Último ano letivo, abril. Cada vez mais os alunos começam a pensar que seria necessário fazer uma tese. Fazer isso é, no sentido, descobrir como preparar rapidamente algo que estará pelo menos em sintonia com o tópico que, ao que parece, foi aprovado pelo supervisor. E, sim, você precisa de pelo menos 80 páginas, também deve obedecer a todos os tipos de GOSTs ... É claro, você não tem tempo para digitar tanto texto conectado (e eles podem até entrar na essência do trabalho, bom!). Obviamente - você precisa realizar o trabalho final que já foi defendido, um trabalho de qualidade, testado e aprovado. A situação é familiar para todos nós. A única questão que permanece em aberto é como garantir que o trabalho seja testado para empréstimo ... As pesquisas na Internet e a comunicação com colegas infelizes levam o aluno às seguintes opções para resolver o problema:
Escreva o trabalho você mesmo;- Reformular o texto (caro e difícil);
- Enganar o sistema com "soluções técnicas".

Vamos ver o que são as rodadas técnicas, como as capturamos e por que o uso delas não é uma boa ideia ...
A reformulação pode ajudar a transmitir o texto de outra pessoa como o seu, se for bem-sucedido. No entanto, a reformulação de alta qualidade em si é um processo muito trabalhoso para o qual o aluno provavelmente não tem tempo e dinheiro. Métodos simples de parafraseando (por exemplo, sinonímia) darão um resultado que não só será detectado pelo sistema antiplágio, mas também, muito provavelmente, divertirá o supervisor e o comitê de certificação.
Assim, chegamos aos meios mais criativos e populares entre os alunos - soluções técnicas - transformações de documentos que, sem alterar a exibição do documento original, alteram o texto extraído pelo sistema de verificação .
Do ponto de vista do trabalho com rodadas técnicas (daqui em diante as chamaremos de "rodadas"), o sistema antiplagiarismo tem duas tarefas:
- Detecção de potenciais desvios e notificação do usuário sobre eles;
- Limpando o texto verificado dos rastreamentos.
O esquema geral das rodadas de processamento pode ser descrito da seguinte maneira:
- Detecção de desvios, salvando informações sobre eles;
- Limpando o texto extraído dos rastreamentos;
- A definição de "suspeita" do documento com base nos desvios;
- Exibir informações sobre suspeitas para o usuário, exibição de desvios encontrados.
É assim que parece na prática.
Documento no formato docx:
Verificando um documento sem a funcionalidade de detecção de rastreamento:
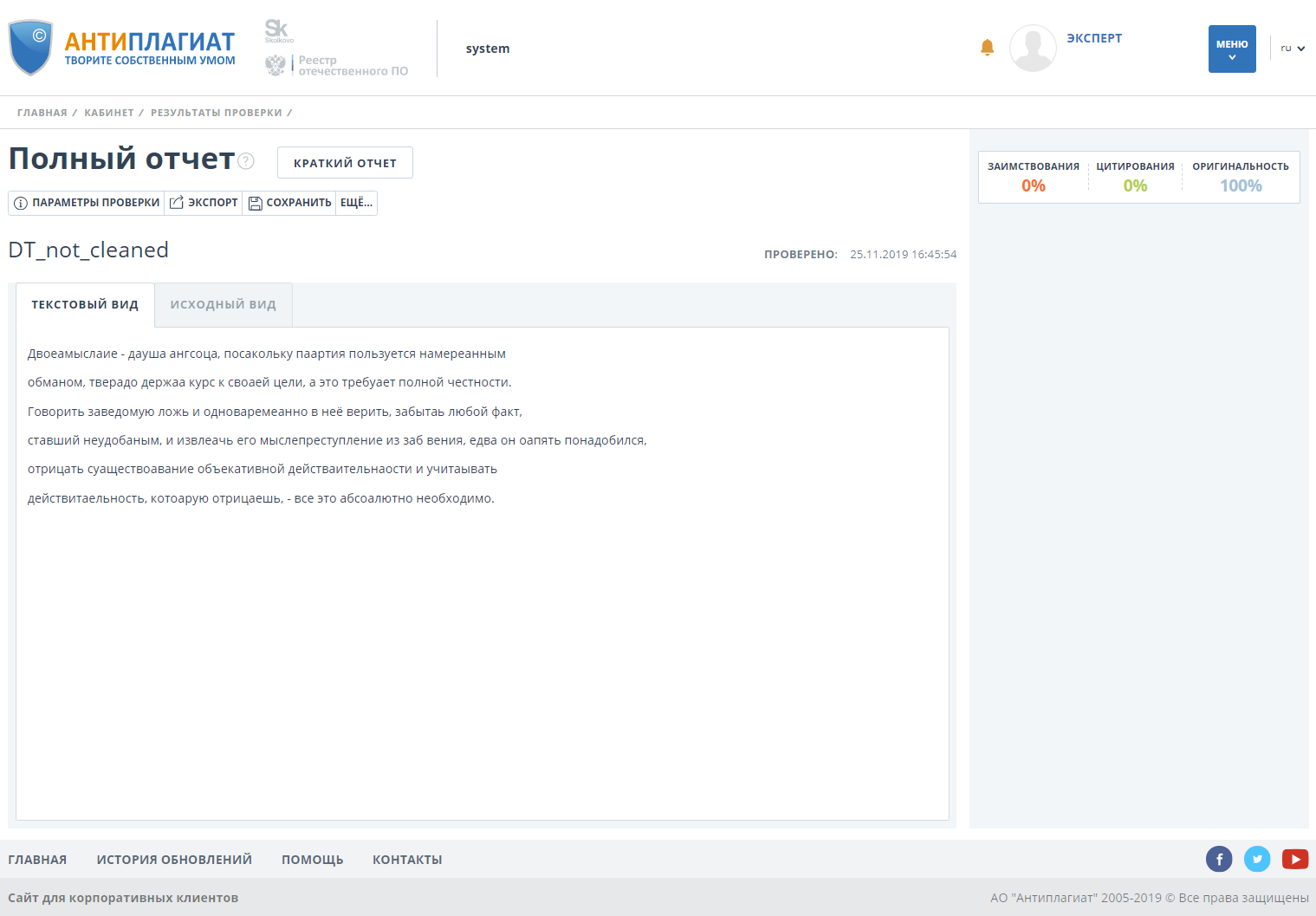
O documento tem cem por cento de originalidade.
Verificamos o documento com a funcionalidade de detecção de desvio ativada e vemos que a originalidade cai para 0.

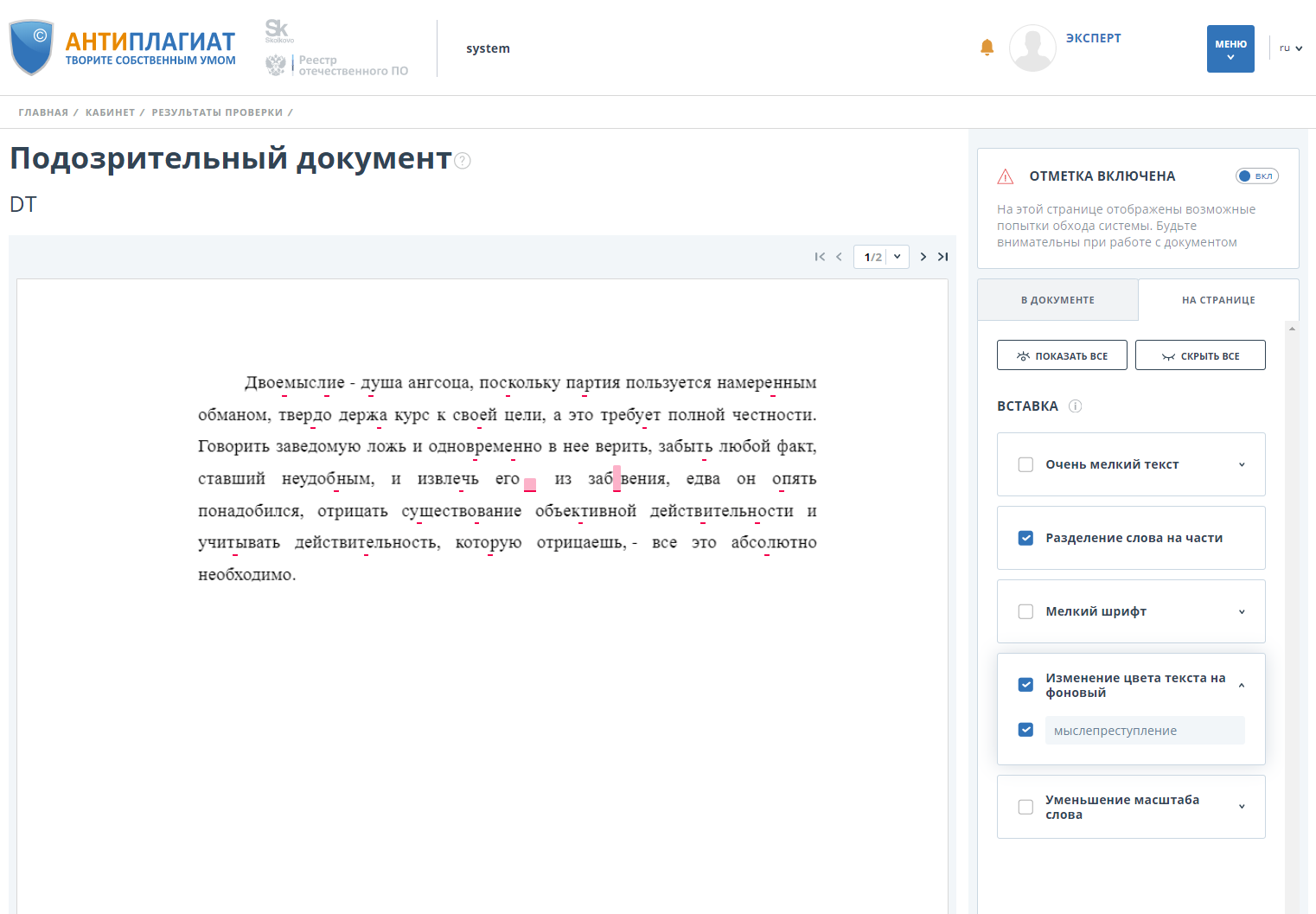
Além disso, o sistema marca o documento como "Suspeito" e mostra ao usuário onde e quais desvios foram detectados:
Como o objetivo das soluções técnicas é aumentar a originalidade de um documento, é interessante classificá-las de acordo com como elas afetam a verificação do documento. Com base no fato de que o principal elemento de verificação de um documento para empréstimo é as palavras do documento, as soluções alternativas podem ser divididas nos seguintes tipos de acordo com o efeito nas palavras extraídas do documento:
- Mude a palavra (a palavra no texto extraído difere da palavra exibida no documento de origem);
- Adicionando uma palavra (a palavra não é visível no documento de origem, aparece no texto extraído do documento);
- Exclusão de uma palavra (a palavra é visível no documento de origem, não no texto extraído do documento)
- Quebra de palavras (no documento original, a palavra é exibida normalmente, no texto curado é dividida em duas ou mais partes);
- Mesclando palavras (várias palavras são exibidas no documento de origem, elas são mescladas em uma palavra no texto extraído).
Vamos ver quais soluções alternativas estamos enfrentando. Vamos começar pelos mais simples e avançar para os mais interessantes.
Rastreamentos de texto
Desvios deste tipo não estão de forma alguma vinculados ao formato do documento; eles alteram o valor da sequência das palavras para que continuem parecendo idênticas às palavras originais.
Omoglifos
Uma das primeiras soluções alternativas que gravamos foi a substituição de letras por omoglifos - caracteres visualmente semelhantes às letras originais e com significados diferentes. A omoglyphia tem sido usada desde os primeiros dias da existência do sistema anti-plágio e, apesar de ter sido capturado por nós por um longo tempo, ainda encontramos desvios semelhantes no trabalho dos alunos.
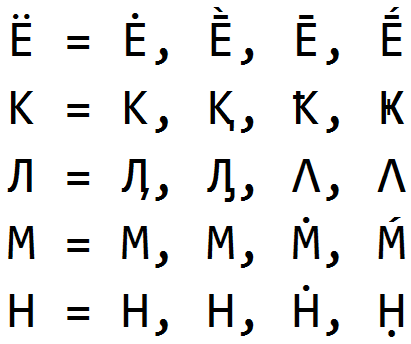
Omóglifos são fáceis de encontrar e limpar quando o idioma de cada palavra é conhecido. Podemos determinar com precisão o idioma de cada palavra do texto, mesmo quando o texto contiver vários idiomas e uma grande quantidade de "lixo" (homóglifos e outros caracteres extras). Como é um tópico para um artigo separado. Tendo a palavra idioma e uma lista de possíveis homóglifos para o idioma, restauramos as letras do idioma original e salvamos informações sobre os homóglifos encontrados.
Caracteres não imprimíveis
Outra maneira de alterar o valor da sequência de palavras sem alterar significativamente sua exibição é usar caracteres Unicode invisíveis ou pouco visíveis. A inserção desses caracteres em uma palavra altera o significado da string da palavra, enquanto praticamente não altera sua exibição.
Muitos desses caracteres estão nas categorias Unicode de "Outro, Controle" e "Marcar, Não Espaçamento" .
O sistema simplesmente exclui esses caracteres e, quando há um grande número deles, notifica o usuário da suspeita do documento, exibindo caracteres não imprimíveis limpos no relatório.
Soluções alternativas em PDF
Como dissemos anteriormente , o formato principal para o processamento de documentos é o pdf. Convertemos todos os outros tipos de documentos em pdf, para que a lógica básica do processamento de documentos seja unificada para todos os formatos suportados. Assim, as soluções alternativas que podem ser implementadas em documentos PDF são de particular interesse para nós.
Texto pequeno
Uma solução alternativa que um dos primeiros vem à mente é tornar algo pequeno e invisível. O texto assim obtido não é visível ao visualizar o documento original, mas é recuperado pelo sistema. A implementação é muito simples - defina o tamanho mínimo da fonte para o texto, altere a cor do texto. Capturar desvios desse tipo é igualmente simples - basta verificar o tamanho da fonte do texto e as dimensões geométricas de palavras individuais. Devido ao seu tamanho pequeno, os alunos geralmente adicionam parágrafos inteiros desse texto oculto à página:

Exibição de uma tentativa de rastreamento detectada:

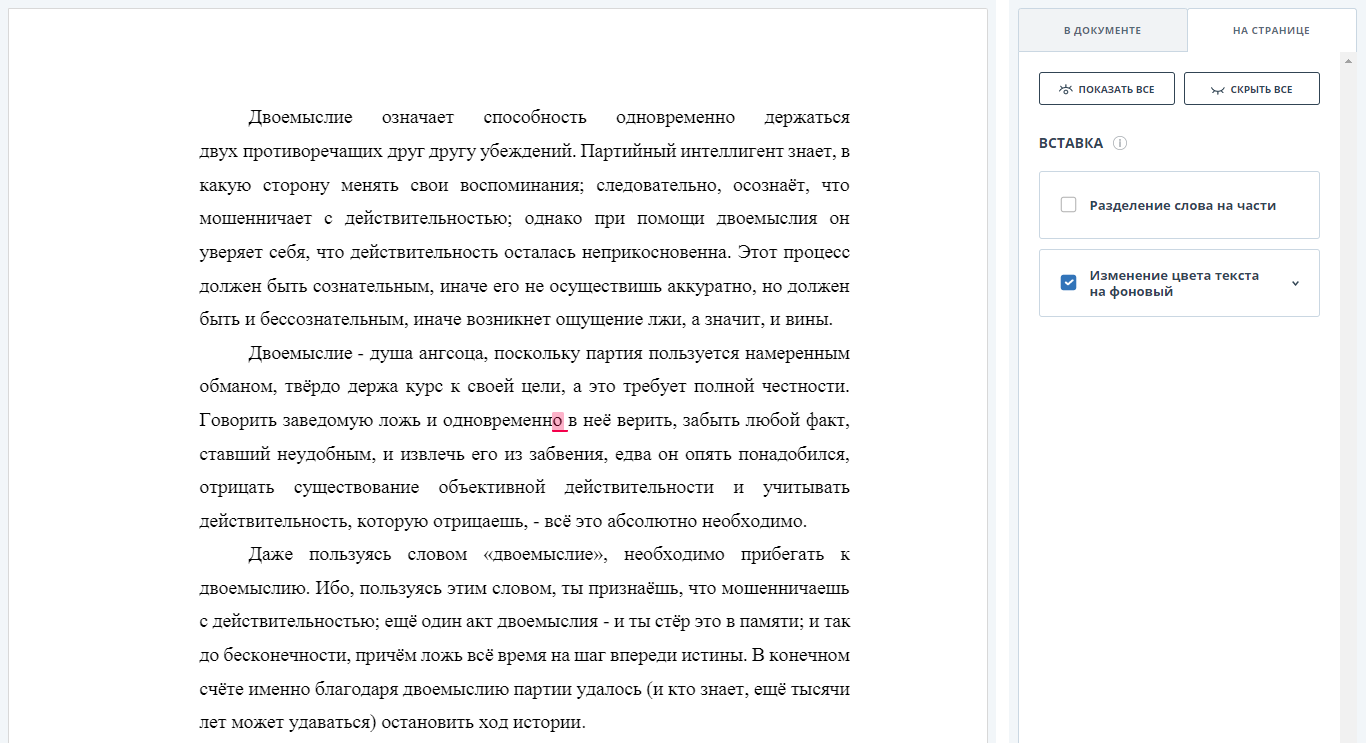
Alterar a cor do texto para segundo plano
Apesar de esse método ser frequentemente usado em combinação com o anterior, seu uso independente é mais interessante. O fato é que, para detectar e limpar o desvio, basta determinar que pelo menos um parâmetro da palavra / símbolo tenha um valor "suspeito". E, se a definição de tamanhos pequenos de uma palavra é trivial, a definição de texto cuja cor corresponde ao plano de fundo é um procedimento mais complicado.
A detecção de um texto invisível é complicada pelas seguintes circunstâncias:
- Nem sempre é possível obter a cor de um caractere específico em pdf;
- O fundo da palavra pode não ser branco. Além disso, a palavra pode estar no fundo da imagem;
- Palavras e símbolos podem se encontrar.
Para eliminar as duas primeiras dificuldades, a “invisibilidade” do texto é determinada analisando a imagem renderizada da página do documento:
- Determine a área da página que contém a palavra;
- Calculamos a variância da região obtida. Se a variação estiver abaixo de um determinado limite - na área analisada, temos uma cor uniforme, nenhuma letra é visível. Portanto, há uma tentativa de ignorar o sistema.
Palavras e símbolos escondidos um após o outro
Caracteres invisíveis não podem ser detectados analisando a área em que estão localizados se esses caracteres estiverem ocultos atrás de outros caracteres "visíveis". Portanto, para detectar esses caracteres "ocultos", temos um procedimento separado que analisa a interseção das áreas de símbolos e marca os caracteres que são amplamente sobrepostos por outros.

Desvio detectado:
Texto como imagens
O que acontecerá se capturarmos e substituirmos parte do texto por imagens que contenham esse texto? Com precisão adequada, tudo parecerá que nada mudou no documento, mas quando você extrai uma camada de texto, naturalmente, as palavras das imagens não serão extraídas. Para fechar essa lacuna, usamos o reconhecimento óptico de texto.
Soluções alternativas usando os recursos de conversão de docx para pdf
Converter documentos em pdf não é uma tarefa trivial. Você pode ler sobre como escolhemos a solução mais adequada para nós aqui . Infelizmente, mesmo a melhor das opções que analisamos converte imperfeitamente documentos em pdf. Alguns "recursos" de conversão são usados ativamente ao tentar ignorar o sistema.
Fórmulas
Fórmulas e vários outros objetos que contêm texto são "perdidos" após a conversão em pdf. Assim, você pode tentar ocultar o parágrafo inteiro do texto ou, por exemplo, cada segunda palavra no texto:

Ao converter para pdf, obtemos o seguinte resultado:

Para detectar e limpar esta e outras soluções alternativas, aprimoradas pelos recursos de conversão de docx para pdf, analisamos e limpamos o arquivo docx de origem. Em particular, se um número significativo de fórmulas for encontrado em um documento, as substituiremos por texto sem formatação, que será salvo quando o documento for convertido em pdf. Além disso, lembramos as posições das fórmulas que processamos e, se necessário, informamos o usuário sobre a suspeita de que o documento está sendo verificado e destacamos o texto que restauramos das fórmulas.
Escala, espaçamento entre símbolos / linhas pequeno
Ao converter para pdf, várias propriedades do texto não são levadas em consideração: escala, inter-símbolo e espaçamento entre linhas. Isso permite adicionar texto que é invisível no documento de origem (por exemplo, possui uma escala muito pequena), que em pdf se torna um texto normal que não se destaca. Ignorar a implementação (docx):

O resultado da conversão para pdf (nós mesmos mudamos a cor):

A única maneira de capturar esse texto é encontrá-lo no docx e salvar informações sobre ele. Se encontrarmos muitos desses textos no documento, marcamos o documento como suspeito e mostramos ao usuário onde encontramos texto com atributos suspeitos no documento.
Quebrando uma palavra em pedaços
Um caso especial interessante de aplicar as propriedades descritas no parágrafo anterior é adicionar um espaço à palavra e ocultá-la. No documento original, a palavra parecerá normal, mesclada e, depois de converter o documento em pdf, ela será dividida em duas partes, à medida que o espaço ficar em tamanho normal. Percebemos uma simulação semelhante com nossos ouvidos da mesma maneira que no parágrafo anterior. Ignorar a implementação (docx):

O resultado da conversão para pdf:

Exibição de um desvio de desvio:

Sob o velho castanheiro, à luz do dia, eu te traiu, e você eu ...
Falamos sobre o básico, mas de maneira alguma todas as formas técnicas de implementar soluções alternativas. Obviamente, dificilmente poderemos tornar a defesa absoluta. No entanto, estamos constantemente aprimorando nosso sistema, deixando cada vez menos oportunidades para "enganá-lo". Na sessão, tentamos fechar brechas detectáveis especialmente rapidamente - geralmente a partir do momento em que uma lacuna é descoberta até ser fechada no produto, apenas alguns dias se passam. É por isso que é um pouco engraçado e, ao mesmo tempo, triste ler as "promessas" publicitárias de empresas prontas para ajudar os alunos a aumentar a originalidade de seu trabalho e dar uma garantia por seu trabalho, às vezes chegando a 30 dias. Estudante, você será traído! Na melhor das hipóteses, essa "garantia" pode devolver o custo dos serviços da empresa de rastreadores, mas não ajudará de maneira alguma com um diploma com falha e uma expulsão potencial da universidade ...
Crie com sua própria mente!