 O que?
O que? Um codec de vídeo é um software / hardware que compacta e / ou descompacta o vídeo digital.
Para que? Apesar de certas limitações em termos de largura de banda,
e em termos de quantidade de espaço de armazenamento, o mercado exige cada vez mais vídeos de alta qualidade. Lembre-se de como, na última postagem, calculamos o mínimo necessário para 30 quadros por segundo, 24 bits por pixel, com uma resolução de 480x240? Recebeu 82,944 Mbps sem compactação. A compressão é a única maneira de transferir HD / FullHD / 4K para telas de TV e Internet. Como isso é alcançado? Agora vamos considerar brevemente os principais métodos.

A tradução foi feita com o apoio do software EDISON.
Estamos envolvidos na integração de sistemas de vigilância por vídeo , bem como no desenvolvimento de um microtomógrafo .
Codec vs Container
Um erro comum para iniciantes é confundir um codec de vídeo digital e um contêiner de vídeo digital. Um contêiner é um determinado formato. Um wrapper contendo metadados de vídeo (e possivelmente áudio). O vídeo compactado pode ser considerado como uma carga útil do contêiner.
Normalmente, uma extensão de arquivo de vídeo indica um tipo de contêiner. Por exemplo, o arquivo video.mp4 provavelmente é um contêiner
MPEG-4 Parte 14 e o arquivo video.mkv provavelmente é uma
boneca russa. Para ter total confiança no codec e no formato do contêiner, você pode usar o
FFmpeg ou o
MediaInfo .
Um pouco de história
Antes de chegarmos a
Como? , vamos explorar um pouco da história para entender um pouco melhor alguns codecs antigos.
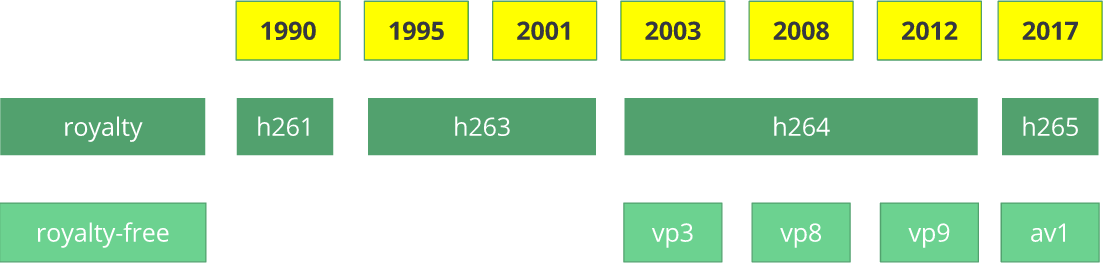
O codec de vídeo
H.261 apareceu em 1990 (tecnicamente - em 1988) e foi criado para funcionar com uma taxa de transferência de dados de 64 Kbps. Ele já usou idéias como subamostragem de cores, macroblocos etc. Em 1995, foi publicado o padrão de codec de vídeo
H.263 , desenvolvido até 2001.
Em 2003, a primeira versão do
H.264 / AVC foi concluída. No mesmo ano, o TrueMotion lançou seu codec de vídeo gratuito que comprime o vídeo com perdas chamado
VP3 . Em 2008, o Google comprou esta empresa, lançando o
VP8 no mesmo ano. Em dezembro de 2012, o Google lançou o
VP9 e é suportado em aproximadamente ¾ do mercado de navegadores (incluindo dispositivos móveis).
O AV1 é um novo codec de vídeo de código aberto gratuito desenvolvido
pela Open Media Alliance (
AOMedia ), que inclui empresas conhecidas como Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel e Cisco. . A primeira versão do codec 0.1.0 foi publicada em 7 de abril de 2016.
Nascimento do AV1
No início de 2015, o Google trabalhou no
VP10 , o Xiph (que pertence à Mozilla) trabalhou no
Daala e a Cisco criou seu codec de vídeo gratuito chamado
Thor .
Em seguida, a
MPEG LA anunciou pela primeira vez limites anuais para
HEVC (
H.265 ) e uma taxa 8 vezes maior que para H.264, mas eles logo mudaram as regras novamente:
sem limite anual,
taxa de conteúdo (0,5% da receita) e
os custos unitários são cerca de 10 vezes superiores aos do H.264.
A Open Media Alliance foi criada por empresas de vários campos: fabricantes de equipamentos (Intel, AMD, ARM, Nvidia, Cisco), provedores de conteúdo (Google, Netflix, Amazon), fabricantes de navegadores (Google, Mozilla) e outros.
As empresas tinham um objetivo comum - um codec de vídeo sem royalties. Depois vem o
AV1 com uma licença de patente muito mais simples. Timothy B. Terriberry fez uma apresentação impressionante, que se tornou a fonte do conceito atual do AV1 e seu modelo de licença.
Você ficará surpreso ao saber que pode analisar o codec AV1 por meio de um navegador (os interessados podem ir ao
aomanalyzer.org ).

Codec universal
Vamos analisar os mecanismos básicos subjacentes ao codec de vídeo universal. A maioria desses conceitos é útil e usada em codecs modernos, como
VP9 ,
AV1 e
HEVC . Eu aviso que muitas coisas explicadas serão simplificadas. Exemplos do mundo real às vezes serão usados (como é o caso do H.264) para demonstrar a tecnologia.
1º passo - dividir a imagem
O primeiro passo é dividir o quadro em várias seções, subseções e muito mais.

Para que? Existem muitas razões. Quando dividimos a imagem, podemos prever com mais precisão o vetor de movimento usando pequenas seções para pequenas partes móveis. Quanto a um plano de fundo estático, você pode restringir-se a seções maiores.
Normalmente, os codecs organizam essas seções em seções (ou fragmentos), macroblocos (ou blocos de uma árvore de codificação) e muitas subseções. O tamanho máximo dessas partições varia, o HEVC define 64x64, enquanto o AVC usa 16x16, e as subseções podem ser divididas em 4x4.
Lembre-se das variedades de quadros do último artigo ?! O mesmo pode ser aplicado aos blocos, para que possamos ter um fragmento I, bloco B, macrobloco P, etc.
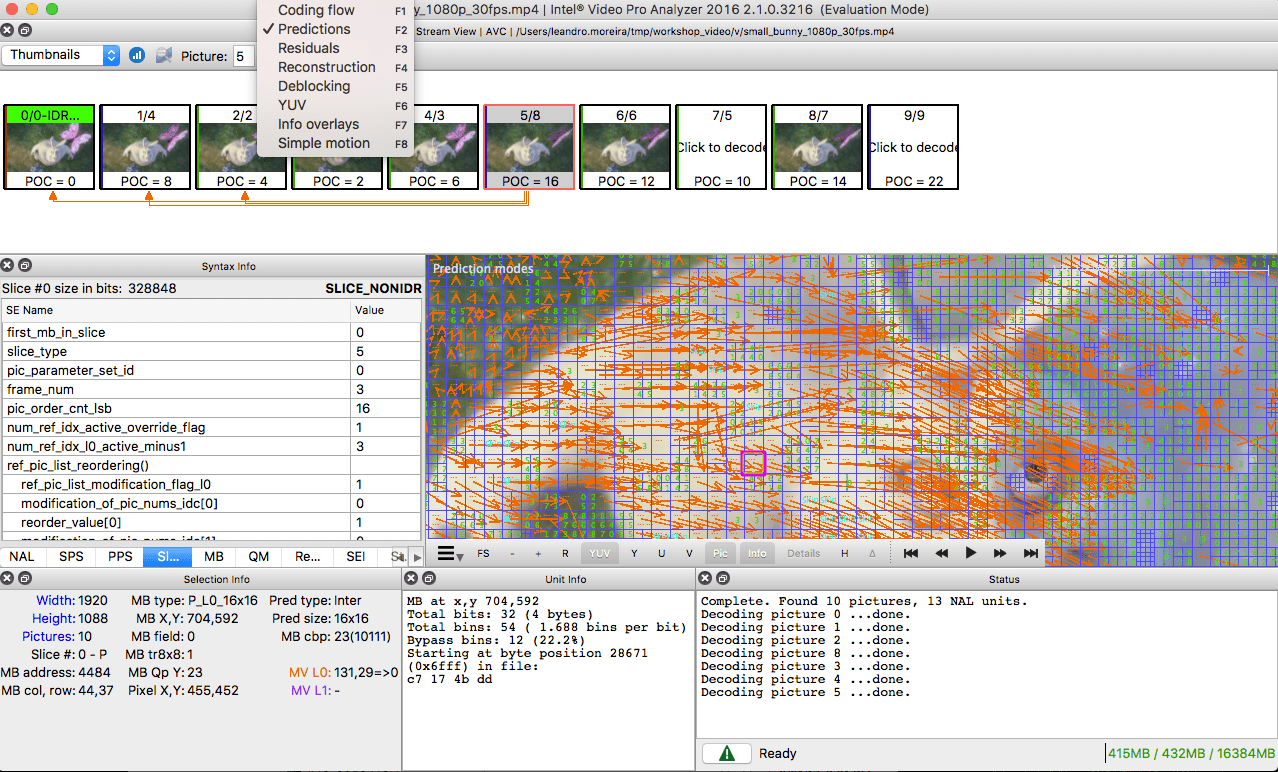
Para aqueles que querem praticar, veja como a imagem será dividida em seções e subseções. Para fazer isso, você pode usar o
Intel Video Pro Analyzer já mencionado no artigo anterior (o que é pago, mas com uma versão de avaliação gratuita, que tem um limite nos 10 primeiros quadros). As seções do
VP9 são analisadas aqui:

2º passo - previsão
Assim que tivermos seções, podemos fazer previsões
astrológicas sobre elas. Para
a previsão INTER, é necessário transferir
vetores de movimento e o restante, e para a previsão INTRA, a
direção da previsão e o restante são transmitidos.
3º passo - conversão
Depois de obtermos o bloco residual (a seção prevista → a seção real), é possível transformá-lo de forma a saber quais pixels podem ser descartados, mantendo a qualidade geral. Existem algumas transformações que fornecem comportamento preciso.
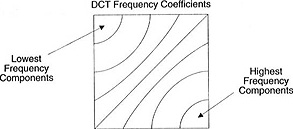
Embora existam outros métodos, vamos considerar mais detalhadamente a
transformação discreta de cosseno (
DCT - da
transformação discreta de cosseno ). Principais recursos do DCT:
- Converte blocos de pixels em blocos de tamanho igual de coeficientes de frequência.
- Sela a energia, ajudando a eliminar a redundância espacial.
- Fornece reversibilidade.
2 de fevereiro de 2017 Sintra R.J. (Cintra, RJ) e Bayer F.M. (Bayer FM) publicou um artigo sobre conversão tipo DCT para compactação de imagem, exigindo apenas 14 adições.
Não se preocupe se você não entender os benefícios de cada item. Agora, com exemplos concretos, verificaremos seu valor real.
Vamos pegar um bloco de 8x8 pixels como este:
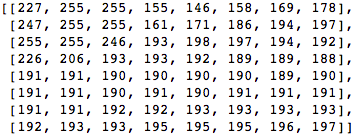
Este bloco é renderizado na seguinte imagem 8 por 8 pixels:
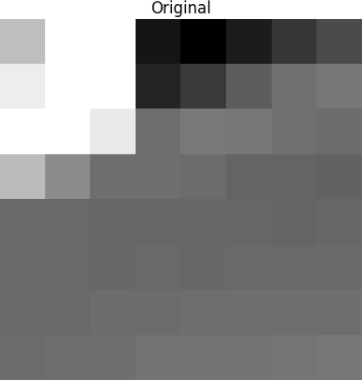
Aplique o DCT a esse bloco de pixels e obtenha um bloco de coeficientes de tamanho 8x8:
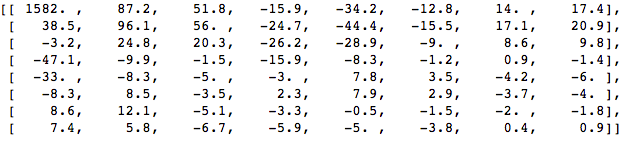
E se renderizarmos esse bloco de coeficientes, obteremos a seguinte imagem:
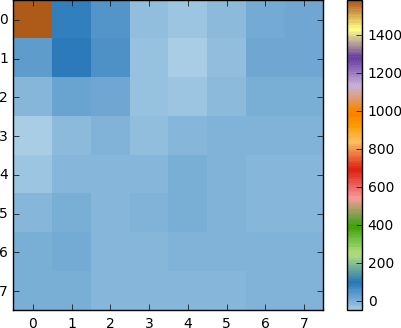
Como você pode ver, isso não é como a imagem original. Você pode perceber que o primeiro coeficiente é muito diferente de todos os outros. Esse primeiro coeficiente é conhecido como coeficiente DC, representando todas as amostras na matriz de entrada, algo semelhante ao valor médio.
Esse bloco de coeficientes tem uma propriedade interessante: separa os componentes de alta frequência dos de baixa frequência.
Na imagem, a maior parte da energia está concentrada em frequências mais baixas; portanto, se você converter a imagem em seus componentes de frequência e descartar os coeficientes de frequência mais altos, poderá reduzir a quantidade de dados necessários para descrever a imagem sem sacrificar muito a qualidade da imagem.
Frequência significa a rapidez com que o sinal muda.
Vamos tentar aplicar o conhecimento adquirido no exemplo de teste, convertendo a imagem original em sua frequência (bloco de coeficientes) usando o DCT e descartando alguns dos coeficientes menos importantes.
Primeiro, converta-o para o domínio da frequência.
Em seguida, descartamos parte (67%) dos coeficientes, principalmente o lado inferior direito.
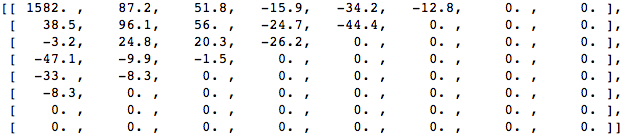
Por fim, restauramos a imagem desse bloco de coeficientes descartados (lembre-se de que deve ser reversível) e comparamos com o original.
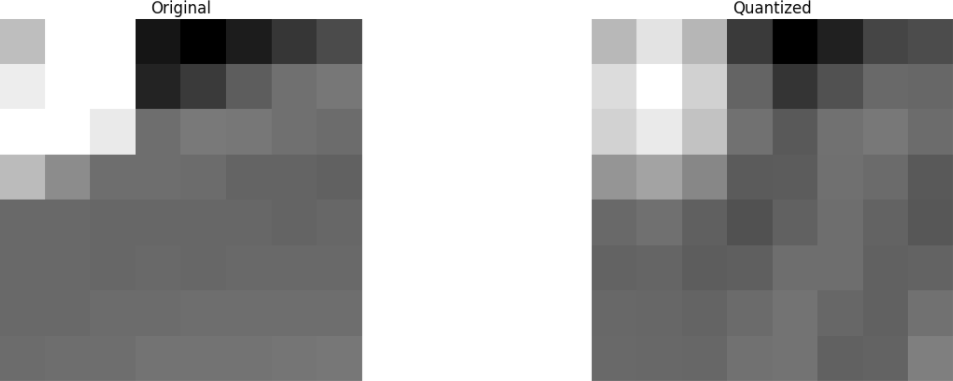
Vemos que ela se assemelha à imagem original, mas há muitas diferenças em relação à original. Jogamos 67,1875% e ainda temos algo que se assemelha à fonte original. Você poderia deliberadamente descartar os coeficientes para obter uma imagem de qualidade ainda melhor, mas este é o próximo tópico.
Cada coeficiente é gerado usando todos os pixels.
Importante: cada coeficiente não é exibido diretamente em um pixel, mas é uma soma ponderada de todos os pixels. Este gráfico incrível mostra como o primeiro e o segundo coeficientes são calculados usando pesos exclusivos para cada índice.
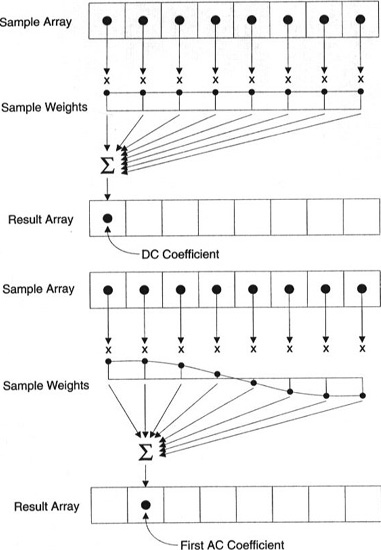
Você também pode tentar visualizar o DCT observando imagens simples com base nele. Por exemplo, aqui está o símbolo A gerado usando cada peso do coeficiente:

4º passo - quantização
Depois de jogarmos alguns coeficientes na etapa anterior, na última etapa (transformação), produzimos uma forma especial de quantização. Neste ponto, é permitido perder informações. Ou, mais simplesmente, quantizaremos os coeficientes para obter a compactação.
Como um bloco de coeficientes pode ser quantizado? Um dos métodos mais simples será a quantização uniforme; quando pegamos um bloco, dividimos por um valor (por 10) e arredondamos o que aconteceu.
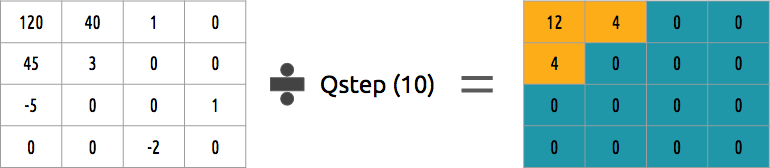
Podemos reverter esse bloco de coeficientes? Sim, podemos multiplicar pelo mesmo valor pelo qual dividimos.
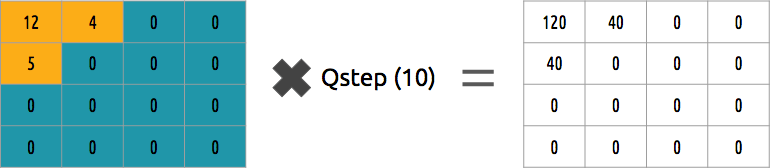
Essa abordagem não é a melhor, pois não leva em consideração a importância de cada coeficiente. Pode-se usar a matriz quantizadora em vez de um único valor, e essa matriz pode usar a propriedade DCT, quantizando a maior parte do canto inferior direito e uma minoria do canto superior esquerdo.
5 passo - codificação de entropia
Depois de quantizarmos os dados (blocos de imagens, fragmentos, quadros), ainda podemos compactá-los sem perda. Existem muitas maneiras algorítmicas de compactar dados. Vamos nos familiarizar brevemente com alguns deles, para uma compreensão mais profunda, você pode ler o livro “
Entendendo a Compactação: Compactação de Dados para Desenvolvedores Modernos ” (“
Entendendo a Compactação: Compactação de Dados para Desenvolvedores Modernos ”).
Codificação de vídeo com VLC
Suponha que tenhamos um fluxo de caracteres:
a ,
e ,
r e
t . A probabilidade (variando de 0 a 1) de quantas vezes cada símbolo ocorre no fluxo é apresentada nesta tabela.
Podemos atribuir códigos binários únicos (de preferência pequenos) aos códigos mais prováveis e maiores, menos prováveis.
Comprimimos o fluxo, assumindo que, no final, gastamos 8 bits para cada caractere. Sem compressão em um personagem, seriam necessários 24 bits. Se cada caractere for substituído por seu código, obteremos economia!
O primeiro passo é codificar o caractere
e , que é 10, e o segundo caractere é
a , que é adicionado (não matematicamente): [10] [0] e, finalmente, o terceiro caractere
t , que torna nosso bitstream final comprimido igual [10] [0] [1110] ou
1001110 , que requer apenas 7 bits (3,4 vezes menos espaço que o original).
Observe que cada código deve ser um código exclusivo com um prefixo.
O algoritmo de Huffman ajudará a encontrar esses números. Embora esse método não exista falhas, existem codecs de vídeo que ainda oferecem esse método algorítmico para compactação.
Tanto o codificador quanto o decodificador devem ter acesso à tabela de símbolos com seus códigos binários. Portanto, também é necessário enviar uma tabela na entrada.
Codificação aritmética
Suponha que tenhamos um fluxo de caracteres:
a ,
e ,
r , se sua probabilidade é representada por esta tabela.
Com esta tabela, construímos intervalos contendo todos os caracteres possíveis, classificados pelo maior número.

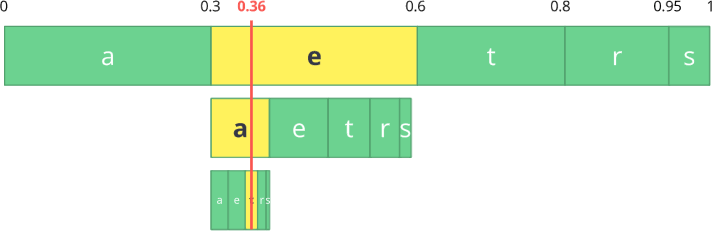
Agora vamos codificar um fluxo de três caracteres:
comer .
Primeiro, selecione o primeiro caractere
e , que está no sub-intervalo de 0,3 a 0,6 (não incluindo). Pegamos esse subintervalo e o dividimos novamente nas mesmas proporções de antes, mas já para esse novo intervalo.

Vamos continuar a codificar nosso fluxo de
comer . Agora, pegamos o segundo caractere
a , que está no novo subintervalo de 0,3 a 0,39, e depois pegamos nosso último caractere
te , repetindo o mesmo processo novamente, obtemos a última sub-banda de 0,354 a 0,372.
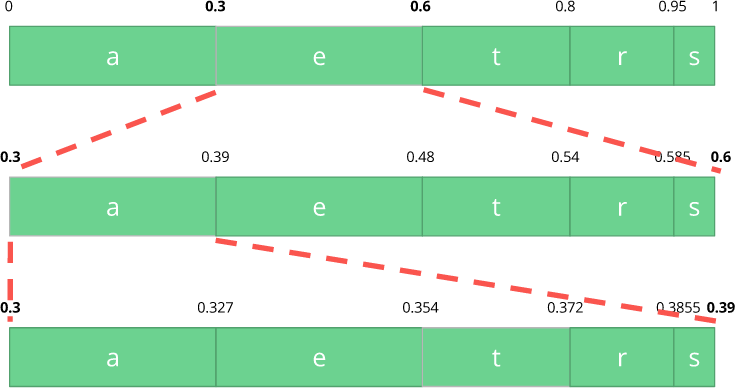
Só precisamos selecionar um número no último sub-intervalo de 0,354 a 0,372. Vamos escolher 0,36 (mas você pode escolher qualquer outro número neste sub-intervalo). Somente com esse número podemos restaurar nosso fluxo original. É como se estivéssemos desenhando uma linha dentro de intervalos para codificar nosso fluxo.
A operação reversa (isto é,
decodificação ) é igualmente simples: com nosso número 0,36 e nosso intervalo inicial, podemos iniciar o mesmo processo. Mas agora, usando esse número, revelamos o fluxo codificado usando esse número.
Com o primeiro intervalo, notamos que nosso número corresponde a uma fatia, portanto, esse é o nosso primeiro caractere. Agora, novamente, compartilhamos essa sub-banda, executando o mesmo processo de antes. Aqui você pode ver que 0,36 corresponde ao caractere
a e, após repetir o processo, chegamos ao último caractere
t (formando nosso fluxo original codificado
eat ).
Tanto o codificador quanto o decodificador devem ter uma tabela de probabilidades de símbolos; portanto, é necessário enviá-lo nos dados de entrada.
Muito elegante, não é? Alguém que veio com essa solução foi muito esperto. Alguns codecs de vídeo usam essa técnica (ou, em qualquer caso, oferecem-na como uma opção).
A idéia é comprimir um fluxo de bits quantificado sem perdas. Certamente neste artigo não há toneladas de detalhes, razões, compromissos, etc. Mas você, se você é um desenvolvedor, deve saber mais. Novos codecs estão tentando usar algoritmos diferentes de codificação de entropia, como o
ANS .
6 etapas - formato bitstream
Depois de fazer tudo isso, resta descompactar os quadros compactados no contexto das etapas executadas. O decodificador deve ser informado explicitamente das decisões tomadas pelo codificador. O decodificador deve receber todas as informações necessárias: profundidade de bits, espaço de cores, resolução, informações sobre previsões (vetores de movimento, predição INTER direcional), perfil, nível, taxa de quadros, tipo de quadro, número de quadros e muito mais.
Vamos dar uma olhada no fluxo de bits
H.264 . Nosso primeiro passo é criar um fluxo de bits H.264 mínimo (o FFmpeg, por padrão, adiciona todos os parâmetros de codificação, como o
SEI NAL - um pouco mais adiante, descobriremos o que é). Podemos fazer isso usando nosso próprio repositório e o FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264Este comando irá gerar um fluxo de bits
H.264 bruto com um quadro, resolução 64x64, com o espaço de cores
YUV420 . A imagem a seguir é usada como moldura.

H.264 Bitstream
O
padrão AVC (
H.264 ) define que as informações serão enviadas em quadros de macro (no entendimento da rede) chamados
NAL (esse é o nível de abstração da rede). O principal objetivo do NAL é fornecer uma apresentação de vídeo "amigável à rede". Esse padrão deve funcionar em TVs (com base em fluxos), na Internet (com base em pacotes).

Há um marcador de sincronização para definir os limites dos elementos NAL. Cada marcador de sincronização contém o valor
0x00 0x00 0x01, com exceção do primeiro, que é
0x00 0x00 0x00 0x01. Se executarmos o
hexdump para o fluxo de bits H.264 gerado, identificaremos pelo menos três padrões NAL no início do arquivo.
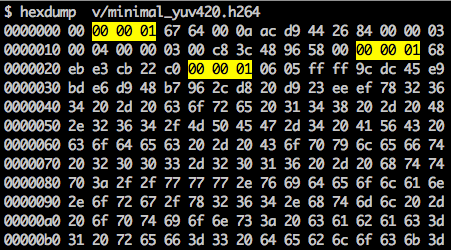
Como afirmado, o decodificador deve conhecer não apenas os dados da imagem, mas também os detalhes do vídeo, quadro, cor, parâmetros usados e muito mais. O primeiro byte de cada NAL define sua categoria e tipo.
Normalmente, o primeiro fluxo de bits NAL é o
SPS . Esse tipo de NAL é responsável por relatar variáveis de codificação comuns, como perfil, nível, resolução e muito mais.
Se pularmos o primeiro token de sincronização, podemos decodificar o primeiro byte para descobrir que tipo de NAL é o primeiro.
Por exemplo, o primeiro byte após o marcador de sincronização é
01100111 , onde o primeiro bit (
0 ) está no campo f
orbidden_zero_bit . Os próximos 2 bits (
11 ) nos dizem o campo
nal_ref_idc, que indica se esse NAL é um campo de referência ou não. E os 5 bits restantes (
00111 ) nos
informam o campo
nal_unit_type; nesse caso, é o bloco SPS (
7 ) NAL.
O segundo byte (
binário =
01100100 ,
hex =
0x64 ,
dec =
100 ) no SPS NAL é o campo
profile_idc, que mostra o perfil que o codificador usou. Nesse caso, um perfil alto limitado foi usado (isto é, um perfil alto sem suporte para um segmento B bidirecional).

Se nos familiarizarmos com a especificação do fluxo de bits
H.264 para o SPS NAL, encontraremos muitos valores para o nome do parâmetro, categoria e descrição. Por exemplo, vejamos os
campos pic_width_in_mbs_minus_1 e
pic_height_in_map_units_minus_1 .
Se realizarmos algumas operações matemáticas com os valores desses campos, obteremos permissão. Você pode imaginar
1920 x 1080 usando
pic_width_in_mbs_minus_1 com um valor de
119 ((119 + 1) * macroblock_size = 120 * 16 = 1920) . Mais uma vez, economizando espaço, em vez de codificar 1920, eles o fizeram com 119.
Se continuarmos a verificar o vídeo criado em formato binário (por exemplo:
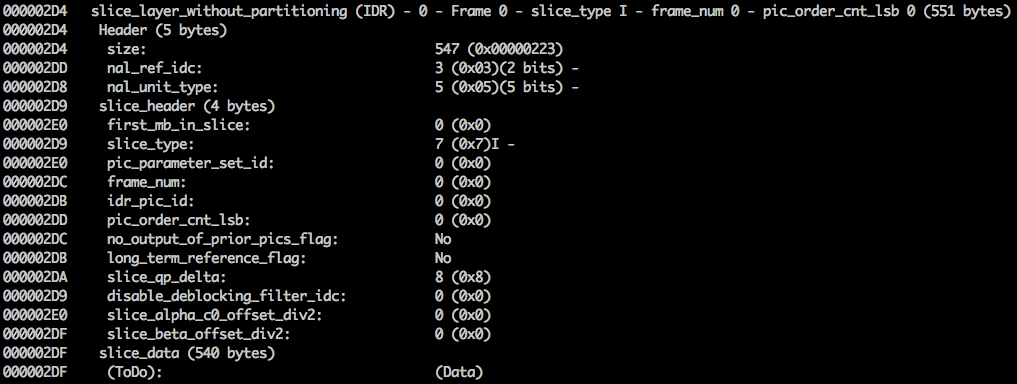
xxd -b -c 11 v / minimal_yuv420.h264 ), poderemos ir para o último NAL, que é o próprio quadro.

Aqui, vemos seus primeiros valores de 6 bytes:
01100101 10001000 10000100 00000000 00100001 11111111 . Como se sabe que o primeiro byte indica o tipo de NAL, neste caso (
00101 ), este é um fragmento de IDR (5) e, em seguida, será possível estudá-lo mais:

Usando as informações de especificação, será possível decodificar o tipo de fragmento (
slice_type ) e o número do quadro (
frame_num ) entre outros campos importantes.
Para obter os valores de alguns campos (
ue (
v ),
eu (
v ),
se (
v ) ou
te (
v )), precisamos decodificar o fragmento usando um decodificador especial baseado no
código exponencial de Golomb . Este método é muito eficaz para codificar valores de variáveis, especialmente quando existem muitos valores padrão.
Os valores
slice_type e
frame_num deste vídeo são 7 (fragmento I) e 0 (primeiro quadro).
O fluxo de bits pode ser considerado como um protocolo. Se você quiser saber mais sobre o fluxo de bits, consulte a especificação
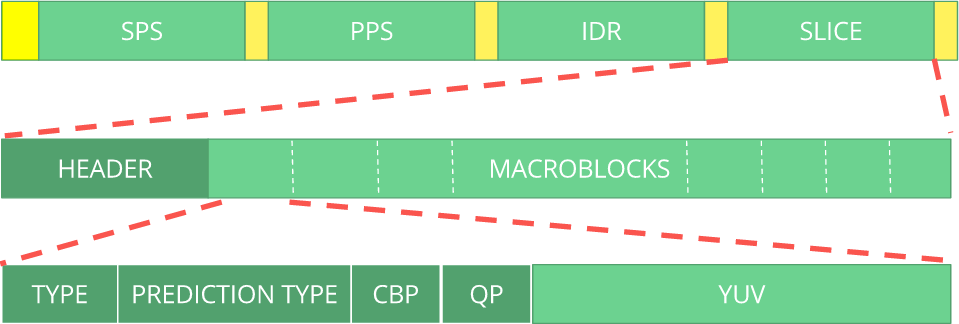
ITU H.264 . Aqui está uma macro mostrando onde estão os dados da imagem (
YUV na forma compactada).
Você pode explorar outros fluxos de bits, como
VP9 ,
H.265 (
HEVC ) ou até mesmo nosso novo melhor fluxo de bits
AV1 . Eles são todos iguais? Não, mas lidar com pelo menos um deles é muito mais fácil de entender o resto.
Quer praticar? Explore o fluxo de bits H.264
Você pode gerar vídeo de quadro único e usar o MediaInfo para examinar o fluxo de bits H.264 . De fato, nada impede que você veja o código-fonte que analisa o fluxo de bits H.264 ( AVC ).
Para praticar, você pode usar o Intel Video Pro Analyzer (eu já disse que o programa é pago, mas existe uma versão de avaliação gratuita com um limite de 10 quadros?).
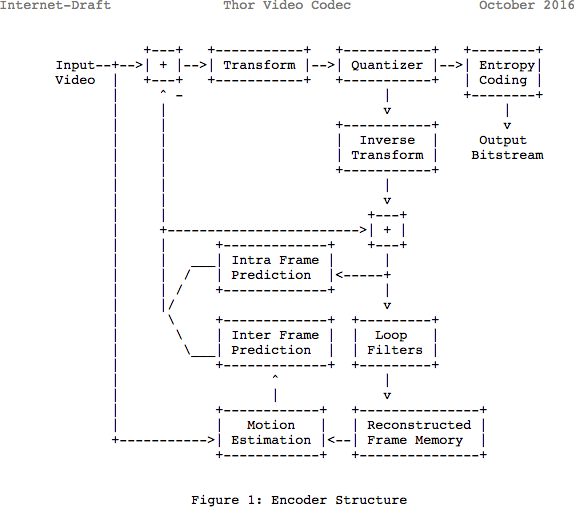
Revisão
Observe que muitos codecs modernos usam o mesmo modelo que acabaram de aprender. Aqui, vamos dar uma olhada no diagrama de blocos do codec de vídeo
Thor . Ele contém todas as etapas que tomamos. O objetivo deste post é que você entenda pelo menos melhor as inovações e a documentação nessa área.
Anteriormente, estimava-se que 139 GB de espaço em disco seriam necessários para armazenar um arquivo de vídeo com duração de uma hora com qualidade 720p e 30 fps. Se você usar os métodos discutidos neste artigo (previsões internas e entre quadros, conversão, quantização, codificação de entropia etc.), poderá conseguir (assumindo que gastamos 0,031 bits por pixel), o vídeo é de qualidade bastante satisfatória, o que ocupa apenas 367,82 MB, não 139 GB de memória.
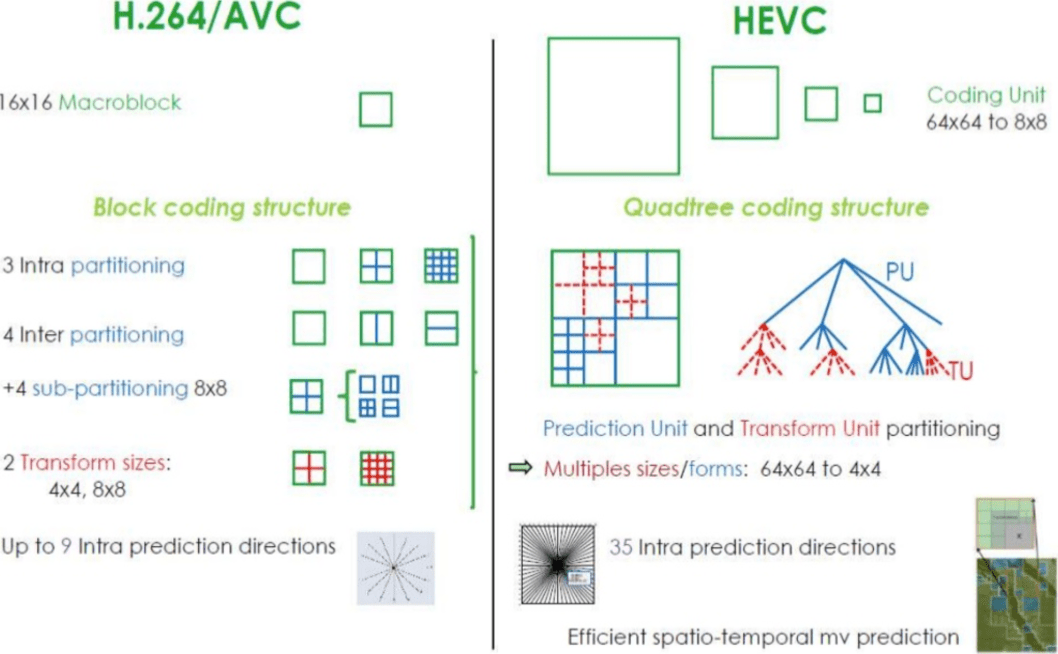
Como o H.265 alcança uma taxa de compressão melhor que o H.264?
Agora que você sabe mais sobre como os codecs funcionam, é mais fácil entender como os novos codecs podem fornecer uma resolução mais alta com menos bits.
Ao comparar o
AVC e o
HEVC , você não deve esquecer que quase sempre é uma opção entre uma carga de CPU mais alta e uma taxa de compactação.
O HEVC tem mais opções para seções (e subseções) que o
AVC , mais instruções para previsão interna, codificação de entropia aprimorada e muito mais. Todas essas melhorias tornaram o
H.265 capaz de compactar 50% mais que o
H.264 .

Leia também o blog
Empresa EDISON:
20 bibliotecas para
aplicação iOS espetacular