
Em uma conferência de desenvolvedores de software de sistema e ferramenta - OS DAY 2016, realizada em Innopolis de 9 a 10 de junho de 2016 (Kazan), ao discutir um relatório sobre arquitetura multicelular, foi expressa a ideia de que seria mais eficaz na solução de problemas de inteligência artificial. As condições para o desenvolvimento de um novo processador de uso geral focado nas tarefas de IA foram desenvolvidas este ano.
O neuroprocessador S2 Multiclet, cujo projeto foi apresentado pela primeira vez no Huawei Innovation Forum 2019, é um desenvolvimento adicional da arquitetura multicelular. Difere das multicélulas criadas anteriormente com um sistema de comandos, ou seja, a introdução de novos tipos de dados de tamanho pequeno (com ponto fixo e flutuante) e as operações com eles. O número de células foi aumentado - 256 e a frequência - 2,5 GHz, o que deve fornecer um desempenho máximo de 81,9 TFlops a 16F e, portanto, torná-lo comparável, em termos de cálculos neurais, com as capacidades dos modernos ASIC TPUs especializados (TPU-3: 90 TFlops em 16F).
Como a eficiência do uso de processadores depende amplamente da otimização do compilador, um esquema de otimização de código desenvolvido foi desenvolvido.
Vamos considerar com mais detalhes.
O
artigo anterior mencionou otimizações do compilador que valem a pena ser implementadas. Lá, você pode encontrar materiais sobre arquitetura multicelular se ainda não estiver familiarizado.
Gerando comandos de dois argumentos com duas constantes
Um novo formato de instrução foi introduzido com o processador S1, permitindo que ambos os argumentos fossem especificados como um valor constante. Isso permite reduzir o número de comandos no código, livrando-se de comandos desnecessários, como carregar para carregar as constantes no comutador.
Por exemplo:
load_l func wr_l @1, #SP
pode ser substituído por:
wr_l func, #SP
Ou até duas equipes ao mesmo tempo:
load_l [foo] load_l [bar] add_l @1, @2
Existem dois endereços constantes e a leitura deles também pode ser substituída diretamente nos argumentos do comando:
add_l [foo], [bar]
Essa otimização foi implementada para todos que suportam esse formato. Infelizmente, acabou sendo muito ineficaz, por duas razões:
- O número de situações em que essa otimização pode ser realizada é muito pequeno. No código de arbitragem, as situações raramente surgem quando você precisa de alguma forma processar dois valores que são conhecidos antecipadamente. Na maioria das vezes, essas coisas são decididas no estágio de compilação e resta apenas um pouco a ser feito em tempo de execução. Geralmente, estas são algumas operações em endereços, novamente, constantes.
- A remoção do comando load não libera o processador do processo de geração da constante, mas apenas da busca de um comando load separado, que fornece apenas uma aceleração fraca e, mesmo assim, nem sempre.
Otimização da transferência de registros virtuais entre unidades base
No LLVM, os blocos básicos são seções lineares nas quais o código é executado sem ramificação. Os parágrafos em uma arquitetura multicelular desempenham exatamente a mesma função; portanto, na maioria das vezes, ao gerar um código, um parágrafo reflete um bloco básico. No processador R1, qualquer transferência de registradores virtuais entre parágrafos foi realizada através da memória, escrevendo o valor do registro desejado na pilha e lendo-o novamente no parágrafo que precisa desse registro. Esse mecanismo é dividido em 2 partes: transferência do registro virtual para outro parágrafo para uso direto e transferência do registro virtual como parâmetro para o nó phi.
Os nós phi são uma conseqüência da forma
SSA (Static Single Assignment) na qual a linguagem de apresentação LLVM é representada. Nesse formulário, uma variável (ou, como no caso de LLVM IR - registros virtuais) pode ser gravada apenas uma vez. Por exemplo, este pseudo código:
a = 1; if (v < 10) a = 2; else a = 3; b = a;
não apresentado no formato SSA, porque o valor da variável
a pode ser substituído. O código pode ser reescrito neste formulário, se você usar o nó phi:
a1 = 1; if (v < 10) a2 = 2; else a3 = 3; b = phi(a2, a3);
O nó phi seleciona a2 ou a3, dependendo da origem do fluxo de controle:
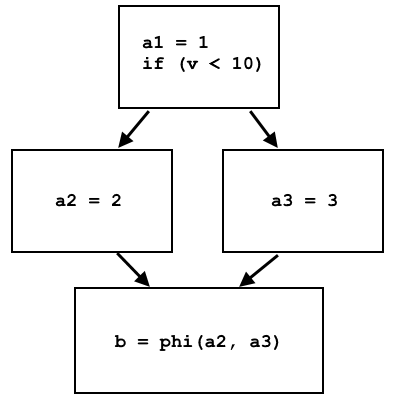
No phi LLVM IR, os nós são implementados como uma instrução separada, que seleciona diferentes registros virtuais, dependendo de qual unidade base o controle veio. A implementação no processador desta instrução através da memória é bastante simples: diferentes blocos de base gravam dados diferentes na mesma célula de memória e, no lugar do nó phi, essa célula de memória é lida e os dados serão diferentes dependendo do bloco de base anterior.
O formulário SSA implica que, quando o registro for inicializado, o valor sempre será o mesmo. Quando a transferência direta de registros virtuais é realizada, quando o valor de cada registro virtual é gravado em sua própria célula de memória separada, a condição SSA é atendida sem problemas: os dados ficam na memória até serem substituídos. No entanto, se queremos transferir o registro por meio do comutador, devemos lembrar: seu tamanho é de apenas 63 células e qualquer valor desaparece quando qualquer 63 comando é executado. Portanto, se o registro virtual for escrito em um primeiro parágrafo e for usado após a conclusão de centenas de outros, é impossível transferi-lo através do comutador; apenas a memória permanece.
A implementação dessa otimização foi iniciada precisamente com a otimização dos nós phi, porque, diferentemente da transferência direta de registros virtuais, os valores dos parâmetros para o nó phi sempre são inicializados diretamente nos parágrafos anteriores (blocos de base), o que permite que você não pense muito se o switch é grande o suficiente se queremos passar esses parâmetros através dele.
O assembler multicelular permite atribuir nomes aos resultados dos comandos e usar seus resultados por esse nome. Em vez de cada programador ter que calcular quantos comandos esse resultado foi obtido de volta, o montador calcula isso sozinho:
result := add_l [A], [B] ; ; ; wr_l @result, C
Esse mecanismo funciona perfeitamente dentro do parágrafo atual, porque é uma seção linear e a ordem dos comandos é conhecida lá. Isso é usado ativamente quando o compilador gera código: todos os comandos recebem nomes e o compilador não precisa se preocupar com a numeração dos comandos. Mais precisamente, não era necessário, porque se queremos que o resultado de um comando seja executado em outro parágrafo, o mecanismo não funciona: no estágio de montagem, é impossível descobrir qual parágrafo foi realmente executado pelo anterior, se houver várias entradas no atual. Portanto, a única opção é acessar os resultados das equipes através do número. Por esse motivo, você não pode jogar fora registros / leituras extras da memória em parágrafos vizinhos e substituir as referências de registro do comando read pelo comando do parágrafo anterior.
Aqui vale a pena prestar atenção a uma consequência muito importante: se um parágrafo tiver várias entradas, então
@ 1 no primeiro comando desta seção poderá se referir a resultados completamente diferentes, dependendo de qual parágrafo foi o anterior. O nó Phi é exatamente essa situação. Anteriormente, em todos os blocos básicos que inicializavam o nó phi, os dados eram gravados na mesma célula de memória e, no lugar do nó phi, havia uma leitura dessa célula. Portanto, não era absolutamente importante o local em que havia um registro nessa célula nos parágrafos anteriores, assim como o local em que essa célula foi lida. Se você se livrar do uso da memória - isso muda.
Para permitir que hosts phi usem um switch em vez de memória, o seguinte foi feito:
- Todos os nós phi na unidade base atual são contados (e pode haver vários), são marcados com um número de série e são organizados nesta ordem
- Para cada nó phi, os blocos básicos que o iniciam são ignorados; comandos para carregar os valores no comutador ( loadu_q ), marcados pelo número de série do nó phi correspondente, são adicionados a eles
- A instrução phi do próprio nó também é substituída por loadu_q com seu número de série
- Todos os comandos adicionados são reorganizados na ordem especificada
O quarto ponto é necessário pelo motivo já indicado: se queremos que o comando
loadu_q @ 3 acesse o resultado especificamente para seu nó phi, todos os parágrafos de inicialização do comando que carrega dados no comutador devem estar exatamente na mesma ordem. Vamos dar um exemplo do resultado real da compilação de código no qual existem dois nós phi em uma unidade base.
Parágrafos com nós phi inicializadores:
LBB1_27: LBB1_30: SR4 := loadu_q @1 setjf_l @0, LBB1_31 setjf_l @0, LBB1_31 SR4 := loadu_q [#SP + 8] SR5 := loadu_q [#SP + 16] SR5 := loadu_q [#SP] SR6 := loadu_l 0x1 SR6 := add_l @SR4, 0xffffffff SR7 := add_l @SR6, [@SR4] loadu_q @SR5 wr_l @SR7, @SR4 loadu_q @SR6 loadu_q @SR6 complete loadu_q @SR5 complete
Um parágrafo com dois nós phi:
LBB1_31: SR4 := loadu_q @2 SR5 := loadu_q @2 SR6 := loadu_l [#SP + 124] SR7 := loadu_l [#SP + 120] setjf_l @0, @SR7 setrg_q #RETV, @SR4 wr_l @SR5, @SR6 setrg_q #SP, #SP + 120 complete
Anteriormente, em vez de comandos
loadu_q, haveria gravações na memória e leituras a partir dela.
No processo de implementação dessa otimização, também houve alguns problemas que não foram previstos com antecedência:
- Algumas otimizações de código existentes reorganizam os comandos em alguns locais, por exemplo, colocando o endereço do próximo parágrafo no início do atual, ou o local dos comandos de leitura / gravação de memória no início / final do parágrafo, respectivamente. Essas otimizações ocorrem após operações com nós phi (as chamadas instruções LLVM de abaixamento antes das instruções do processador) e, portanto, frequentemente interrompem a ordem de construção dos comandos loadu_q . Para não atrapalhar o trabalho dessas otimizações, tive que criar uma passagem LLVM separada, que organize os comandos para nós phi na ordem correta, depois de todas as outras manipulações com os comandos.
- Descobriu-se que pode surgir uma situação em que uma unidade base inicializa nós phi para duas unidades base diferentes. Ou seja, seguindo o algoritmo indicado, esses blocos base serão adicionados ao comando de inicialização loadu_q para cada nó phi. Nesse caso, mesmo se eles tiverem apenas um nó phi, na seção de inicialização, haverá 2 comandos loadu_q , que, logicamente, devem estar em último lugar, o que, é claro, é impossível. Felizmente, essas situações são bastante raras; portanto, se existe uma unidade base na qual os nós phi são inicializados para mais de uma outra unidade base, somente o primeiro usa o comutador de acordo com o algoritmo, para o resto - como antes, através da memória.
Toda essa otimização de nós phi pode ser complementada um pouco mais. Por exemplo, se você observar o parágrafo
LBB1_30 acima, poderá ver que os
comandos loadu_q carregam valores que não são usados em nenhum outro lugar. Ou seja, se você remover
loadu_q e configurar os comandos que criam esses valores na mesma ordem, os comandos
loadu_q @ 2 na próxima seção também carregarão os valores corretos.
Benchmarks
Os resultados atuais da otimização foram testados nos benchmarks CoreMark e WhetStone, cuja descrição pode ser encontrada no
artigo anterior . Vamos começar com os resultados do CoreMark no núcleo S2 em comparação com os resultados antigos (versão anterior do compilador no núcleo S1).
Os valores relativos do CoreMark / MHz são mostrados no histograma:

Para obter uma estimativa da aceleração apenas devido à otimização dos nós phi, é possível recalcular o indicador CoreMark em uma multicélula nos núcleos S1 e S2 para uma frequência de 1600 MHz: eles são 1147 e 1224, respectivamente, o que significa um aumento de 6,7%.
Com o WhetStone, a situação é um pouco diferente. As alterações no kernel aqui influenciaram o resultado. Além disso, esse benchmark é executado em um núcleo (multicelular) e é calculado em termos de megahertz, para que a frequência do processador não desempenhe nenhum papel.
Cartão de pontuação da pedra de amolar:
Agora está claro que, mesmo ao usar a versão anterior do compilador no kernel S1, o índice geral é mais alto, principalmente devido aos testes de ponto flutuante MFLOPS1-3. Essa desvantagem foi percebida durante o teste e foi causada pelo fato de o transportador interno do bloco de ponto flutuante em S2, em comparação com S1, ser mais uma etapa. Como resultado, cadeias sucessivas de comandos relacionados a dados perderam uma medida em cada comando. A necessidade dessa etapa foi causada por uma redução na duração do ciclo do clock (um aumento na frequência do processador de 1,6 GHz para 2,5 GHz e um aumento na nomenclatura de comandos, por exemplo, a aparência do comando de multiplicação com o acúmulo de MAC). Esta decisão é temporária. O trabalho para reduzir o comprimento do pipeline está em andamento e, no futuro, isso será corrigido, mas foram realizados testes na versão atual do S2.
Para avaliar a aceleração da otimização do compilador, o WhetStone também foi compilado em uma versão anterior e lançado na versão atual do S2. O indicador total foi de 0,3068 MWIPS / MHz versus 0,3267 MWIPS / MHz no novo compilador, ou seja, que mostra uma aceleração de 6,5% devido às otimizações acima.
O sistema de otimização desenvolvido e testado permite implementar no futuro o próximo esquema de otimização, ou seja, a transferência direta de registros virtuais por meio do comutador. Como já mencionado, nem todas as cópias do registro virtual podem ser feitas através do switch. Devido ao tamanho limitado do comutador e à incapacidade de acessar corretamente os resultados dos parágrafos anteriores, se houver vários pontos de entrada para o atual (isso é parcialmente resolvido por nós phi), a única opção possível é copiar registros virtuais de um parágrafo diretamente para o próximo, mas há apenas um anterior . Esses casos, de fato, não são tão poucos, muitas vezes é necessário transferir dados tão diretamente, embora a aceleração do código que ele dará a dizer com antecedência seja, obviamente, difícil.