O Python entende todos os formatos de arquivo populares. Além disso, cada biblioteca possui seu próprio formato de "tubo quente". A sintaxe, é claro, em cada formato é puramente individual. Reuni todas as funções para trabalhar com arquivos de diferentes formatos em uma folha A4, com o aplicativo como exemplo de uso no notebook jupyter.
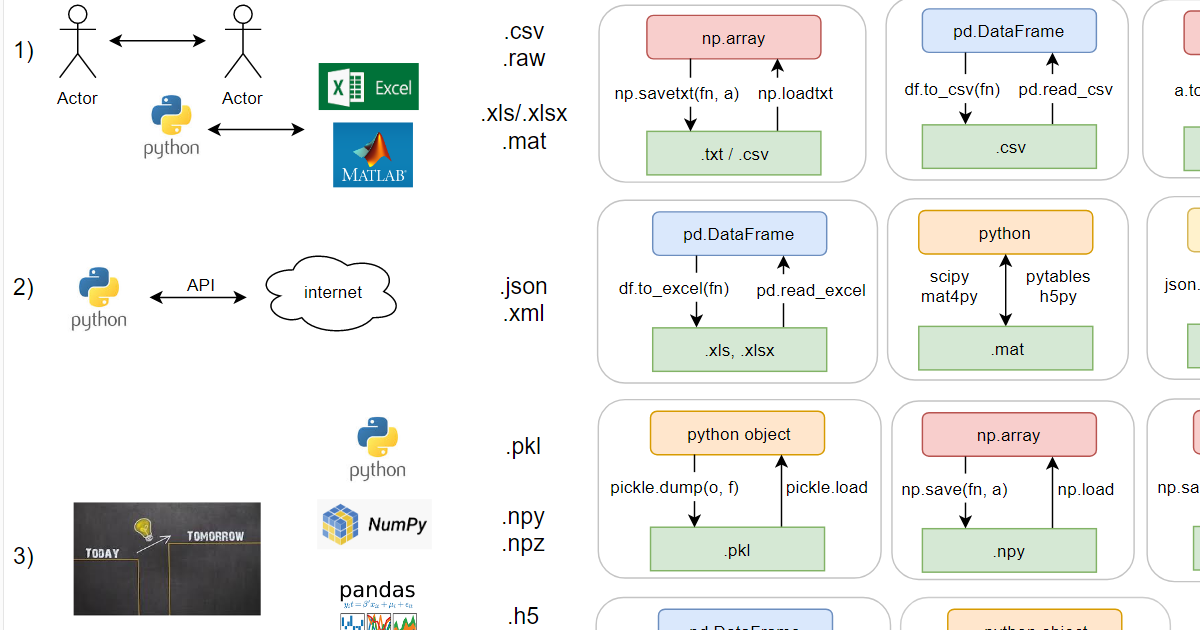
Dividi condicionalmente os formatos em três blocos, de acordo com o método de uso. Como você sabe, são necessários arquivos para a troca de informações: entre pessoas, entre programas (primeiro bloco), entre um computador e uma rede (segundo) e "salvar jogo" - entre o mesmo programa em diferentes momentos (terceiro bloco).
Brevemente sobre cada bloco:
1) Formatos universais:
- .csv - texto, valores separados em princípio por vírgula, mas por exemplo, o exel russo prefere separá-lo com ponto e vírgula, pois a vírgula já é usada no código do idioma russo como separador decimal;
- .raw é um formato binário para quem não gosta de formatos de arquivo. O tipo de dado e, se os dados forem multidimensionais, os tamanhos correspondentes deverão ser transferidos separadamente, apenas os dados no arquivo;
- .xls / .xlsx - o antigo binário (limitação de 65k linhas) e os novos formatos xml exel;
- Na verdade, o .mat também possui dois formatos (ambos binários): o antigo proprietário e o novo baseado no hdf5. Python pode trabalhar com ambos (através de bibliotecas).
2) Formatos "Rede":
- .json - textual, parece um dicionário em python, mas as aspas podem ser usadas apenas duas vezes;
- .xml - textual, semelhante ao html.
3) Formatos python nativos:
- .pkl é um formato binário, todos os objetos Python integrados podem salvar nele. Classes personalizadas também são capazes e, se o python salvar algo errado, você poderá ajudá-lo através de métodos mágicos. Suporta anexar ao final de um arquivo existente.
- .npy e .npz - em numpy, existem até dois de seus formatos (ambos binários). Eles apareceram como uma reação à perda de compatibilidade com versões anteriores em pkl no momento da transição python v2-> v3. A sobrecarga é mínima (~ 100 bytes a mais do que o raw correspondente; pkl, no entanto, é um pouco maior: ~ 150 bytes a mais do que o raw). No .npy, você pode salvar apenas uma matriz e em npz - várias ao mesmo tempo e, posteriormente, removê-las pelo nome.
- .h5 - formato binário hdf5. Vale ressaltar que você pode armazenar toda uma estrutura hierárquica de dados, é praticamente um sistema de arquivos em um arquivo. Além disso, ele pode ser aberto no matlab sem conversão. Contras:
a) arquivos pequenos ocupam espaço excessivamente grande (por exemplo, 300 bytes pkl vs 3,1 Mb para h5),
b) muitos bugs ,
c) existe um anexo em um arquivo existente, mas se ocorrer um erro (como acontece), obter dados a partir dele será problemático.
Aqui está uma análise detalhada dos prós e contras do hdf5, em resumo - um bom formato para troca de dados, ruim - para uso como sistema de arquivos (por exemplo, você não pode apagar uma matriz, apenas copie o arquivo sem ela). - .parquet é um formato binário para big data. O Apache Parquet não é um formato Python nativo, mas está bem integrado aos pandas. Você pode compactar / expandir rapidamente (rle, gzip, codificação de dicionário); comprime um pouco melhor que o Apache Avro. Ao contrário do avro, onde os dados são armazenados linha por linha (como a ordem C), no parquet, os dados são armazenados coluna por coluna (como a ordem fortran). Graças a isso, você pode trabalhar efetivamente com tabelas com um grande número de colunas.
- O jupyter decidiu não reinventar a roda - o% store o salva no formato .pkl, mas por algum motivo sem extensão.
Sheatsheet em si:
- em formato
pdf- em formato png:

Um exemplo de uso de todas as funções de um diagrama:
html com sumário e fonte ipynb