Nós usamos serviços em nuvem há muito tempo: correio, armazenamento, redes sociais, mensagens instantâneas. Todos eles funcionam remotamente - enviamos mensagens e arquivos e são armazenados e processados em servidores remotos. Os jogos na nuvem também funcionam: o usuário se conecta ao serviço, seleciona o jogo e inicia. Isso é conveniente para o jogador, porque os jogos são iniciados quase instantaneamente, não ocupam memória e não precisam de um computador poderoso para jogos.

Para um serviço em nuvem, tudo é diferente - ele tem problemas de armazenamento de dados. Cada jogo pode pesar dezenas ou centenas de gigabytes, por exemplo, "The Witcher 3" leva 50 GB e "Call of Duty: Black Ops III" - 113. Ao mesmo tempo, os jogadores não usam o serviço com 2-3 jogos, pelo menos várias dezenas são necessárias . Além de armazenar centenas de jogos, o serviço precisa decidir quanto armazenamento alocar por jogador e escalar quando houver milhares deles.
Tudo isso deve ser armazenado em seus servidores: quantos eles precisam, onde colocar os data centers, como "sincronizar" dados entre vários data centers em tempo real? Compre "nuvens"? Use máquinas virtuais? É possível armazenar dados do usuário com compressão 5 vezes e fornecê-los em tempo real? Como excluir qualquer influência de usuários um sobre o outro durante o uso consistente da mesma máquina virtual?
Todas essas tarefas foram resolvidas com sucesso no Playkey.net - uma plataforma de jogos baseada em nuvem.
Vladimir Ryabov (
Graymansama ) - chefe do departamento de administração de sistemas - falará em detalhes sobre a tecnologia ZFS para o FreeBSD, que ajudou nisso, e seu novo fork do ZOL (ZFS no Linux).
Mil servidores da empresa estão localizados em data centers remotos em Moscou, Londres e Frankfurt. Existem mais de 250 jogos no serviço, disputados por 100 mil jogadores por mês.
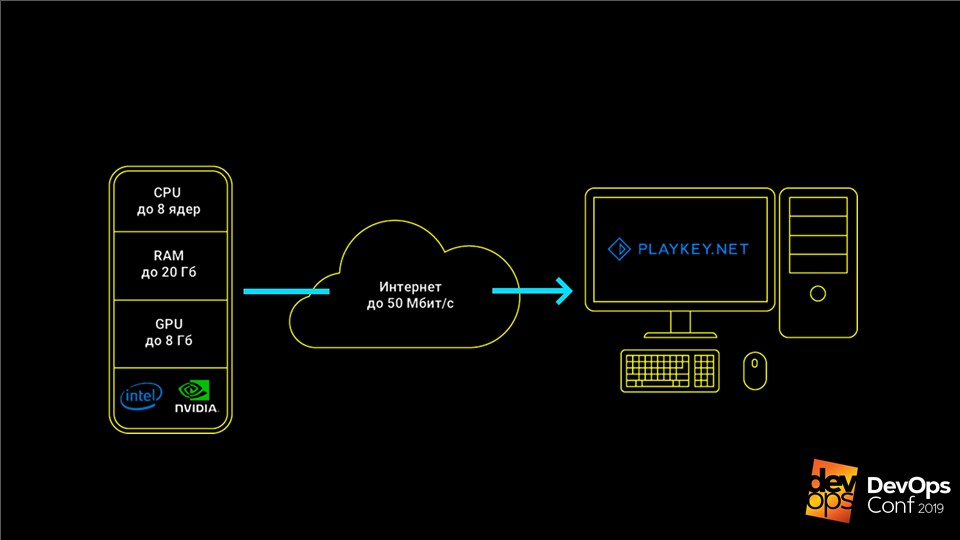
O serviço funciona assim: o jogo é executado nos servidores da empresa, o usuário recebe um fluxo de controles do teclado, mouse ou gamepad e um fluxo de vídeo é enviado em resposta. Isso permite que você jogue jogos modernos de ponta em computadores com hardware fraco, laptops com vídeo integrado ou em Macs para os quais esses jogos não são lançados.
Os jogos devem ser armazenados e atualizados
Os principais dados do serviço de jogos em nuvem são as distribuições de jogos, que podem exceder centenas de GB, e a economia do usuário.
Quando éramos pequenos, tínhamos apenas uma dúzia de servidores e um modesto catálogo de 50 jogos. Armazenamos todos os dados localmente nos servidores, atualizados manualmente, tudo estava bem. Mas chegou a hora de crescer e partimos
para as nuvens da AWS .
Com a AWS, temos várias centenas de servidores, mas a arquitetura não mudou. Eles também eram servidores, mas agora virtuais, com discos locais nos quais as distribuições de jogos estavam. No entanto, a atualização manual em cem servidores falhará.
Começamos a procurar uma solução. Inicialmente, tentamos atualizar via
rsync . Mas aconteceu que isso é extremamente lento e a carga no nó principal é demais. Mas isso nem é o pior: quando tínhamos pouco online, desligamos algumas das máquinas virtuais para não pagar por elas e, ao atualizar, os dados não foram derramados nos servidores desligados. Todos eles foram deixados sem atualizações.
A solução foi torrents - o programa
BTSync . Ele permite sincronizar uma pasta em um grande número de nós sem especificar explicitamente um nó central.
Problemas de crescimento
Por um tempo, tudo isso funcionou maravilhosamente. Mas o serviço estava em desenvolvimento, havia mais jogos e servidores. O número de depósitos locais também aumentou, tivemos que pagar cada vez mais. Nas nuvens, é caro, especialmente para SSDs. A certa altura, até a indexação usual de uma pasta para iniciar sua sincronização começou a demorar mais de uma hora, e todos os servidores podiam ser atualizados por vários dias.
O BTSync criou outro problema com tráfego de rede excessivo. Naquela época, na Amazon, era pago mesmo entre virtuais internos. Se o iniciador de jogos clássico fizer pequenas alterações em arquivos grandes, o BTSync imediatamente acreditará que o arquivo inteiro foi alterado e começará a transferi-lo totalmente para todos os nós. Como resultado, mesmo uma atualização de 15 MB pode gerar dezenas de GB de tráfego de sincronização.
A situação tornou-se crítica quando o armazenamento aumentou para 1 TB. Acabou de lançar um novo jogo World of Warships. Sua distribuição tinha várias centenas de milhares de arquivos pequenos. O BTSync não conseguiu digeri-lo e distribuí-lo a todos os outros servidores - isso atrasou a distribuição de outros jogos.
Todos esses fatores criaram dois problemas:
- produzir armazenamento local é caro, inconveniente e difícil de atualizar;
- as nuvens eram muito caras.
Decidimos voltar ao conceito de nossos servidores físicos.
Sistema de armazenamento próprio
Antes de passar para servidores físicos, precisamos nos livrar do armazenamento local. Isso requer seu próprio
sistema de armazenamento - armazenamento . Este é um sistema que armazena todas as distribuições e as distribui centralmente para todos os servidores.
Parece que a tarefa é simples - já foi resolvida repetidamente. Mas com jogos existem nuances. Por exemplo, a maioria dos jogos simplesmente se recusa a trabalhar se tiver acesso somente leitura. Mesmo com a inicialização normal usual, eles gostam de escrever algo em seus arquivos e, sem isso, se recusam a trabalhar. Pelo contrário, se um grande número de usuários tiver acesso a um conjunto de distribuições, eles começarão a superar os arquivos uns dos outros com acesso competitivo.
Pensamos no problema, verificamos várias soluções possíveis e chegamos ao
ZFS - Zettabyte File System no FreeBSD .
ZFS no FreeBSD
Este não é um sistema de arquivos comum. Os sistemas clássicos são instalados inicialmente em um dispositivo e para trabalhar com vários discos já exigem um gerenciador de volume.
O ZFS foi originalmente construído em pools virtuais.
Eles são chamados
zpool e consistem em grupos de discos ou matrizes RAID. O volume inteiro desses discos está disponível para qualquer sistema de arquivos no zpool. Isso ocorre porque o ZFS foi desenvolvido originalmente como um sistema que funcionará com grandes quantidades de dados.
Como o ZFS ajudou a resolver nossos problemas
Este sistema possui um
mecanismo maravilhoso
para criar snapshots e clones . Eles são criados
instantaneamente e pesam apenas alguns KB. Quando fazemos alterações em um dos clones, aumenta o volume dessas alterações. Ao mesmo tempo, os dados nos clones restantes não são alterados e permanecem únicos. Isso permite que você distribua um disco de
10 TB com acesso exclusivo ao usuário final, gastando apenas alguns KB.
Se os clones crescerem no processo de fazer alterações em uma sessão de jogo, eles não ocuparão tanto espaço quanto todos os jogos? Não, descobrimos que, mesmo em sessões bastante longas, o conjunto de alterações raramente excede 100-200 MB - isso não é crítico. Portanto, podemos dar acesso total a um disco rígido de alta capacidade para várias centenas de usuários ao mesmo tempo, gastando apenas 10 TB com uma cauda.
Como o ZFS funciona
A descrição parece complicada, mas o ZFS funciona de maneira bastante simples. Vamos analisar seu trabalho com um exemplo simples - criar
zpool data partir dos discos
zpool create data /dev/da /dev/db /dev/dc disponíveis,
zpool create data /dev/da /dev/db /dev/dc .
Nota Isso não é necessário para a produção, porque se pelo menos um disco morrer, todo o pool ficará esquecido. Melhor usar grupos RAID.Nós criamos o
zfs create data/games file system, e nele um dispositivo de bloco com o nome
data/games/disk de 10 TB. O dispositivo está disponível em
/dev/zvol/data/games/disk como um disco normal - você pode executar as mesmas manipulações.
Então a diversão começa. Damos esse disco via
iSCSI ao nosso assistente de atualização - uma máquina virtual comum executando o Windows. Conectamos o disco e colocamos os jogos nele simplesmente no Steam, como em um computador doméstico comum.
Encha o disco com jogos. Agora resta distribuir esses dados para
200 servidores para usuários finais.
- Crie um instantâneo deste disco e chame-o de primeira versão -
zfs snapshot data/games/disk@ver1 . Crie seu clone zfs clone data/games/disk@ver1 data/games/disk-vm1 , que irá para a primeira máquina virtual. - Damos o clone via iSCSI e o KVM lança uma máquina virtual com este disco . Carrega, entra em um conjunto de servidores acessíveis para os usuários e espera um jogador.
- Quando a sessão do usuário é concluída, pegamos todos os salvamentos de usuários dessa máquina virtual e os colocamos em um servidor separado . Desligamos a máquina virtual e destruímos o clone - o
zfs destroy data/games/disk-vm1 . - Retornamos ao primeiro passo, crie novamente um clone e inicie a máquina virtual.
Isso nos permite fornecer a cada próximo usuário uma
máquina sempre limpa , na qual não há alterações em relação ao player anterior. O disco após cada sessão do usuário é excluído e o espaço que ele ocupava no sistema de armazenamento é liberado. Também realizamos operações semelhantes com o disco do sistema e com todas as nossas máquinas virtuais.
Recentemente, me deparei com um vídeo no YouTube, onde um usuário satisfeito durante uma sessão de jogo formatou nossos discos rígidos em servidores e fiquei muito feliz por ele ter quebrado tudo. Sim, por favor, apenas para pagar - ele pode jogar e entrar. De qualquer forma, o próximo usuário sempre terá uma máquina virtual limpa e funcional, independentemente do que o anterior fizer.
De acordo com esse esquema, os jogos são distribuídos para apenas 200 servidores. Calculamos o número 200 experimentalmente: este é o número de servidores nos quais não ocorrem cargas críticas nas unidades de armazenamento. Isso ocorre porque os
jogos têm um perfil de carga bastante específico : eles lêem muito no estágio de lançamento ou no nível de carregamento e, durante o jogo, pelo contrário, praticamente não usam um disco. Se o seu perfil de carga for diferente, a figura será diferente.
No esquema antigo, para serviços simultâneos a 200 usuários, precisaríamos de 2.000 TB de armazenamento local. Agora podemos gastar um pouco mais de 10 TB no conjunto de dados principal e ainda existem 0,5 TB em estoque para alterações do usuário. Embora o ZFS adore quando possui pelo menos 15% de espaço livre em seu pool, parece-me que economizamos significativamente.
E se tivermos vários data centers?
Esse mecanismo funcionará apenas dentro de um data center, onde os servidores com um sistema de armazenamento são conectados por pelo menos 10 interfaces de gigabit. O que fazer se houver vários CDs? Como atualizar o disco principal com jogos (conjunto de dados) entre eles?
Para isso, o ZFS possui sua própria solução -
o mecanismo de envio / recebimento . O comando de execução é muito simples:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/disk
O mecanismo permite transferir de um sistema de armazenamento para outro um instantâneo do sistema principal. Pela primeira vez, você precisará enviar todos os 10 terabytes de dados gravados no nó mestre para um sistema de armazenamento vazio. Porém, com as próximas atualizações, enviaremos apenas alterações a partir do momento em que criamos o instantâneo anterior.
Como resultado, obtemos:
- Todas as alterações são feitas centralmente em um sistema de armazenamento . Em seguida, eles se dispersam para todos os outros data centers em qualquer quantidade, e os dados em todos os nós são sempre idênticos.
- O mecanismo de envio / recebimento não tem medo de uma desconexão . Os dados não são aplicados ao conjunto de dados principal até que sejam completamente transmitidos ao nó escravo. Se a conexão for perdida, é impossível danificar os dados e basta repetir o procedimento de envio.
- Qualquer nó pode facilmente se tornar um nó mestre durante um acidente em apenas alguns minutos, pois os dados em todos os nós são sempre idênticos.
Desduplicação e backups
O ZFS possui outro recurso útil - a
desduplicação . Esta função ajuda a
não armazenar dois blocos de dados idênticos . Em vez disso, apenas o primeiro bloco é armazenado e, no lugar do segundo, um link para o primeiro é armazenado. Dois arquivos idênticos ocupam espaço como um e, se corresponderem a 90%, preencherão 110% do volume original.
A função nos ajudou muito no armazenamento de salvamentos do usuário. Em um jogo, usuários diferentes têm salvamentos semelhantes, muitos arquivos são iguais. Com o uso da desduplicação, podemos armazenar cinco vezes mais dados. Nossa taxa de deduplicação é de 5,22. Fisicamente, temos 4,43 terabytes, multiplicamos por um fator e obtemos quase 23 terabytes de dados reais. Isso economiza espaço, evitando armazenamento duplicado.
Instantâneos são bons para backups . Usamos essa tecnologia em nossos armazenamentos de arquivos. Por exemplo, se você salvar uma imagem todos os dias durante um mês, poderá implantar um clone a qualquer momento em qualquer dia desse mês e retirar arquivos perdidos ou danificados. Isso elimina a necessidade de reverter todo o armazenamento ou implantar uma cópia completa dele.
Usamos clones para ajudar nossos desenvolvedores . Por exemplo, eles querem experimentar uma migração potencialmente perigosa em uma base de combate. Não é rápido implantar um backup clássico de um banco de dados com aproximadamente 1 TB. Portanto, simplesmente removemos o clone do disco base e o adicionamos instantaneamente à nova instância. Agora, os desenvolvedores podem testar tudo com segurança.
API do ZFS
Claro, tudo isso deve ser automatizado. Por que subir nos servidores, trabalhar com as mãos, escrever scripts, se isso pode ser dado aos programadores? Portanto, escrevemos nossa
API da Web simples.
Envolvemos todas as funções padrão do ZFS, cortamos o acesso àquelas que são potencialmente perigosas e que podem danificar todo o sistema de armazenamento e entregamos tudo isso aos programadores. Agora
todas as operações de disco são estritamente centralizadas e executadas por código, e
sempre sabemos o status de cada disco . Tudo funciona muito bem.
ZoL - ZFS no Linux
Centralizamos o sistema e pensamos: é tão bom? De fato, agora para qualquer extensão, precisamos comprar imediatamente vários racks de servidor: eles estão vinculados a sistemas de armazenamento e é irracional dividir o sistema. O que fazer quando decidimos implantar um pequeno estande de demonstração para mostrar a tecnologia para parceiros em outros países?
Pensando, chegamos à velha idéia -
usar unidades locais , mas apenas com toda a experiência e conhecimento que recebemos. Se você expandir a ideia de maneira mais global, por que não dar a nossos usuários a oportunidade não apenas de usar nossos servidores, mas também de alugar seus computadores?
A relativamente recente bifurcação do
ZFS no Linux - ZoL nos ajudou muito nisso.
Agora cada servidor tem seu próprio armazenamento.
Somente ele não armazena 10 terabytes de dados, como no caso de uma instalação centralizada, mas apenas 1-2 distribuições dos jogos que ele serve. Um SSD é suficiente para isso. Tudo isso funciona bem: todo usuário seguinte sempre recebe uma máquina virtual limpa, bem como uma instalação de combate.
No entanto, aqui encontramos dois problemas.
Como atualizar?
Atualize centralmente via SSH, como fazemos nos data centers não funcionará . Os usuários podem estar conectados à rede local ou simplesmente desligados, ao contrário dos sistemas de armazenamento, e você não deseja criar tantas conexões SSH.
Encontramos os mesmos problemas que ao usar o rsync. No entanto, os torrents sobre o ZFS não podem mais ser obtidos. Nós pensamos cuidadosamente sobre como o mecanismo de envio funciona: ele envia todos os blocos de dados alterados para o armazenamento final, onde Receive os aplica ao conjunto de dados atual. Por que não gravar os dados em um arquivo, em vez de enviá-los para o usuário final?
O resultado é o que chamamos de
diff . Este é um arquivo no qual todos os blocos alterados entre os dois últimos instantâneos são gravados seqüencialmente. Colocamos esse diff em uma CDN e enviamos a todos os nossos usuários via HTTP: ele ligou a máquina, viu que havia atualizações, esvaziou e aplicou-a ao conjunto de dados local usando Receive.
O que fazer com os motoristas?
Servidores centralizados têm a mesma configuração e os
usuários finais sempre têm computadores e placas de vídeo diferentes . Mesmo se preenchermos a distribuição do sistema operacional com todos os drivers possíveis, tanto quanto possível, na primeira vez em que ele iniciar, ele ainda desejará instalar esses drivers, depois reiniciará e, possivelmente, novamente. Como toda vez que fornecemos um clone limpo, todo esse carrossel ocorre após cada sessão do usuário - isso é ruim.
Queríamos fazer alguma inicialização: espere até o Windows inicializar, instale todos os drivers, faça tudo o que ela deseja e só então opere nesta unidade. Mas o problema é que, se você fizer alterações no conjunto de dados principal, as atualizações serão interrompidas, porque os dados na fonte e no receptor serão diferentes e o diff simplesmente não será aplicado.
No entanto, o ZFS é um sistema flexível e nos permitiu fazer uma pequena muleta.
- Como de costume, crie uma captura instantânea:
zfs snapshot data/games/os@init . - Crie seu clone -
zfs clone data/games/os@init data/games/os-init - e execute-o no modo de inicialização. - Estamos aguardando a instalação de todos os drivers e tudo será reiniciado.
- Desligue a máquina virtual e tire um instantâneo novamente. Mas desta vez, não do conjunto de dados original, mas do clone de inicialização:
zfs snapshot data/games/os-init@ver1 . - Criamos um clone do instantâneo com todos os drivers instalados. Ele não será mais reinicializado:
zfs clone data/games/os-init@ver1 data/games/os-vm1 . - Então trabalhamos no grupo clássico.
Agora este sistema está na fase de teste alfa. Testamos em usuários reais sem o conhecimento do Linux, mas eles conseguem implantá-lo em casa. Nosso objetivo final é que qualquer usuário simplesmente conecte uma unidade flash USB inicializável em seu computador, conecte uma unidade SSD adicional e alugue-a em nossa plataforma em nuvem.
Discutimos apenas uma pequena parte da funcionalidade do ZFS. Esse sistema pode fazer coisas muito mais interessantes e diferentes, mas poucas pessoas sabem sobre o ZFS - os usuários não querem falar sobre isso. Espero que, após este artigo, novos usuários apareçam na comunidade ZFS.
Assine um canal de telegrama ou boletim informativo para aprender sobre novos artigos e vídeos da conferência DevOpsConf . Além do boletim, coletamos notícias das próximas conferências e informamos, por exemplo, o que será interessante para os fãs do DevOps no Saint HighLoad ++ .