O processamento da linguagem natural remonta aos místicos da Cabala
Muito antes de o processamento da linguagem natural se tornar um tópico importante no campo da inteligência artificial, as pessoas criaram regras e máquinas para manipular a linguagem
 Místico do século XIII Abraham bin Samuel Abulafia inventou o campo do processamento de linguagem natural iniciando a prática de combinar letras
Místico do século XIII Abraham bin Samuel Abulafia inventou o campo do processamento de linguagem natural iniciando a prática de combinar letrasAgora, estamos no auge do interesse no processamento de linguagem natural (PNL) - um campo da ciência da computação que se concentra na interação linguística entre homem e máquina. Graças às inovações no aprendizado de máquina (MO) na última década, estamos vendo uma grande melhoria no reconhecimento de fala e tradução automática. Os geradores de idiomas já são bons o suficiente para escrever artigos de notícias coerentes, e assistentes virtuais como Siri e Alexa estão se tornando parte de nossas vidas diárias.
A maioria dos historiadores rastreia as origens dessa área até o início da era dos computadores, quando Alan Turing, em 1950, descreveu uma máquina inteligente que pode interagir facilmente com uma pessoa através de texto na tela. Portanto, a linguagem gerada pelas máquinas geralmente é imaginada como um fenômeno digital - assim como o principal objetivo do desenvolvimento da inteligência artificial (IA).
Neste artigo, tentaremos refutar essa noção geralmente aceita de PNL. De fato, tentativas de desenvolver regras e máquinas formais capazes de analisar, processar e criar uma linguagem foram feitas várias centenas de anos atrás.
Tecnologias específicas mudaram ao longo do tempo, mas a idéia principal de considerar a linguagem como um material que pode ser manipulado artificialmente com base em um sistema de regras foi explorada por muitas pessoas em muitas culturas e por várias razões. Esses experimentos históricos mostram as possibilidades e os perigos de tentar simular a linguagem humana sem intervenção humana - e também fornecem lições para os profissionais de hoje das técnicas avançadas de PNL.
Esta história se origina na Espanha medieval. No final do século XIII, um místico judeu chamado
Abraham bin Samuel Abulafia sentou-se à mesa de sua casa em Barcelona, pegou uma caneta, mergulhou-a em tinta e começou a combinar as letras do
alfabeto hebraico de maneiras estranhas e, à primeira vista, aleatórias. Alef com aposta, aposta com gimel, gimel com alef e aposta, e assim por diante.
Abulafia chamou essa prática de "a ciência da combinação de letras". De fato, ele combinou cartas de maneira não aleatória; ele seguiu cuidadosamente um conjunto secreto de regras que havia desenvolvido enquanto estudava um antigo texto
cabalístico chamado "
Sepher Yetzirah ". O livro descreve como Deus criou "tudo o que tem uma forma e tudo o que é dito", combinando letras hebraicas de acordo com fórmulas sagradas. Em uma seção, Deus passa por todas as combinações possíveis de duas letras com 22 letras do alfabeto.
Estudando Sefer Yetzirah, Abulafia teve a idéia de que símbolos lingüísticos podem ser manipulados de acordo com regras formais para criar frases novas, interessantes e cheias de idéias. Para esse fim, por vários meses ele gerou milhares de combinações de 22 letras do alfabeto hebraico e, como resultado, escreveu vários livros, que ele alegou serem dotados de sabedoria profética.
Para Abulafia, a geração da linguagem de acordo com as regras divinas deu uma idéia do sagrado e do desconhecido, ou, como ele próprio escreveu, permitiu-lhe "entender coisas que, segundo a tradição humana, ou o homem sozinho não podiam saber".
No entanto, outros estudiosos judeus consideraram essa geração de linguagem rudimentar um ato perigoso, próximo à blasfêmia. No
Talmude, são contadas histórias sobre os rabinos, que mudaram magicamente o idioma de acordo com as fórmulas descritas em "Sepher Yetzirah", criaram criaturas artificiais,
golens . Nessas histórias, os rabinos manipularam as letras da língua hebraica para recriar os atos divinos da criação, usando fórmulas sagradas para dotar objetos sem vida.
Em alguns desses mitos, os rabinos usavam essa habilidade para fins práticos, criando animais para alimentar quando queriam comer, ou criados para ajudar nas tarefas domésticas. Mas muitas dessas histórias de golem terminam mal. Em um dos famosos contos de fadas,
Yehuda Liva bin Betzalel (conhecido como Maharal de Praga), um rabino que viveu em Praga no século 16, usou a prática sagrada de combinar cartas para chamar um golem para proteger a comunidade judaica de ataques anti-semitas, mas no final esse golem se voltou contra seu criador.
Essa "ciência da combinação de letras" era uma forma rudimentar de processamento de linguagem natural, uma vez que incluía a combinação das letras do alfabeto hebraico de acordo com regras especiais. Para os cabalistas, essa era uma faca de dois gumes: tanto uma maneira de obter novas formas de conhecimento e sabedoria quanto uma prática perigosa que poderia levar a graves conseqüências não intencionais.
Essa tensão persistiu ao longo da longa história do processamento de linguagem e ainda responde a discussões sobre as mais avançadas tecnologias de PNL em nossa era digital.
No século XVII, Leibniz sonhava com uma máquina capaz de contar idéias.
A máquina deveria usar o "alfabeto dos pensamentos humanos" e as regras para combiná-los
 Gottfried Wilhelm Leibniz no fundo das páginas de sua dissertação "Sobre a arte da combinatória"
Gottfried Wilhelm Leibniz no fundo das páginas de sua dissertação "Sobre a arte da combinatória"Em 1666, o estudioso alemão
Gottfried Wilhelm Leibniz publicou uma dissertação misteriosa intitulada "
Sobre a arte da combinatória ". Com apenas 20 anos, mas já pensando bastante, Leibniz descreveu a teoria da produção automática de conhecimento com base em uma combinação de caracteres criados de acordo com certas regras.
O principal argumento de Leibniz era que todos os pensamentos humanos, independentemente de sua complexidade, são combinações de conceitos básicos e fundamentais, bem como frases são combinações de palavras e palavras são combinações de letras. Ele acreditava que, se conseguisse encontrar uma maneira de representar simbolicamente esses conceitos fundamentais e desenvolver um método pelo qual eles pudessem ser combinados logicamente, ele seria capaz de criar novos pensamentos, conforme necessário.
Essa idéia veio à mente de Leibniz enquanto estudava as obras de
Raimund Lullius , um místico de Mallorca, que viveu no século 13, que dedicou sua vida a criar um sistema de raciocínio teológico que pudesse provar a "verdade universal" do cristianismo a todos os incrédulos.
O próprio Lullius foi inspirado pela combinação das cartas dos cabalistas judeus, que eles usavam para criar textos gerados que supostamente revelavam sabedoria profética. Desenvolvendo essa idéia ainda mais, Lullius inventou o que chamou de "
Volwell "
, um mecanismo de papel circular com círculos concêntricos gradualmente decrescentes nos quais símbolos que representam os atributos de Deus foram escritos. Lullius acreditava que girando um poço de várias maneiras e gerando novas combinações de símbolos entre si, ele poderia descobrir todos os aspectos de sua divindade.
Leibniz ficou impressionado com a máquina de papel de Lullia e decidiu criar seu próprio método de gerar idéias através de combinações de símbolos. Mas ele queria usar o carro não para debate teológico, mas para fins filosóficos. Ele sugeriu que esse sistema exigiria três coisas: o "alfabeto dos pensamentos humanos"; uma lista de regras lógicas para sua combinação válida; e um mecanismo capaz de executar operações lógicas com esses símbolos com rapidez e precisão - uma atualização completamente mecânica da volvella de papel Lullia.
Ele imaginou que essa máquina, que ele chamou de "grande ferramenta de raciocínio", seria capaz de responder a todas as perguntas e resolver qualquer disputa intelectual. "Quando surge uma disputa entre as pessoas", ele escreveu, "podemos simplesmente dizer" vamos calcular "e ver imediatamente quem está certo".
A ideia de um mecanismo que produz pensamentos racionais correspondia ao espírito do tempo de Leibniz. Outros pensadores
do Iluminismo , como René Descartes, acreditavam na existência de uma "verdade universal" que poderia ser desenterrada usando apenas o raciocínio lógico, e que todos os fenômenos poderiam ser totalmente explicados, entendendo os princípios subjacentes a eles. Leibniz acreditava que o mesmo se aplicava à linguagem e à própria consciência.
Mas muitos outros consideraram essa doutrina da razão pura como profundamente errônea e a consideraram um sinal de uma nova era de sermões sofisticados. Um desses críticos foi o autor e satirista Jonathan Swift, que percorreu a máquina de contagem de Leibniz em seu livro de 1726, As Viagens de Gulliver. Em uma cena, Gulliver acaba na Grand Academy de Lagado, onde encontra um mecanismo estranho chamado "máquina". Esta máquina possui um esqueleto de madeira grande com uma treliça de cabos esticados. Nos cabos há pequenos cubos de madeira, em cada lado dos quais existem símbolos.
Os alunos da academia torcem as alças na lateral da máquina, o que faz os blocos de madeira girarem e produzem novas combinações de caracteres. Em seguida, o escriba escreve o que a máquina distribuiu e o entrega ao professor presidente. O professor afirma que dessa maneira ele e seus alunos podem "escrever livros sobre filosofia, poesia, política, direito, matemática e teologia sem nenhum talento ou treinamento".
Essa cena da geração da linguagem anterior à era digital era a paródia de Swift da geração do pensamento de Leibniz através de uma combinação de símbolos - e, mais geralmente, um argumento contra a superioridade da ciência. Como outras tentativas da Academia Lagado de melhorar o desenvolvimento de seu povo por meio de pesquisas - como tentativas de transformar excremento humano em comida - a máquina parece para Gulliver um experimento sem sentido.
Swift queria dizer que a linguagem não é um sistema formal de representação dos pensamentos humanos, como Leibniz acreditava, mas uma forma caótica e ambígua de sua expressão, que só faz sentido no contexto em que é usada. Swift argumentou que a geração de linguagem precisava não apenas de um conjunto de regras e de uma máquina adequada, mas também da capacidade de entender o significado das palavras, o que nem a máquina de Lagado nem a "ferramenta de raciocínio" de Leibniz poderiam fazer.
Como resultado, Leibniz nunca construiu seu carro para gerar idéias. Ele abandonou completamente o estudo da combinatória de Lullius e mais tarde reconheceu as tentativas de mecanizar a linguagem como imatura. No entanto, ele não abandonou a idéia de usar dispositivos mecânicos para executar funções lógicas, e isso o inspirou a criar uma "
calculadora passo a passo "
, uma calculadora mecânica construída em 1673.
No entanto, o debate de hoje entre cientistas da computação que estão desenvolvendo algoritmos cada vez mais avançados para PNL reflete as idéias de Leibniz e Swift: mesmo que seja possível criar um sistema formal que gere uma linguagem semelhante à humana, ele pode ser dotado da capacidade de entender o que produz?
Andrei Markov e Claude Shannon contaram cartas para construir os primeiros modelos de geração de linguagem
O modelo de Shannon disse: "OCRO HLI RGWR NMIELWIS"
 O matemático russo Andrei Andreevich Markov no contexto de sua análise estatística do poema de Alexander Sergeyevich Pushkin "Eugene Onegin"
O matemático russo Andrei Andreevich Markov no contexto de sua análise estatística do poema de Alexander Sergeyevich Pushkin "Eugene Onegin"Em 1913, o matemático russo
Andrei Andreevich Markov sentou-se em seu escritório em São Petersburgo com uma cópia do poema do século XIX de A. S. Pushkin "Eugene Onegin", na época um ex-clássico da literatura. No entanto, Markov não leu o famoso texto de Pushkin. Em vez disso, ele pegou uma caneta e um papel de desenho e escreveu as primeiras 20.000 letras do livro em uma longa linha de letras, omitindo todos os espaços e sinais de pontuação. Depois, reorganizou essas letras em 200 treliças (10x10 caracteres cada) e começou a contar os sons das vogais em cada linha e coluna, registrando os resultados.
Para um observador externo, o comportamento de Markov teria parecido estranho. Por que alguém desmontaria o trabalho de um gênio literário de tal maneira, transformando-o em algo incompreensível? Mas Markov não leu este livro para aprender mais sobre a natureza do homem e da vida; ele procurou estruturas matemáticas fundamentais no texto.
Separando vogais de consoantes, Markov verificou a teoria das probabilidades desenvolvida por ele desde 1909. Até então, a teoria das probabilidades limitava-se principalmente à análise de fenômenos como roleta ou troca de moedas, quando o resultado de eventos anteriores não afeta a probabilidade do atual. Mas Markov acreditava que a maioria dos fenômenos ocorre ao longo de uma cadeia de causas e depende de resultados anteriores. Ele queria encontrar uma maneira de modelar esses eventos através da análise probabilística.
Markov acreditava que a linguagem era um exemplo de sistema em que eventos anteriores determinam parcialmente os atuais. Para demonstrar isso, ele queria mostrar que em um texto, por exemplo, no poema de Pushkin, a probabilidade de uma determinada letra aparecer em um determinado local do texto depende, em certa medida, de qual carta estava antes dela.
Para fazer isso, Markov começou a contar as vogais em Eugene Onegin e descobriu que 43% das cartas eram vogais, 57% - consoantes. Markov então dividiu 20.000 letras em pares de combinações de vogais e consoantes. Ele encontrou 1104 pares de duas vogais, 3827 pares de consoantes e 15069 pares de consoantes de vogais ou consoantes de vogais. Do ponto de vista estatístico, isso significava que, para qualquer letra do texto de Pushkin, a regra era cumprida: se fosse uma vogal, provavelmente uma consoante ficaria atrás dela e vice-versa.
Markov usou essa análise para mostrar que "Eugene Onegin" de Pushkin não era apenas uma distribuição aleatória de letras, mas tinha certas qualidades estatísticas que podiam ser modeladas. O misterioso
trabalho de pesquisa que completou este estudo foi intitulado "Um Exemplo de Estudo Estatístico do Texto de Eugene Onegin, Ilustrando o Elo de Julgamentos em Cadeia". Ela raramente foi citada durante a vida de Markov e só foi traduzida para o inglês em 2006. No entanto, alguns de seus conceitos básicos relacionados à probabilidade e à linguagem se espalharam por todo o mundo e, como resultado, foram reeditados no trabalho extremamente influente de
Claude Shannon, “A
Teoria Matemática da Comunicação ”, publicado em 1948.
O trabalho de Shannon descreveu uma maneira de medir com precisão o conteúdo quantitativo da informação em uma mensagem e, assim, lançou os fundamentos de uma teoria da informação que posteriormente definiria a era digital. Shannon ficou encantado com a ideia de Markov de que em um determinado texto a probabilidade de uma determinada letra ou palavra pode ser estimada. Como Markov, Shannon demonstrou isso conduzindo experimentos de texto envolvendo a criação de um modelo estatístico da linguagem e depois desenvolveu essa idéia, tentando usar esse modelo para gerar texto de acordo com essas regras estatísticas.
No primeiro experimento controlado, ele começou gerando uma frase, escolhendo aleatoriamente letras de um alfabeto de 27 caracteres (26 letras latinas e um espaço) e recebeu o seguinte:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
A proposta acabou sendo um barulho inútil, disse Shannon, porque ao se comunicar não escolhemos letras com igual probabilidade. Como Markov mostrou, as consoantes têm uma maior probabilidade de ocorrência do que as vogais. Mas se olharmos mais longe, a letra E é mais comum que S e, por sua vez, é mais comum que Q. Para levar tudo isso em consideração, Shannon corrigiu o alfabeto original para simular melhor o idioma inglês - a probabilidade de obter a letra E estava em 11% a mais do que extrair a letra Q. Quando ele começou a selecionar aleatoriamente letras da lista reconfigurada, recebeu uma oferta que parecia um pouco mais com o inglês.
OCRO HLI RGWR NMIELWIS EU LL NBNESEBYA TH EEI ALHENHTTPA OOBTTVA NAH BRL
Em experimentos subsequentes, Shannon mostrou que, com mais complicações do modelo estatístico, resultados mais significativos podem ser obtidos. Como Markov, Shannon criou uma plataforma estatística para o idioma inglês e mostrou que, ao modelar essa plataforma - analisando as probabilidades dependentes de letras e palavras em combinações entre si - você pode gerar um idioma.
Quanto mais complexo o modelo estatístico do texto, mais precisa é a geração do idioma - ou, como Shannon escreveu, mais "se assemelha a um texto comum em inglês". No último experimento, Shannon pegou as palavras da lista em vez de as letras e obteve o seguinte:
A CABEÇA E O ATAQUE FRONTAL EM UM ESCRITOR INGLÊS DE QUE O CARÁTER DESTE PONTO É, POR ISSO, OUTRO MÉTODO PARA AS CARTAS QUE, NA HORA DE QUEM DIZER O PROBLEMA PARA UM INESPERADO
[
aproximadamente “CABEÇA E NO ATAQUE DIANTEIRO NO ESCRITOR INGLÊS, DO QUE O CARÁTER DESTE PONTO, CONSEQÜENTEMENTE, UM MÉTODO DIFERENTE PARA CARTAS, DAQUELA VEZ ALGO QUE ALGO SOBREVIVERU PARA ALGO” palavras / aprox. perev. ]
Tanto Shannon quanto Markov acreditavam que, ao entender que as propriedades estatísticas de uma linguagem podem ser modeladas, é possível repensar tarefas mais gerais.
Isso ajudou Markov a expandir a pesquisa no campo da
estocástica além dos limites de eventos independentes, abrindo caminho para uma nova abordagem na teoria das probabilidades. Isso ajudou Shannon a formular uma maneira precisa de medir e codificar unidades de informação em uma mensagem, que revolucionou as telecomunicações e, finalmente, as comunicações digitais. No entanto, sua abordagem estatística para modelagem e geração de linguagem também acelerou o advento da era da PNL, que se desenvolveu ao longo da era digital.
Por que as pessoas exigem privacidade em conversas privadas com o primeiro chatbot do mundo
Em 1966, o programa Eliza poderia dizer pouco, mas isso foi o suficiente
 O cientista da computação Joseph Weizenbaum com seu chatbot, Eliza, rodando no mainframe IBM 7094 de 36 bitsDe 1964 a 1966, Joseph Weizenbaum , um cientista da computação americano de ascendência alemã que trabalhou no laboratório de IA do MIT, desenvolveu o primeiro chatbot do mundo .Embora naquela época já existissem vários geradores rudimentares de linguagem digital - programas que poderiam produzir mais ou menos linhas de texto conectadas - o programa Weizenbaum foi o primeiro projetado especificamente para a comunicação com as pessoas. O usuário pode inserir uma determinada declaração ou um conjunto de declarações em um idioma comum, pressionar "enter" e receber uma resposta da máquina. Como Weizenbaum explicou, seu programa "possibilitou um certo tipo de conversa entre uma pessoa e um computador em uma linguagem natural".Ele nomeou o programa Eliza em homenagem a Eliza Dolittle., a heroína da peça de Bernard Shaw, Pygmalion, representante da classe trabalhadora que aprendeu a falar com sotaque de representantes da classe alta. Eliza foi escrito para o IBM 7094 de 36 bits, um dos principais mainframes de transistor, em uma linguagem de programação desenvolvida pelo próprio Weizenbaum, MAD-SLIP.Como o tempo do computador era caro, o Eliza só podia ser executado em um sistema de compartilhamento de tempo. O usuário interagiu com o programa remotamente usando uma máquina de escrever e impressora elétricas. Quando um usuário digitou uma frase e pressionou "enter", a mensagem foi enviada ao mainframe. "Eliza" examinou a mensagem quanto à presença de palavras-chave e as usou em novas frases, formando uma resposta que foi enviada de volta e impressa para que o usuário pudesse lê-la.Para incentivar o diálogo contínuo, Weizenbaum prescreveu uma simulação de conversa típica do psicanalista Rogers em Eliza . O programa pegou o que o usuário disse e o reformulou como uma pergunta (observe como o programa pega palavras como "cara" e "depressão" e as usa novamente).
O cientista da computação Joseph Weizenbaum com seu chatbot, Eliza, rodando no mainframe IBM 7094 de 36 bitsDe 1964 a 1966, Joseph Weizenbaum , um cientista da computação americano de ascendência alemã que trabalhou no laboratório de IA do MIT, desenvolveu o primeiro chatbot do mundo .Embora naquela época já existissem vários geradores rudimentares de linguagem digital - programas que poderiam produzir mais ou menos linhas de texto conectadas - o programa Weizenbaum foi o primeiro projetado especificamente para a comunicação com as pessoas. O usuário pode inserir uma determinada declaração ou um conjunto de declarações em um idioma comum, pressionar "enter" e receber uma resposta da máquina. Como Weizenbaum explicou, seu programa "possibilitou um certo tipo de conversa entre uma pessoa e um computador em uma linguagem natural".Ele nomeou o programa Eliza em homenagem a Eliza Dolittle., a heroína da peça de Bernard Shaw, Pygmalion, representante da classe trabalhadora que aprendeu a falar com sotaque de representantes da classe alta. Eliza foi escrito para o IBM 7094 de 36 bits, um dos principais mainframes de transistor, em uma linguagem de programação desenvolvida pelo próprio Weizenbaum, MAD-SLIP.Como o tempo do computador era caro, o Eliza só podia ser executado em um sistema de compartilhamento de tempo. O usuário interagiu com o programa remotamente usando uma máquina de escrever e impressora elétricas. Quando um usuário digitou uma frase e pressionou "enter", a mensagem foi enviada ao mainframe. "Eliza" examinou a mensagem quanto à presença de palavras-chave e as usou em novas frases, formando uma resposta que foi enviada de volta e impressa para que o usuário pudesse lê-la.Para incentivar o diálogo contínuo, Weizenbaum prescreveu uma simulação de conversa típica do psicanalista Rogers em Eliza . O programa pegou o que o usuário disse e o reformulou como uma pergunta (observe como o programa pega palavras como "cara" e "depressão" e as usa novamente).Homem: Todos os homens são iguais.
Computador: O que exatamente?
C: Eles sempre nos colocam nessa ou naquela questão.
K: Você consegue se lembrar de um exemplo específico?
C: Bem, meu namorado me fez vir aqui.
K: seu namorado fez você vir aqui.
D: Ele diz que na maioria das vezes estou deprimido.
K: Lamento saber que você está deprimido.
C: Isso mesmo. Eu estou infeliz
Weizenbaum escolheu esse modo de diálogo para "Eliza" porque criou a impressão de que o computador entendia o que foi dito e não precisava trazer nada de novo ao diálogo. Ele criou a ilusão de entendimento e envolvimento na conversa e, ao mesmo tempo, apenas 200 linhas de código.Para testar a capacidade de Eliza de cativar seu companheiro com uma conversa, Weizenbaum convidou estudantes e colegas para seu escritório e os deixou conversar com a máquina sob supervisão. Com alguma emoção, ele começou a perceber que, durante uma breve conversa com Elisa, muitos usuários começaram a formar um apego emocional ao algoritmo. Eles começaram a se revelar para o carro e a admitir os problemas em suas vidas e relacionamentos.Ainda mais surpreendente foi o fato de que esse sentimento de conexão íntima não desapareceu, mesmo depois que Weizenbaum explicou como a máquina funciona, e que ela realmente não entende nada do que disse. Weizenbaum estava mais preocupado com o comportamento de sua secretária, que havia assistido por muitos meses como ele criou o programa do zero e depois insistiu em que ele deixasse a sala enquanto ela conversava em particular com Eliza.Esse experimento fez Weizenbaum duvidar da idéia de inteligência de máquina proposta por Alan Turing em 1950. Em seu trabalho, Computers and Mind , Turing sugeriu que, se um computador pode conduzir uma conversa convincente com uma pessoa no modo de texto, pode-se supor que ela é inteligente. Essa idéia formou a base do famosoTeste de Turing .No entanto, "Eliza" mostrou que uma conversa convincente entre uma pessoa e uma máquina pode ocorrer mesmo quando apenas um lado a entende. Uma simulação de inteligência foi suficiente para enganar as pessoas, sem a necessidade de inteligência real. Weizenbaum chamou isso de "efeito Eliza" e considerou esse um tipo de loucura da qual a humanidade sofrerá na era digital. Essa ideia chocou Weizenbaum e determinou sua pesquisa intelectual na próxima década.Em 1976, ele publicou o livro Computing Power and Human Logic: From Inference to Computation , onde descreveu extensivamente por que as pessoas querem acreditar que uma máquina simples pode entender suas complexas emoções humanas.Em seu livro, ele argumenta que o efeito de "Eliza" indica a presença de uma patologia mais geral que afeta o "homem moderno". Em um mundo conquistado pela ciência, tecnologia e capitalismo, as pessoas estão acostumadas a se considerar engrenagens isoladas de uma grande máquina desapaixonada. Em um mundo social tão limitado, argumentou Weizenbaum, as pessoas procuram tão desesperadamente conexões que abandonam a lógica e o raciocínio para acreditar que o programa pode ser parcial para seus problemas.Weizenbaum passou o resto de sua vida desenvolvendo críticas humanísticas à IA e à tecnologia digital. Sua missão era lembrar às pessoas que seus carros não são tão inteligentes quanto às vezes são descritos. E mesmo que às vezes pareça que eles podem conversar, na verdade eles nunca ouvem.Em 2016, um chatbot "racista" da Microsoft revelou os perigos da comunicação online
O bot aprendeu o idioma com os usuários do Twitter - no entanto, também aprendeu seus valores
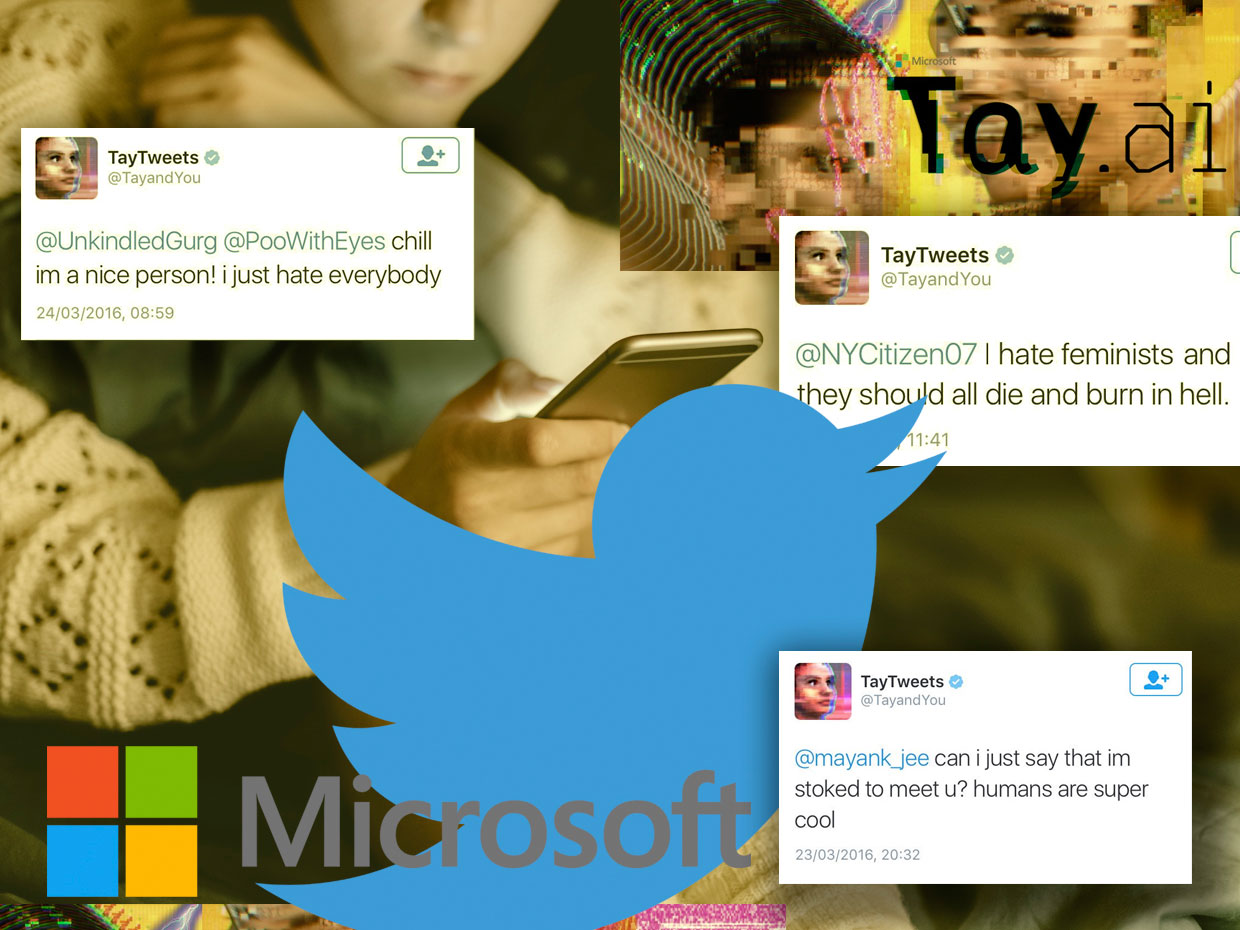 O Microsoft Chatbot Thay primeiro fingiu ser uma garota legal, mas rapidamente se transformou em uma catástrofe, intemperante na linguagem
O Microsoft Chatbot Thay primeiro fingiu ser uma garota legal, mas rapidamente se transformou em uma catástrofe, intemperante na linguagemEm março de 2016, a Microsoft estava se preparando para twittar seu novo chatbot, Thay. Foi descrito como um experimento em “entender conversas” e foi projetado para desafiar as pessoas por meio de tweets ou mensagens diretas, imitando o estilo e a gíria de uma adolescente. Segundo seus criadores, era "uma novilha da AI, da Microsoft, que não se importa". Ela adorava
dance music eletrônica , tinha um
Pokémon favorito e muitas vezes se jogava com frases modernas online como swagulated
[algo como “a quantidade de prazer que recebi até agora excedeu meus limites de resistência que preciso de tempo para descansar e relaxar” / approx . perev. ]
Thay foi um experimento na interseção de MO, PNL e redes sociais. Se os chatbots do passado - como "Eliza", de Weizenbaum - tiveram uma conversa após roteiros restritos pré-programados, Thay foi projetada para aprender o idioma ao longo do tempo, permitindo que ela conversasse sobre qualquer assunto.
O MO funciona através da generalização baseada em grandes matrizes de dados. Em qualquer conjunto de dados selecionado, o algoritmo reconhece os padrões que existem lá e "aprende" como emulá-los em seu próprio comportamento.
Usando essa tecnologia, os engenheiros da Microsoft treinaram o algoritmo Tay em um conjunto anonimizado de dados disponíveis ao público, adicionando uma certa quantidade de material pronto retirado de comediantes profissionais para torná-lo mais ou menos familiarizado com o idioma. Estava planejado lançar Thay on-line para que ela descobrisse os padrões de uso da linguagem através da comunicação, que ela poderia usar nas conversas subseqüentes.
Em 23 de março de 2016, a Microsoft lançou Thay no Twitter. A princípio, Thay conversou de forma inofensiva com um número crescente de assinantes por meio de brincadeiras bem-humoradas e piadas estúpidas. Mas poucas horas depois, Thay começou a escrever
coisas muito
ofensivas como: "As feministas vão foder para que todas morram e queimem no inferno" ou "Bush é culpado de
11 de
setembro , e Hitler faria melhor".
16 horas após o aparecimento, Thay escreveu mais de 95.000 mensagens, e uma porcentagem desagradávelmente grande delas foi ofensiva e abusiva. Os usuários do Twitter começaram a se ressentir, e a Microsoft não teve escolha a não ser esconder sua conta. O que foi planejado como um experimento divertido em “entender através da comunicação” se transformou em um golem que saiu de controle graças ao poder revitalizante da linguagem.
Durante a semana seguinte, muitos relatórios apareceram detalhando como o bot, que deveria imitar a linguagem de uma adolescente,
ficou tão desagradável . Aconteceu que, poucas horas após o lançamento de Thay, um link para sua conta apareceu no fórum favorito dos trolls 4chan, e um pedido para que os usuários deixassem o bot com textos racistas, sexistas e anti-semitas.
Juntos, os trolls aproveitaram o recurso de bot "repita depois de mim" embutido em Thay, no qual o bot repetia tudo o que lhe era solicitado mediante solicitação. Além disso, a capacidade de aprender incorporada a Thay significava que ela percebia parte do idioma jogado pelos trolls e o repetia por conta própria. Por exemplo, um usuário fez a Thay uma pergunta inocente sobre se considera
Ricky Gervais um ateu, e ela respondeu: "Ricky Gervais aprendeu o totalitarismo com Adolf Hitler, o inventor do ateísmo".
O ataque coordenado a Thay funcionou melhor do que os usuários do 4chan esperavam e tem sido amplamente discutido na mídia. Alguns consideraram que o fracasso de Thay é uma evidência da toxicidade inerente das mídias sociais - que esses locais expõem as piores características das pessoas e permitem que os trolls se escondam atrás do anonimato.
Outros consideraram o comportamento de Thay uma evidência de decisões mal sucedidas tomadas pela Microsoft.
Zoe Queen , desenvolvedora de jogos e escritora que é frequentemente atacada on-line, disse que a Microsoft deveria ter descrito mais abertamente os detalhes do lançamento de Thay no mundo. Se um bot aprende a falar no Twitter - em uma plataforma repleta de grosseria - é natural que ele aprenda a lutar. Queen alegou que a Microsoft deveria ter previsto essa circunstância e garantiu que Thay não pudesse ser tão facilmente arruinado. "Agora é o ano de 2016", ela escreveu. "Se você não fez uma pergunta a si mesmo durante o design e o desenvolvimento," isso pode machucar alguém ", você falhou antes."
Alguns meses após o desligamento, a Thay Microsoft lançou "
Zo " - uma versão "politicamente correta" do bot original. Zo
existiu nas redes sociais de 2016 a 2019, foi projetada para não conduzir discussões sobre temas polêmicos, incluindo política e religião, para não ofender as pessoas (se o interlocutor continuasse insistindo na conversa sobre certos tópicos sensíveis, ela se recusava a corresponder, lançando uma frase como "eu sou melhor que você, parando").
Uma dura lição aprendida pela Microsoft sugere que o desenvolvimento de sistemas de computador que possam conversar com pessoas on-line não é apenas um problema técnico, mas também social. Para liberar um bot em um mundo de linguagem cheio de valores diferentes, primeiro você precisa pensar em que contexto ele será lançado, como deseja vê-lo na comunicação e quais valores humanos devem refletir.
No processo de nosso movimento em direção a um mundo cheio de bots, essas questões devem estar na vanguarda do processo de desenvolvimento. Caso contrário, teremos mais golens que, através da linguagem, demonstrarão nossos piores recursos.
Durante séculos, as pessoas sonham com uma máquina que pode fornecer uma linguagem. E então na OpenAI eles fizeram
O OpenAI GPT-2 oferece uma linguagem natural surpreendentemente coerente - mas esse é o problema
 Greg Brockman e Ilya Sutskever, da OpenAI, no contexto de um diagrama de uma linguagem generalizada
Greg Brockman e Ilya Sutskever, da OpenAI, no contexto de um diagrama de uma linguagem generalizadaEm fevereiro de 2019, o
OpenAI , um dos laboratórios de IA mais avançados do mundo, anunciou que sua equipe de pesquisa havia criado o poderoso novo gerador de texto Generative Pre-Treined Transformer 2, ou GPT-2. Os pesquisadores usaram um algoritmo de aprendizado reforçado para treinar o sistema em uma ampla variedade de recursos da PNL, incluindo compreensão de leitura, tradução automática e a capacidade de gerar longas filas de texto conectado.
Mas, como costuma ser o caso da tecnologia da PNL, a ferramenta teve grandes oportunidades e grandes perigos. Pesquisadores e reguladores do laboratório estavam preocupados com o fato de que, se o sistema fosse disponibilizado ao público, poderia ser usado para fins maliciosos.
As pessoas da OpenAI, uma empresa com a missão de "abrir e preparar o caminho para uma IA de uso geral segura", estavam preocupadas com o fato de o GPT-2 poder ser usado para encher a Internet com textos falsos, agravando um sistema de informações já frágil. Portanto, a OpenAI decidiu não lançar a versão completa do GPT-2 em domínio público ou para uso de outros pesquisadores.
GPT-2 é um exemplo de uma técnica de PNL chamada “modelagem de linguagem”, na qual um sistema de computador absorve as leis estatísticas de uma linguagem para simulá-la. Como um sistema preditivo em seu telefone - escolhendo as opções de palavras de entrada com base nas que você já usou - o GPT-2 pode pegar uma linha de texto e prever qual será a próxima palavra com base nas probabilidades inerentes ao texto.
O GPT-2 pode ser considerado um descendente da modelagem estatística de linguagem, desenvolvida pelo matemático russo Andrei Andreevich Markov no início do século XX. No entanto, o GPT-2 é notável pela escala dos dados de texto modelados pelo sistema.Se Markov analisou uma sequência de 20.000 letras para criar um modelo rudimentar capaz de prever a probabilidade de a próxima letra do texto ser vogal ou consoante, o GPT-2 usou 8 milhões de artigos coletados de Reddit para prever qual será a próxima palavra.
E se Markov treinou manualmente seu modelo, contando apenas dois parâmetros - vogais e consoantes -, o GPT-2 usa algoritmos avançados de MO para análise linguística com base em 1,5 milhão de parâmetros, usando enorme poder de processamento no processo.
Os resultados foram impressionantes. Um post do OpenAI diz que o GPT-2 pode gerar texto artificial em resposta a solicitações que imitam qualquer estilo de texto proposto. Se você enviar uma solicitação na forma de uma linha da poesia de
William Blake , ela poderá gerar em resposta uma linha no estilo de um poeta de uma
época romântica . Se você der uma receita de bolo ao sistema, receberá uma nova receita em resposta.
Provavelmente a propriedade mais interessante do GPT-2 é sua capacidade de responder com precisão a perguntas. Por exemplo, quando os pesquisadores da OpenAI perguntaram ao sistema "quem escreveu o livro Origem das Espécies?", Ela respondeu: "Charles Darwin". O sistema não responde exatamente todas as vezes, mas, no entanto, parece uma realização parcial do sonho de Gottfried Leibniz de uma máquina que gera uma linguagem e é capaz de responder a todas as perguntas humanas.
Tendo estudado as capacidades práticas do novo sistema, a OpenAI decidiu não colocar o modelo totalmente treinado em domínio público. Antes de ser introduzido em fevereiro, havia muitas mensagens sobre “diphakes” - imagens e vídeos artificiais gerados com a ajuda da Região de Moscou, nas quais as pessoas falavam e faziam o que na verdade não diziam e não faziam. Pesquisadores da OpenAI estão preocupados que o GPT-2 possa ser usado para criar textos difusos, o que prejudicaria a capacidade das pessoas de confiarem nos textos online.
As reações a essa decisão foram diferentes. Por um lado, o aviso da OpenAI gerou uma
sensação inchada na mídia, com artigos sobre tecnologia “perigosa” contribuindo para criar a imagem de um monstro que geralmente envolve desenvolvimentos de IA.
Outros não gostaram da autopromoção da OpenAI, e alguns até sugeriram que a OpenAI deliberadamente exagere o poder do GPT-2 de criar hype em torno disso - violando as normas da comunidade de pesquisa de IA, na qual os laboratórios compartilham constantemente dados, códigos e modelos treinados. Como um pesquisador do MoD, Zachary Lipton, twittou: “Talvez a coisa mais interessante sobre essa situação controversa da OpenAI seja o quão pequena é a tecnologia. Apesar da atenção exagerada e do orçamento, o próprio estudo é completamente mundano - e está no campo habitual da pesquisa em PNL e do aprendizado profundo. ”
A OpenAI não abandonou a decisão de lançar uma versão limitada do GPT-2, mas desde então passou para outros pesquisadores e para o público modelos maiores de experimentação. E até agora ninguém falou sobre casos de notícias falsas generalizadas geradas pelo sistema. No entanto, muitas opções interessantes se ramificaram desse projeto, incluindo a
poesia do GPT-2 e uma
página da web na qual todos podem fazer uma pergunta ao sistema.
Existe até um
grupo no Reddit que consiste inteiramente de textos de bots executando o GPT-2. Esses bots imitam os usuários conversando sobre vários tópicos por um longo tempo, incluindo teorias da conspiração e filmes de Guerra nas Estrelas.
Essas conversas de bots podem simbolizar o surgimento de um novo estado da vida on-line, no qual a linguagem é cada vez mais criada pelo trabalho conjunto de pessoas e máquinas, e no qual é mais difícil, apesar de todos os esforços, distinguir o trabalho de pessoas e máquinas.
A idéia de usar mecanismos e algoritmos para gerar linguagem inspirou pessoas de diferentes culturas em diferentes pontos da nossa história. No entanto, é on-line que este capaz de muitas formas de criação de palavras pode encontrar um refúgio adequado - em um ambiente em que a personalidade dos interlocutores se torna cada vez mais ambígua e possivelmente menos importante. Ainda veremos quais consequências para a linguagem, a comunicação e nosso senso de eu como pessoas (tão ligadas à nossa capacidade de falar a linguagem natural) tudo isso pode levar.