Mais cedo ou mais tarde, qualquer serviço em crescimento precisa avaliar suas capacidades técnicas. Quantos visitantes podemos servir? Qual é a capacidade do sistema? Atingimos o limite e não cairemos se atrairmos vários milhares de usuários? Quantos recursos de computação adicionais estão orçados para o próximo ano para atender aos planos de crescimento?
As respostas podem ser obtidas analiticamente, endereçando perguntas a um desenvolvedor experiente / DevOps / SRE / admin. A confiabilidade da avaliação depende de um grande número de fatores: começando pelo ritmo de preenchimento do sistema com funcionalidade e pelo gráfico das relações entre os componentes e terminando com o tempo que o especialista passou a manhã no trânsito. Quanto mais complexo o sistema, maior a dúvida sobre a adequação da avaliação analítica.
Meu nome é Maxim Kupriyanov, há cinco anos que trabalho na Yandex.Market. Hoje vou contar aos leitores da Habr como aprendemos a avaliar a capacidade de nossos serviços e o que resultou dele.
Vamos para a posição
Como a estrutura dos componentes do mercado é bastante complicada, decidimos avaliar a capacidade de dimensionar apenas os serviços maiores e mais caros. Além disso, o número diário de solicitações para eles deve depender claramente do tamanho do público diário do mercado (usuários ativos diários, DAU). Por que exatamente da DAU? Como os analistas, fazendo previsões para os próximos meses e anos, sempre calculam o tamanho futuro da audiência, e tiraremos proveito dessa circunstância agradável.
Agora vamos falar sobre o qual é impossível criar avaliações objetivas: sobre as métricas do serviço. Se o número de solicitações de serviço depender da DAU, definitivamente precisaremos da métrica "solicitações por segundo" (solicitações por segundo, RPS). Além disso, para avaliar a qualidade do serviço, você precisa conhecer a porcentagem de erros e tempos de resposta (tempos de solicitação). O erro será considerado uma resposta com um código HTTP de 500 ou superior. Os erros do intervalo 4xx são do lado do cliente e, em um sistema normalmente funcionando, geralmente não dizem nada sobre problemas de serviço. Quanto aos horários, é habitual calcular e armazenar os percentis 80, 95, 99 e 99,9 de tempos de resposta, mas um conjunto específico pode diferir ligeiramente de serviço para serviço.
Portanto, temos métricas de frequência de solicitação, porcentagem de erros e um conjunto de percentis de tempo de resposta. E também sabemos o serviço DAU para todos os dias e períodos futuros (na forma de uma previsão). Dado que os padrões médios de comportamento do usuário não mudam muito a cada dia, digamos o seguinte: conhecendo o RPS no período mais ativo do dia útil (RPS de pico), podemos prever o RPS de pico para períodos futuros, desde que tenhamos uma previsão da DAU. E vice-versa: se sabemos quantas solicitações por segundo o sistema pode suportar sem violar o acordo sobre o tempo de resposta e a porcentagem de erros, podemos estimar quanto público podemos atender, ou seja, sabemos a capacidade do sistema.
Bem, decidimos a tarefa: fixar os tempos de resposta e a porcentagem de erros na forma de acordos e encontrar o RPS máximo que o sistema pode suportar nessas condições. Como vamos decidir?
Atiramos no alvo
Aqui está uma abordagem clássica para resolver o problema: coletamos um site de teste, pegamos os logs de acesso ao sistema no ambiente de produção, fabricamos cartuchos e acionamos o sistema, aumentando a frequência das solicitações, até que o site mostre degradação significativa nos tempos de resposta e / ou erros. Nesse ponto, paramos e corrigimos a frequência das solicitações (o mesmo RPS). Vitória Não importa como. E aqui está o porquê:
- o site de teste, como regra, não é idêntico à plataforma sob o serviço no ambiente de produção;
- o código de serviço muda todos os dias ou com mais frequência;
- experimentos podem influenciar a carga;
- a gravidade das solicitações do usuário depende da hora do dia e de outras condições;
- serviços modernos raramente funcionam isoladamente, mais frequentemente fazem subconsultas a outros serviços, e isso terá que ser levado em consideração de alguma forma.
Melhoria: lançaremos o serviço automaticamente todos os dias, coletando cartuchos de revistas nos horários de pico. E, para não desperdiçar recursos em um local de teste, começaremos a descascar componentes de interesse para nós do mesmo lado. Parece complicado e não resolve todos os problemas. Mas que outras opções existem?
Simule a realidade
A ideia geral é a seguinte: copiamos parte do tráfego dos balanceadores para o local, onde coletamos o análogo completo do ambiente de produção em miniatura e, ajustando o volume do tráfego copiado, procuramos o ponto de degradação. A idéia é linda e nós, no mercado, fazemos isso para testar novas funcionalidades e comparar o comportamento de novas versões com as antigas. Meu colega Eugene
falou sobre isso em detalhes - veja a seção sobre o cluster de sombras. Mas também existem dificuldades óbvias:
- o problema de interagir com componentes externos não é resolvido, pois é muito caro fazer uma cópia de todo o ambiente de produção;
- os logs de solicitação do sistema de espelhos podem acidentalmente se misturar com os logs do ambiente de produção, o que significa que é necessário criar um sistema com marcação do tráfego de espelhos para que ele possa ser encontrado e limpo;
- as solicitações geralmente são espelhadas na totalidade ou em porcentagem do total, e essa precisão não nos convém (mas isso pode ser resolvido, estamos trabalhando nessa direção).
Em geral, a imitação da produção é uma abordagem muito boa e promissora, mas muito cara e com limitações significativas.
Testando diretamente na produção
E então finalmente chegamos ao delicioso. Para cada componente testado, criamos uma instância separada na produção, cuja frequência de solicitações é regulada a partir do balanceador com alta precisão. Na última vez, os
leitores nos perguntaram : “O HAProxy é suficiente para você? Havia necessidade de escrever algo seu? Portanto, este é um caso muito raro, quando não foi suficiente e eu tive que escrever.
Ao mesmo tempo, existe um serviço separado que monitora de perto as métricas da instância carregada e, quando os indicadores se aproximam de valores críticos, fecha a válvula no balanceador, reduzindo a frequência de solicitações. Se o serviço funcionar dentro de limites aceitáveis, a válvula, pelo contrário, abre. Obviamente, os limites para tempos e erros ao carregar um serviço ao vivo são notavelmente mais conservadores (geralmente de 5 a 10%) do que no campo de treinamento, porque não queremos piorar a interação com os usuários. Assim, a instância carregada sempre funciona até o limite. Nós corrigimos esses indicadores. E então temos aritmética: sabemos o número de núcleos de serviço sob carga a cada momento, conhecemos a DAU ontem. A partir disso, consideramos opções de reciclagem, reservas de capacidade e comportamento do sistema ao desativar um ou outro local. Tudo isso estabelece na base de onde são criados belos gráficos. Com base nesses dados, quando a capacidade cai abaixo do limite, os alertas são acionados.
Vejamos os gráficos
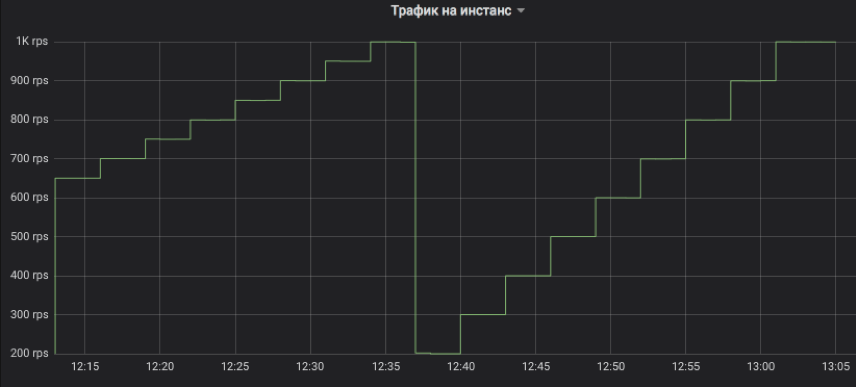
É assim que controlamos o fluxo de tráfego para a instância testada. A etapa pode ser qualquer múltiplo de 1 RPS. No gráfico, para ilustração, modelamos uma subida com um intervalo de três minutos: primeiro, de 650 a 1K RPS em incrementos de 50 e, em seguida, de 200 a 1K RPS em incrementos de 100. Deixe-me lembrá-lo de que é o tráfego real do usuário ao qual os clientes receberam respostas.
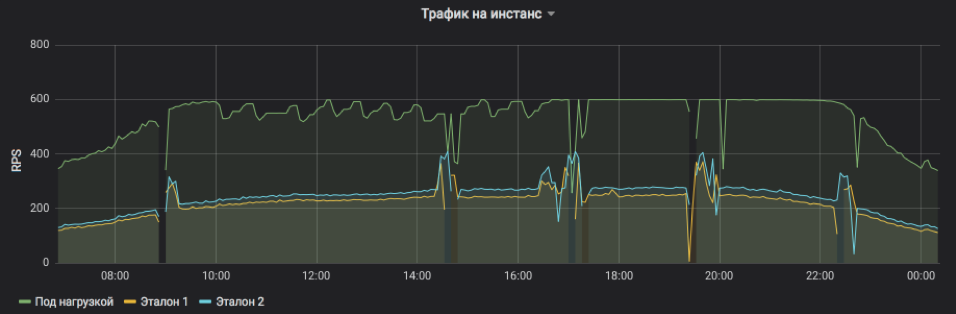
Isso mostra o RPS para três instâncias: uma sob carga e duas sob controle. O sujeito foi artificialmente definido um limite superior de 600 RPS. O serviço pode ser mais, mas se torna instável demais e depende de influências externas. Vê-se claramente que, na primeira metade do dia, as solicitações de serviço são, em média, mais pesadas e a instância não pode atingir sua capacidade máxima em condições aceitáveis, mas, no final da tarde, tudo volta ao normal. Bursts e omissões no gráfico são instâncias de reinicialização para distribuir lançamentos e outras atualizações (todos estão em equilíbrio, ninguém foi ferido). E os ajustes passo a passo do RPS no assunto do teste são apenas o trabalho de um algoritmo que busca o limite de possibilidades.

A frequência das solicitações de serviço e a carga que uma instância pode suportar são claramente visíveis.
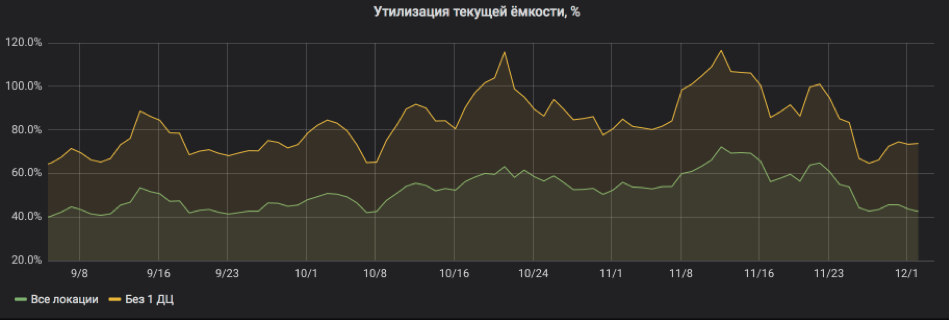
E aqui recalculamos tudo em porcentagem de utilização. O gráfico mostra que o serviço estava muito carregado e quando um dos locais foi desativado, havia riscos de sair para o SLA. Mas agora está tudo bem: recursos foram adicionados ao serviço, a reciclagem voltou a limites aceitáveis.
Assim, o teste de carga na produção permite avaliar rapidamente a capacidade do sistema e prever o consumo de recursos para períodos futuros. Ao mesmo tempo, o sistema não adiciona despesas consideráveis e você pode trabalhar com segurança com serviços com estado, uma vez que não geramos novo tráfego, mas apenas redistribuímos com precisão o que é. E finalmente: para funcionar, como regra, não é necessário alterar o código do próprio sistema experimental, o que permite testar até aplicativos legados.
Refletir
Essa metodologia não atua no mercado há mais de um ano, e podemos compartilhar observações e recomendações:
- Ao lado da instância carregada, deve haver um controle comum e, de preferência, vapor, pois a degradação geralmente ocorre não porque a instância está sobrecarregada, mas devido a problemas gerais com o serviço como um todo.
- A técnica funciona bem apenas com os componentes cuja carga é superior a centenas de solicitações por segundo para um local. O motivo é bem simples: precisamos carregar a instância testada e uma ou duas de controle. Se não houver tráfego suficiente, não alcançaremos a saturação ou não poderemos comparar honestamente. E se o RPS limite por instância for muito pequeno, a etapa mínima para alterar a frequência da solicitação para 1 RPS pode ser muito difícil.
- É melhor testar frentes e back-ends em locais diferentes, para que artefatos de back-end de teste de carga não afetem a estimativa da capacidade frontal.
- Quando analisamos os tempos de resposta e procuramos sinais de degradação, geralmente utilizamos agregados de cinco minutos e contamos a mediana para não reagir a explosões aleatórias.
- O principal motivo pelo qual a instância carregada do serviço falha é o espaço em disco para arquivos de log (logs). Eles sempre esquecem dele.
- O registro no disco de servidores da Web carregado com E / S é um motivo muito comum para agravar os tempos, mesmo em SSDs. Sempre ative o buffer, a gravação assíncrona e qualquer outra coisa, apenas para não esperar até que a gravação termine.
- A carga noturna não é indicativa, pois os pedidos são, em média, mais pesados devido à maior participação de robôs. Portanto, para estimar a capacidade, é melhor fixar o intervalo da hora do dia convencionalmente leve e à noite apenas para reduzir o fluxo de solicitações se aparecerem sinais de degradação.
- O percentil 99,9º de tempos de resposta é inútil para a estimativa de capacidade, pois as garantias de disponibilidade da rede raramente excedem 99%.
- Inicie uma linha do tempo e grave lançamentos de serviço e outros eventos significativos. Ajuda a encontrar o que levou a uma diminuição da capacidade.
- Em uma análise detalhada das causas da degradação, o rastreamento também é útil: um cabeçalho de marcador é adicionado a cada solicitação de serviço, que vai da frente até o último back-end e entra em todos os logs. Dessa forma, você pode rastrear todo o caminho da solicitação e entender o que causa atrasos.