
Sentei-me pacificamente em um seminário, ouvi o relatório de um aluno em um artigo do
CVPR passado e pesquisei o tópico ao mesmo tempo.
- As vantagens do artigo incluem a disponibilidade do código-fonte ....
Eu tive que intervir:
- A presença de quê, com licença?
- Uhh ... Código fonte ...
"Você já assistiu?"
- Não, mas o artigo declara ...
(mãe-mãe-mãe ... ecoou habitualmente)Follow Você seguiu o link?
O artigo, de fato, é muito encorajadoramente escrito: “O código e o modelo estão disponíveis publicamente na página do projeto ... / imtqy.com / ...”, no entanto, no commit de dois anos atrás, o inspirador link “Código e modelo será apresentado em breve” :
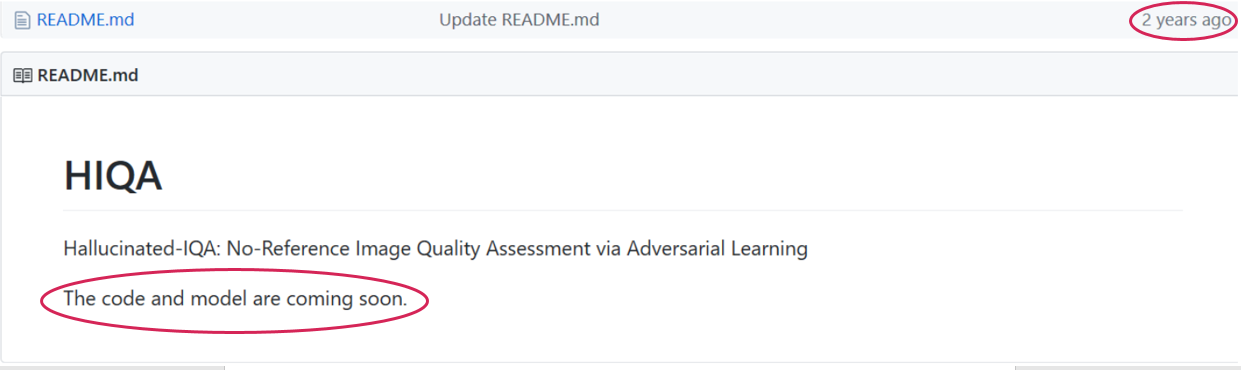
Pesquise e encontre, bata e abra ... Talvez ... Ou talvez não. Com base na minha triste experiência, eu colocaria no segundo, já que a situação se repete ultimamente, oh, oh, com muita frequência. Mesmo no CVPR. E isso é apenas parte do problema! As fontes podem estar disponíveis, mas, por exemplo, apenas um modelo, sem scripts de treinamento. E pode haver scripts de aprendizado, mas por vários meses com cartas aos autores é impossível obter o mesmo resultado. Ou, por um ano em outro conjunto de dados com chamadas regulares pelo skype, um autor nos EUA não consegue reproduzir seu resultado, obtido no laboratório mais famoso do setor, sobre esse tópico ... Algum tipo de Tryndets.
E, aparentemente, até agora vemos apenas flores. Num futuro próximo, a situação se deteriorará dramaticamente.
Quem se importa com o
que aconteceu com o aluno para onde o mundo científico está indo, inclusive através da “falha” do aprendizado profundo, seja bem-vindo ao gato!
Crise de reprodutibilidade
Em 2016,
EXISTE UMA CRISE DE REPRODUCIBILIDADE? (Existe uma crise de reprodutibilidade agora)? , que citaram os resultados de uma pesquisa com 1576 pesquisadores:
 Fonte: Este e os gráficos a seguir nesta seção são um artigo da Nature.
Fonte: Este e os gráficos a seguir nesta seção são um artigo da Nature.De acordo com os resultados da pesquisa, 52% dos pesquisadores acreditam que há uma crise significativa, 38% - uma crise leve (total de 90% no total!), 3% - que não há crise e 7% - não foram determinados.
A versão conspiratória do autor - dada a escala do desastre, este último simplesmente não deseja chamar atenção "excessiva" à questão:

Se você observar as disciplinas, verifica-se que a química está em primeiro lugar, a biologia está em segundo e a física em terceiro:
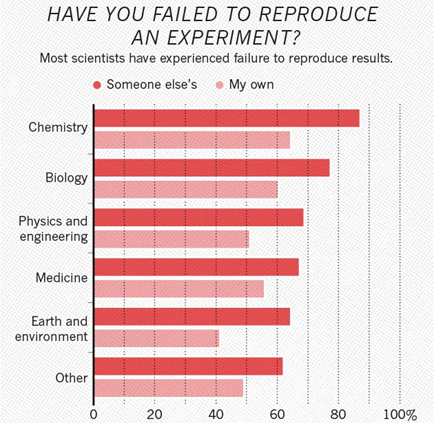
Curiosamente, na química, por exemplo, mais de 60% dos pesquisadores acharam impossível reproduzir suas próprias pesquisas. Na física, esses também são mais de 50%.
Também é muito interessante o
que exatamente do ponto de vista dos pesquisadores faz a maior contribuição para a crise da irreprodutibilidade:

Em primeiro lugar, é "Relatório seletivo". Para Ciência da Computação, essa é uma situação em que o autor, por exemplo, seleciona os melhores exemplos para publicação nos quais o algoritmo funciona e não descreve em detalhes onde e o que não funciona.
Curiosamente, o segundo é "Pressão para publicar". Este é um princípio muito conhecido de "publicar ou perecer".
Um artigo na Wikipedia em inglês descreve bem o problema. Não há nenhum artigo na Wikipedia sobre esse assunto, embora em locais com alto pagamento por trabalhos científicos, o problema se torne relevante. Por exemplo, em uma universidade de topo com um bom salário (infelizmente, não estou falando da minha Universidade Estatal de Moscou), pontuações altas em publicações são críticas para a recertificação e, se você quiser continuar trabalhando, publique. Uma carcaça, um espantalho, o que for, mas para que os pontos fossem.
Observe também que “Métodos, código indisponível” é comum em 45% dos casos e, às vezes, em 82%. Bem, a fraude direta é indicada em 40% dos casos, ou seja, com bastante frequência. Falei recentemente com um professor chinês que trabalha no campo de algoritmos de compressão de vídeo. Ele disse que na China existem muitos artigos com fraude consciente, que acabaram de se tornar um flagelo. As publicações estrangeiras com fraude são rapidamente descartadas por lá, então elas tentam cumprir, mas um pesadelo é criado por dentro (veja, por exemplo, o artigo
“Publicar ou perecer na China” na Nature). Um pesadelo, inclusive pelo seguinte motivo na lista de "Revisão insuficiente por pares" - não há força suficiente para uma revisão cruzada de alta qualidade.
Um grande problema separado, que mencionarei apenas brevemente: se o resultado não puder ser reproduzido, é quase impossível publicar um artigo sobre isso ...

Todos estão interessados em novas conquistas, novas contribuições e novas idéias, e o que é antigo não funciona - que diferença isso faz. Isso naturalmente aumenta a participação de resultados irreprodutíveis, incluindo fraudes deliberadas. Provavelmente, ninguém vai entender, isso não é aceito. É óbvio que quando outros começam a se basear em um resultado falso, todo o sistema se torna instável, o que acaba afetando a todos:
 Suas apostas
Suas apostas - tem
tempo para se esquivar ou esmagá-lo?Total:
- De acordo com uma pesquisa com 1.576 pesquisadores publicados na Nature, 52% acreditam que agora existe uma crise significativa de reprodutibilidade e 90% concordam que existe essa crise.
- Além disso, a situação atual ainda está florescendo e em breve tudo ficará pior, principalmente em Ciência da Computação. Porque Descubra agora.
Reprodutibilidade em Ciência da Computação
Na Universidade Estadual do Arizona (que, a propósito, é duas vezes maior que a Universidade Estadual de Moscou em termos de número de estudantes), um site especial
http://repeatability.cs.arizona.edu/ foi criado no departamento do programador dedicado ao estudo da reprodutibilidade de seus resultados em 601 artigos de periódicos e conferências
ACM . O resultado foi a seguinte imagem:

 Fonte: Repetibilidade em Ciência da Computação
Fonte: Repetibilidade em Ciência da ComputaçãoEles não conferiram 106 artigos porque não queriam violar a pureza do experimento (escreveram aos autores e solicitaram o código), nos demais:
- em 93 artigos (19%) não há código ou havia hardware com o qual eles não puderam ser comparados,
- em 176 artigos (35%), os autores não forneceram um código,
- em 226 artigos (46%) o código era, em 9 (2%) não era possível coletar e em 87 (64 + 23) artigos (18%) foram necessárias mais de meia hora para resolver os problemas de montagem do projeto (em 23 casos, os problemas foram eliminados falhou, mas o autor garantiu que "fazer mais esforços" tudo teria reunido).
Devo dizer que, em nossa experiência após a assembléia, o mais interessante está apenas começando, mas no estudo eles decidiram parar nesta fase, e com tantos deles você pode entender. De qualquer forma, as estatísticas são muito reveladoras e 35% das recusas em fornecer o código estão bem próximas da linha "Métodos, código indisponível" do estudo anterior (terceiro gráfico).
Em geral, o tópico é desenterrado muito bem. Em particular, o "Gold Standard" é a disponibilidade de código e dados nos quais é fácil repetir completamente o resultado, e a pior abordagem é a submissão de apenas artigos:
 Fonte: Conceituando, medindo e estudando a reprodutibilidade
Fonte: Conceituando, medindo e estudando a reprodutibilidadePor que isso está acontecendo?
Existem várias razões, como qualquer fenômeno complexo:
- No Ocidente, o mencionado "Publicar ou perecer" é muito influente. Em seminários e workshops, os jovens estudantes de pós-graduação ecológicos são completamente sérios e inequivocamente orientados - “Uma idéia surgiu, primeiro publique-a! E só então verifique! ”(Quem disse selvageria? Realidade dura, senhores!) A prioridade na ciência é realmente importante (inclusive para a notória citação); portanto, quando alguma idéia interessante surge, ela é publicada primeiro (às vezes com dados falsos) , às vezes não) e só então eles começam a programar algo por muito tempo dolorosamente, muitas vezes puxando uma coruja para o globo. O artigo citado como o primeiro exemplo no início deste texto parece ser apenas um deles (redes neurais alucinógenas ... eu me pergunto o que eles fumaram? Mas chegou ao CVPR!). O resultado é um animal peludo branco com excesso de peso, pois a situação continua se deteriorando:

- Convencionalmente, o estado doa metade do dinheiro da pesquisa (em algum lugar mais, em algum lugar menos). E o dinheiro do governo provoca loucura na publicação (quando publicado, apenas para publicação). A outra metade do dinheiro vem de empresas, e as empresas estão claramente falando sobre restrições de publicação. Uma empresa coreana popular, que ofereceu cientistas russos para trabalhar, de acordo com a expressão adequada de um colega, "por contas" era especialmente conhecida por suas condições de
negro para institutos e universidades. Sim, agora eles até quebraram o mercado na área de redes neurais na corrida salarial, mas, em geral, a primeira coisa a oferecer um contrato terrível é a identidade corporativa dessas empresas asiáticas. E quando um artigo bem escrito não pode ser publicado, e depois outro e mais - ele desmotiva fortemente, é claro. Isso, mesmo depois de alguns anos, não é esquecido.
Como resultado, o resultado vai para patentes com um mínimo de artigos. É interessante que eu falei com colegas da Finlândia, EUA, França etc. Lá, muitas pessoas se apoiam firmemente em subsídios, mas aqueles que têm muitas empresas também publicam longe de todos os resultados e, se publicam, reduzem de alguma forma (culturalmente) a descrição da abordagem, complicando naturalmente a reprodução. Para isso já foi pago.
Total:
- Mesmo após solicitações urgentes, o código é enviado em um máximo de 46% dos casos (a propósito, leia o estudo , há exemplos interessantes de "desculpas", em nossa experiência exatamente como estas basicamente enviam).
- O próprio sistema de financiamento científico incentiva a publicação de resultados não verificados o mais rápido possível ou restringe as publicações, inclusive em termos de divulgação completa. Nos dois casos, a reprodutibilidade diminui.
Por que o aprendizado de máquina piora as coisas
Mas isso não é tudo! Recentemente, o aprendizado de máquina em geral e as redes neurais em particular estão se espalhando rapidamente. Isso é demais. Funciona incrivelmente. O ontem completamente impossível se torna possível hoje! Apenas algum tipo de feriado! Então
Não. As redes neurais adicionaram à Ciência da Computação uma nova rodada de imersão no abismo da irreprodutibilidade.
Aqui está um exemplo simples: parece com a função de perda para o
ResNet-56 sem pular conexões (visualização de alguns parâmetros de várias dezenas de milhões). Nossa tarefa para um número razoável de iterações (eras) é encontrar o ponto mais profundo:
 Fonte: Visualizando o cenário de perda de redes neurais
Fonte: Visualizando o cenário de perda de redes neuraisVocê pode ver claramente o mar dos mínimos locais, nos quais nosso declive gradiente "cai alegremente" e "não pode" sair dali. Sim, é claro que é para a ResNet que este exemplo é usado como uma excelente ilustração, fornecida por
ignorar conexões (após a introdução de qual aprendizado de rede é dramaticamente aprimorado):
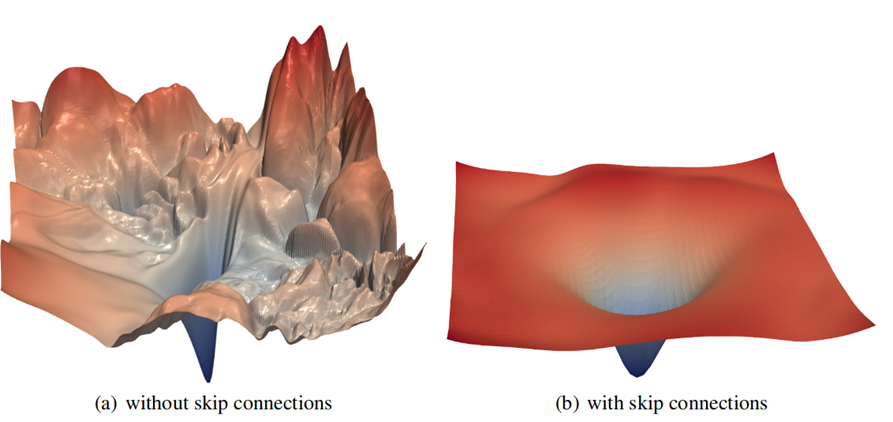
Uma coisa é tentar encontrar o mínimo em um cenário complexo (e apenas a dimensão geral proibitiva do espaço de pesquisa ajuda), e outra coisa é ver um mínimo global relativamente fácil de encontrar com gradientes.
A história é linda, mas em nossa dura realidade, com um grande número de camadas, uma e outra vez, temos que enfrentar o fato de que a rede não está aprendendo. Geralmente.
E ainda mais interessante - em algum momento é possível treiná-lo (o erro diminui acentuadamente), mas depois de algum tempo, ao tentar reproduzir o resultado do zero (por exemplo, quando esses coeficientes são perdidos), não é possível repetir o foco, e há uma jornada dolorosa óbvia da rede à distância de um mínimo. Centenas de
épocas se sucedem e o carrinho permanece no lugar. A Flor de Pedra não sai de Danila, a mestra.
Era bastante difícil imaginar uma situação em que um pesquisador não pudesse reproduzir seus próprios resultados em Ciência da Computação. Hoje tornou-se comum, como há muito tempo em física, química, biologia e mais adiante na lista.
Com redes neurais, a Ciência da Computação de repente se tornou uma ciência experimental! Bem-vindo a este mundo maravilhoso. Agora você será cada vez mais confrontado com a incapacidade de reproduzir seu
próprio resultado (como 64% dos químicos, 60% dos biólogos, veja o segundo gráfico deste artigo).
Mas isso não é tudo alegria. Mais será mais divertido!
Em geral, durante algum tempo fiquei bastante cético em relação às redes neurais, pois os algoritmos baseados nelas não funcionavam. Bem ... eles de alguma forma funcionaram, é claro, mas perderam amostras grandes para os algoritmos de ponta "clássicos" (que não os impediram de serem publicados em massa). Isso aconteceu porque as redes neurais são extremamente convenientes para todos os tipos de fraudes. O principal é selecionar corretamente uma amostra de treinamento para exemplos e você pode demonstrar naturalmente milagres. Acontece belas imagens (e, às vezes, belas imagens), e o artigo vai bem. Você pode até definir o código (parece que ficou na moda), isso não muda a essência. Isso não funciona. Mas quando o grande galo vermelho
PoP com um enorme bico afiado aparece por trás ... o artigo é um figo e vai para impressão.

Um grande problema separado são as áreas em que não há grandes amostras de treinamento. Colegas de medicina reclamam - um pesadelo completo está acontecendo. Eles colecionam conjuntos de dados há anos. E existem até dezenas de milhares de exemplos. Mas estudantes de pós-graduação com redes neurais profundas vêm. Figak-figak e ultrapassou todos ... Bonito! Os gigantes da ciência! E com rostos brilhantes e felizes, relate os resultados. Eles são perguntados:
- O que você fez para evitar o ajuste excessivo?
- desculpe?
- Por que você não tem reciclagem?
E um homem absolutamente fala seriamente como ele pegou a rede certa e a treinou estritamente de acordo com o manual de treinamento e, portanto, está tudo bem com ele. I.e. jovens (maciçamente!) não entendem o que é reciclagem! Não um, não dois, mas apenas uma parte notável dos relatórios de pós-graduação. Aqui está, uma nova onda de jovens revolucionários da rede neural. Lembramos o
professor Preobrazhensky , suspiramos profundamente sobre o analfabetismo tradicional para jovens revolucionários. Tiramos conclusões.
Mas tudo bem. No recente
ITIS 2019, Mikhail Belyaev deu exemplos maravilhosos de como essa abordagem chega muito bem à produção médica! Em empresas reais que oferecem análises usando redes neurais, elas passaram nos testes de controle e receberam resultados inesperadamente tristes. O motivo é que os investidores também sentiram uma revolução e, se uma pessoa promete novos horizontes com base em redes neurais, ela recebe dinheiro (a perspicaz Anatoly Levenchuk
alertou sobre isso já em 2015, meio ano após a invenção do
benchmark e meio ano antes da ResNet, quando muitas camadas ainda são mal treinadas). E pague por isso, queridos senhores! E, sim, seria melhor experimentar primeiro os ratos, mas os ratos, como disse um cínico familiar, não têm carteiras! Portanto, agora os dados para treinamento estão sendo coletados (expressos culturalmente) com dinheiro do consumidor, ou seja, no seu dinheiro. Pessoas, sejam vigilantes!
É claro que não são as redes neurais que devem ser responsabilizadas. A grande questão é como obter uma quantidade suficiente de dados adjacentes,
ajustá- los em uma pequena amostra, evitar
esquecimentos catastróficos e isso é tudo. Mas, mesmo se você tiver pesquisadores competentes, isso levará tempo. E o investidor quer um resultado
aqui e ontem . Então, se alegrou com a onda de sucesso das redes neurais?
Temos uma
espuma grande
de uma onda grande, quando métodos inoperantes de fato arrastaram o surf de ondas grandes para o uso real. Pague a conta, por favor!
Total: As redes neurais agravam a situação em Ciência da Computação em três áreas:
- Com o treinamento de redes neurais, o CS do primeiro se torna uma ciência experimental com todas as desvantagens resultantes.
- Ajustar a amostra de treinamento ao teste permite que você demonstre qualquer resultado arbitrariamente maravilhoso (exacerbando o principal motivo da irreprodutibilidade - relatórios seletivos).
- E, finalmente, em áreas onde as amostras de treinamento são pequenas, é extremamente difícil evitar a reciclagem, com a qual muitos não sabem como capturar e trabalhar (formalmente, o resultado é excelente no conjunto de dados, mas na verdade o algoritmo não funciona).
O que pode ser feito?
Se você (uma pessoa feliz!) Trabalha em áreas bem cavadas, geralmente todo o trabalho é preparar conjuntos de dados e alimentá-los às redes. A menos que valha a pena assistir arquiteturas. Nesse caso, não faz sentido assistir a artigos sem código. E este é um feriado de verdade! Sinta sua felicidade, nem todo mundo tem tanta sorte!
Existe ainda um site como o
PapersWithCode.com , que no campo de aprendizado de máquina coleta propositalmente artigos, analisa automaticamente a classificação de seus repositórios no GitHub, lista tudo por categoria e adiciona referências e conjuntos de dados. Em geral - tudo é para pessoas! A propósito, de acordo com seus cálculos, o código agora está disponível apenas para 17 a 19% dos artigos:
 Fonte: porcentagem de artigos publicados que possuem pelo menos uma implementação de código
Fonte: porcentagem de artigos publicados que possuem pelo menos uma implementação de códigoMas eles, se ficarmos distraídos por um segundo (e ainda anunciarmos esses caras certos), há um cronograma muito interessante para mudar a popularidade das estruturas de ML / DL nos últimos 4 anos:
 Fonte: Implementações em papel agrupadas por estrutura
Fonte: Implementações em papel agrupadas por estruturaTocha no cavalo, TF (quem teria pensado recentemente!) Está perdendo terreno. No entanto, esta é uma história diferente ...
Por experiência, fica claro que esses 17 a 20% dos artigos com código também (pelas razões descritas) nem tudo é mágico, mas pelo menos você pode verificar o trabalho deles em uma ordem de magnitude mais rapidamente. E isso é incrível.
Outra receita realmente funcional é a criação de conjuntos de dados e benchmarks bastante grandes. O surgimento de redes neurais começou em vão com o
ImageNet, com 14 milhões de imagens, divididas em mais de 20.000 classes. Sim, é difícil, mas com o aprendizado profundo você pode trabalhar apenas com conjuntos
realmente grandes. Mesmo que sua criação seja dolorosa e difícil.
Por exemplo, há algum tempo, criamos uma
referência para destacar objetos translúcidos em um vídeo (lã, cabelo, tecidos, fumaça e outras alegrias não triviais da vida). Inicialmente, foi planejado manter-se dentro de quando foi criado em 3 meses. Servomotores foram encontrados, uma tela, uma boa câmera
, uma fita elétrica azul foi comprada , um milhão de brinquedos macios foram requisitados de todas as amigas das meninas, um manequim com cabelo de verdade foi encontrado no qual os cabeleireiros treinam o penteado. E ...
 Fonte: materiais do autor ... A fita isolante azul, como pode ser claramente visto, desempenha um papel importante de apoio
Fonte: materiais do autor ... A fita isolante azul, como pode ser claramente visto, desempenha um papel importante de apoioTudo (não, não é assim ... TUDO!) Dava errado. , ( ), ( ), ( , ). Etc. ..
( ), , . , ! , - , , .
— . , . , , , (. ,
25 Kaggle).
Total:
Pelo texto acima, pode parecer que o autor acredita que tudo está ruim, tudo está perdido e, em geral ... Isso não é verdade. Se apenas um grande número de obras não reproduzíveis cria uma demanda constante pelo trabalho do autor e de seus colegas, e a deterioração da situação significa que agora teremos que trabalhar sem parar, a demanda será apenas maior.Além disso, deve ser claramente entendido que a situação com irreprodutibilidade nas ciências exatas não pode ser comparada com a escala do desastre nas ciências humanitárias. O artigo da Wikipedia Replication crise (ela, infelizmente, não tem uma versão russa novamente) concentra-se apenas nas ciências humanas, principalmente na psicologia, situação em que há muito tempo é triste: Fonte:The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...
Fonte:The Reproducibility Crisis in Psychological Science: One Year Later , , , , , … , Computer Science ...! 20 ,
Computer Science , (
), - . — , .

E o último.
Prometi dizer o que aconteceu com o aluno. Ele foi severamente punido ao preparar materiais e fotos para este artigo. Para que não fosse bom!Toda a pesquisa mais reproduzível a caminho!Leia também:Agradecimentos
A introdução utiliza desenhos do workshop A crise de replicação e do artigo Science for Sale: The Other Problem With Corporate Money .Além disso, gostaria de agradecer cordialmente:- . .. ,
- , , , , ,
- , , ,
- , , , , , , , , , , !