
Nós nos tornamos o que vemos. Primeiro modelamos as ferramentas, depois as ferramentas nos modelam.
—Marshal McLuhan
Gostaria de agradecer sinceramente e expressar minha gratidão ao meu bom amigo Ricardo Sueiras pela revisão, contribuição e por não me deixar deixar este artigo inacabado. Ricardo, você é apenas uma lenda!
É importante lembrar que a engenharia do caos não ocorre quando você libera macacos e entra indiscriminadamente em falhas. A engenharia do caos é uma técnica de experimentação formalizada e bem definida.
"A engenharia do caos envolve observação cuidadosa, ceticismo severo sobre o objeto da observação, porque as premissas cognitivas distorcem a interpretação dos resultados. Essa técnica envolve a formulação de hipóteses por indução com base em observações semelhantes; teste experimental e baseado em medidas de conclusões feitas a partir de hipóteses semelhantes; ajuste" ou rejeição de hipóteses com base em resultados experimentais "
—Wikipedia
A engenharia do caos começa com a compreensão do estado estável do sistema com o qual você está lidando, a subsequente formulação da hipótese e, finalmente, o experimento que a confirma, ajudando a aumentar a margem de segurança do sistema.
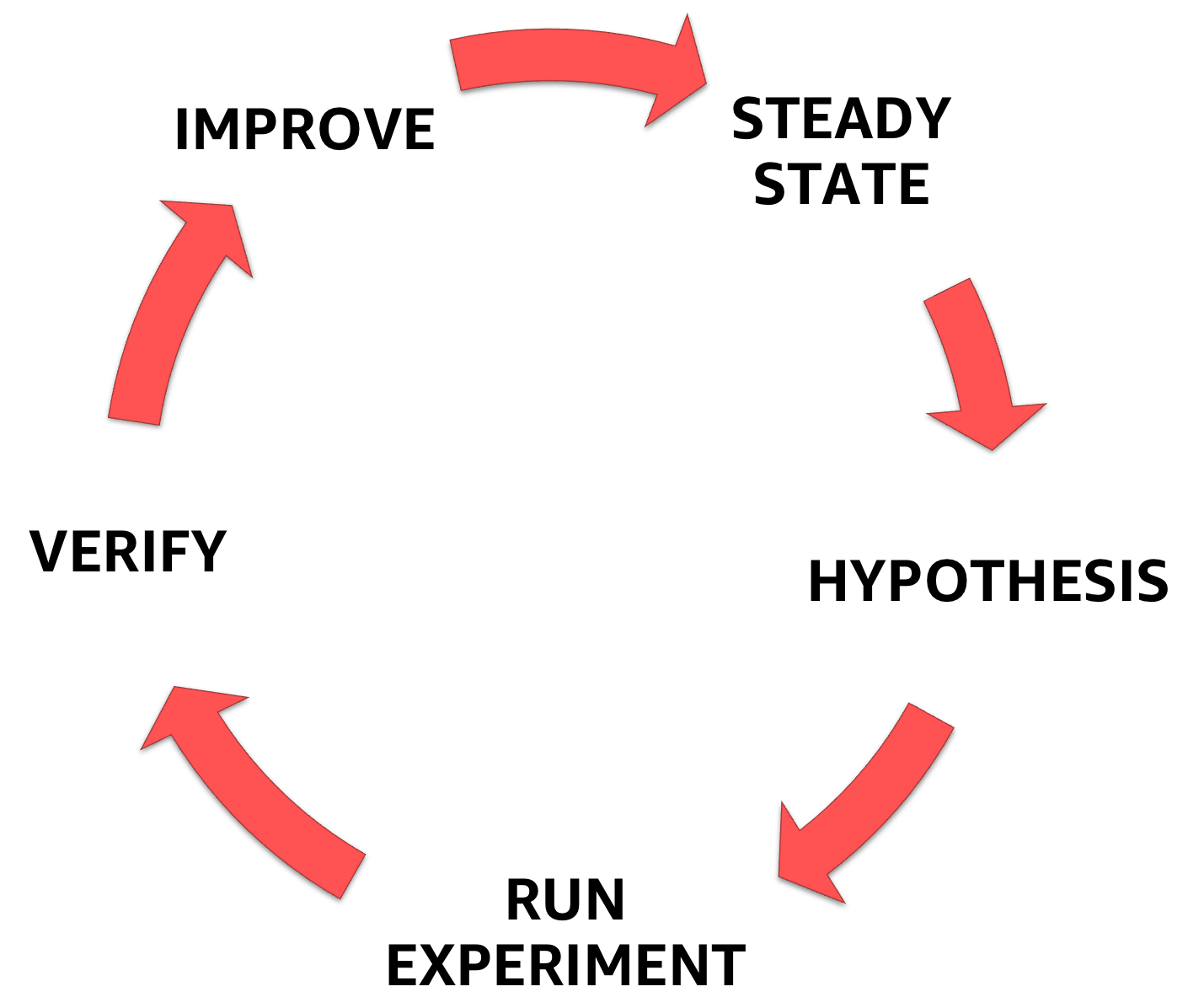
Fases da engenharia do caos
Na primeira parte de uma série de artigos, introduzi a engenharia do caos e discuti cada etapa da metodologia descrita acima.
Na segunda parte , examinei as áreas em que você precisa investir ao projetar experimentos em engenharia do caos e como escolher as hipóteses corretas.
Nesta terceira parte, vou me concentrar no experimento em si e apresentar uma seleção de ferramentas e métodos que cobrem uma ampla gama de falhas.
A lista não é exaustiva, mas, para começar, e para alimentar o pensamento, deve ser suficiente.
Introdução à falha - o que é e para que serve?
A falha é usada para verificar se a resposta do sistema atende às especificações em condições normais de carga. Pela primeira vez, essa técnica foi usada quando as falhas foram introduzidas no nível "ferro" - no nível dos contatos, alterando os sinais elétricos nos dispositivos.
Na programação, a introdução de falhas ajuda a melhorar a estabilidade do sistema de software e permite corrigir deficiências na resistência a possíveis falhas no sistema. Isso é chamado de solução de problemas. Também ajuda a avaliar os danos causados pela falha - ou seja, raio de dano, mesmo antes que ocorra falha no ambiente de produção. Isso é chamado de previsão de falha.
A introdução de falhas tem vários benefícios importantes, ajudando:
- Compreender e praticar respostas a acidentes e incidentes.
- entender os efeitos de falhas reais.
- entender a eficácia e as limitações dos mecanismos de tolerância a falhas.
- eliminar erros de projeto e detectar pontos comuns de falha.
- entender e melhorar a observabilidade do sistema.
- entender o raio da falha e reduzi-lo.
- entender a propagação do erro entre os componentes do sistema.
Categorias de falha
Existem 5 categorias de introdução de falha: no nível de (1) recurso; (2) rede e dependências; (3) aplicação, processo e serviço; (4) infraestrutura; e (5) o nível humano **.
A seguir, examinarei cada uma das categorias e darei um exemplo de introdução de falhas para cada uma delas. Também considerarei um exemplo de introdução de falhas e instrumentos de orquestração tudo em um.
** Importante! Neste post, não abordarei a introdução de falhas no nível humano, mas analisarei a seguir.
1 - Introdução de falha no nível de recurso, também conhecido como falta de recursos.
Sim, as tecnologias em nuvem nos ensinaram que os recursos são quase ilimitados, mas me apresso em desapontá-lo: eles não são infinitos. Instância, contêiner, função etc. - independentemente da abstração, os recursos acabam eventualmente. Indo além do limite máximo permitido de recursos, chama-se esgotamento.

A falta de recursos imita um ataque de negação de serviço , mas não o usual, para se infiltrar no servidor pretendido. Essa introdução de falhas provavelmente é generalizada, porque, provavelmente, não é difícil de usar.
Esgotando recursos de CPU, memória e E / S
Uma das minhas ferramentas favoritas é o stress-ng, a correspondência da ferramenta original de teste de estresse, de autoria de Amos Waterland .
Com o stress-ng, as falhas podem ser inseridas carregando vários subsistemas físicos do computador, bem como controlando as interfaces do núcleo do sistema usando testes de estresse. Os seguintes testes de estresse estão disponíveis: CPU, cache da CPU, dispositivo, E / S, interrupção, sistema de arquivos, memória, rede, SO, pipeline, agendador e VM. As páginas de manual incluem uma descrição completa de todos os testes de estresse disponíveis, e existem apenas 220 deles!
Abaixo estão alguns exemplos práticos de como usar o stress-ng:
A carga no CPU matrixprod fornece a combinação certa de operações com memória, cache e ponto flutuante. Talvez isso. A melhor maneira de aquecer bem a CPU.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60s
A carga do iomix-bytes grava N-bytes para cada iomix manipulador do iomix ; O padrão é 1 GB e é ideal para executar um teste de estresse de E / S. Neste exemplo, configurarei 80% do espaço livre do sistema de arquivos.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s
vm-bytes ótimo para testes de estresse de memória. Neste exemplo, o stress-ng executa 9 testes de estresse da memória virtual, que juntos consomem 90% da memória disponível por hora. Assim, cada teste de árvores consome 10% da memória disponível.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60s
Sem espaço em disco nos discos rígidos
dd é um utilitário de linha de comando compilado para converter e copiar arquivos. No entanto, o dd pode ler e / ou gravar arquivos de dispositivos especiais como /dev/zero e /dev/random para tarefas como fazer backup do setor de inicialização de um disco rígido e obter uma quantidade fixa de dados aleatórios. Assim, ele pode ser usado para introduzir falhas no servidor e simular o estouro de disco. Seus arquivos de log sobrecarregaram o servidor e descartaram o aplicativo? Então, o dd vai ajudar - e vai doer!
Use dd muito cuidado. Digite o comando errado - e os dados no disco serão apagados, destruídos ou substituídos!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &
Desaceleração da API do aplicativo
O desempenho, resiliência e escalabilidade da API são importantes. APIs são vitais para criar aplicativos e expandir seus negócios.
O teste de carga é uma ótima maneira de testar seu aplicativo antes que ele entre em produção. Esse também é um método interessante de carga de estresse, porque muitas vezes revela exceções e limitações que, em outras circunstâncias, permaneceriam invisíveis antes de encontrar tráfego real.
wrk é uma ferramenta de benchmarking HTTP que coloca uma pressão significativa nos sistemas. Eu gosto especialmente de testar as verificações de acessibilidade da API, especialmente quando se trata de verificações de desempenho , porque elas revelam muitas coisas relacionadas às decisões de design no nível do código do desenvolvedor: como o cache é configurado? Como o limite de velocidade é implementado? O sistema prioriza verificações de integridade em relação aos balanceadores de carga?
Aqui é por onde começar:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Este comando inicia 12 threads e mantém 400 conexões HTTP abertas por 20 segundos.
2 - Introduzindo falhas e dependências no nível da rede
O livro de Peter Deutsch , As oito falácias da computação distribuída, é uma coleção de suposições que os desenvolvedores fazem ao projetar sistemas distribuídos. E então a resposta voa na forma de inacessibilidade, e você precisa refazer tudo. Essas suposições errôneas são:
- A rede é confiável.
- O atraso é 0.
- A largura de banda é interminável.
- A rede está segura.
- A topologia não muda.
- Existe apenas um administrador.
- Custo de transferência 0.
- A rede é homogênea.
Esta lista é um bom ponto de partida para escolher o failover se você estiver testando para verificar se o sistema distribuído pode lidar com falhas de rede.
Introdução à latência, perda e interrupção da rede
Introdução à latência, perda ou interrupção da rede
tc ( controle de tráfego ) é uma ferramenta de linha de comando do Linux usada para configurar o agendador em lote do kernel do Linux. Ele define como os pacotes são enfileirados para transmissão e recepção na interface de rede. As operações incluem enfileiramento, definição de política, classificação, planejamento, modelagem e perda.
tc pode ser usado para simular atraso e perda de pacotes para aplicativos UDP ou TCP ou para limitar o uso da largura de banda de um serviço específico - para simular as condições do tráfego da Internet.
- introdução de um atraso de 100 ms
#Start ❯ tc qdisc add dev etho root netem delay 100ms #Stop ❯ tc qdisc del dev etho root netem delay 100ms
- introdução de um atraso de 100 ms com um delta de 50 ms
#Start ❯ tc qdisc add dev eth0 root netem delay 100ms 50ms #Stop ❯ tc qdisc del dev eth0 root netem delay 100ms 50ms
- danos a 5% dos pacotes de rede
#Start ❯ tc qdisc add dev eth0 root netem corrupt 5% #Stop ❯ tc qdisc del dev eth0 root netem corrupt 5%
- 7% de perda de pacotes com uma correlação de 25%
#Start ❯ tc qdisc add dev eth0 root netem loss 7% 25% #Stop ❯ tc qdisc del dev eth0 root netem loss 7% 25%
Importante! 7% é suficiente para o aplicativo TCP não cair.
Brincando com "/ etc / hosts" - uma tabela de pesquisa estática para nomes de hosts
/etc/hosts é um arquivo de texto simples que associa endereços IP a nomes de host, uma linha por vez. Cada nó requer uma linha contendo as seguintes informações:
IP_address canonical_hostname [aliases...]
O arquivo hosts é um dos vários sistemas que acessam nós de rede em uma rede de computadores e convertem nomes de host que as pessoas entendem em endereços IP. E sim, você adivinhou: graças a isso, é conveniente enganar computadores. Aqui estão alguns exemplos:
- Bloquear o acesso à API do DynamoDB para a instância do EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
- Bloquear o acesso à API do EC2 a partir de uma instância do EC2
#Start # make copy of /etc/hosts to /etc/host.back ❯ cp /etc/hosts /etc/hosts.back ❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts ❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts #Stop # copy back the old version /etc/hosts ❯ cp /etc/hosts.back /etc/hosts
Assista ao vivo: primeiro, a API do EC2 está disponível e ec2 describe-instances retornam com êxito.
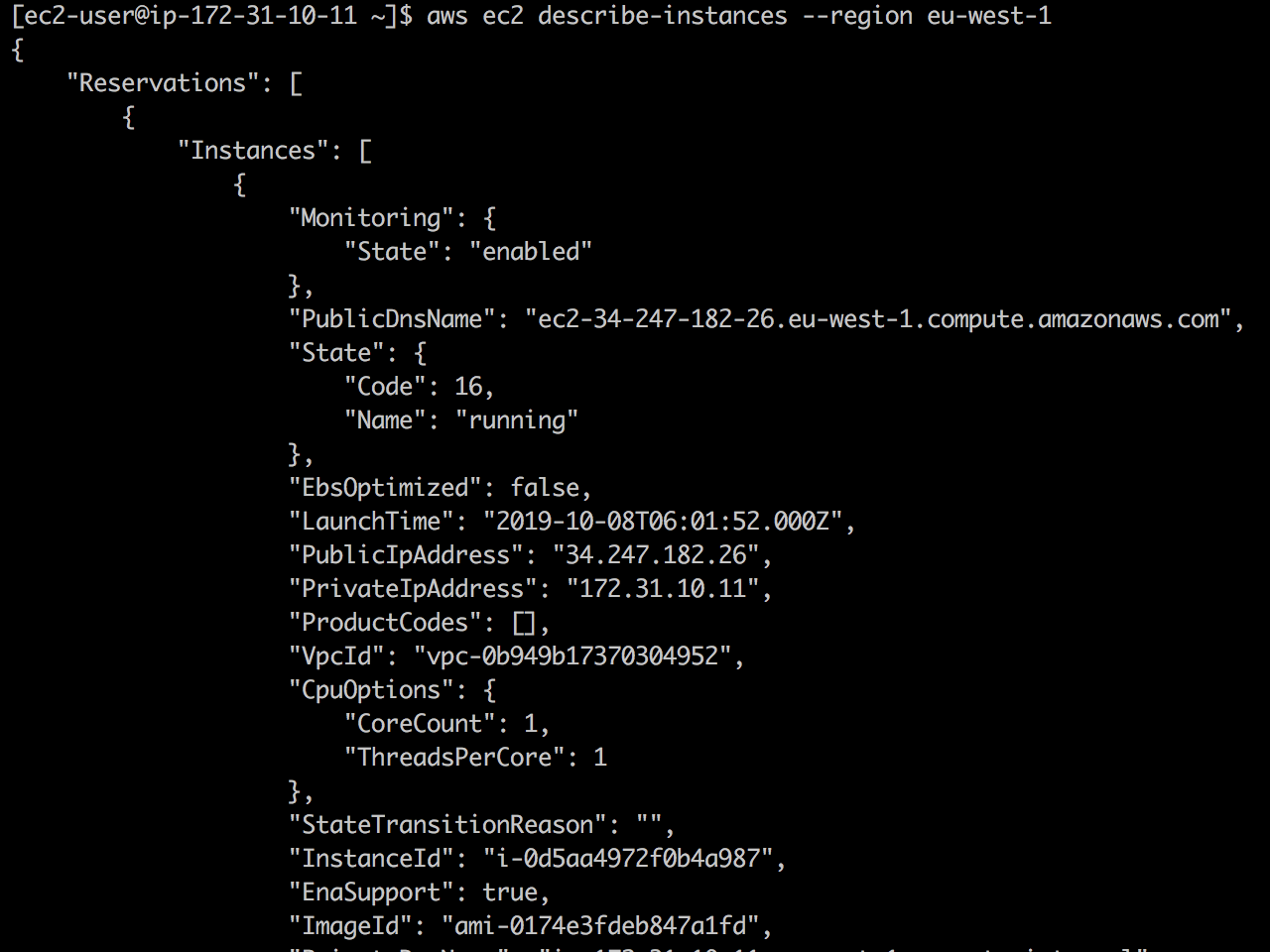
Uma vez eu adicionei 127.0.01 ec2.eu-west-1.amazonaws.com em /etc/hosts , e a chamada da API do EC2 cai.

Obviamente, isso funciona para todas as APIs da AWS.
Eu diria uma piada sobre DNS ...

... mas receio que só chegue até você no segundo dia. Quero dizer, depois de 24 horas.
Em 21 de outubro de 2016, devido ao ataque DDoS Dyn, um número decente de plataformas e serviços na Europa e na América do Norte não estava disponível. De acordo com o relatório ThousandEyes sobre o desempenho do DNS em todo o mundo em 2018 , 60% das empresas e provedores de SaaS ainda dependem de um único provedor de DNS de origem e, portanto, ficam vulneráveis a falhas de DNS. E como não haverá Internet sem DNS, será ótimo simular uma falha no DNS para avaliar sua resiliência à próxima falha no DNS.
Blackholing é um método pelo qual eles tradicionalmente reduzem o dano de um ataque DDoS . O tráfego de rede ruim é roteado para o buraco negro e despejado para ser anulado. A versão do /dev/null para trabalhar na rede :-) Você pode usá-lo para simular a perda de tráfego da rede ou o protocolo do mesmo DNS , digamos.
Para esta tarefa, você precisa da ferramenta iptables , usada para configurar, manter e verificar o pacote IP no kernel do Linux.
Para obter tráfego DNS pelo blackhole, tente o seguinte:
#Start ❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP #Stop ❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP ❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROP
Introdução de falhas usando o Toxiproxy.
Ferramentas Linux como tc e iptables um - mas não o único - problema sério. Eles exigem permissão de root para serem executados, e isso cria problemas para algumas organizações e ambientes. Por favor, ame e favor - Toxiproxy !
O Toxiproxy é um proxy TCP de código aberto desenvolvido pela equipe de engenheiros da Shopify . Ajuda a simular condições caóticas da rede e do sistema ou sistemas reais. Coloque-o entre os vários componentes da arquitetura, como mostrado abaixo.
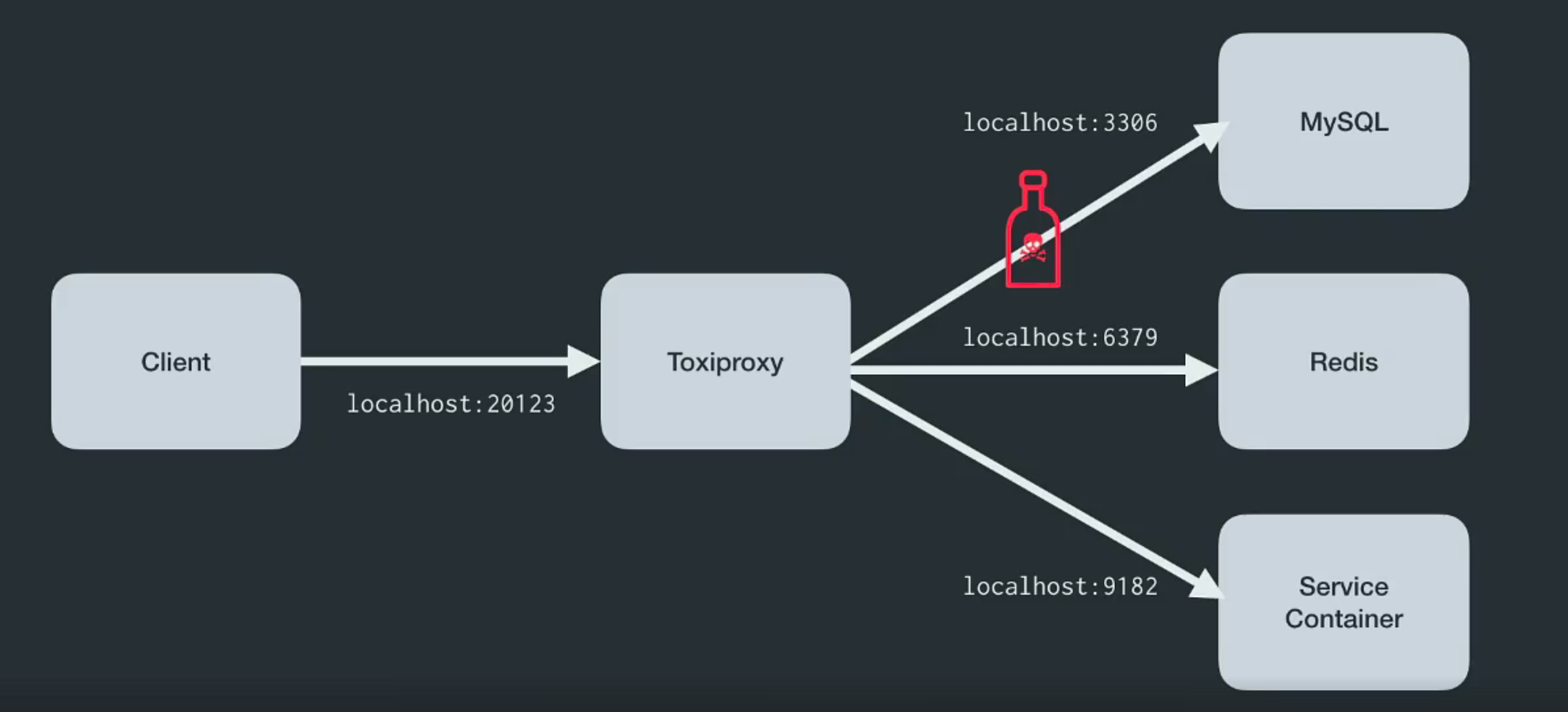
Foi criado especificamente para ambientes de teste, IC e desenvolvimento e apresenta uma confusão predefinida ou aleatória que é controlada por meio de configurações. O Toxiproxy usa substâncias tóxicas para manipular o relacionamento entre o cliente e o código do desenvolvedor e pode ser configurado através da API HTTP . E para ele no kit há toxinas suficientes para começar.
O exemplo a seguir mostra como o Toxiproxy funciona com o código do cliente tóxico, introduzindo um atraso de 1000 ms na conexão entre meu cliente Redis, redis-cli e o próprio Redis.
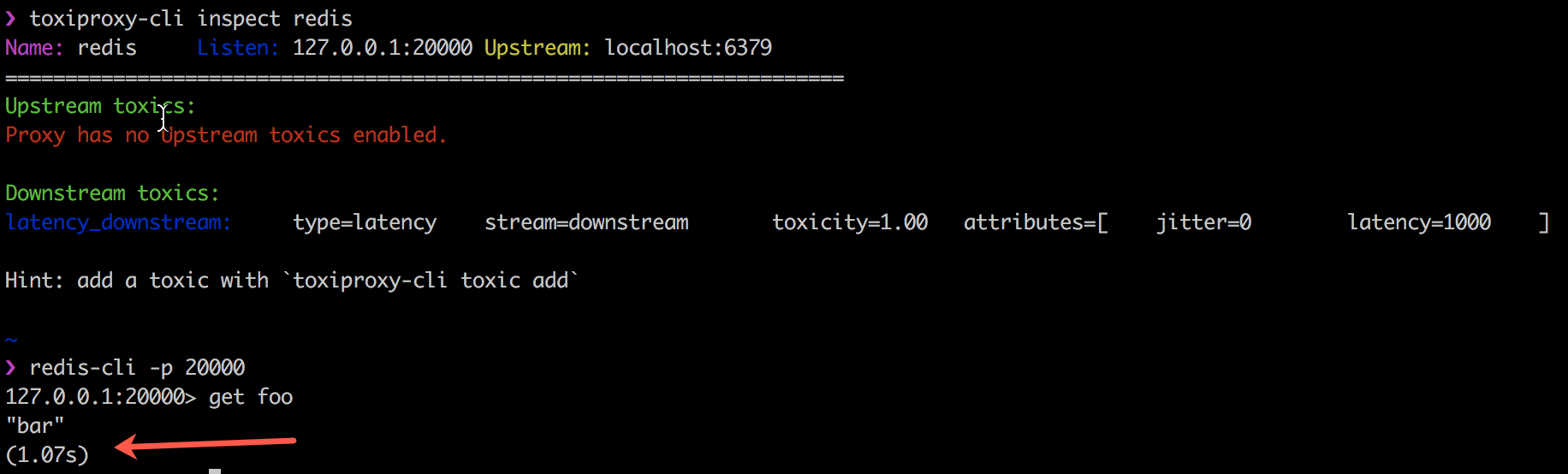
O Toxiproxy é usado com sucesso pelo Shopify em todos os ambientes de produção e desenvolvimento desde outubro de 2014. Mais informações estão em seu blog .
3 - Introdução de falhas no nível de aplicação, processo e serviço
O software está caindo. Isso é um fato. E o que voce faz Devo efetuar login via SSH no servidor e reiniciar o processo com falha? Os sistemas de controle de processo fornecem funções de controle ou alteração de estado do tipo iniciar, parar, reiniciar. Os sistemas de controle são geralmente usados para garantir um controle estável do processo. systemd é exatamente essa ferramenta, fornecendo os tijolos básicos de controle de processo para Linux. Supervisord oferece controle de vários processos em sistemas operacionais como o UNIX.
Ao implantar o aplicativo, você deve usar essas ferramentas. Certamente, é uma boa prática testar os danos causados pela morte de processos críticos. Certifique-se de receber alertas e que o processo reinicie automaticamente.
- mate processos Java
❯ pkill -KILL -f java #Alternative ❯ pkill -f 'java -jar'
- mate processos Python
❯ pkill -KILL -f python
Obviamente, você pode usar o comando pkill para eliminar alguns outros processos em execução no sistema.
Apresentando falhas no banco de dados
Se houver mensagens de falha que os operadores não gostam de receber, essas são as relacionadas a falhas no banco de dados. Os dados valem o seu peso em ouro e, portanto, sempre que um banco de dados falha, o risco de perda de dados do cliente aumenta.

Será apenas uma manutenção fácil. E-e-e-e-e-e-então ... tudo caiu
Às vezes, a capacidade de recuperar dados e colocar o banco de dados em condição de trabalho o mais rápido possível decide o futuro da empresa. Infelizmente, nem sempre é fácil se preparar para vários modos de falha do banco de dados - e muitos deles aparecerão apenas no ambiente de produção.
No entanto, se você estiver usando o Amazon Aurora , poderá testar a resiliência do cluster de banco de dados do Amazon Aurora para falhas usando solicitações de failover .
Introdução ao Amazon Aurora Crash
As solicitações de falha são emitidas como comandos SQL para uma instância do Amazon Aurora e permitem agendar uma simulação de um dos seguintes eventos:
- Falha em uma instância de gravação de banco de dados.
- Falha na réplica do Aurora.
- Falha no disco.
- Sobrecarga de disco.
Ao enviar uma solicitação de falha, você também deve especificar a quantidade de tempo durante a qual o evento de falha será simulado.
- Causa falha na instância do Amazon Aurora:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];
- simular a falha da Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE [ TO ALL | TO "replica name" ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simule falha de disco para o cluster de banco de dados Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
- simule falha de disco para o cluster de banco de dados Aurora:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION BETWEEN minimum AND maximum MILLISECONDS [ IN DISK index | NODE index ] FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };
Crash no mundo dos aplicativos sem servidor
A falha pode ser um desafio real se você usar componentes sem servidor, porque serviços sem servidor como o AWS Lambda não oferecem suporte nativo a failover.
Apresentando falhas do Lambda
Para entender esse problema, escrevi uma pequena biblioteca python e uma camada lambda - para introduzir falhas no AWS Lambda . Atualmente, ambos suportam atraso, erros, exceções e a introdução de um código de erro HTTP. A falha é obtida configurando o AWS SSM Parameter Store da seguinte maneira:
{ "isEnabled": true, "delay": 400, "error_code": 404, "exception_msg": "I really failed seriously", "rate": 1 }
Você pode adicionar um decorador python à função de manipulador para introduzir uma falha.
- lançar uma exceção:
@inject_exception def handler_with_exception(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_exception('foo', 'bar') Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1 corrupting now Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../chaos_lambda.py", line 316, in wrapper raise _exception_type(_exception_msg) Exception: I really failed seriously
- digite o código de erro "HTTP inválido":
@inject_statuscode def handler_with_statuscode(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_statuscode('foo', 'bar') Injecting Error 404 at a rate of 1 corrupting now {'statusCode': 404, 'body': 'Hello from Lambda!'}
- insira um atraso:
@inject_delay def handler_with_delay(event, context): return { 'statusCode': 200, 'body': 'Hello from Lambda!' } >>> handler_with_delay('foo', 'bar') Injecting 400 of delay with a rate of 1 Added 402.20ms to handler_with_delay {'statusCode': 200, 'body': 'Hello from Lambda!'}
Clique aqui para saber mais sobre esta biblioteca python.
Negação de imposição de lambda por limitação de simultaneidade
Por padrão, o Lambda, por motivos de segurança, ajusta a execução paralela de todas as funções em uma região específica por conta. Execuções paralelas se referem a várias execuções de um código de função que ocorrem em um único momento no tempo. Eles são usados para dimensionar uma chamada de função para uma solicitação recebida. Mas pode servir para o propósito oposto: parar a execução do Lambda.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0
Este comando reduzirá a simultaneidade a zero, causando falhas na consulta com um erro como "frenagem" - DTC 429 .
Thundra - rastreamento de transmissão sem servidor
O Thundra é uma ferramenta de monitoramento de aplicativos sem servidor que possui uma capacidade interna de injetar falhas em aplicativos sem servidor. Ele cria manipuladores de invólucro para a introdução de falhas como "sem manipulador de erros" para operações com o DynamoDB, "sem neutralização de erros" para a fonte de dados ou "sem tempo limite nas solicitações HTTP de saída". Eu ainda não tentei, mas neste post para a autoria de Yan Chui e neste magnífico vídeo de Marsha Villalba, o processo é bem descrito. Parece promissor.
E, concluindo a seção sobre aplicativos sem servidor, direi que Yan Chui tem um excelente artigo sobre as dificuldades da engenharia do caos em relação aos aplicativos sem servidor. Eu recomendo a todos que leiam.
4 - Introdução de falhas no nível da infraestrutura
Tudo começou com a introdução de falhas no nível da infraestrutura - para Amazon e Netflix. A introdução de falhas no nível da infraestrutura - da desconexão de um datacenter inteiro à interrupção aleatória de instâncias - é provavelmente a mais fácil de implementar.
E, claro, o exemplo do " macaco do caos " vem à mente primeiro.
Parando instâncias do EC2 selecionadas aleatoriamente em uma determinada zona de disponibilidade.
Na infância, a Netflix queria introduzir regras arquiteturais difíceis. Ele implantou seu “macaco do caos” como um dos primeiros aplicativos da AWS a instalar microsserviços sem estado de escala automática - no sentido de que qualquer instância pode ser destruída ou substituída automaticamente sem causar perda de estado. O Macaco do Caos garantiu que ninguém violasse essa regra.
O próximo cenário - semelhante ao "macaco do caos" - é interromper qualquer instância aleatoriamente, em uma zona de disponibilidade específica dentro da mesma região.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")
import boto3 import random REGION = 'eu-west-1' def stop_random_instance(az, tag_name, tag_value, region=REGION): ''' >>> stop_random_instance(az="eu-west-1a", tag_name='chaos', tag_value="chaos-ready", region='eu-west-1') ['i-0ddce3c81bc836560'] ''' ec2 = boto3.client("ec2", region_name=region) paginator = ec2.get_paginator('describe_instances') pages = paginator.paginate( Filters=[ { "Name": "availability-zone", "Values": [ az ] }, { "Name": "tag:" + tag_name, "Values": [ tag_value ] } ] ) instance_list = [] for page in pages: for reservation in page['Reservations']: for instance in reservation['Instances']: instance_list.append(instance['InstanceId']) print("Going to stop any of these instances", instance_list) selected_instance = random.choice(instance_list) print("Randomly selected", selected_instance) response = ec2.stop_instances(InstanceIds=[selected_instance]) return response
Você tag_name tag_value e tag_value ? Essas pequenas coisas impedirão o fracasso das instâncias erradas. #lessonlearned

E sim ... reinicie o banco de dados - bem feito [oops, não nessa instância]
5 - Introdução de falhas e ferramentas de orquestração tudo em um
É provável que você esteja perdido em tantas ferramentas. Felizmente, existem algumas ferramentas de introdução e orquestração de recusas que incluem a maioria delas e são fáceis de usar.
Uma das minhas ferramentas favoritas é o Chaos Toolkit , uma plataforma de engenharia de caos de código aberto suportada comercialmente pela grande equipe do ChaosIQ . Aqui estão apenas alguns deles: Russ Miles , Sylvain Helleguarch e Marc Parrien .
O Chaos Toolkit define uma API declarativa e extensível para conduzir convenientemente um experimento de engenharia do caos. Inclui drivers para AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus e Gremlin.
Extensões são um conjunto de verificações e ações usadas para experimentos da seguinte maneira: paramos uma instância selecionada aleatoriamente em uma zona de disponibilidade específica se a tag-key contiver chaos-ready valor chaos-ready .
{ "version": "1.0.0", "title": "What is the impact of randomly terminating an instance in an AZ", "description": "terminating EC2 instance at random should not impact my app from running", "tags": ["ec2"], "configuration": { "aws_region": "eu-west-1" }, "steady-state-hypothesis": { "title": "more than 0 instance in region", "probes": [ { "provider": { "module": "chaosaws.ec2.probes", "type": "python", "func": "count_instances", "arguments": { "filters": [ { "Name": "availability-zone", "Values": ["eu-west-1c"] } ] } }, "type": "probe", "name": "count-instances", "tolerance": [0, 1] } ] }, "method": [ { "type": "action", "name": "stop-random-instance", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "stop_instance", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] }, "pauses": { "after": 60 } } ], "rollbacks": [ { "type": "action", "name": "start-all-instances", "provider": { "type": "python", "module": "chaosaws.ec2.actions", "func": "start_instances", "arguments": { "az": "eu-west-1c" }, "filters": [ { "Name": "tag-key", "Values": ["chaos-ready"] } ] } } ] }
Realizar a experiência acima é simples:
❯ chaos run experiment_aws_random_instance.json
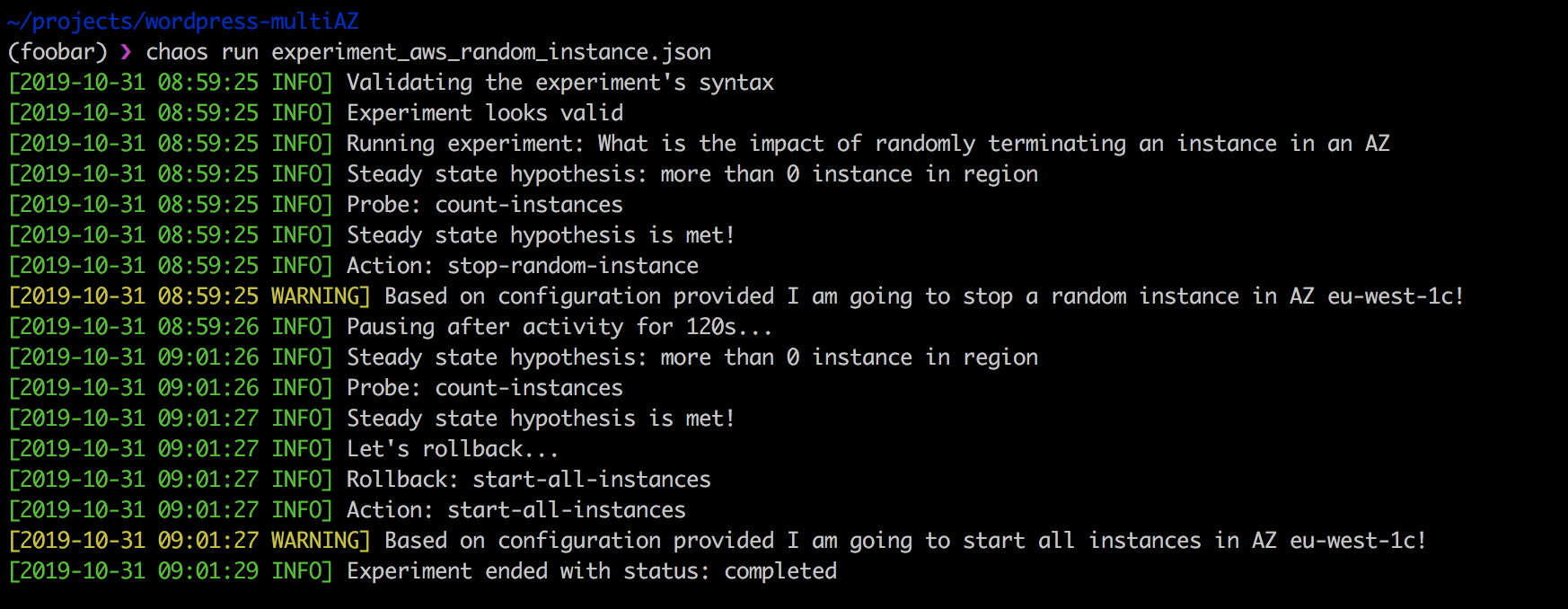
A força do Chaos Toolkit é que, primeiramente, ele é de código aberto e pode ser adaptado às suas necessidades. Em segundo lugar, ele se encaixa perfeitamente no pipeline de CI / CD e suporta testes contínuos de caos.
A desvantagem do Chaos Toolkit é que leva tempo para dominá-lo. Além disso, não existem experimentos prontos, então você deve escrevê-los. No entanto, estou familiarizado com a equipe do ChaosIQ, que trabalha incansavelmente, entendendo essa tarefa.
Gremlin
Outro favorito meu é o Gremlin. Ele contém um conjunto abrangente de modos para introduzir falhas em uma ferramenta simples com uma interface de usuário intuitiva. Tal caos como serviço.
O Gremlin suporta a introdução de falhas nos níveis de recursos, rede e consulta , permitindo que você experimente rapidamente todo o sistema, incluindo com hardware, vários provedores de nuvem, ambientes em contêiner, incluindo Kubernetes, aplicativos e, até certo ponto, aplicativos sem servidor.
Mais um bônus - os caras do Gremlin são ótimos companheiros que escrevem ótimos conteúdos para o blog e estão sempre prontos para ajudar! Aqui estão alguns deles: Matthew , Colton , Tammy , Rich , Ana e HML .
Gremlin não tem onde usar:
Primeiro, entre no aplicativo Gremlin e selecione "Criar ataque".
Atribua uma meta - instância.
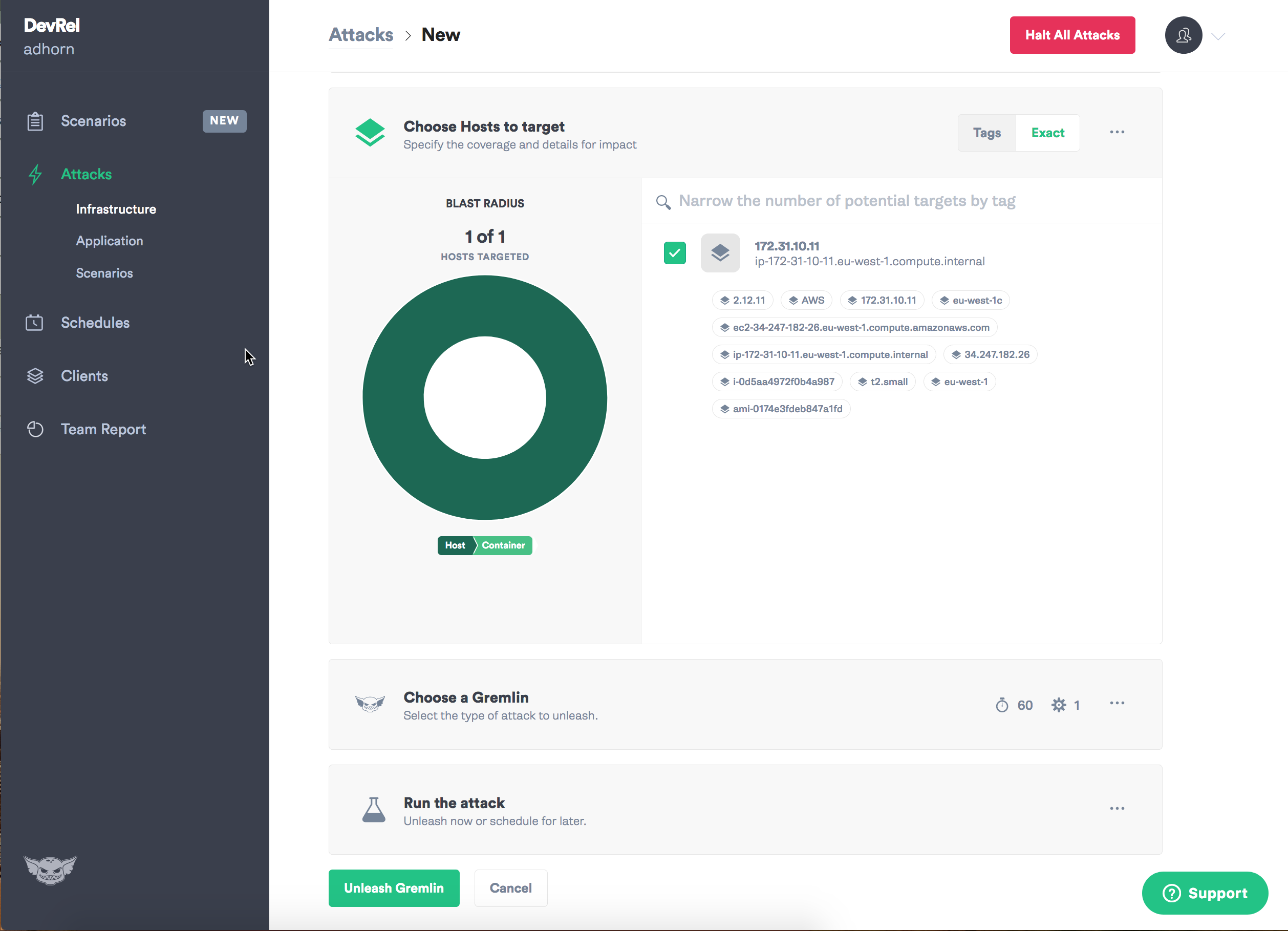
Selecione o tipo de falha que você deseja introduzir e o caos pode começar!
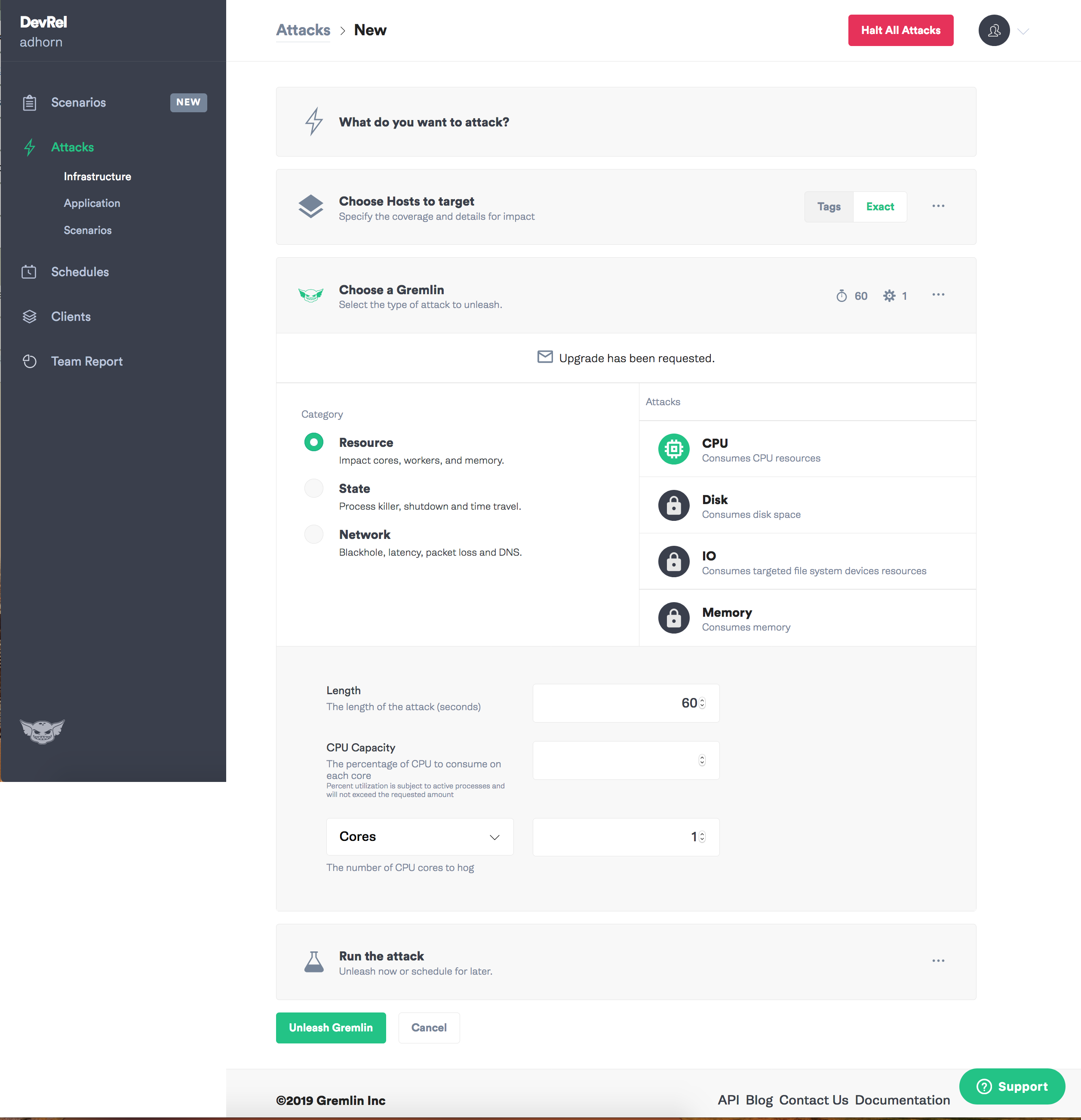
Devo admitir que sempre gostei de Gremlin: com isso, experimentos em engenharia do caos são intuitivamente simples.
Menos preço - é necessária uma licença para o trabalho, que pode não ser adequada para usuários iniciantes ou trabalhos únicos. No entanto, recentemente adicionou sua versão gratuita. Além disso, o cliente e daemon Gremlin precisam ser instalados em instâncias que precisam ser atacadas, mas isso não é do agrado de todos.
Executar comando do AWS System Manager
Run command EC2 , 2015 , . — 2, . , , Systems Manager.
Run Command DevOps ad-hoc , .
, Run Command , Windows, -.
AWS System Manager . — !
!
, .
1 — - — , - . . — , — , , . , ! :
" . ".
— , - Amazon Prime Video
2 — , , . , -.
3 — , , .
4 — , , , . , - — , .
, , , . , . , , :-)
—