
Recentemente, ocorreu um evento significativo no Departamento de Operações Yandex.Money. Nossa empresa está crescendo rapidamente e constatou-se que não apenas nossos corações, mas também a demanda do data center mudam. Mais precisamente, o local exigia alterações. E agora por três meses, como um dos data centers mora em um novo local.
Sobre como o Yandex.Money mudou para um novo data center, vou lhe dizer, o chefe do departamento de operações e Ivan, o chefe do departamento de infraestrutura de TI e sistemas internos.
Sob o corte - uma cronologia de eventos, marcos importantes do movimento, curvas inesperadas e debriefing. Compartilhamos como sobrevivemos a isso.
Pré-requisitos para realocação
Anteriormente, um dos datacenters Yandex.Money estava localizado no subúrbio de Moscou. A realidade é que, fora da cidade, nem todos os provedores de canais de comunicação óptica têm a capacidade de estabelecer rotas a cabo de forma independente - é caro. E a primeira razão para a nossa decisão de mudar foi devido ao fato de que, nos antigos canais de comunicação do data center, passavam pelas mesmas rotas, e isso trazia riscos adicionais.
Dentro do anel viário de Moscou, existem muitos fornecedores e o sistema de cabos está bem desenvolvido. Você pode comprar canais de diferentes fornecedores, de maneiras diferentes e que não se sobrepõem. Há riscos crescentes na região - por exemplo, uma escavadeira virá e cavará todas as trilhas de uma só vez.
Em segundo lugar, o data center anterior apresentava limitações tecnológicas, incluindo periodicamente problemas de fornecimento de energia.
Mas a principal razão (= dor) é a incapacidade de expandir. Isso significava que o prédio ficou sem espaço para racks adicionais, onde foi possível colocar novos equipamentos. Isso está diretamente relacionado ao nosso ambiente produtivo, porque o Yandex.Money possui dois data centers e eles devem ser simétricos em termos de capacidades.
Planejamento
A preparação para a mudança foi dividida em etapas:
- Competições: DC, canais, redes, racks, PDUs, cabos;
- Transferir aplicativos e bancos de dados para o 2º DC;
- Ensinamentos - desabilitando a CD;
- Nova arquitetura de redes principais, IX;
- Configurando um novo núcleo de rede no controlador de domínio.
Seleção de Fornecedores
O primeiro data center Yandex.Money está localizado em Moscou. E, para evitar grandes atrasos na rede, decidimos colocar o segundo data center próximo ao primeiro.
Dentro do MKAD, para minimizar os atrasos na rede e não mais de 20 km da primeira instalação, para garantir a independência dos dois data centers da mesma infraestrutura urbana e possíveis desastres tecnológicos ou naturais.
Ao analisar o mercado, fomos guiados por um critério tão importante como a certificação de data centers em termos de disponibilidade e confiabilidade. O padrão mais comum na Rússia e no mundo é o desenvolvido pelo Uptime Institute, que audita data centers em todo o mundo. Vale ressaltar que existem muitos data centers que certificaram apenas a documentação do projeto, mas isso não significa que o próprio data center seja construído, testado e operado de acordo com os padrões.
Um caso de nossa prática: um provedor de serviços de data center em Moscou nos anunciou que o projeto do data center atende ao padrão de Nível III e se ofereceu para concluir um contrato com a promessa de 100% de disponibilidade, ou seja, 0 minutos de inatividade por ano! Tendo visitado pessoalmente o site, percebemos que não há certificações oficiais que garantam o nível de qualidade, e a infraestrutura claramente não se baseia no Nível III. O data center estava localizado no térreo de um prédio residencial, e o único gerador-reboque ficava na rua sem nenhuma proteção física.
Portanto, nos requisitos para a competição, incluímos não apenas a certificação do projeto, mas também a certificação dos processos de implementação e gerenciamento.
Além disso, determinamos com fornecedores de canais de comunicação óptica entre nossos CDs e canais para pontos de troca de tráfego (IX) onde organizamos interfaces com fornecedores ou nossos parceiros. O principal critério era que os canais de comunicação óptica fossem independentes, seguissem diferentes rotas.
E, é claro, houve outras compras - principalmente equipamentos de rede, racks (gabinetes especializados para instalação de servidores), unidade de distribuição de energia (unidades inteligentes de distribuição de energia), além de cabos e cabos de conexão.
Vale ressaltar que selecionamos com cuidado o fornecedor que transportará o equipamento. É importante que a empresa tenha experiência no transporte de servidores, e os operadores entendam que isso não é mobília e carga, e você também deve ter um cuidado especial ao dirigir. Além disso, asseguramos o equipamento transportado em caso de danos durante o transporte.
Atualização da infraestrutura de rede
Em relação à infraestrutura de rede, tínhamos duas opções. O primeiro é transportar equipamentos de rede antigos "como estão". O segundo é criar primeiro uma nova infraestrutura de rede em um novo data center e, somente então, transportar o equipamento do servidor.
Como entendemos que já havíamos “encontrado” a largura de banda da rede no antigo datacenter e precisávamos da reserva e da capacidade de escalabilidade por pelo menos os próximos 3-5 anos, foi decidido construir uma infraestrutura de rede no novo datacenter do zero e atualizar para uma nova geração de equipamentos .
Aderimos ao modelo clássico ao construir uma rede em um novo data center. Em cada rack, os servidores são conectados a dois comutadores de acesso, que, por sua vez, são conectados aos comutadores de agregação central (eles também são o núcleo da rede).
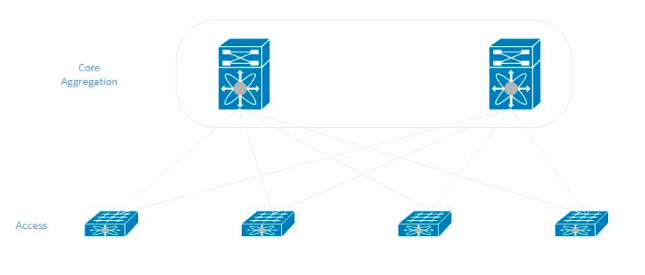
Ensinamentos
Ao mudar, decidimos desligar completamente o datacenter, ao mesmo tempo para transportar tudo e ativá-lo em um novo local. Para isso, a empresa precisou aprender a lidar com um dos dois data centers. Foi necessária a participação de quase todos os nossos administradores para que os sistemas de informação em plataformas diferentes, em sistemas operacionais diferentes, com bancos de dados diferentes funcionassem ininterruptamente no site restante.
Para os serviços mais críticos, foi fornecida uma reserva que permaneceu disponível mesmo com um data center desativado.
Depois de realizar o trabalho de reserva, começaram os exercícios. Primeiro, desconectamos redes, segmentos e somente então o data center completamente. Em 2019, realizamos um desligamento de teste do data center 10 vezes - vimos como nossos 300 sistemas de informação se comportam. Verificando repetidamente a autonomia, estávamos convencidos de que podemos desconectar facilmente.
E então ...
Semana X
Uma das sextas-feiras estava programada para desligar todos os equipamentos do data center - os últimos lançamentos foram lançados pela manhã e, em seguida, uma moratória foi anunciada neles.
O Yandex.Money pode ter 60 ou mais liberações por dia e todas elas são conduzidas para os dois data centers.
Interrompemos os lançamentos, garantimos que o sistema esteja funcionando de maneira estável e que nenhuma correção seja necessária em nossos componentes. A partir das 15:00, começaram a extinguir gradualmente todos os aplicativos, bancos de dados e servidores. Durante a noite, de sexta a sábado, esperamos um tempo, estávamos convencidos de que nada de ruim estava acontecendo, o que significa que podemos ir. Na manhã de sábado, uma equipe de 15 pessoas começou a desmontar o equipamento e transportá-lo para o novo data center.

Levamos o dia todo sábado para desmontar e transportar o equipamento. Em seguida, iniciou o processo de instalação do equipamento, comutação e conexão à fonte de alimentação.

No sábado à noite, montamos e conectamos o primeiro lote de servidores. O trabalho principal começou no domingo - na noite do fim de semana quase todo o equipamento foi instalado. E terminamos a comutação apenas na segunda-feira à noite.

Na terça-feira de manhã, realizamos os testes finais de redes, canais de comunicação e estávamos prontos para elevar nossos sistemas. Eles começaram a aumentar o primeiro lote de servidores, mas algo deu errado ...
Começamos a receber reclamações em massa dos administradores de que a rede não funcionava nos servidores: completamente ou uma das duas interfaces. Eles começaram a procurar problemas no lado dos equipamentos de rede, nos sistemas operacionais, nas configurações dos sistemas operacionais.
Os sintomas eram semelhantes - eles começaram a olhar para o que poderia ser o motivo. Percebemos que vale a pena mover os cabos de conexão ao lado das portas do switch com mais força e alguns dos links de trabalho se apagam.

Tendo descoberto isso, percebemos que uma parte significativa desses cabos de conexão (cerca de 40% das 2.000 peças) estava com defeito. Movemos todos os patch cords disponíveis de outro fabricante confiável para um novo data center e começamos urgentemente a reconectar os servidores mais críticos. Demorou mais um dia.
Desde a noite de quarta-feira na manhã de quinta-feira, a equipe começou a levantar o principal bloco de sistemas de informação.
Depois que levantamos os serviços críticos e lançamos a reserva do sistema de pagamento, incluímos parte das bancas de testes do novo data center e da reserva dos sistemas de backoffice para que todos os nossos sistemas internos funcionem com dois data centers. No final da semana, quase toda a infraestrutura de TI do data center transportado foi lançada.
Inicialmente, havia um plano para 5 dias, mas com uma situação de contingência relacionada a patch cords defeituosos, era uma semana. Abaixo, pintamos claramente a linha do tempo de nossas ações.
Plano de realocação - pendente:- Sexta-feira - extinguimos redes e aplicativos;
- Sábado - realizamos e iniciamos a montagem;
- Domingo - instalação de servidores, lançamento de redes;
- Segunda-feira - terminamos a rede, lançamos aplicativos;
- Terça-feira - ligue tudo.
Realidade:- Sexta-feira - extinguimos redes e aplicativos;
- Sábado - realizamos e iniciamos a montagem;
- Domingo - instalação de servidores, lançamento de redes;
- Segunda-feira - cabeamento, lançamento de rede;
- Terça-feira - ligue os servidores, mais de 100 não funcionam;
- Quarta-feira - casamento em fios, substituição , lançamento de App e DB;
- Quinta-feira - terminou a substituição do PS, inicie o aplicativo.
Vida depois de se mudar
O que conseguimos com a mudança?Antes de tudo, agora os dois data centers estão no nível do Uptime Tier III Institute. Os fornecedores de data centers nos garantem um nível de disponibilidade de Uptime de 99,982%, o que equivale a 1,6 horas de tempo de inatividade por ano. Estamos confiantes na confiabilidade dos canais de comunicação entre nossos sites. Agora também não há restrições para expandir nossa infraestrutura de TI.
A idéia de mudar nos deu uma grande oportunidade de atualizar o equipamento de rede em termos de largura de banda. Também refatoramos fontes de alimentação em racks - instalamos “PDUs inteligentes”, servidores de energia reservados.
E quando nos mudamos, fomos capazes de “pentear” a comutação, e agora ela parece mais limpa.

Portanto, em geral, o sistema começou a funcionar mais estável e nossos clientes recebem um melhor serviço.
Que conclusões você tirou para si mesmo?Ao realizar grandes projetos, você precisa pensar nos riscos, imaginar quais podem ser as armadilhas. Nosso exemplo com cabos Ethernet mostrou que não é suficiente fazer uma compra de teste e testar os produtos de cabo do fabricante selecionado. Para reduzir os riscos, foi necessário realizar testes aleatórios de um lote de 2000 cabos.
Também vale a pena considerar que alguns servidores podem não sobreviver à mudança e simplesmente não são ativados por vários motivos. De uma maneira ou de outra, a estrada está tremendo e com um estresse mecânico. Das 600 unidades de equipamentos transportados, 6 blocos quebraram. De um número suficientemente grande de servidores, apenas 1% sofreu, nem um único disco travou - acreditamos que este é um excelente resultado.
Foi assim que o data center Yandex.Money mudou-se para um novo local. Esperamos que nossa experiência o ajude a evitar possíveis erros e, talvez, o leve a outras soluções interessantes.