Continuarei uma análise sem pressa da implementação de tipos básicos no CPython,
dicionários e
números inteiros foram considerados anteriormente. Aqueles que pensam que não pode haver nada interessante e astuto em sua implementação são incentivados a participar desses artigos. Quem já os leu sabe que o CPython possui muitos recursos interessantes e de implementação. Eles podem ser úteis para saber ao escrever seus próprios scripts ou como um guia para soluções arquitetônicas e algorítmicas. As strings não são exceção aqui.
Vamos começar com uma breve digressão na história. O Python apareceu em 1990-91. Inicialmente, ao desenvolver a codificação base em python, havia um ascii antigo de um byte. Mas, mais ou menos na mesma época (um pouco mais tarde), a humanidade estava cansada de lidar com o "zoológico" de codificações e, em 1991, o padrão Unicode foi proposto. No entanto, pela primeira vez, também não funcionou. A introdução das codificações de dois bytes começou, mas logo ficou claro que dois bytes não seriam suficientes para todos, uma codificação de 4 bytes foi proposta. Infelizmente, alocar 4 bytes para cada caractere parecia um desperdício de espaço em disco e memória, especialmente nos países onde um ascii de um byte era suficiente antes. Várias muletas foram serradas em uma codificação de 2 bytes para suportar mais caracteres, e tudo isso começou a se assemelhar à situação anterior com o "zoológico" de codificações.
Mas em 1993 o utf-8 foi introduzido. O que foi um compromisso: ascii era um subconjunto válido de utf-8, todos os outros caracteres o expandiram, no entanto, para suportar essa possibilidade, tive que me separar de um comprimento fixo de cada caractere. Mas foi ele quem estava destinado a
ordenar que todos se tornassem exatamente Unicode, ou seja, uma única codificação suportada pela maioria dos programas em que a maioria dos arquivos é armazenada. Isso foi especialmente influenciado pelo desenvolvimento da Internet, uma vez que as páginas da Web usualmente usavam apenas utf-8.
O suporte para essa codificação foi gradualmente introduzido em linguagens de programação que, como python, foram desenvolvidas antes do utf-8 e, portanto, usavam outras codificações. Há um
PEP com um bom número 100 que discutiu o suporte a Unicode. E no
PEP-0263 tornou
- se possível declarar a codificação dos arquivos de origem. A ascodificação ainda era a codificação base, o prefixo `u` era usado para declarar cadeias unicode, trabalhar com elas ainda não era conveniente e natural o suficiente. Mas houve uma oportunidade de criar a seguinte heresia:
class 비빔밥: _ = 2 א = 비빔밥() print(א)
Em 3 de dezembro de 2008, ocorreu um evento histórico para toda a comunidade python (e considerando a extensão que essa linguagem se espalhou agora, então, talvez, para todo o mundo) - o python 3. foi lançado. Foi decidido encerrar os problemas de uma vez por todas por causa de muitas codificações e, portanto, Unicode se tornou a codificação base. Mas lembramos que a codificação é complicada e não funciona da primeira vez. Desta vez, não deu certo.
A grande desvantagem do utf-8 é que o comprimento do caractere não é fixo, o que leva ao fato de que uma operação simples como acessar o índice tem complexidade O (N), uma vez que o deslocamento do elemento não é conhecido antecipadamente, além de conhecer o tamanho do buffer, alocado para armazenar uma sequência, você não pode calcular seu comprimento em caracteres.
Para evitar todos esses problemas em python, foi decidido usar codificações de 2 e 4 bytes (dependendo da plataforma). A manipulação do índice foi simplificada - era necessário apenas multiplicar o índice por 2 ou 4. No entanto, isso implicava em seus problemas:
- Cada plataforma tinha sua própria codificação, o que poderia levar a problemas com a portabilidade do código
- Maior consumo de memória e / ou problemas de codificação para caracteres complicados que não cabem em dois bytes
Uma solução para esses problemas foi proposta no
PEP-393 , e falaremos sobre isso.
Foi decidido deixar as linhas como uma matriz de caracteres, para facilitar o acesso pelo índice e outras operações, no entanto, o comprimento dos caracteres começou a variar. Ao criar uma string, o intérprete verifica todos os caracteres e aloca para cada um o número de bytes necessário para armazenar o "maior", ou seja, se você declarar uma string ascii, todos os caracteres terão um byte único, no entanto, se você decidir adicionar um caractere à string do cirílico, todos os caracteres já terão dois bytes. Existem três opções possíveis: 1, 2 e 4 bytes por caractere.
O tipo de sequência (PyUnicodeObject) é declarado da
seguinte maneira :
typedef struct { PyCompactUnicodeObject _base; union { void *any; Py_UCS1 *latin1; Py_UCS2 *ucs2; Py_UCS4 *ucs4; } data; } PyUnicodeObject;
Por sua vez, PyCompactUnicodeObject representa a
seguinte estrutura (fornecida com algumas simplificações e meus comentários):
typedef struct { PyASCIIObject _base; Py_ssize_t utf8_length; char *utf8; Py_ssize_t wstr_length; } PyCompactUnicodeObject; typedef struct { PyObject_HEAD Py_ssize_t length; Py_hash_t hash; struct { unsigned int interned:2; unsigned int kind:3; unsigned int compact:1; unsigned int ascii:1; unsigned int ready:1; unsigned int :24; } state; wchar_t *wstr; } PyASCIIObject;
Assim, são possíveis 4 representações de linha:
- sequência herdada, pronta
* structure = PyUnicodeObject structure * : !PyUnicode_IS_COMPACT(op) && kind != PyUnicode_WCHAR_KIND * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 0 * ready = 1 * data.any is not NULL * utf8 data.any utf8_length = length ascii = 1 * utf8_length = 0 utf8 is NULL * wstr with data.any wstr_length = length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_4)=4 * wstr_length = 0 wstr is NULL
- sequência herdada, não pronta
* structure = PyUnicodeObject * : kind == PyUnicode_WCHAR_KIND * length = 0 (use wstr_length) * hash = -1 * kind = PyUnicode_WCHAR_KIND * compact = 0 * ascii = 0 * ready = 0 * interned = SSTATE_NOT_INTERNED * wstr is not NULL * data.any is NULL * utf8 is NULL * utf8_length = 0
- ascii compacto
* structure = PyASCIIObject * : PyUnicode_IS_COMPACT_ASCII(op) * kind = PyUnicode_1BYTE_KIND * compact = 1 * ascii = 1 * ready = 1 * (length — utf8 wstr ) * (data ) * ( ascii utf8 string data)
- compacto
* structure = PyCompactUnicodeObject * : PyUnicode_IS_COMPACT(op) && !PyUnicode_IS_ASCII(op) * kind = PyUnicode_1BYTE_KIND, PyUnicode_2BYTE_KIND or PyUnicode_4BYTE_KIND * compact = 1 * ready = 1 * ascii = 0 * utf8 data * utf8_length = 0 utf8 is NULL * wstr data wstr_length=length kind=PyUnicode_2BYTE_KIND and sizeof(wchar_t)=2 or if kind=PyUnicode_4BYTE_KIND and sizeof(wchar_t)=4 * wstr_length = 0 wstr is NULL * (data )
Deve-se notar que o python 3 também suporta a sintaxe para declarar cadeias unicode através do prefixo `u`.
>>> b = u"" >>> b ''
Esse recurso foi adicionado para facilitar a portabilidade do código da segunda versão para a terceira no
PEP-414 no python 3.3 apenas em fevereiro de 2012, lembrando que o python 3 foi lançado em dezembro de 2008, mas ninguém estava com pressa com a transição.
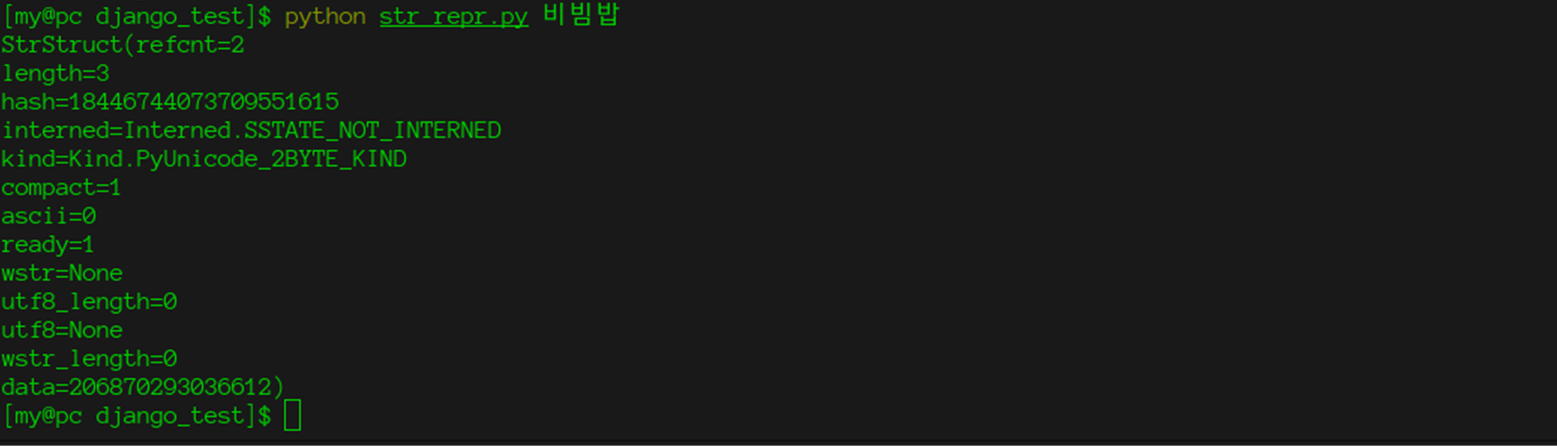
Armado com esse conhecimento e o módulo ctypes padrão, podemos acessar os campos internos da string.
import ctypes import enum import sys class Interned(enum.Enum):
E até "quebre" o intérprete, como você fez na
parte anterior .
AVISO LEGAL: O código a seguir é fornecido como está, o autor não assume nenhuma responsabilidade e não pode garantir o estado do intérprete, bem como a saúde mental de você e seus colegas, depois de executar este código. O código é testado no cpython versão 3.7 e, infelizmente, não funciona com seqüências de caracteres ascii.
Para fazer isso, altere o código descrito acima para:
def make_some_magic(str1, str2): s1 = StrStruct.from_address(id(str1)) s2 = StrStruct.from_address(id(str2)) s2.data = s1.data if __name__ == '__main__': string = "비빔밥" string2 = "háč" print(string == string2)
Esses exemplos usam a interpolação de strings adicionada no
python 3.6 . O Python não chegou imediatamente a esse método de saída de strings:% sintaxe, formato, algo
como perl foram tentados (uma descrição mais detalhada com exemplos pode ser encontrada
aqui ).
Talvez essa mudança para o seu tempo (antes do python 3.8 com seu operador `: =`) tenha sido a mais controversa. A discussão (e condenação) foi conduzida tanto no
reddit quanto na forma de
PEP . As idéias de melhoria / correção foram expressas na forma de adicionar
linhas i para as quais os usuários poderiam escrever seus analisadores, para melhor controle e evitar injeções de SQL e outros problemas. No entanto, essa alteração foi adiada, para que as pessoas se acostumem às linhas f e identifiquem problemas, se houver.
As linhas F têm uma peculiaridade (desvantagem): você não pode especificar caracteres especiais com barras, por exemplo, '\ n' '\ t'. No entanto, isso pode ser facilmente contornado declarando uma linha separada contendo caracteres especiais e passando-a para a linha f, como foi feito no exemplo acima, mas você pode usar colchetes aninhados.
>>> number = 2 >>> precision = 3 >>> f"{number:.{precision}f}" 2.000
Como você pode ver, as cadeias armazenam seu hash; houve uma
sugestão para usar esse valor para comparar cadeias, com base em uma regra simples: se as cadeias forem iguais, elas terão o mesmo hash e, portanto, as cadeias com hashes diferentes não serão as mesmas. No entanto, ele permaneceu não realizado.
Ao comparar duas strings, é verificado se os ponteiros para as strings se referem ao mesmo endereço; caso contrário, uma comparação caracter por caracter ou memcmp é iniciada nos casos em que isso é permitido.
int PyUnicode_Compare(PyObject *left, PyObject *right) { if (PyUnicode_Check(left) && PyUnicode_Check(right)) { if (PyUnicode_READY(left) == -1 || PyUnicode_READY(right) == -1) return -1; if (left == right) return 0; return unicode_compare(left, right);
No entanto, o valor do hash afeta indiretamente a comparação. O fato é que, em cpython, as strings são internadas, ou seja, armazenadas em um único dicionário. Isso não é verdade para todas as linhas; todas as constantes, chaves de dicionário, campos e variáveis e linhas ascii com comprimento inferior a 20 são internadas.
if __name__ == '__main__': string = sys.argv[1] string2 = sys.argv[2] print(id(string) == id(string2))
$ python check_interned.py aa True $ python check_interned.py 비빔밥 비빔밥 False $ python check_interned.py aaaaaaaaaaaaaaaaaaaaaaaaaaaaa aaaaaaaaaaaaaaaaaaaaaaaaaaaaa False
E a cadeia vazia é geralmente singleton
static PyUnicodeObject * _PyUnicode_New(Py_ssize_t length) { PyUnicodeObject *unicode; size_t new_size; if (length == 0 && unicode_empty != NULL) { Py_INCREF(unicode_empty); return (PyUnicodeObject*)unicode_empty; } ... }
Como podemos ver, o cpython conseguiu criar uma implementação simples, mas ao mesmo tempo eficiente, do tipo string. Foi possível reduzir a memória usada e acelerar as operações em alguns casos, graças às funções memcmp, memcpy, em vez de operações caracter por caracter. Como você pode ver, o tipo de string não é tão simples de implementar quanto pode parecer da primeira vez. Mas os desenvolvedores de cpython abordaram seus negócios com muita habilidade e, portanto, podemos usá-lo e nem pensar no que está por trás.