Sabe-se que a competência CTO é testada apenas pela segunda vez que esse papel é desempenhado. Porque uma coisa é trabalhar em uma empresa há vários anos, evoluir com ela e, estando no mesmo contexto cultural, gradualmente ganhar mais responsabilidade. E é outra coisa - assumir imediatamente o cargo de diretor técnico em uma empresa com malas herdadas e vários problemas claramente notados sob o tapete.
Nesse sentido, a experiência de Leon Fayer, que ele compartilhou no
DevOpsConf , não é apenas única, mas é multiplicada pela experiência e pelo número de papéis diferentes que ele conseguiu
exercer por mais de 20 anos. Sob o corte, uma cronologia de eventos ao longo de 90 dias e muitas histórias que são boas de rir quando acontecem com outra pessoa, mas que não são tão divertidas de encarar pessoalmente.
Leon é muito colorido em russo, por isso, se você tiver 35 a 40 minutos, recomendo assistir ao vídeo. Versão em texto para economizar tempo abaixo.
A primeira versão do relatório era uma descrição bem estruturada do trabalho com pessoas e processos, contendo recomendações úteis. Mas ela não transmitiu todas as surpresas que surgiram ao longo do caminho. Portanto, mudei o formato e descrevi os problemas que a nova empresa apareceu na minha frente como um inferno de uma caixa de rapé e os métodos para resolvê-los em ordem cronológica.
Um mês antes
Como muitas boas histórias, essa começou com álcool. Sentamos com os amigos no bar e, como deveria estar entre as pessoas de TI, todos choraram por seus problemas. Um deles acabou de mudar de emprego e falou sobre seus problemas com a tecnologia, as pessoas e a equipe. Quanto mais ouvia, mais percebia que ele só precisava me contratar, porque eram exatamente esses problemas que eu vinha resolvendo nos últimos 15 anos. Eu disse isso a ele e no dia seguinte já nos conhecemos em um ambiente de trabalho. A empresa foi chamada de Estratégias de Ensino.
Estratégias de ensino lidera o mercado de programas educacionais para crianças muito pequenas - desde o nascimento até três anos. A empresa tradicional de "papel" já tem 40 anos e a versão SaaS digital da plataforma 10. Recentemente, começou o processo de adaptação da tecnologia digital aos padrões da empresa. A versão "nova" foi lançada em 2017 e era quase como a antiga, mas funcionou pior.
O mais interessante é que o tráfego desta empresa é muito previsível - dia após dia, ano a ano, você pode prever com muita clareza quantas pessoas virão e quando. Por exemplo, entre 13h e 15h, todas as crianças nos jardins de infância vão dormir e os professores começam a inserir informações. E isso acontece todos os dias, exceto nos finais de semana, porque nos fins de semana quase ninguém trabalha.
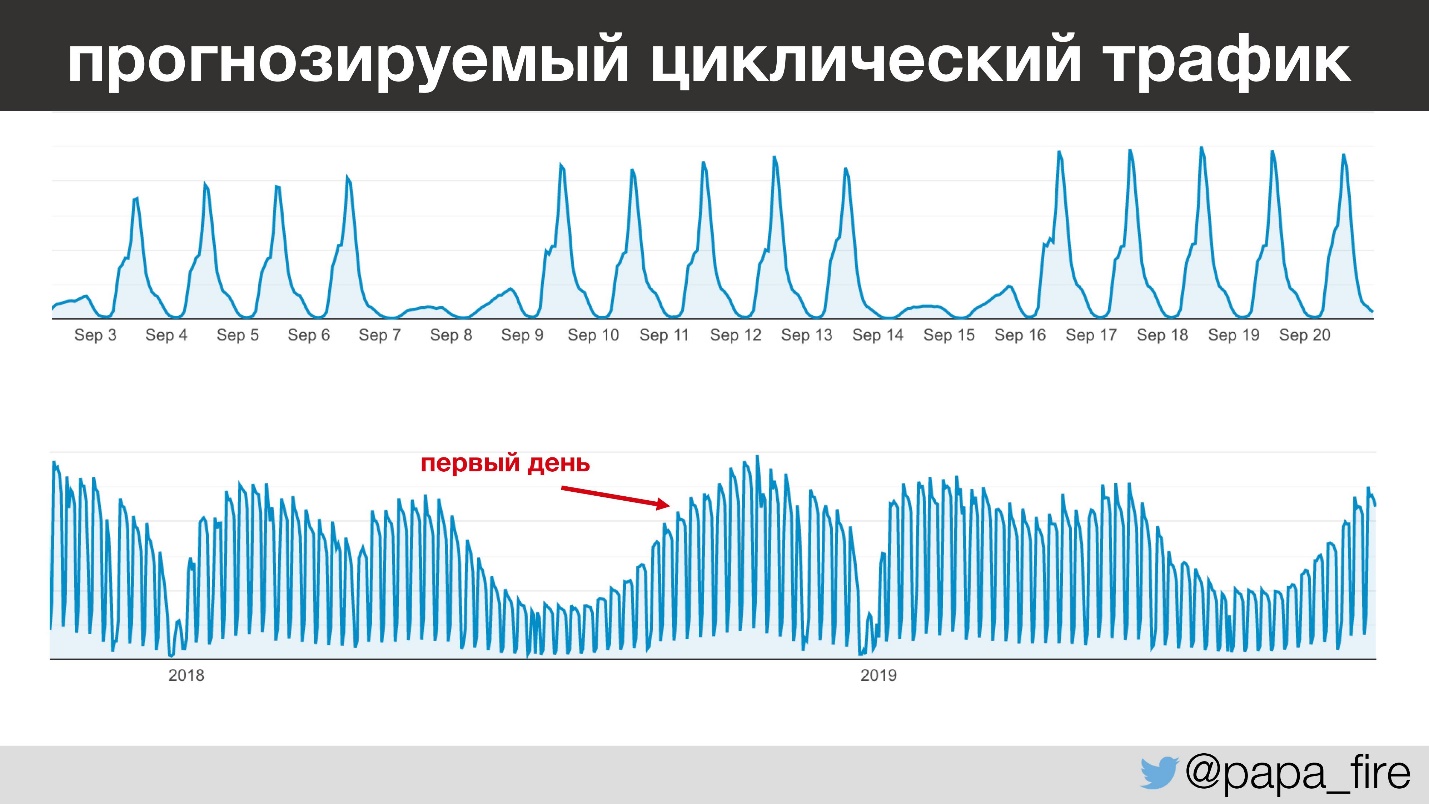
Olhando um pouco à frente, comecei meu trabalho durante o período de maior tráfego anual, o que é interessante por várias razões.
A plataforma, que parecia ter apenas 2 anos de idade, tinha uma pilha peculiar: ColdFusion & SQL Server 2008. O ColdFusion, se você não sabe, mas provavelmente não sabe, é um PHP corporativo que surgiu em meados dos anos 90 e, desde então, eu nem ouvi falar disso. Também havia: Ruby, MySQL, PostgreSQL, Java, Go, Python. Mas o principal monólito funcionou no ColdFusion e no SQL Server.
Os problemas
Quanto mais eu falava com os funcionários da empresa sobre o trabalho e quais problemas eram encontrados, mais percebia que os problemas não são apenas de natureza técnica. Ok, a tecnologia é antiga - e eles não funcionaram nisso, mas houve problemas com a equipe e com os processos, e a empresa começou a entender isso.
Tradicionalmente, os técnicos estavam sentados no canto e fazendo parte de seu trabalho. Mas mais e mais negócios começaram a passar pela versão digital. Portanto, na empresa no último ano antes do início do meu trabalho, surgiram novos: o conselho de administração, CTO, CPO e diretor de QA. Ou seja, a empresa começou a investir no campo tecnológico.
Traços de herança pesada não estavam apenas nos sistemas. A empresa tinha processos legados, pessoas legadas, cultura legada. Tudo isso teve que ser mudado. Eu pensei que definitivamente não seria chato, e decidi tentar.
Dois dias antes
Dois dias antes de iniciar um novo emprego, cheguei ao escritório, preenchi os últimos documentos, familiarizei-me com a equipe e descobri que a equipe estava lutando com o problema naquele momento. Consistia no fato de que o tempo médio de carregamento da página saltou para 4 s, ou seja, 2 vezes.
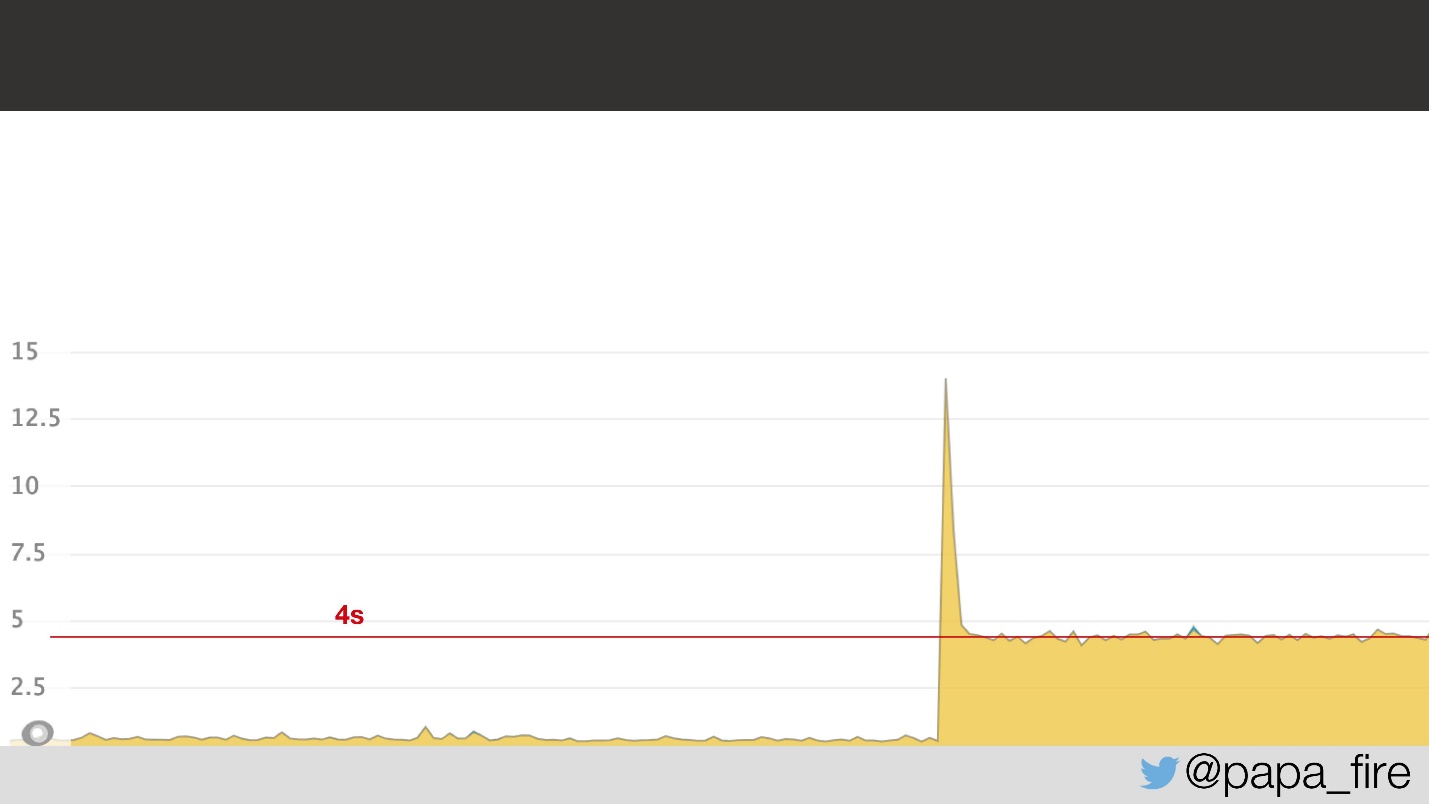
A julgar pelo cronograma, obviamente algo aconteceu, e não está claro o que. Verificou-se que o problema estava na latência da rede no data center: latência de 5 ms no data center foi convertida em 2 s para os usuários. Por que isso aconteceu, eu não sabia, mas, de qualquer forma, ficou claro que o problema está no data center.
Primeiro dia
Dois dias se passaram e, no meu primeiro dia útil, descobri que o problema não desapareceu.
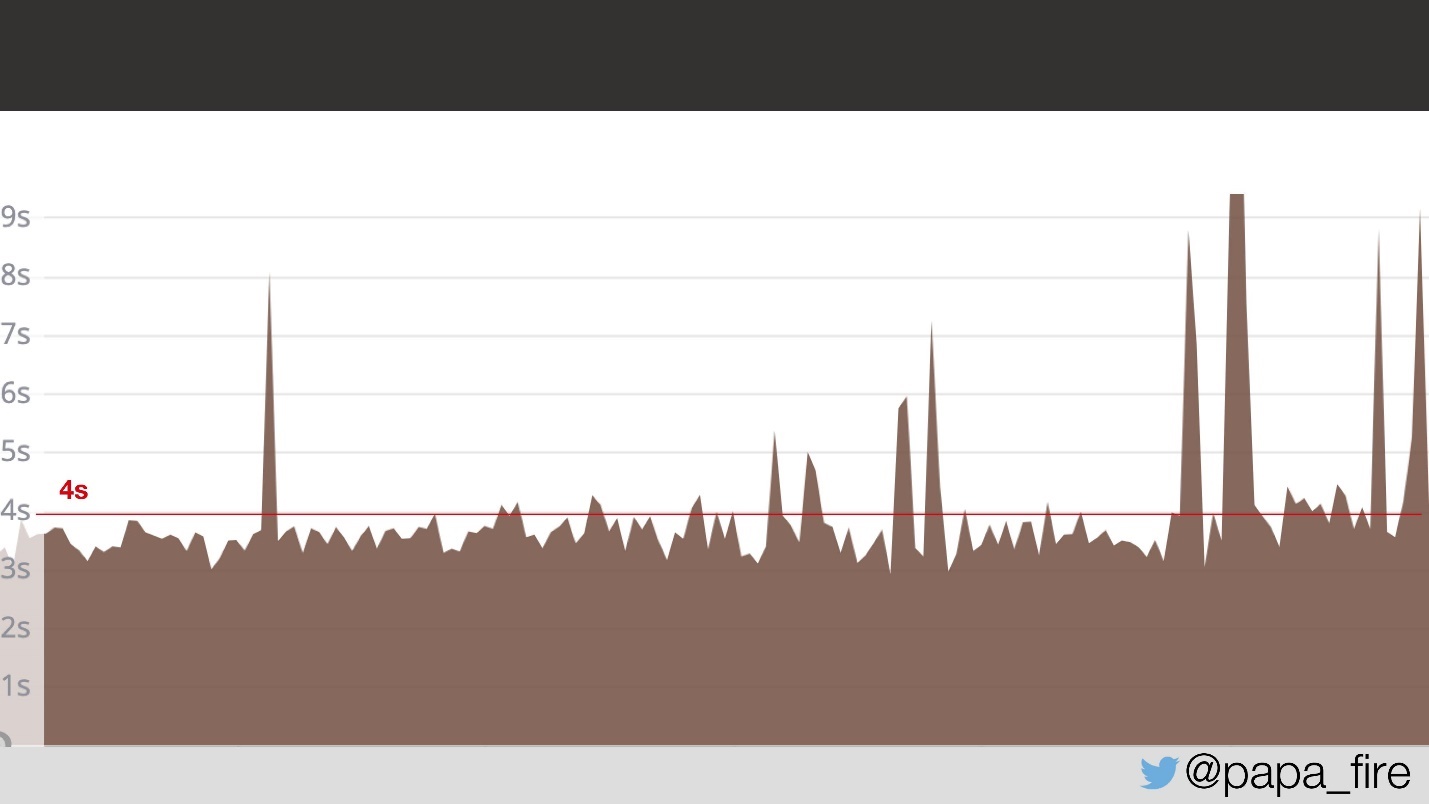
Por dois dias, os usuários da página carregaram em média 4 s. Pergunto se eles descobriram qual é o problema.
- Sim, nós abrimos um ingresso.
- e
"Bem, eles ainda não nos responderam."Então percebi que tudo que me haviam dito antes era apenas a pequena ponta do iceberg com a qual eu tinha que lutar.
Há uma boa citação que é muito adequada para este caso:
"Às vezes você precisa mudar a organização para mudar a tecnologia".
Mas desde que comecei a trabalhar na época mais movimentada do ano, tive que procurar as duas opções para resolver o problema: rápido e a longo prazo. E comece com o que é crítico agora.
Dia três
Portanto, o carregamento leva 4 segundos e de 13 a 15 os maiores picos.
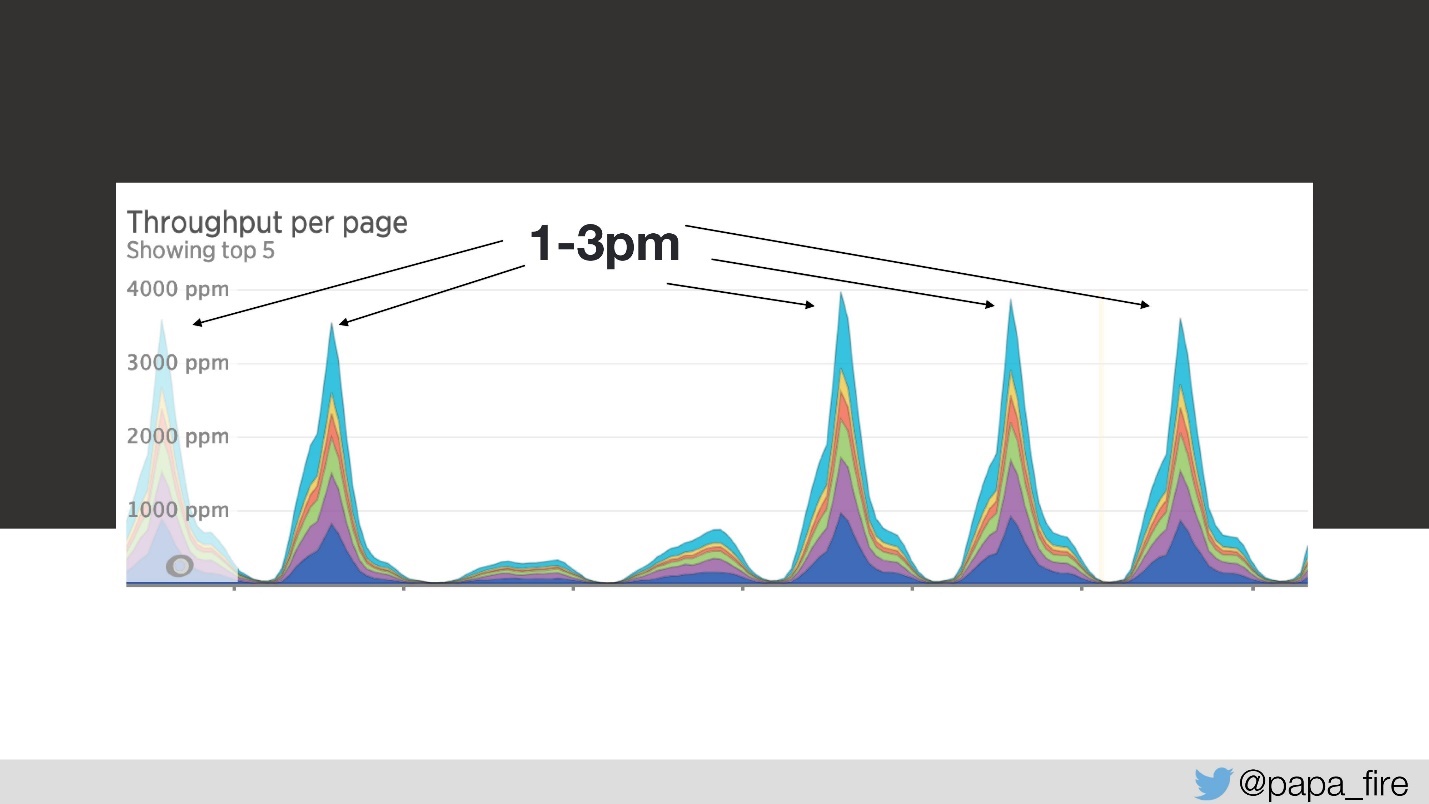
No terceiro dia, nesse intervalo de tempo, a velocidade do download ficou assim:
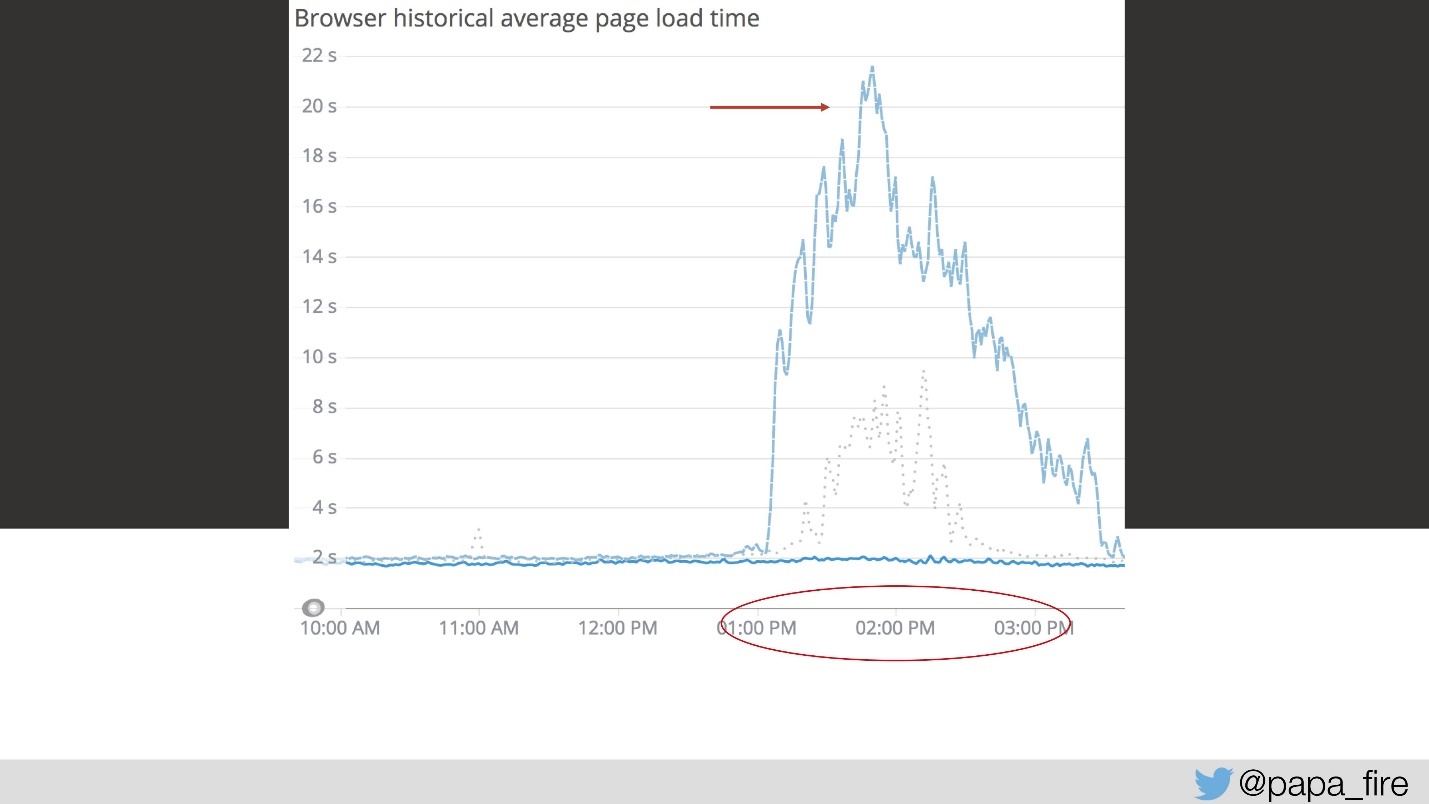
Do meu ponto de vista, nada funcionou. Do ponto de vista de todos os outros, funcionou um pouco mais devagar que o normal. Mas isso simplesmente não acontece assim - esse é um problema sério.
Tentei convencer a equipe, à qual eles responderam que só precisavam de mais servidores. Essa, é claro, é a solução para o problema, mas nem sempre é a única e mais eficaz. Perguntei por que não há servidores suficientes, quanto tráfego. Extrapolei os dados e concluí que temos cerca de 150 solicitações por segundo, o que basicamente se encaixa em limites razoáveis.
Mas não devemos esquecer que, antes de você obter a resposta certa, você precisa fazer a pergunta certa. Minha próxima pergunta foi: quantos servidores front-end temos? A resposta "me intrigou" - tínhamos 17 servidores de front-end!
- Tenho vergonha de perguntar, 150 dividido por 17, será cerca de 8? Você quer dizer que cada servidor ignora 8 solicitações por segundo e, se houver 160 solicitações por segundo amanhã, precisaremos de mais 2 servidores?Obviamente, não precisamos de servidores adicionais. A solução estava no próprio código e na superfície:
var currentClass = classes.getCurrentClass(); return currentClass;
Havia uma função
getCurrentClass() , porque tudo no site funciona no contexto da classe - corretamente. E para essa função em cada página, havia
mais de 200 solicitações .
A solução dessa maneira era muito simples, não havia necessidade de reescrever nada: simplesmente não solicite as mesmas informações novamente.
if ( !isDefined("REQUEST.currentClass") ) { var classes = new api.private.classes.base(); REQUEST.currentClass = classes.getCurrentClass(); } return REQUEST.currentClass;
Fiquei muito feliz porque decidi que apenas no terceiro dia encontrei o principal problema. Como eu era ingênuo, esse era apenas um dos muitos problemas.
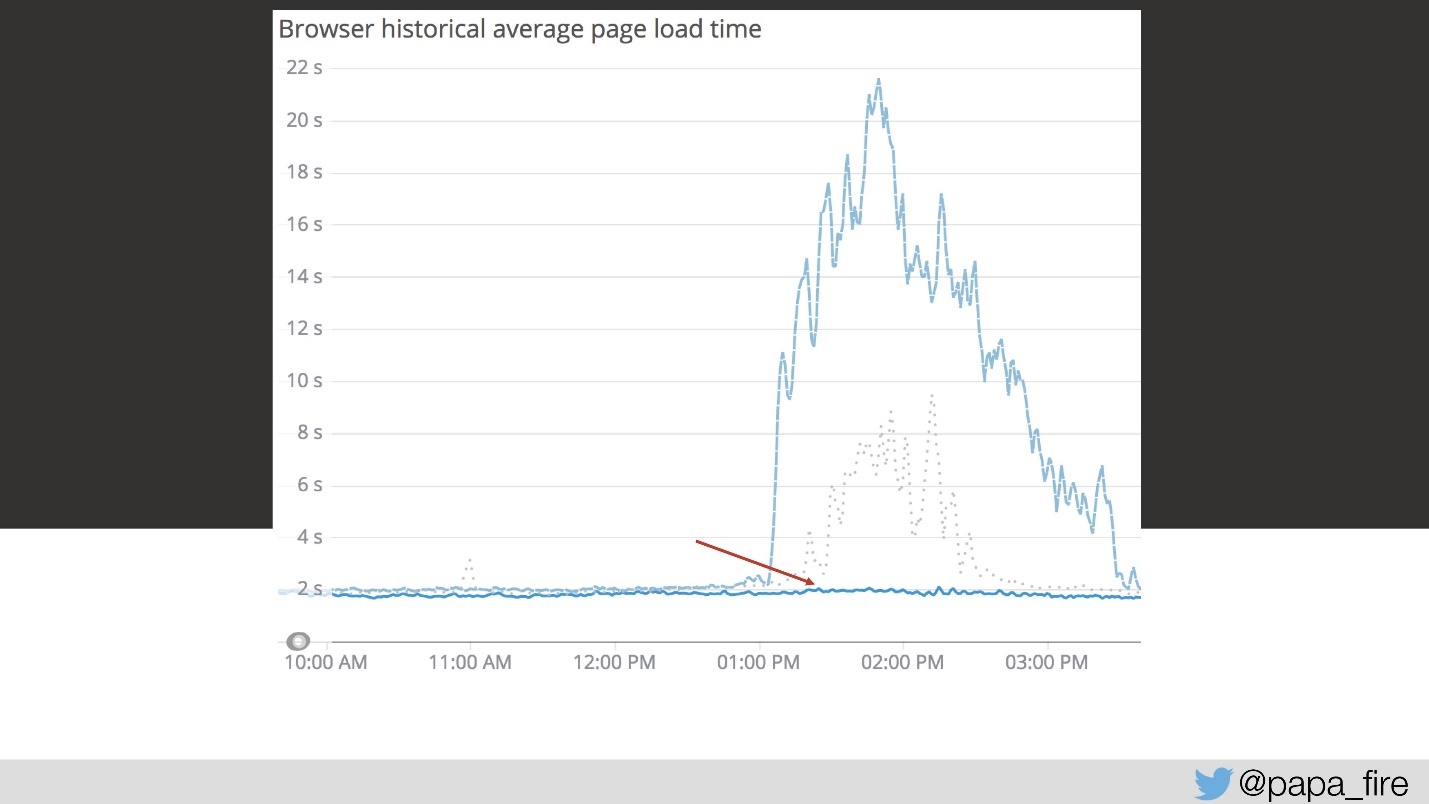
Mas a solução para esse primeiro problema reduziu muito o cronograma.
Ao mesmo tempo, estávamos envolvidos em outras otimizações. À vista havia muito de tudo que pode ser reparado. Por exemplo, no mesmo terceiro dia, descobri que ainda havia um cache no sistema (no começo, pensei que todas as solicitações fossem diretamente do banco de dados). Quando penso em um cache, apresento o Redis ou Memcached padrão. Mas apenas pensei assim, porque para o cache desse sistema foram utilizados o MongoDB e o SQL Server - o mesmo a partir do qual os dados haviam acabado de ser lidos.
Dia dez
Na primeira semana, eu estava lidando com problemas que precisavam ser resolvidos agora. Em algum momento da segunda semana, cheguei ao stand-up para conversar com a equipe, ver o que está acontecendo e como está todo o processo.
Novamente, uma coisa interessante foi descoberta. A equipe era composta por: 18 desenvolvedores; 8 testadores; 3 gerentes; 2 arquitetos. E todos eles participaram de rituais comuns, ou seja, mais de 30 pessoas vieram para o stand-up todas as manhãs e disseram o que estavam fazendo. É claro que a reunião não levou 5 ou 15 minutos. Ninguém ouviu ninguém, porque todo mundo trabalha em sistemas diferentes. Dessa forma, 2-3 bilhetes por hora na sessão de limpeza já eram um bom resultado.
A primeira coisa que fizemos foi dividir a equipe em várias ao longo da linha de produtos. Para diferentes seções e sistemas, identificamos equipes separadas que incluíam desenvolvedores, testadores, gerentes de produto, analistas de negócios.
Como resultado, recebemos:
- Redução de stand-ups e comícios.
- Conhecimento do produto.
- Um senso de propriedade. Quando antes as pessoas costumavam sempre falar sobre sistemas, elas sabiam que alguém provavelmente teria que trabalhar com seus erros, mas não com eles mesmos.
- Colaboração entre grupos. Você não pode dizer que o controle de qualidade não se comunicava muito com os programadores antes, o produto fazia suas próprias coisas etc. Agora eles têm um ponto de responsabilidade comum.
Nosso foco principal é eficiência, produtividade e qualidade - esses são os problemas que tentamos resolver com a transformação da equipe.
Décimo primeiro dia
No processo de mudar a estrutura da equipe, descobri como os
Story Points são contados. 1 SP foi igual a um dia e cada ticket continha SP para desenvolvimento e controle de qualidade, ou seja, pelo menos 2 SP.
Como eu encontrei isso?
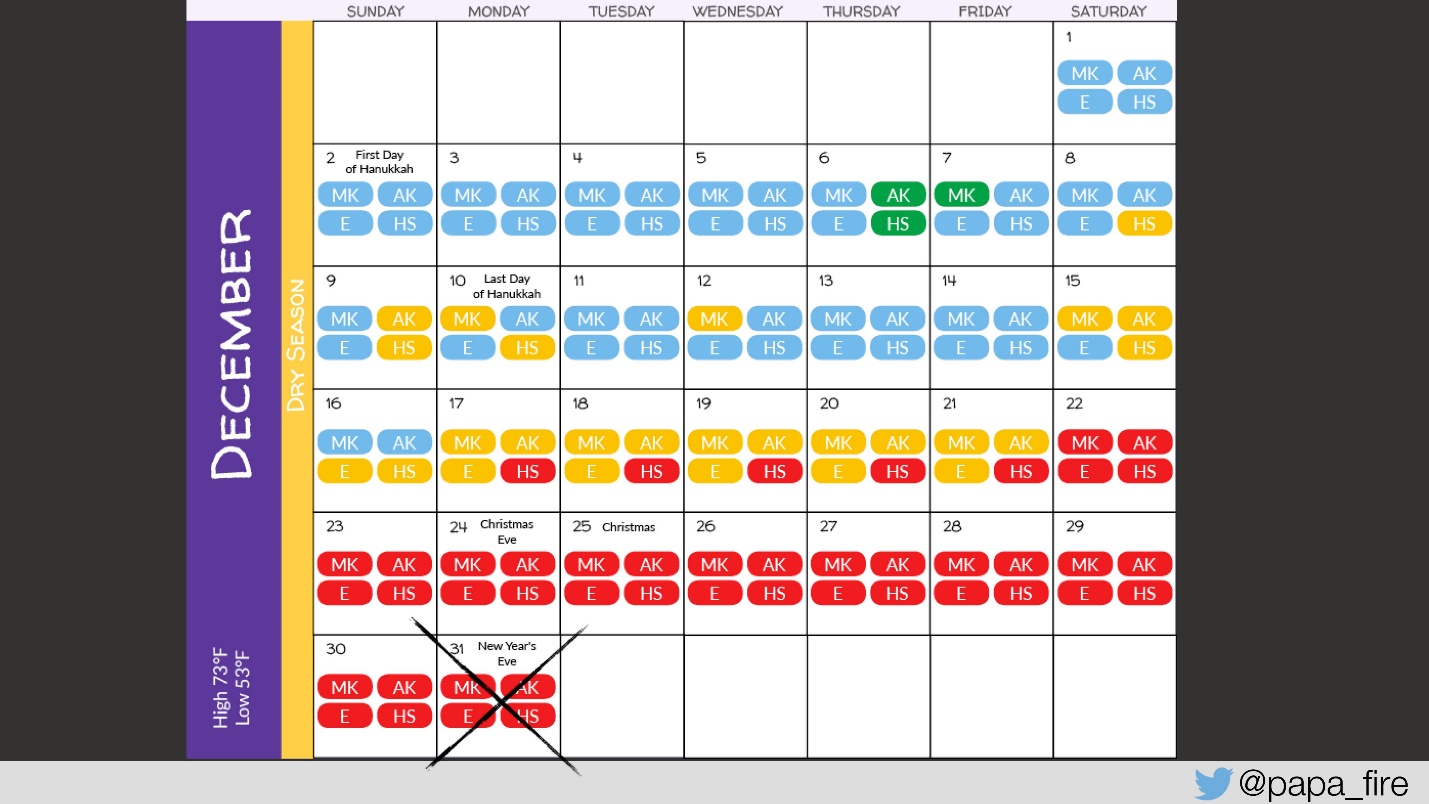
Foi encontrado um erro: em um dos relatórios, onde a data de início e término do período para o qual o relatório é necessário é inserida, o último dia não é levado em consideração. Ou seja, em algum lugar da solicitação não havia <=, mas simplesmente <. Disseram-me que estes são três Story Points, ou seja,
3 dias .
Depois disso nós:
- Revisou o sistema de classificação dos Story Points. Agora, a correção de pequenos bugs que podem ser passados rapidamente pelo sistema chega rapidamente ao usuário.
- Começamos a combinar tickets relacionados para desenvolvimento e teste. Anteriormente, todo ticket, todo bug era um ecossistema fechado, não anexado a mais nada. Alterar três botões em uma página pode ter três tickets diferentes com três processos diferentes de controle de qualidade, em vez de um teste automático em uma página.
- Eles começaram a trabalhar com os desenvolvedores em uma abordagem para avaliar os custos de mão-de-obra. Três dias para trocar um botão não é engraçado.
Vigésimo dia
Em algum lugar no meio do primeiro mês, a situação havia se estabilizado um pouco, eu descobri o que estava acontecendo principalmente e já comecei a olhar para o futuro e pensar em soluções de longo prazo.
Objetivos de longo prazo:
- Plataforma gerenciada Centenas de solicitações em cada página - isso não é sério.
- Tendências previsíveis. Havia picos de tráfego periódicos que, à primeira vista, não se correlacionavam com outras métricas - era necessário entender por que isso acontece e aprender a prever.
- Extensão da plataforma. Os negócios estão em constante crescimento, mais e mais usuários estão chegando, o tráfego está aumentando.
Costumava-se dizer no passado: "Vamos reescrever tudo em [idioma / framework], tudo funcionará melhor!"
Na maioria dos casos, isso não funciona, bem, se o reescrito funcionará. Portanto, precisávamos criar um roteiro - uma estratégia concreta que ilustra passo a passo como os objetivos de negócios serão alcançados (o que faremos e por que), que:
- reflete a missão e os objetivos do projeto;
- prioriza os principais objetivos;
- contém um cronograma para sua conquista.
Antes disso, ninguém havia conversado com a equipe sobre o propósito de qualquer alteração. Isso requer as taxas de sucesso corretas. Pela primeira vez na história da empresa, definimos KPI para um grupo técnico, e esses indicadores estavam atrelados aos organizacionais.
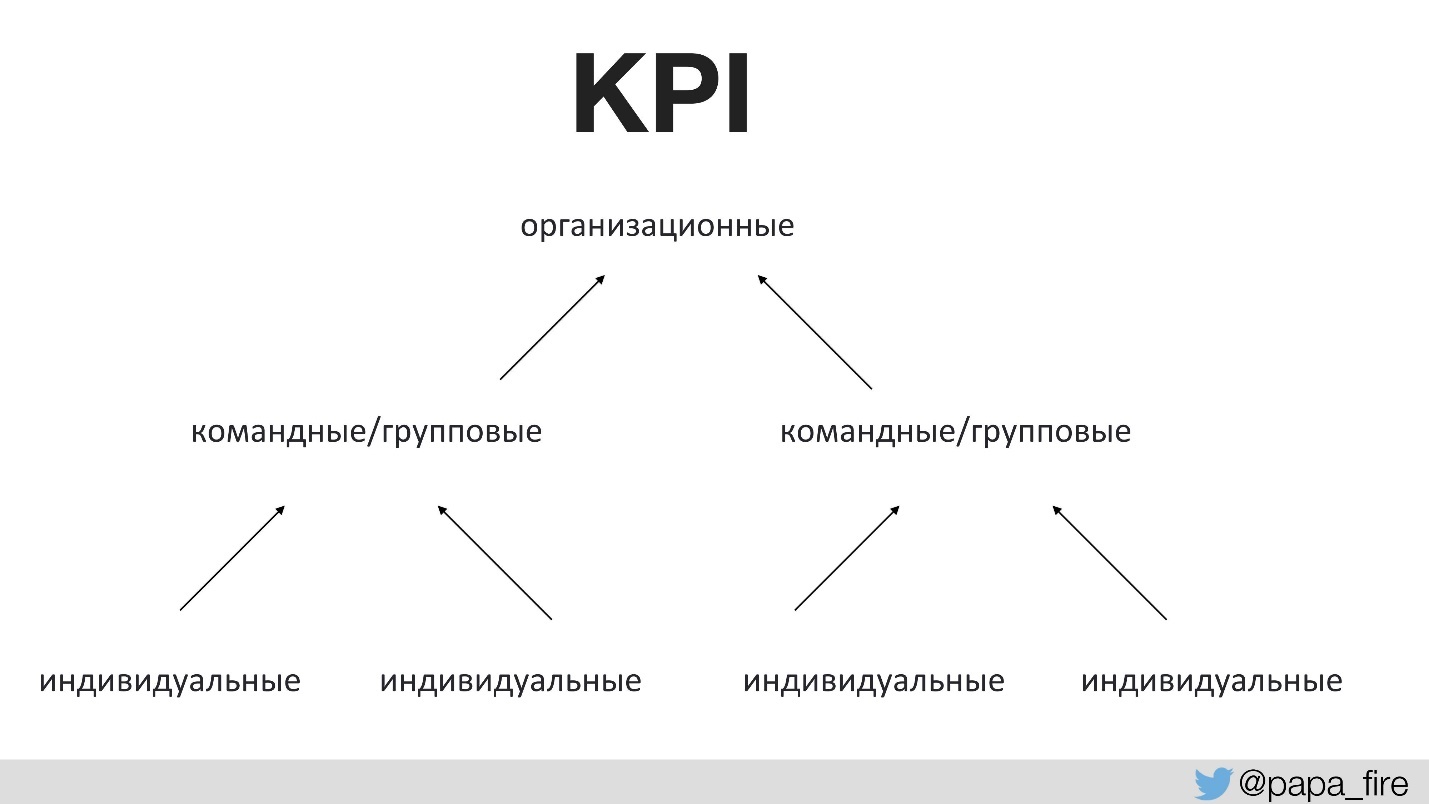
Ou seja, os KPIs organizacionais são suportados por equipes e os KPIs de equipe já são suportados por indivíduos. Caso contrário, se os KPIs tecnológicos não concordarem com os organizacionais, todo mundo puxa o cobertor sobre si mesmo.
Por exemplo, um dos KPIs organizacionais é aumentar a participação de mercado por meio de novos produtos.
Como você pode apoiar o objetivo de ter mais novos produtos?
- Primeiro, queremos gastar mais tempo desenvolvendo novos produtos em vez de corrigir bugs. Essa é uma solução lógica fácil de medir.
- Em segundo lugar, queremos apoiar um aumento no volume de transações, porque quanto maior a participação no mercado, mais usuários e, consequentemente, mais tráfego.
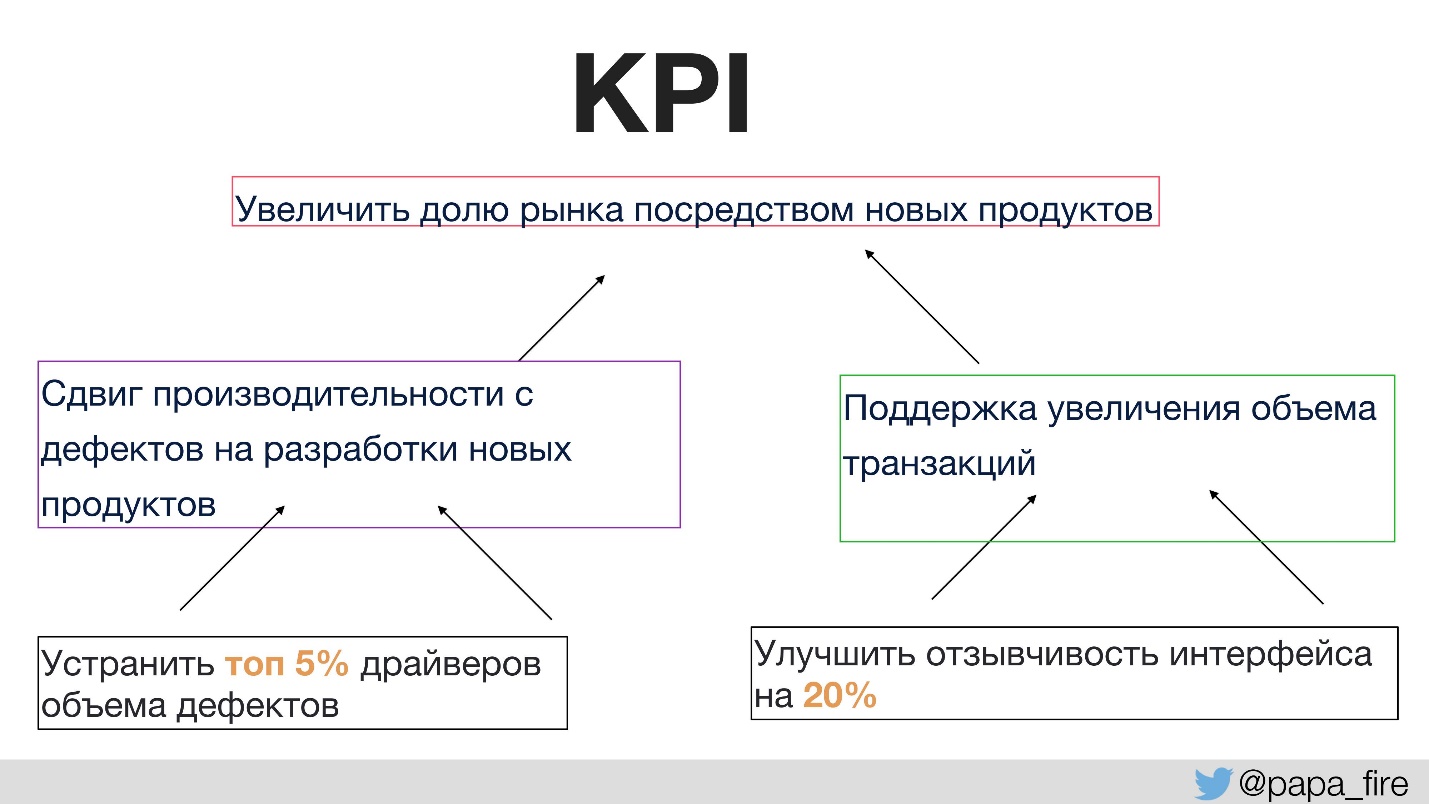
Em seguida, os KPIs individuais que podem ser executados dentro do grupo estarão, por exemplo, no local de origem dos principais defeitos. Se você se concentrar nesta seção em particular, poderá diminuir o número de defeitos e aumentar o tempo para desenvolver novos produtos e, novamente, dar suporte aos KPIs organizacionais.
Assim, cada decisão, incluindo a reescrita do código, deve apoiar os objetivos específicos que a empresa estabeleceu para nós (o crescimento da organização, novas funções, recrutamento).
Durante esse processo, surgiu uma coisa interessante que se tornou notícia não apenas para os técnicos, mas geralmente na empresa: todos os tickets devem se concentrar em pelo menos um KPI. Ou seja, se o produto disser que deseja criar um novo recurso, a primeira pergunta deve ser feita: “Qual KPI esse recurso suporta?” Se não, desculpe-me - parece que esse é um recurso desnecessário.
Trigésimo dia
No final do mês, descobri mais uma nuance de que nenhuma equipe da Ops jamais havia visto os contratos que concluímos com os clientes. Você pode perguntar por que ver os contatos.
- Primeiro, porque os SLAs são registrados em contratos.
- Em segundo lugar, os SLAs são todos diferentes. Cada cliente veio com seus requisitos e o departamento de vendas assinou sem olhar.
Outra nuance interessante é que, no contrato com um dos maiores clientes, está escrito que todas as versões de software suportadas pela plataforma devem ser n-1, ou seja, não a versão mais recente, mas a penúltima.
É claro a que distância estávamos do n-1 se a plataforma estivesse no ColdFusion e no SQL Server 2008, que em julho deixou de ter suporte.
Quadragésimo quinto dia
Em algum lugar no meio do segundo mês, eu tinha tempo livre suficiente para me sentar e fazer um
mapeamento completo do
fluxo de valor durante todo o processo. Essas são as etapas necessárias a serem tomadas, desde a criação do produto até a entrega ao consumidor, e você deve pintá-lo com o máximo de detalhes possível.
Você divide o processo em pedaços pequenos e vê o que leva muito tempo, o que pode ser otimizado, aprimorado etc. Por exemplo, quanto tempo a solicitação do produto leva, passando pela limpeza, quando atinge o ticket que o desenvolvedor pode levar, o controle de qualidade etc. Você analisa cada etapa em detalhes e acha que pode otimizar.
Quando fiz isso, duas coisas chamaram minha atenção:
- alta porcentagem de tickets de retorno do controle de qualidade para desenvolvedores;
- a revisão da solicitação de recebimento demorou muito tempo.
O problema era que essas eram conclusões como: parece levar muito tempo, mas não sabemos ao certo quanto.
"É impossível melhorar o que não pode ser medido."
Como comprovar a gravidade do problema? Passa dias ou horas?
Para medir isso, adicionamos algumas etapas ao processo Jira: "ready for dev" e "ready for QA", para medir quanto tempo cada ticket aguarda e quantas vezes ele retorna a uma determinada etapa.
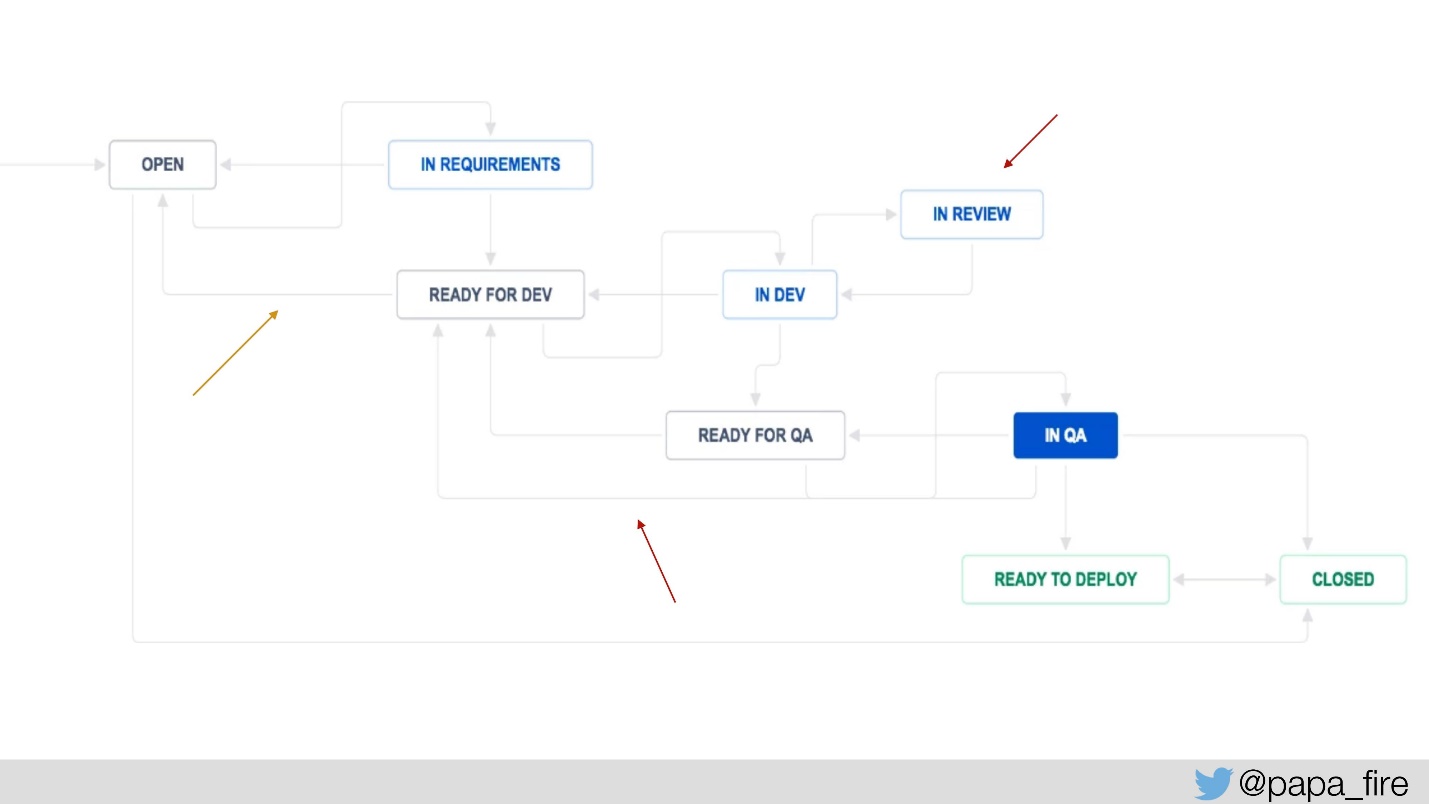
Também adicionamos "em revisão" para saber quantos ingressos estão em revisão, em média, e é por isso que eles já estão dançando. Tínhamos métricas do sistema, agora adicionamos novas métricas e começamos a medir:
- Eficiência do processo: desempenho e planejado / entregue.
- Qualidade do processo: número de defeitos, defeitos de controle de qualidade.
Realmente ajuda a entender o que está indo bem e o que está ruim.
Quinquagésimo dia
Isso é tudo, é claro, bom e interessante, mas no final do segundo mês aconteceu algo que, em princípio, era previsível, embora eu não esperasse tal escala. As pessoas começaram a sair porque o topo mudou. Novas pessoas chegaram à liderança, que começaram a mudar tudo, e as antigas desistiram. E geralmente em uma empresa com vários anos de idade, todos os amigos e todos se conhecem.
Isso era esperado, mas a escala de demissões foi inesperada. Por exemplo, em uma semana, dois líderes de equipe entraram simultaneamente com sua própria demissão. Portanto, não tive que esquecer outros problemas, mas me concentrar na
criação de uma equipe . Esse é um problema longo e difícil, mas ela teve que lidar com isso porque queria salvar as pessoas que permaneceram (ou a maioria delas). Era necessário, de alguma forma, reagir ao fato de as pessoas saírem para manter a moral na equipe.
Em teoria, isso é bom: entra uma nova pessoa com uma carta branca completa que pode avaliar as habilidades da equipe e substituir o pessoal. Na verdade, você não pode simplesmente trazer novas pessoas por muitas razões.
Sempre precisa de um equilíbrio.- Velho e novo. Precisamos manter os idosos que podem mudar e apoiar a missão. Mas, ao mesmo tempo, precisamos trazer sangue novo, falaremos sobre isso um pouco mais tarde.
- Experiência. Conversei muito com bons juniores que queimaram e queriam trabalhar para nós. Mas não pude aceitá-los, porque não havia senhores suficientes para apoiar os juniores e ser mentores para eles. Primeiro foi necessário ganhar o topo e só então a juventude.
- Cenoura e palito.
Não tenho uma boa resposta para a pergunta sobre qual equilíbrio é correto, como mantê-lo, quantas pessoas devem sair e quanto empurrar. Este é um processo puramente individual.
Dia cinquenta primeiro
Comecei a olhar atentamente para a equipe para entender quem eu tenho e mais uma vez lembrei:
"A maioria dos problemas são problemas com as pessoas."
Descobri que na equipe, como tal - os desenvolvedores e as Ops - têm três grandes problemas:
- Satisfação com o estado atual das coisas.
- Falta de responsabilidade - porque ninguém jamais trouxe os resultados do trabalho dos artistas para influenciar os negócios.
- Medo da mudança.

A mudança sempre tira você da sua zona de conforto e, quanto mais jovens, mais eles não gostam de mudar porque não entendem o porquê e não sabem como. A resposta mais comum que ouvi foi: "Nós nunca fizemos isso". E chegou ao ponto de completo absurdo - as menores mudanças não ocorreram sem que alguém se indignasse. E não importa o quanto as mudanças digam respeito ao seu trabalho, as pessoas disseram: "Não, por quê? Não vai funcionar.
Mas você não pode melhorar sem mudar nada.
Tive uma conversa absolutamente absurda com um funcionário, contei minhas idéias para otimização, para as quais ele me disse:
- Ah, você não viu o que tivemos no ano passado!
"Então o que?"
"Agora muito melhor do que era."
"Então não poderia ser melhor?"
Porque?Boa pergunta - por quê? Como se, se é melhor agora do que era, tudo está bom o suficiente. Isso leva a uma falta de responsabilidade, o que é absolutamente normal em princípio. Como eu disse, a equipe técnica estava um pouco distante. A empresa acreditava que deveria, mas
ninguém jamais estabeleceu padrões . Eles nunca viram o SLA no suporte técnico, por isso foi bastante "aceitável" para o grupo (e isso me impressionou mais):
- 12 segundos de download;
- 5 a 10 minutos de inatividade em cada release;
- A solução de problemas críticos leva dias e semanas;
- falta de serviço 24x7 / plantão.
Ninguém nunca tentou perguntar por que não devemos fazê-lo melhor, e ninguém nunca percebeu que não deveria ser.
Como bônus, havia outro problema:
falta de experiência . Os idosos foram embora e a equipe jovem restante cresceu sob o regime anterior e foi envenenada por ele.
Por tudo isso, as pessoas também tinham medo de falhar, de parecer incompetentes. Isso se expressa no fato de que, em primeiro lugar,
sob nenhuma circunstância eles pediram ajuda . Quantas vezes conversamos em grupo e individualmente, e eu disse: "Faça uma pergunta se você não souber fazer alguma coisa". Estou confiante em mim mesmo e sei que posso resolver qualquer problema, mas isso levará tempo. Portanto, se você puder perguntar a alguém que sabe como resolvê-lo em 10 minutos, perguntarei. Quanto menos experiência você tiver, mais você tem medo de perguntar, porque pensa que será considerado incompetente.
Esse medo de fazer uma pergunta se manifesta de formas interessantes. Por exemplo, você pergunta: "Como está indo com esta tarefa?" - "Faltam algumas horas, já estou terminando". No dia seguinte, você perguntar novamente, você obtém a resposta de que está tudo bem, mas houve um problema: ele estará pronto no final do dia. Outro dia passa, e até você pressionar a parede e forçar alguém a falar, tudo continua. Uma pessoa quer resolver o problema, acredita que, se não o resolver, será um grande fracasso.
É por isso que os
desenvolvedores exageraram . Foi essa piada quando eles discutiram uma tarefa específica, eles me deram uma figura que fiquei muito surpreso. Ao que me disseram que, em estimativas, o desenvolvedor inclui o tempo que o ticket retornará do controle de qualidade, porque eles encontrarão erros lá, o tempo que o PR levará e o tempo que as pessoas que precisam visualizá-lo estarão ocupadas - ou seja, tudo isso só é possível.
Em segundo lugar, as pessoas que têm medo de parecer incompetentes
analisam desnecessariamente . Quando você diz o que exatamente precisa ser feito, começa: “Não, mas e se pensarmos aqui?” Nesse sentido, nossa empresa não é única, é um problema comum da juventude.
Em resposta, introduzi as seguintes práticas:
- A regra é 30 minutos. Se em meia hora você não conseguir resolver o problema, peça ajuda a alguém. Isso funciona com sucesso variável, porque as pessoas ainda não perguntam, mas pelo menos o processo já começou.
- Exclua tudo, exceto a essência , ao estimar o termo da tarefa, ou seja, considere apenas quanto tempo leva para escrever o código.
- Educação continuada para quem analisa demais. É apenas um trabalho constante com as pessoas.
Sexagésimo dia
Enquanto eu fazia tudo isso, é hora de descobrir o orçamento. Claro, encontrei muitas coisas interessantes em que gastamos o dinheiro. Por exemplo, tínhamos um rack inteiro em um data center separado, no qual havia um servidor FTP usado por um cliente. Acabou que "... nos mudamos, mas ele permaneceu, não o mudamos". Isso foi há 2 anos.
De particular interesse foi a conta de serviço em nuvem. Estou certo de que o principal motivo da grande fatura de serviços em nuvem são os desenvolvedores que têm acesso ilimitado aos servidores pela primeira vez em suas vidas. Eles não precisam perguntar: "Por favor, me dê um servidor de teste", eles podem usar. Além disso, os desenvolvedores sempre querem construir um sistema tão legal para que o Facebook com Netflix inveje.
Mas os desenvolvedores não têm experiência na compra de servidores e a capacidade de determinar o tamanho certo dos servidores, porque eles não precisavam disso antes. E, geralmente, eles não entendem completamente a diferença entre escalabilidade e desempenho.
Resultados do inventário:
- Saímos de um data center.
- Encerrou o contrato com 3 serviços de log. Porque tínhamos cinco deles - cada desenvolvedor que começou a brincar com algo ganhou um novo.
- Desativou 7 sistemas da AWS. Mais uma vez, ninguém interrompeu os projetos mortos, todos continuaram trabalhando.
- Custos de software reduzidos em 6 vezes.
Setenta quinto dia
O tempo passou e, depois de dois meses e meio, tive que me encontrar com o conselho de administração. Nosso conselho de administração não é melhor nem pior do que outros; ele quer saber tudo como todos os conselhos de administração. As pessoas investem dinheiro e querem entender o quanto o que fazemos se encaixa nos KPIs definidos.
O Conselho de Administração recebe muitas informações todos os meses: o número de usuários, seu crescimento, quais serviços eles usam e como, produtividade e produtividade e, finalmente, a velocidade média de carregamento da página.
O único problema é que acredito que o valor médio é puro mal. Mas o conselho de administração é muito difícil de explicar. Eles estão acostumados a operar com números agregados, e não, por exemplo, pela propagação do tempo de carregamento por segundo.
Nesse sentido, houve pontos interessantes. Por exemplo, eu disse que você precisa dividir o tráfego entre servidores da web individuais, dependendo do tipo de conteúdo.

Ou seja, o ColdFusion passa pelo Jetty e pelo nginx e lança páginas. E imagens, JS e CSS passam por um nginx separado com suas próprias configurações. Essa é uma prática bastante padrão que
escrevi há alguns anos atrás. , … 200 .
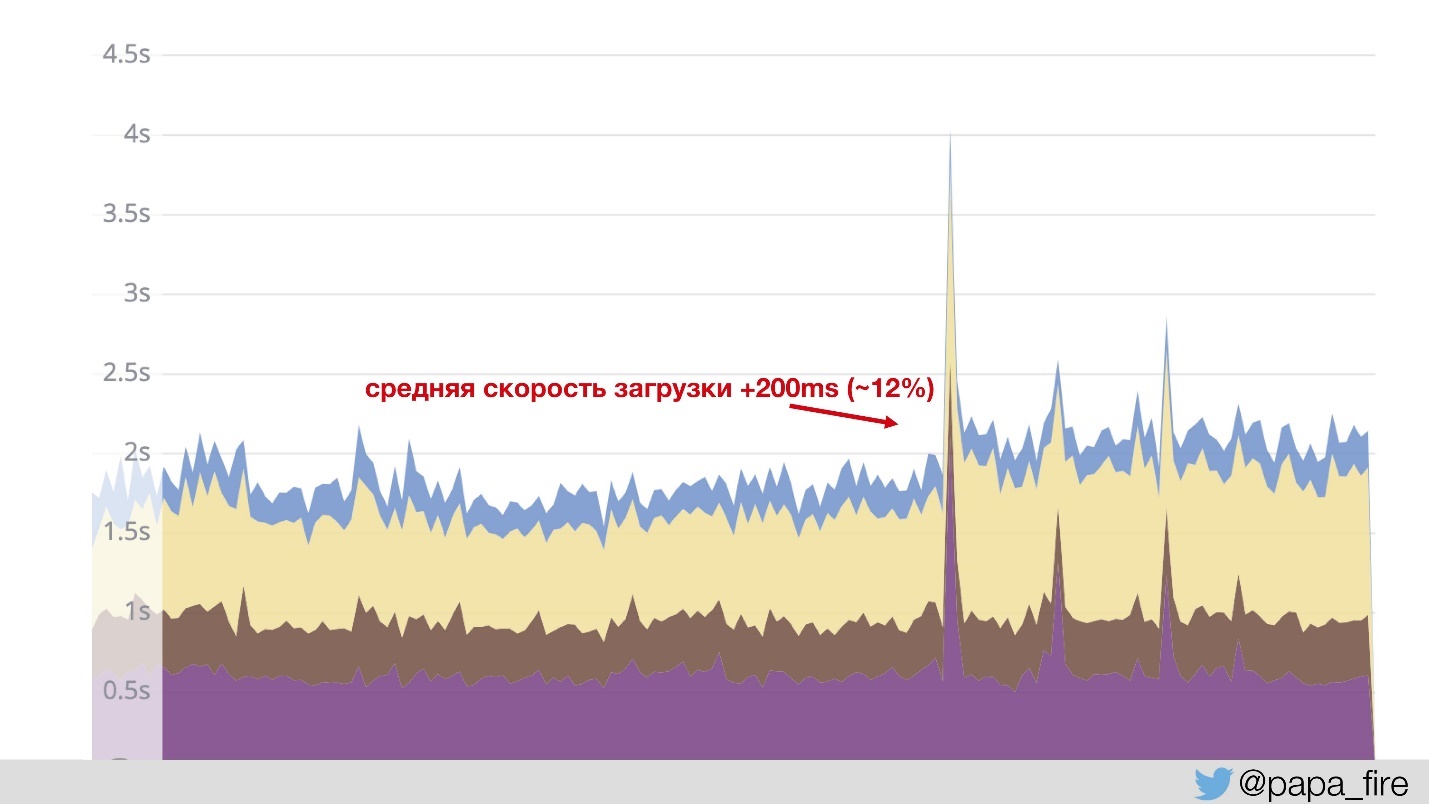
, , Jetty. — . , , , - 12%?
, — . , , .

— , . . - , .
Conclusão
. , , , . , ,
SEQUENCE .
nextID , .
, . , , — .

. , :
.
twitter ,
facebook medium .
legacy : , . c DevOpsConf , . youtube , , DevOps.