
Era 2019 e ainda não temos uma solução padrão para agregação de logs no Kubernetes. Neste artigo, gostaríamos, usando exemplos da prática real, de compartilhar nossas pesquisas, os problemas encontrados e suas soluções.
No entanto, para começar, farei uma reserva para que diferentes clientes entendam coisas muito diferentes coletando logs:
- alguém quer ver logs de segurança e auditoria;
- alguém - registro centralizado de toda a infraestrutura;
- e para alguém, basta coletar apenas os logs do aplicativo, excluindo, por exemplo, balanceadores.
Sobre como implementamos várias "lista de desejos" e quais dificuldades encontramos, sob o corte.
Teoria: Sobre Ferramentas de Log
Antecedentes dos componentes do sistema de registro
O log já percorreu um longo caminho, como resultado do qual desenvolvemos metodologias para coletar e analisar logs, que usamos hoje. Nos anos 50, Fortran introduziu um análogo de fluxos de E / S padrão que ajudaram o programador a depurar seu programa. Esses foram os primeiros registros do computador que facilitaram a vida dos programadores da época. Hoje, vemos neles o primeiro componente do sistema de registro - a
fonte ou "produtor" dos registros .
A ciência da computação não parou: surgiram redes de computadores, os primeiros grupos ... Sistemas complexos, compostos por vários computadores, começaram a funcionar. Agora, os administradores de sistema eram forçados a coletar logs de várias máquinas e, em casos especiais, podiam adicionar mensagens do kernel do SO, caso precisassem investigar uma falha no sistema. Para descrever os sistemas centralizados de coleta de logs, o
RFC 3164 foi lançado no início dos anos 2000, que padronizou o remote_syslog. Então outro componente importante apareceu: o
coletor (coletor) de logs e seu armazenamento.
Com o aumento do volume de logs e a ampla adoção de tecnologias da Web, surgiu a questão de quais logs devem ser convenientemente mostrados aos usuários. Ferramentas simples de console (awk / sed / grep) foram substituídas por
visualizadores de log mais avançados - o terceiro componente.
Em conexão com o aumento no volume de logs, outra coisa ficou clara: os logs são necessários, mas não todos. E registros diferentes exigem níveis diferentes de segurança: alguns podem ser perdidos a cada dois dias, enquanto outros precisam ser armazenados por 5 anos. Portanto, um componente de filtragem e roteamento para fluxos de dados foi adicionado ao sistema de registro - vamos chamá-lo de
filtro .
Os repositórios também deram um grande salto: eles mudaram de arquivos regulares para bancos de dados relacionais e, em seguida, para repositórios orientados a documentos (por exemplo, Elasticsearch). Portanto, o armazenamento foi separado do coletor.
No final, o próprio conceito de log se expandiu para um fluxo abstrato de eventos que queremos manter para a história. Mais precisamente, no caso de ser necessário conduzir uma investigação ou elaborar um relatório analítico ...
Como resultado, em um período relativamente curto, a coleção de logs se transformou em um subsistema importante, que pode ser chamado de uma das subseções no Big Data.
 Se antes as impressões comuns eram suficientes para um "sistema de registro", agora a situação mudou muito.
Se antes as impressões comuns eram suficientes para um "sistema de registro", agora a situação mudou muito.Kubernetes e logs
Quando Kubernetes entrou na infraestrutura, o problema existente de coletar logs não passou por ele. Em certo sentido, tornou-se ainda mais doloroso: o gerenciamento da plataforma de infraestrutura não foi apenas simplificado, mas também complicado. Muitos serviços antigos começaram a migrar para trilhas de microsserviço. No contexto dos logs, isso resultou em um número crescente de fontes de log, seu ciclo de vida especial e a necessidade de rastrear através dos logs as interconexões de todos os componentes do sistema ...
Olhando para o futuro, posso dizer que agora, infelizmente, não existe uma opção de registro padronizada para o Kubernetes que se comporte favoravelmente com todos os outros. Os esquemas mais populares da comunidade são os seguintes:
- alguém está implantando uma pilha EFK (Elasticsearch, Fluentd, Kibana);
- alguém está experimentando o Loki lançado recentemente ou usando o operador Logging ;
- nós (e talvez não apenas nós? ..) estamos bastante satisfeitos com nosso próprio desenvolvimento - loghouse ...
Como regra, usamos esses pacotes nos clusters K8s (para soluções auto-hospedadas):
No entanto, não vou me debruçar sobre as instruções para instalação e configuração. Em vez disso, vou me concentrar em suas deficiências e em conclusões mais globais sobre a situação dos logs em geral.
Pratique com logs nos K8s

"Registros diários", quantos de vocês?
A coleta centralizada de logs com uma infraestrutura suficientemente grande requer recursos consideráveis que serão gastos na coleta, armazenamento e processamento de logs. Durante a operação de vários projetos, fomos confrontados com vários requisitos e os problemas operacionais resultantes.
Vamos tentar o ClickHouse
Vejamos um repositório centralizado em um projeto com um aplicativo que gera muitos logs: mais de 5000 linhas por segundo. Vamos começar a trabalhar com os logs dele, adicionando-os ao ClickHouse.
Assim que o tempo real máximo for necessário, o servidor ClickHouse de quatro núcleos já estará sobrecarregado no subsistema de disco:

Esse tipo de download deve-se ao fato de estarmos tentando gravar no ClickHouse o mais rápido possível. E o banco de dados responde a isso com maior carga de disco, o que pode causar os seguintes erros:
DB::Exception: Too many parts (300). Merges are processing significantly slower than insertsO fato é que
as tabelas MergeTree no ClickHouse (elas contêm dados de log) têm suas próprias dificuldades durante as operações de gravação. Os dados inseridos neles geram uma partição temporária, que é mesclada com a tabela principal. Como resultado, a gravação é muito exigente no disco, e a restrição se aplica a ele, cuja notificação recebemos acima: não mais de 300 subpartições podem ser mescladas em 1 segundo (na verdade, são 300 insert'ov por segundo).
Para evitar esse comportamento, você
deve escrever no ClickHouse o maior número possível de partes e não mais do que 1 vez em 2 segundos. No entanto, escrever em lotes grandes sugere que devemos escrever com menos frequência no ClickHouse. Isso, por sua vez, pode levar a estouros de buffer e perda de logs. A solução é aumentar o buffer do Fluentd, mas o consumo de memória aumentará.
Nota : Outro problema com nossa solução ClickHouse foi que o particionamento em nosso caso (loghouse) foi implementado por meio de tabelas externas vinculadas por uma tabela Merge . Isso leva ao fato de que, durante a amostragem de grandes intervalos de tempo, é necessária RAM excessiva, uma vez que a meta-tabela passa por todas as partições - mesmo aquelas que obviamente não contêm os dados necessários. No entanto, agora essa abordagem pode ser declarada obsoleta com segurança para as versões atuais do ClickHouse (desde 18.16 ).Como resultado, fica claro que o ClickHouse não possui recursos suficientes para cada projeto coletar logs em tempo real (mais precisamente, sua distribuição não será conveniente). Além disso, você precisará usar uma
bateria , à qual retornaremos. O caso descrito acima é real. E, naquele momento, não podíamos oferecer uma solução confiável e estável que fosse adequada ao cliente e permitisse coletar logs com um atraso mínimo ...
E a Elasticsearch?
O Elasticsearch é conhecido por lidar com cargas pesadas. Vamos tentar no mesmo projeto. Agora a carga é a seguinte:
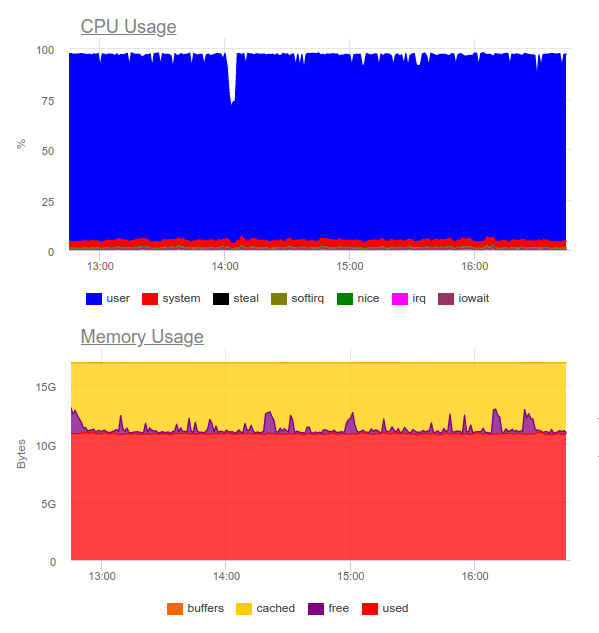
A Elasticsearch conseguiu digerir o fluxo de dados; no entanto, gravar esses volumes nele utiliza muito a CPU. Isso é decidido pela organização do cluster. Tecnicamente, isso não é um problema, mas acontece que apenas para a operação do sistema de coleta de logs já usamos cerca de 8 núcleos e temos um componente adicional altamente carregado no sistema ...
Conclusão: essa opção pode ser justificada, mas apenas se o projeto for grande e seu gerenciamento estiver pronto para gastar recursos significativos em um sistema de registro centralizado.
Então surge uma pergunta lógica:
Quais logs são realmente necessários?

Vamos tentar mudar a abordagem em si: os logs devem ser informativos ao mesmo tempo e não abranger
todos os eventos do sistema.
Digamos que temos uma próspera loja online. Quais logs são importantes? Reunir o máximo de informações possível, por exemplo, de um gateway de pagamento é uma ótima idéia. Porém, no serviço de divisão de imagens no catálogo de produtos, nem todos os logs são críticos para nós: apenas erros e monitoramento avançado são suficientes (por exemplo, a porcentagem de 500 erros que esse componente gera).
Então chegamos à
conclusão de que
o registro centralizado está longe de ser sempre justificado . Muitas vezes, o cliente deseja coletar todos os logs em um único local, embora na verdade apenas 5% das mensagens críticas para os negócios sejam necessárias em todo o log:
- Às vezes, basta configurar, digamos, apenas o tamanho do log do contêiner e do coletor de erros (por exemplo, Sentry).
- Para investigar incidentes, alertas de erro e um grande registro local podem ser suficientes.
- Tínhamos projetos que custavam completamente apenas testes funcionais e sistemas de coleta de erros. O desenvolvedor não precisava dos logs, como tal - eles viram tudo nos rastros de erros.
Ilustração vida
Um bom exemplo é outra história. Recebemos uma solicitação da equipe de segurança de um dos clientes que já possuía uma solução comercial desenvolvida muito antes da implementação do Kubernetes.
Foi necessário para "fazer amigos" um sistema centralizado de coleta de logs com um sensor corporativo para detectar problemas - o QRadar. Este sistema é capaz de receber logs usando o protocolo syslog, para retirá-lo do FTP. No entanto, a integração com o plugin remote_syslog para fluentd não funcionou imediatamente
(como se viu, não somos os únicos ) . Os problemas de configuração do QRadar estavam do lado da equipe de segurança do cliente.
Como resultado, parte dos logs críticos para os negócios foram carregados no FTP QRadar e a outra parte foi redirecionada via syslog remoto diretamente dos nós. Para fazer isso, até escrevemos um
gráfico simples - talvez isso ajude alguém a resolver um problema semelhante ... Graças ao esquema resultante, o próprio cliente recebeu e analisou logs críticos (usando suas ferramentas favoritas), e conseguimos reduzir o custo do sistema de log, mantendo apenas o último mês.
Outro exemplo é bastante indicativo de como não fazer isso. Um de nossos clientes, para lidar com
cada evento proveniente do usuário, produziu informações não
estruturadas em várias
linhas no log. Como você pode imaginar, esses logs eram extremamente inconvenientes para ler e armazenar.
Critérios para logs
Tais exemplos levam à conclusão de que, além de escolher um sistema para coletar logs, você também deve
criar os próprios logs ! Quais são os requisitos aqui?
- Os logs devem estar em um formato legível por máquina (por exemplo, JSON).
- Os logs devem ser compactos e com a capacidade de alterar o grau de log para depurar possíveis problemas. Ao mesmo tempo, em ambientes de produção, você deve executar sistemas com um nível de log como Aviso ou Erro .
- Os logs devem ser normalizados, ou seja, no objeto de log, todas as linhas devem ter o mesmo tipo de campo.
Logs não estruturados podem causar problemas ao carregar logs no repositório e interromper seu processamento completamente. Para ilustrar, aqui está um exemplo com um erro 400, que muitos certamente encontraram nos logs fluentes:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"Um erro significa que você está enviando um campo cujo tipo é instável para o índice com um mapeamento pronto. O exemplo mais simples é um campo no log nginx com a variável
$upstream_status . Pode ter um número ou uma sequência. Por exemplo:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}Os logs mostram que o servidor 10.100.0.10 respondeu com o erro 404 e a solicitação foi para outro armazenamento de conteúdo. Como resultado, nos logs, o significado se tornou assim:
"upstream_response_time": "0.001, 0.007"Essa situação é tão generalizada que até ganhou uma
menção separada
na documentação .
E quanto à confiabilidade?
Há momentos em que todos os logs são vitais, sem exceção. E com isso, os esquemas típicos de coleta de logs para os K8s propostos / discutidos acima têm problemas.
Por exemplo, o fluentd não pode coletar logs de contêineres de curta duração. Em um de nossos projetos, o contêiner com a migração do banco de dados permaneceu por menos de 4 segundos e foi excluído - de acordo com a anotação correspondente:
"helm.sh/hook-delete-policy": hook-succeededPor esse motivo, o log de migração não entrou no repositório. A política de
before-hook-creation pode ajudar nesse caso.
Outro exemplo é a rotação dos logs do Docker. Suponha que exista um aplicativo que grave ativamente nos logs. Em condições normais, conseguimos processar todos os logs, mas assim que surge um problema - por exemplo, como descrito acima com o formato errado - o processamento é interrompido e o Docker gira o arquivo. Conclusão - os logs críticos para os negócios podem ser perdidos.
É por isso
que é importante separar o fluxo de logs , incorporando o envio dos mais valiosos diretamente ao aplicativo para garantir sua segurança. Além disso, não será supérfluo criar um tipo de
"acumulador" de logs que possam sobreviver à breve indisponibilidade do armazenamento, mantendo as mensagens críticas.
Por fim, não esqueça que
é importante monitorar qualquer subsistema de maneira qualitativa . Caso contrário, é fácil encontrar uma situação em que fluentd esteja no estado
CrashLoopBackOff e não envie nada, e isso promete uma perda de informações importantes.
Conclusões
Neste artigo, não consideramos soluções SaaS como o Datadog. Muitos dos problemas descritos aqui já foram resolvidos de uma maneira ou de outra por empresas comerciais especializadas na coleta de logs, mas nem todos podem usar o SaaS por vários motivos
(os principais são custo e conformidade com 152-) .
A coleção centralizada de logs a princípio parece uma tarefa simples, mas não é de todo. É importante lembrar que:
- O registro em detalhes é apenas componentes críticos e, para outros sistemas, você pode configurar o monitoramento e a coleta de erros.
- Os logs de produção devem ser minimizados para não fornecer uma carga extra.
- Os logs devem ser legíveis por máquina, normalizados e ter um formato estrito.
- Logs realmente críticos devem ser enviados em um fluxo separado, que deve ser separado dos principais.
- Vale a pena considerar uma bateria de registro, que pode economizar explosões de alta carga e tornar a carga no armazenamento mais uniforme.

Essas regras simples, se aplicadas em todos os lugares, permitiriam que os circuitos descritos acima funcionassem - mesmo sem componentes importantes (bateria). Se você não seguir esses princípios, a tarefa levará facilmente você e a infraestrutura a outro componente altamente carregado (e ao mesmo tempo ineficaz) do sistema.
PS
Leia também em nosso blog: