Nos últimos anos, tenho projetado e fabricado uma máquina que pode reconhecer e classificar peças LEGO. A parte mais importante da máquina é a
unidade de captura , um pequeno compartimento quase completamente fechado no qual há uma correia transportadora, iluminação e uma câmera.
Iluminando você verá um pouco mais baixo.A câmera tira fotos das peças LEGO que chegam pelo transportador e depois transfere as imagens sem fio para um servidor que executa um algoritmo de inteligência artificial para reconhecer a peça entre milhares de possíveis elementos LEGO. Falarei mais sobre o algoritmo de IA em artigos futuros, e este artigo se concentrará no processamento que é realizado entre a saída bruta da câmera de vídeo e a entrada na rede neural.
O principal problema que eu precisava resolver era converter o fluxo de vídeo do transportador em imagens separadas de partes que uma rede neural poderia usar.
O objetivo final: mudar de um vídeo bruto (à esquerda) para um conjunto de imagens do mesmo tamanho (à direita) para transferi-las para uma rede neural. (em comparação com o trabalho real, o gif é aproximadamente metade da velocidade)Este é um ótimo exemplo de tarefa que, aparentemente, parece simples, mas na verdade apresenta muitos obstáculos únicos e interessantes, muitos dos quais exclusivos das plataformas de visão de máquina.
A recuperação das partes corretas de uma imagem dessa maneira geralmente é chamada de detecção de objeto. É exatamente isso que preciso fazer: reconhecer a presença de objetos, sua localização e tamanho, para que você possa gerar
retângulos delimitadores para cada parte de cada quadro.
O mais importante é encontrar boas caixas delimitadoras (mostradas acima em verde)Vou considerar três aspectos da solução do problema:
- Preparando-se para eliminar variáveis desnecessárias
- Criando um processo a partir de operações simples de visão de máquina
- Manutenção de desempenho suficiente em uma plataforma Raspberry Pi com recursos limitados
Eliminação de variáveis desnecessárias
No caso de tais tarefas, é melhor eliminar o maior número possível de variáveis antes de usar técnicas de visão de máquina. Por exemplo, não devo me preocupar com condições ambientais, posições diferentes da câmera, perda de informações devido à sobreposição de algumas partes por outras. Obviamente, é possível (embora muito difícil) resolver todas essas variáveis programaticamente, mas felizmente para mim, essa máquina é criada do zero. Eu mesmo posso me preparar para uma solução bem-sucedida, eliminando toda a interferência antes mesmo de começar a escrever o código.
O primeiro passo é fixar firmemente a posição, ângulo e foco da câmera. Com isso, tudo é simples - no sistema, a câmera é montada acima do transportador. Não preciso me preocupar com interferências de outras partes; objetos indesejados quase não têm chance de entrar na unidade de captura. Um pouco mais complicado, mas é muito importante garantir
condições de iluminação constantes . Não preciso que o reconhecedor de objetos interprete erroneamente a sombra de uma parte móvel ao longo da fita como um objeto físico. Felizmente, a unidade de captura é muito pequena (todo o campo de visão da câmera é menor que um pedaço de pão), então eu tinha controle mais do que suficiente sobre as condições do ambiente.
Unidade de captura, vista interna. A câmera está no terço superior do quadro.Uma solução é tornar o compartimento totalmente fechado para que não aconteça nenhuma luz externa. Eu tentei essa abordagem usando tiras de LED como fonte de iluminação. Infelizmente, o sistema acabou sendo muito sombrio - basta apenas um pequeno orifício na caixa e a luz penetra no compartimento, impossibilitando o reconhecimento de objetos.
No final, a melhor solução foi "entupir" todas as outras fontes de luz enchendo o compartimento pequeno com luz forte. Verificou-se que as fontes de luz que podem ser usadas para iluminar instalações residenciais são muito baratas e fáceis de usar.
Pegue as sombras!Quando a fonte é direcionada para o pequeno compartimento, ela obstrui completamente todas as possíveis interferências externas da luz. Esse sistema também tem um efeito colateral conveniente: devido à grande quantidade de luz na câmera, você pode usar uma velocidade do obturador muito alta, obtendo imagens perfeitamente nítidas das peças, mesmo quando se move rapidamente ao longo do transportador.
Reconhecimento de Objetos
Como consegui transformar esse lindo vídeo com iluminação uniforme nas caixas delimitadoras de que eu precisava? Se você trabalha com IA, pode sugerir que eu implemente uma rede neural para reconhecimento de objetos como
YOLO ou
Faster R-CNN . Essas redes neurais podem lidar facilmente com a tarefa. Infelizmente, estou executando o código de reconhecimento de objeto no
Raspberry pi . Mesmo um computador poderoso teria problemas para executar essas redes neurais convolucionais na frequência que eu precisava em cerca de 90FPS. E o Raspberry pi, que não possui uma GPU compatível com IA, não conseguiu lidar com uma versão muito simplificada de um desses algoritmos de IA. Posso transmitir vídeo do Pi para outro computador, mas a transmissão de vídeo em tempo real é um processo muito sombrio, e os atrasos e as limitações de largura de banda causam problemas sérios, especialmente quando você precisa de uma alta velocidade de transferência de dados.
YOLO é muito legal! Mas eu não preciso de todas as suas funções.Felizmente, pude evitar uma solução difícil baseada em IA usando as técnicas de visão de máquina da “velha escola”. A primeira técnica é a
subtração em segundo plano , que tenta isolar todas as partes alteradas da imagem. No meu caso, a única coisa que se move no campo de visão da câmera são os detalhes da LEGO. (Obviamente, a fita também se move, mas, como possui uma cor uniforme, parece estacionária para a câmera). Separe esses detalhes da LEGO do plano de fundo e metade do problema está resolvido.
Para que a subtração em segundo plano funcione, os objetos em primeiro plano devem ser significativamente diferentes do segundo plano. Os detalhes da LEGO têm uma ampla variedade de cores, então eu tive que escolher a cor de fundo com muito cuidado para que ela estivesse o mais longe possível das cores da LEGO. É por isso que a fita embaixo da câmera é feita de papel - ela não só precisa ser muito uniforme, mas também não pode consistir em LEGO; caso contrário, será da cor de uma das partes que eu preciso reconhecer! Eu escolhi o rosa pálido, mas qualquer outra cor pastel, ao contrário das cores comuns da LEGO, servirá.
A maravilhosa biblioteca OpenCV já possui vários algoritmos para subtração em segundo plano. O Subtrator em segundo plano do MOG2 é o mais complexo deles e, ao mesmo tempo, funciona incrivelmente rápido, mesmo no raspberry pi. No entanto, alimentar quadros de vídeo diretamente no MOG2 não funciona muito bem. Figuras cinza e branco claras estão muito próximas do brilho de um fundo pálido e se perdem nele. Eu precisava encontrar uma maneira de separar mais claramente a fita das partes, ordenando que o subtractor de fundo olhasse mais de perto a
cor , e não o
brilho . Para fazer isso, bastava aumentar a saturação das imagens antes de transferi-las para um subtractor de fundo. Os resultados melhoraram significativamente.
Depois de subtrair o plano de fundo, eu precisava usar operações morfológicas para me livrar do máximo de ruído possível. Para encontrar os contornos das áreas em branco, você pode usar a função findContours () da biblioteca OpenCV. Ao aplicar várias heurísticas para desviar os loops que contêm ruído, você pode facilmente converter esses loops em caixas delimitadoras predefinidas.
Desempenho
Uma rede neural é uma criatura voraz. Para obter melhores resultados na classificação, ela precisa de imagens de resolução máxima e em quantidades tão grandes quanto possível. Isso significa que eu preciso gravá-las em uma taxa de quadros muito alta, mantendo a qualidade e a resolução da imagem. Eu tenho que espremer o máximo possível da câmera e GPU Raspberry PI.
Uma
documentação muito detalhada
para a picamera diz que o chip da câmera V2 pode produzir imagens de 1280x720 pixels em tamanho com uma frequência máxima de 90 quadros por segundo. É uma quantidade incrível de dados e, embora a câmera possa gerá-los, isso não significa que um computador possa lidar com isso. Se eu fosse processar imagens RGB brutas de 24 bits, teria que transferir dados a uma velocidade de aproximadamente 237 MB / s, o que é demais para a GPU ruim do computador Pi e a SDRAM. Mesmo ao usar a compactação acelerada por GPU em JPEG, 90fps não podem ser alcançados.
O Raspberry Pi é capaz de exibir imagens YUV brutas e não filtradas. Embora seja mais difícil trabalhar do que com RGB, o YUV realmente tem muitas propriedades convenientes. O mais importante deles é que ele armazena apenas 12 bits por pixel (para RGB é de 24 bits).
A cada quatro bytes de Y, há um byte U e um byte V, ou seja, 1,5 bytes por pixel.Isso significa que, comparado aos quadros RGB, posso processar o
dobro de quadros YUV, e isso não está contando o tempo adicional que a GPU economiza na conversão para imagem RGB.
No entanto, essa abordagem impõe restrições exclusivas ao processo de processamento. A maioria das operações com um quadro de vídeo de tamanho completo consumirá uma quantidade extremamente grande de memória e recursos da CPU. Dentro dos meus rígidos prazos, nem é possível decodificar um quadro YUV em tela cheia.
Felizmente, não preciso processar todo o quadro! Para o reconhecimento de objetos, os retângulos delimitadores não precisam ser precisos; a precisão aproximada é suficiente; portanto, todo o processo de reconhecimento de objetos pode ser realizado com um quadro muito menor. A operação de redução de zoom não é necessária para levar em consideração todos os pixels de um quadro de tamanho normal, para que os quadros possam ser reduzidos muito rapidamente e sem nenhum custo. Em seguida, a escala dos retângulos delimitadores resultantes aumenta novamente e é usada para cortar objetos de um quadro YUV de tamanho completo. Graças a isso, não preciso decodificar ou processar todo o quadro de alta resolução.
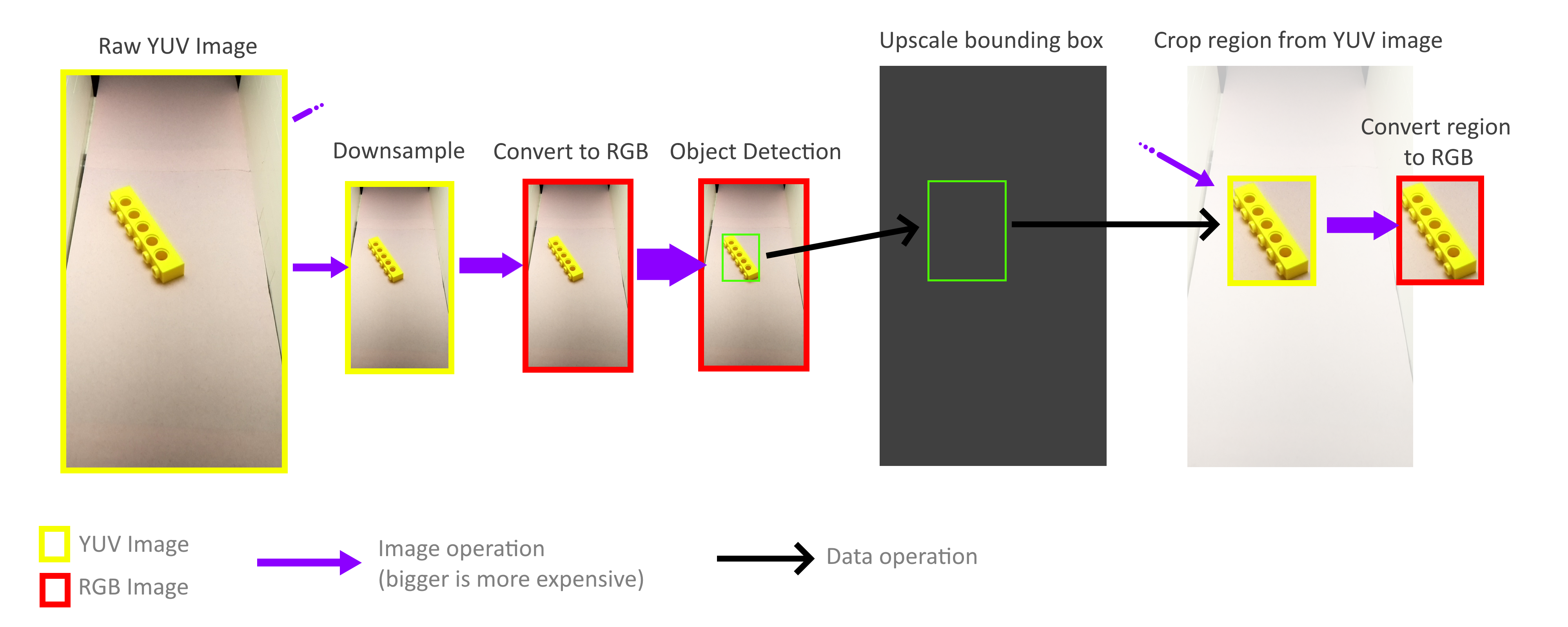
Felizmente, graças ao método de armazenamento deste formato YUV (veja acima), é muito fácil implementar operações de corte e zoom rápidas que funcionam diretamente com o formato YUV. Além disso, todo o processo pode ser paralelo a quatro núcleos Pi sem problemas. No entanto, descobri que nem todos os núcleos estão acostumados a todo o seu potencial, e isso nos diz que a largura de banda da memória ainda é o gargalo. Mas, mesmo assim, consegui atingir 70-80FPS na prática. Uma análise mais profunda do uso da memória pode ajudar a acelerar ainda mais as coisas.
Se você quiser saber mais sobre o projeto, leia meu artigo anterior,
“Como criei mais de 100 mil imagens LEGO rotuladas para aprendizado” .
Vídeo da operação de toda a máquina de triagem: