passo, além de um link para o repositório, pode ser encontrada abaixo do gato.
O artigo mostra apenas os pontos principais do código, a versão reproduzível completa no caderno jupyter para pesquisar aqui
Do ponto de vista de um EEG, o P300 é apenas uma explosão em um determinado momento em determinados canais. Existem várias maneiras de chamá-lo, por exemplo, se você se concentrar em um objeto, e ele é ativado em um momento aleatório (muda de forma, cor, brilho ou salta para algum lugar). Eis como foi implementado nos tempos antigos.
Em termos gerais, o esquema é o seguinte: existem vários (geralmente de 3 a 7) estímulos no campo de visão de uma pessoa. Uma pessoa escolhe uma delas e se concentra nela (uma boa maneira é contar o número de ativações), então cada objeto pisca em uma ordem aleatória. Conhecendo o tempo de ativação de cada estímulo, agora podemos observar o próximo EEG e determinar se havia um pico característico (veremos nas visualizações abaixo). Como a pessoa se concentrou em apenas um estímulo, o pico deve ser um. Assim, nessas interfaces neurais, uma das várias opções é selecionada (cartas para escrever, ações no jogo e Deus sabe o que mais). Se houver mais de sete opções, você poderá colocá-las na grade e reduzir a tarefa para selecionar uma linha + coluna. É assim que o verificador clássico P300 de matriz, mostrado acima.
No caso do conjunto de dados considerado hoje, a parte visual (assim como o nome) foi emprestada dos famosos invasores do espaço de jogo. Parecia algo assim

De fato, este é o mesmo jogo, apenas as letras são substituídas por alienígenas do jogo.
O vídeo do processo do jogo e os relatórios técnicos também foram preservados.
De uma forma ou de outra, os dados coletados usando este jogo apareceram na Internet e podemos acessá-los. Os dados consistem em 16 canais de EEG e um canal de evento, mostrando em quais momentos os incentivos alvo (feitos pelo jogador) e não alvo foram ativados, e trabalharemos com eles.
A maioria dos conjuntos de dados da BCI foram escritos por neurofisiologistas, e esses são os que realmente não se preocupam com a compatibilidade. Portanto, os formatos de dados são muito diversos: desde versões diferentes de arquivos .edf formatos "padrão" .edf e .gdf .
A coisa mais importante que você precisa saber sobre esses formatos é que não deseja analisá-los ou trabalhar diretamente com eles.
Felizmente, um grupo de entusiastas do NeuroTechX escreveu downloads para alguns conjuntos de dados diretamente em numpy.
Esses gerenciadores de inicialização fazem parte do projeto moabb que afirma ser uma solução universalizada para o BCI.
Baixar conjunto de dados brutos
import moabb.datasets sampling_rate = 512 m_dataset = moabb.datasets.bi2013a( NonAdaptive=True, Adaptive=True, Training=True, Online=True, ) m_dataset.download() m_data = m_dataset.get_data()
Nesta fase, obtivemos uma estrutura RawEDF contendo registros EEG. Essa é uma estrutura do pacote mne , os biólogos costumam usá-la para interagir com sinais: essa estrutura possui métodos mne para filtrar, visualizar, armazenar etiquetas e você nunca sabe. Mas não vamos por aqui desde a interface do pacote tende a ser instável (a versão atual é 0.19 , mas usaremos 0.17 pois o conjunto de dados não é mais lido pela nova versão) e mal documentado; por isso, nossos resultados podem se tornar improdutivos.
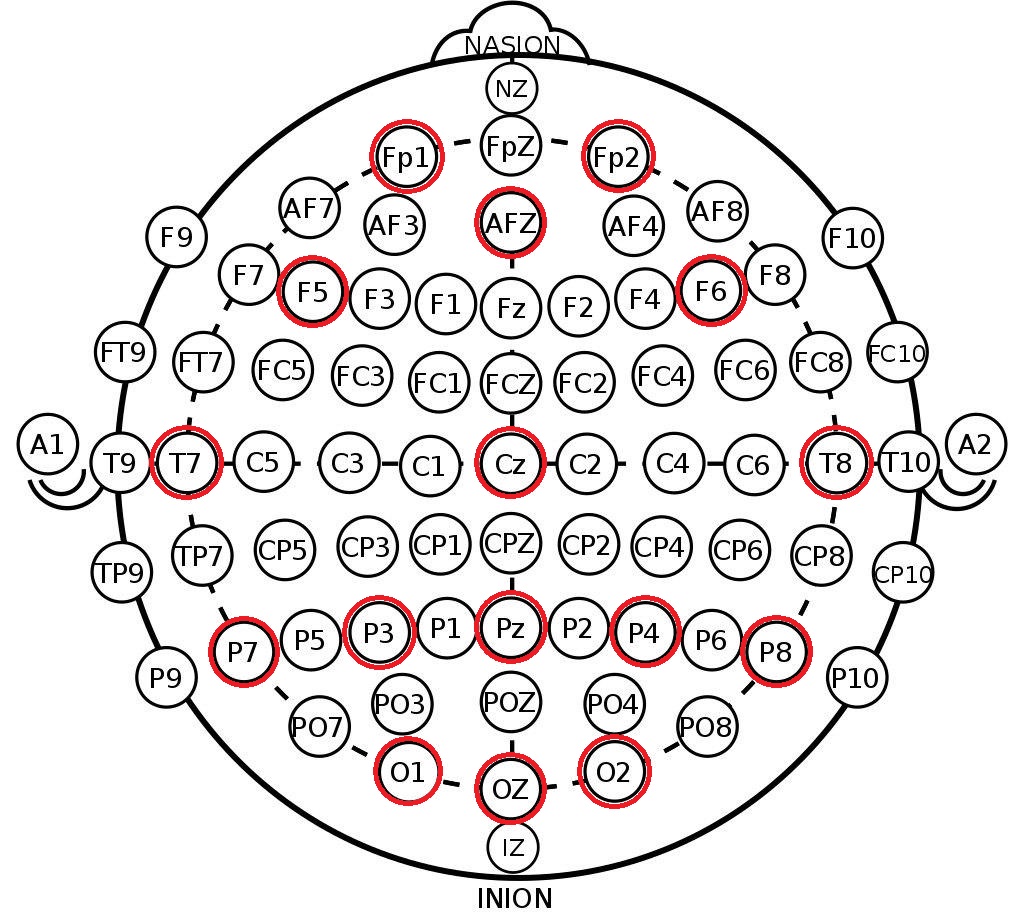
O que extraímos da estrutura resultante são os rótulos dos canais no sistema 10-20 . Este é um arranjo internacional de eletrodos na cabeça de uma pessoa, criado para que os cientistas possam correlacionar as zonas cerebrais e a localização dos canais de EEG. Abaixo está a disposição dos eletrodos no sistema 10-10 (difere de 10-20 por duas vezes a densidade de marcação) e os canais que foram registrados neste conjunto de dados são marcados em vermelho.
print(m_data[1]['session_1']['run_1'])
Primeiro, a partir dos dados baixados para cada sujeito, alocamos matrizes de EEG contínuo por 16 segundos e todos os rótulos para esse intervalo (nos dados, esse é apenas mais um canal no qual são anotados os primórdios dos eventos de interesse).
Nesse estágio, mantemos o comprimento máximo do EEG contínuo para não encontrar efeitos de borda durante a filtragem adicional.
raw_dataset = [] for _, sessions in sorted(m_data.items()): eegs, markers = [], [] for item, run in sorted(sessions['session_1'].items()): data = run.get_data() eegs.append(data[:-1]) markers.append(data[-1]) raw_dataset.append((eegs, markers))
Filtragem e Separação
Em geral, para revisar os métodos de pré-processamento e classificação do EEG, posso recomendar uma excelente visão geral dos mestres das interfaces de neurocomputadores. Também não faz muito tempo, foi lançada uma revisão mais recente dos testes de redes neurais.
O pré-processamento mínimo do sinal EEG para classificação inclui 3 etapas:
Para implementar essas etapas, usaremos o bom e velho sklearn e seu paradigma para transformadores e tubulações, para que nosso pré-processamento possa ser facilmente extensível.
O código dos transformadores é colocado em um arquivo separado, abaixo descreveremos alguns detalhes.
Dizimação
Por alguma razão, em alguns artigos e exemplos de processamento, eu encontrei uma diminuição na frequência do sinal simplesmente jogando amostras no estilo eeg = eeg[:, ::10] . Isso está completamente incorreto (por que - veja qualquer livro sobre processamento de sinais). Usamos a scipy padrão scipy .
Filtragem
Aqui, também contamos com filtros scipy , selecionando um filtro passa-banda Butterworth de 4 ordens e aplicando-o na direção direta e reversa ( filtfilt ) para manter a fase. Frequências de corte - de 0,5 a 20 Hz, esta é a faixa padrão para nossa tarefa.
Dimensionamento
Usamos um StandardScaler por canal (subtrai a média, divide pelo desvio padrão), que vê todos os sinais da amostra. De fato, um pequeno vazamento de dados é introduzido neste momento. formalmente, o scaler também vê dados da amostra de teste, mas com volumes de dados suficientemente grandes, a média e o desvio são os mesmos.
A masturbação é realizada canal por canal, para que, dentro do mesmo conjunto de dados, seja possível agregar dados de diferentes sensores com diferentes ordens de magnitude e natureza (por exemplo, reação pele-galvânica (RAG) )
Além das operações acima, também foi possível distinguir artefatos no EEG (piscando, mastigando, movendo a cabeça), mas esse conjunto de dados já está muito limpo, então vamos deixá-lo até a próxima vez.
reload(transformers) decimation_factor = 10 final_rate = sampling_rate // decimation_factor epoch_duration = 0.9
Em seguida, aplicaremos o pipeline de pré-processamento aos nossos dados e cortaremos o sinal EEG contínuo em épocas. Vamos chamar a época de período imediatamente após a ativação do estímulo, com uma duração característica de 0,5-1 segundo, no nosso caso, a duração é de 900 ms, embora possa ser encurtada.
Em nosso conjunto de dados, existem 16 canais de EEG; após a aplicação da dizimação, a frequência cai para 50 Hz; portanto, uma época será descrita por uma matriz (16, 45) - 900 ms a 50 Hz são 45 amostras de tempo.
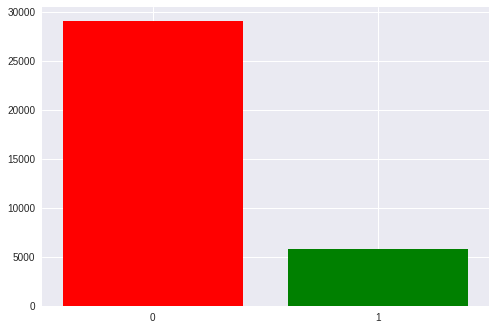
As tags neste conjunto de dados são apenas binários - elas marcam os sinais de destino (ocultos pelo jogador, ativos, 1) e não-alvo (vazios, 0).
for eegs, _ in raw_dataset: eeg_pipe.fit(eegs) dataset = [] for eegs, markers in raw_dataset: epochs = [] labels = [] filtered = eeg_pipe.transform(eegs) markups = markers_pipe.transform(markers) for signal, markup in zip(filtered, markups): epochs.extend([signal[:, start:(start + epoch_count)] for start in markup[:, 0]]) labels.extend(markup[:, 1]) dataset.append((np.array(epochs), np.array(labels)))
dataset[0][0].shape, dataset[0][1].shape
Então, temos um conjunto de Pytorch no estilo Pytorch, no qual o primeiro índice conta pessoas diferentes. Com essa estrutura, podemos realizar a validação cruzada nos dados de uma pessoa e testar a tolerância do classificador entre pessoas diferentes (o chamado aprendizado de transferência, previsão sem calibração). Os dados de uma pessoa consistem em uma variedade de eras e rótulos de classe. O número de eras para cada pessoa varia um pouco devido às características da gravação.
Pesquisa e visualização de dados
Primeiro, dê uma olhada em um dos sinais contínuos antes de cortar em épocas.
Apesar de já ter sido filtrado, ele não mostra nenhuma ativação no olho e parece mais algum tipo de ruído.
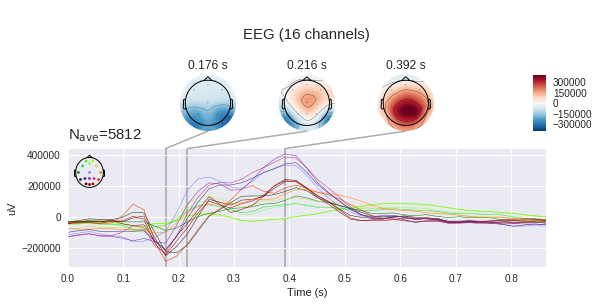
Se considerarmos apenas uma época alvo do nosso conjunto de dados, veremos um aumento característico no intervalo de 400 a 600 ms. Este é o nosso P300 potencial procurado.
No total, em nosso conjunto de dados, existem cerca de 35 mil épocas, ou seja, ativação de estímulos. Cada pessoa tem cerca de 1300 a 1750 (isso se deve ao fato de alguém abater alienígenas mais rápido e mais lento).
Há também um desequilíbrio notável nas classes: 1 a 5 a favor de estímulos vazios. temos 6 linhas e colunas na matriz e apenas uma delas é o destino. Mais tarde, voltaremos a isso ao discutir as métricas obtidas.
Agora é hora de observar a diferença entre o sinal alvo e o não alvo
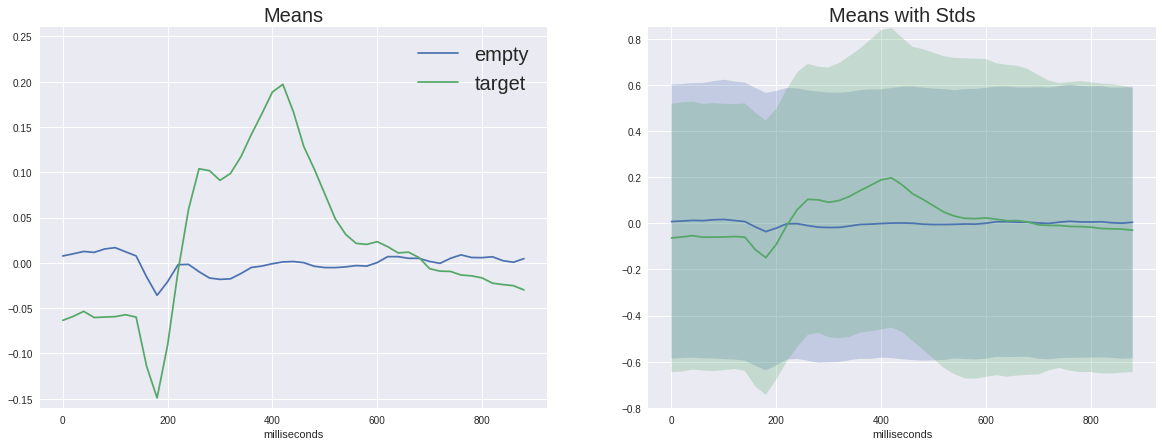
No gráfico esquerdo, você pode ver que os sinais médios variam muito, e ambos têm uma resposta inespecífica na região de 180ms, mas o alvo é muito mais amplitude, o alvo também possui um hump característico de 250 a 500 ms - este é o notório P300.
Com essa diferença no sinal, nossa tarefa pode parecer um pouco, mas se adicionarmos o desvio padrão em cada ponto ao gráfico, veremos que a imagem não é tão otimista - o sinal é bastante barulhento. E isso apesar do fato de a relação sinal / ruído do P300 ser considerada uma das mais altas da neurofisiologia.
(Na verdade, esses gráficos não são construídos com honestidade, porque o sinal vazio é calculado em média cinco vezes mais do que amostras diferentes, portanto os desvios aleatórios são mais sufocados, mas como podemos ver pela dispersão da mesma ordem, isso não ajuda muito)

Também é útil observar os sinais médios de uma pessoa.
Aqui é encontrada a observação anterior sobre a média “desonesta” - o sinal vazio é visivelmente mais amplitude do que a média geral. Além disso, o pico do P300 em uma pessoa é mais alto devido à menor média.
É importante observar outra característica do sinal de uma pessoa - ela tem uma forma ligeiramente diferente da generalizada. A variabilidade interpessoal das reações neurofisiológicas é bastante alta, ainda veremos a influência desse fator no trabalho dos classificadores. No entanto, as diferenças intrapessoais (uma pessoa com humor diferente, nível de estresse, fadiga) também são bastante grandes.

A seguir, vemos a varredura canal a canal dos sinais. O ponto de vista aqui coincide com a figura acima, que mostra a posição dos eletrodos - nariz acima, etc.
A resposta de cada parte da cabeça é diferente. Em Fp1,2, dois picos negativos anteriores ao pico positivo são pronunciados. Além disso, em alguns canais há dois picos positivos e em alguns - um ou algo de transição entre eles.
Canais diferentes são de importância diferente para determinar a presença do P300, ele pode ser estimado usando métodos diferentes - cálculo de informações mútuas (informações mútuas) ou método de adição e exclusão (também conhecido como regressão por etapas). A aplicação desses métodos, vamos lidar com outro momento.
Vale lembrar que medimos a diferença de potencial entre os eletrodos com eletrodos, o que significa que podemos construir mapas de tensão para toda a cabeça em determinados momentos, usando mudanças de tensão em pontos individuais. É claro que, se houver 16 eletrodos, a precisão de tal cartão deixa muito a desejar, mas é necessário algum entendimento. (por padrão, mne espera ver microvolts, mas já aplicamos a escala, portanto os valores absolutos não estão corretos)

Classificação
Finalmente, é hora de aplicar métodos de aprendizado de máquina à nossa amostra.
Vários básicos foram escolhidos como classificadores - um log. regressão, o método do vetor de suporte (SVM) e vários métodos usando a análise de correlação do pacote pyriemann (detalhes de cada método podem ser encontrados na documentação), é importante notar que esses métodos foram desenvolvidos especialmente para a aplicação ao EEG e, com a ajuda deles, várias competições foram vencidas. kaggle.
clfs = { 'LR': ( make_pipeline(Vectorizer(), LogisticRegression()), {'logisticregression__C': np.exp(np.linspace(-4, 4, 9))}, ), 'LDA': ( make_pipeline(Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'SVM': ( make_pipeline(Vectorizer(), SVC()), {'svc__C': np.exp(np.linspace(-4, 4, 9))}, ), 'CSP LDA': ( make_pipeline(CSP(), LDA(shrinkage='auto', solver='eigen')), {'csp__n_components': (6, 9, 13), 'csp__cov_est': ('concat', 'epoch')}, ), 'Xdawn LDA': ( make_pipeline(Xdawn(2, classes=[1]), Vectorizer(), LDA(shrinkage='auto', solver='eigen')), {}, ), 'ERPCov TS LR': ( make_pipeline(ERPCovariances(estimator='oas'), TangentSpace(), LogisticRegression()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), 'ERPCov MDM': ( make_pipeline(ERPCovariances(), MDM()), {'erpcovariances__estimator': ('lwf', 'oas')}, ), }

O esquema mais comum de interfaces neurais é "calibração + trabalho", ou seja, Primeiro, é necessário que uma pessoa se concentre nos estímulos indicados anteriormente por algum tempo, e somente depois disso predizemos sua escolha. Essa abordagem tem a óbvia desvantagem de um estágio inicial chato.
Para avaliar o desempenho de nossos métodos nesse modo, realizaremos a validação cruzada nas épocas de uma pessoa.
A métrica de precisão, neste caso, não é relevante devido ao desequilíbrio do conjunto de dados (a linha de base é de 5/6 a 83% aqui), então prefiro examinar os três três.
Para revisar todo o conjunto de dados, calculamos a média dos resultados dessa validação cruzada em todas as pessoas. Em geral, o desempenho dos melhores modelos é bastante alto comparado ao que temos em Neiry nas condições "de campo" de um parque de diversões (lembro-me de que esse conjunto de dados foi registrado em laboratório).
Nesse conjunto de dados, existem apenas rótulos binários para os dados. Em geral, precisamos resolver o problema multiclasse de escolher um dos estímulos (a propósito, ele é equilibrado, pois cada estímulo é ativado no mesmo número de vezes). Para resolvê-lo, o número de ativações de cada estímulo geralmente é fixo (por exemplo, 6 estímulos de 5 ativações cada) e todos os estímulos são ativados aleatoriamente (30 vezes), são obtidas 30 épocas e adicionadas as probabilidades de suas ativações, após as quais o estímulo que atingiu o máximo o valor é reconhecido como alvo. Demonstraremos a implementação dessa abordagem em uma publicação futura em um conjunto de dados adequado.

O segundo esquema é chamado aprendizado de transferência - ou seja, a transferência do classificador entre as pessoas. O fato é que, quando fazemos a calibração, na verdade, retreinamos a forma de pico de uma pessoa, para podermos prever bem em testes subsequentes. Na ausência de calibração, um classificador pré-treinado deve poder isolar o conceito P300 sem conhecer antecipadamente a forma de onda de uma pessoa em particular.
Conduziremos dois experimentos - treinaremos o classificador em uma pessoa e preveremos cinco; em seguida, aumentaremos a amostra de treinamento para 10 pessoas e compararemos os resultados para garantir que os modelos possam aumentar sua capacidade de generalização.
Treinamento para 1 pessoa

Treinamento para 10 pessoas
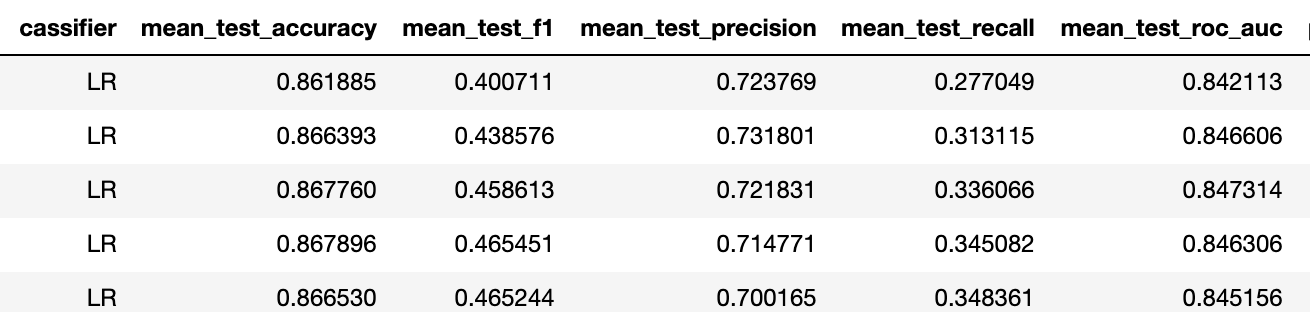
Portanto, f1 passou de 0,23 para 0,4 para um classificador melhor (nos dois casos, é uma regressão logarítmica com a mesma regularização).
Isso significa que a capacidade preditiva aumentou de "não" para "aceitável". Com base em nossa experiência, com essas métricas de tarefas binárias, 5 ativações de cada estímulo são suficientes para atingir a precisão de um problema de várias classes de cerca de 75%.
No final, quero observar que o método acima é bastante primitivo, o que pode ser visto, por exemplo, pelo alto grau de regularização da regressão logarítmica - os canais nos dados estão fortemente correlacionados e existem várias abordagens para resolver essa circunstância.
Conclusão
Hoje, nos familiarizamos com o potencial evocado do P300 e construímos um pipeline simples para a interface neural. Eu recomendo aos interessados abrir um laptop por conta própria (localizado no repositório ) e experimentar opções de visualização e classificadores.
Tendo uma compreensão básica dos métodos de trabalho com o sinal EEG, poderemos examinar esse tópico mais profundamente - aplicar métodos avançados de pré-processamento, bem como redes neurais, para resolver os problemas de construção de interfaces neurais. Para continuar ...