Qualquer
imagem rasterizada pode ser representada como uma
matriz bidimensional . No que diz respeito às cores, a ideia pode ser desenvolvida observando a imagem na forma de uma
matriz tridimensional , na qual medições adicionais são usadas para armazenar dados para cada uma das cores.
Se considerarmos a cor final como uma combinação dos chamados cores primárias (vermelho, verde e azul), em nossa matriz tridimensional, determinamos três planos: o primeiro para o vermelho, o segundo para o verde e o último para o azul.
Vamos chamar cada ponto dessa matriz de pixel (elemento de imagem). Cada pixel contém informações de intensidade (geralmente na forma de um valor numérico) de cada cor. Por exemplo, um
pixel vermelho significa que possui 0 verde, 0 azul e vermelho máximo.
Um pixel rosa pode ser formado usando uma combinação de três cores. Usando um intervalo numérico de 0 a 255, o pixel rosa é definido como
Vermelho = 255 ,
Verde = 192 e
Azul = 203 .

Este artigo foi publicado com o apoio da EDISON.
Desenvolvemos aplicativos para vigilância por vídeo, streaming de vídeo e gravação de vídeo na sala cirúrgica .
Técnicas alternativas de codificação por cores
Para representar as cores que compõem a imagem, existem muitos outros modelos. Por exemplo, você pode usar uma paleta indexada na qual apenas um byte é necessário para representar cada pixel, em vez dos três necessários ao usar o modelo RGB. Nesse modelo, você pode usar uma matriz 2D em vez de uma matriz 3D para representar cada cor. Isso economiza memória, mas fornece menos cores.

RGB
Por exemplo, veja esta imagem abaixo. A primeira face é completamente pintada. Outros são os planos vermelho, verde e azul (a intensidade das cores correspondentes é mostrada em escala de cinza).

Vemos que os tons de vermelho no original estarão nos mesmos lugares em que as partes mais brilhantes da segunda pessoa são observadas. Enquanto a contribuição do azul pode ser vista principalmente apenas nos olhos de Mario (o último rosto) e nos elementos de suas roupas. Observe onde os três planos de cores contribuem menos (as partes mais escuras das imagens) - este é o bigode de Mario.
Para armazenar a intensidade de cada cor, é necessário um certo número de bits - esse valor é chamado
profundidade de bits . Digamos que 8 bits sejam gastos (com base em um valor de 0 a 255) em um plano de cores. Em seguida, temos uma profundidade de cor de 24 bits (8 bits * 3 plano R / G / B).
Outra propriedade da imagem é a
resolução , que é o número de pixels em uma dimensão. É geralmente chamado de
largura × altura , como abaixo na imagem de exemplo 4 por 4.

Outra propriedade com a qual lidamos ao trabalhar com imagens / vídeo é a
proporção , que descreve a relação proporcional usual entre a largura e a altura de uma imagem ou pixel.
Quando eles dizem que um filme ou imagem tem 16 por 9, geralmente se refere à
proporção da tela (
DAR - da
proporção da
tela ). No entanto, às vezes pode haver diferentes formas de pixels individuais - neste caso, estamos falando sobre a
proporção de pixels (
PAR - da
relação de aspecto de pixel ).


Nota para a anfitriã: DVD corresponde a DAR 4 por 3
Embora a resolução real do DVD seja 704x480, ela mantém uma proporção de aspecto 4: 3, pois o PAR está definido em 10:11 (704x10 / 480x11).
E, finalmente, podemos definir um
vídeo como uma sequência de
n quadros ao longo de um período de
tempo , o que pode ser considerado uma dimensão adicional. E então é a taxa de quadros ou o número de quadros por segundo (
FPS - de
quadros por segundo ).

O número de bits por segundo necessário para exibir um vídeo é sua
taxa de bits .
taxa de bits = largura * altura * profundidade de bits * quadros por segundo
Por exemplo, para vídeos com 30 quadros por segundo, 24 bits por pixel, resolução 480x240, 82.944.000 bits por segundo ou 82.944 Mbit / s (30x480x240x24) seriam necessários - mas isso é se você não usar nenhum dos métodos de compactação.
Se a taxa de bits é
quase constante , é chamada de
taxa de bits constante (
CBR - da
taxa de bits constante ). Mas também pode variar, neste caso, é chamada de
taxa de bits variável (
VBR - da
taxa de bits variável ).
Este gráfico mostra um VBR limitado quando não são gastos muitos bits no caso de um quadro completamente escuro.

Inicialmente, os engenheiros desenvolveram um método para dobrar a taxa de quadros percebida de uma exibição de vídeo sem usar largura de banda adicional. Este método é conhecido como
vídeo entrelaçado ; basicamente, ele envia metade da tela no primeiro "quadro" e a outra metade no próximo "quadro".
Atualmente, a visualização de cenas é realizada principalmente usando a
tecnologia de varredura progressiva . Este é um método de exibição, armazenamento ou transmissão de imagens em movimento, em que todas as linhas de cada quadro são desenhadas seqüencialmente.

Bem então! Agora sabemos como a imagem é representada em formato digital, como suas cores são organizadas, quantos bits por segundo gastamos para mostrar o vídeo se a velocidade de transmissão for constante (CBR) ou variável (VBR). Conhecemos uma determinada resolução usando uma determinada taxa de quadros, nos familiarizamos com muitos outros termos, como vídeo entrelaçado, PAR e outros.
Remoção de redundância
Sabe-se que o vídeo sem compactação não pode ser usado normalmente. O vídeo por hora com uma resolução de 720p e uma frequência de 30 quadros por segundo ocuparia 278 GB. Chegamos a esse valor multiplicando 1280 x 720 x 24 x 30 x 3600 (largura, altura, bits por pixel, FPS e tempo em segundos).
O uso de
algoritmos de compactação sem perdas como DEFLATE (usado em PKZIP, Gzip e PNG) não reduzirá suficientemente a largura de banda necessária. Você precisa procurar outras maneiras de comprimir o vídeo.
Para isso, você pode usar os recursos de nossa visão. Distinguimos melhor brilho do que cores. Um vídeo é um conjunto de imagens seqüenciais que se repetem com o tempo. Existem pequenas diferenças entre os quadros adjacentes da mesma cena. Além disso, cada quadro contém muitas áreas que usam a mesma cor (ou similar).
Cor, brilho e nossos olhos
Nossos olhos são mais sensíveis ao brilho do que à cor. Você pode ver por si mesmo olhando para esta foto.
Se você não perceber que na metade esquerda da imagem as cores dos quadrados
A e
B são realmente as mesmas, então isso é normal. Nosso cérebro nos faz prestar mais atenção ao claro-escuro do que à cor. No lado direito entre os quadrados marcados, há um jumper da mesma cor - portanto, nós (ou seja, nosso cérebro) podemos determinar facilmente que, de fato, a mesma cor está lá.
Vejamos (simplificado) como nossos olhos funcionam. O olho é um órgão complexo composto de muitas partes. No entanto, estamos mais interessados em cones e paus. O olho contém cerca de 120 milhões de hastes e 6 milhões de cones.
Considere a percepção de cor e brilho como funções separadas de certas partes do olho (de fato, tudo é um pouco mais complicado, mas simplificaremos). As células-tronco são responsáveis principalmente pelo brilho, enquanto as células-cone são responsáveis pela cor. Os cones são divididos em três tipos, dependendo do pigmento contido: cones S (azul), cones M (verde) e cones L (vermelho).
Como temos muito mais bastões (brilho) do que cones (cores), podemos concluir que somos mais capazes de distinguir entre as transições entre escuridão e luz do que cores.

Funções de sensibilidade ao contraste
Pesquisadores em psicologia experimental e em muitos outros campos desenvolveram muitas teorias da visão humana. E um deles é chamado de funções de sensibilidade ao contraste . Eles estão associados à iluminação espacial e temporal. Em resumo, trata-se de quantas mudanças são necessárias antes que o observador as veja. Observe o plural da palavra "função". Isso se deve ao fato de podermos medir as funções de sensibilidade para contrastar não apenas com imagens em preto e branco, mas também com cores. Os resultados desses experimentos mostram que, na maioria dos casos, nossos olhos são mais sensíveis ao brilho do que à cor.
Como se sabe que somos mais sensíveis ao brilho da imagem, você pode tentar usar esse fato.
Modelo de cor
Nós descobrimos um pouco como trabalhar com imagens coloridas usando o esquema RGB. Existem outros modelos. Existe um modelo que separa a luminância da cor e é conhecido como
YCbCr . A propósito, existem outros modelos que fazem uma separação semelhante, mas consideraremos apenas este.
Nesse modelo de cores,
Y é uma representação do brilho e dois canais de cores são usados:
Cb (azul saturado) e
Cr (vermelho saturado). YCbCr pode ser obtido no RGB, assim como a transformação inversa é possível. Usando esse modelo, podemos criar imagens coloridas, como podemos ver abaixo:

Converter entre YCbCr e RGB
Alguém se oporá: como é possível obter todas as cores se o verde não for usado?
Para responder a esta pergunta, converta RGB em YCbCr. Utilizamos os coeficientes adotados no
padrão BT.601 , recomendado pela unidade
ITU-R . Esta unidade define os padrões de vídeo digital. Por exemplo: o que é 4K? Qual deve ser a taxa de quadros, resolução, modelo de cores?
Primeiro, calculamos o brilho. Usamos as constantes propostas pela ITU e substituímos os valores RGB.
Y = 0,299
R + 0,587
G + 0,114
BDepois de obter o brilho, separaremos as cores azul e vermelho:
Cb = 0,564 (
B -
Y )
Cr = 0,713 (
R -
Y )
E também podemos converter de volta e até ficar verde com o YCbCr:
R =
Y + 1,402
CrB =
Y + 1,772
CbG =
Y - 0,344
Cb - 0,714
CrComo regra, os monitores (monitores, TVs, telas etc.) usam apenas o modelo RGB. Mas esse modelo pode ser organizado de diferentes maneiras:

Redução de escala de cores
Com a imagem apresentada como uma combinação de brilho e cor, podemos usar uma sensibilidade mais alta do sistema visual humano ao brilho do que à cor se excluirmos as informações seletivamente. A redução da amostragem de cores é um método de codificação de imagens usando resolução mais baixa para cores do que para brilho.
Quão aceitável é reduzir a resolução de cores ?! Acontece que já existem alguns esquemas que descrevem como lidar com a resolução e a mesclagem
(Cor final = Y + Cb + Cr).Esses esquemas são conhecidos como
sistemas de subamostragem e são expressos na forma de uma proporção de três vezes -
a :
x :
y , que determina o número de amostras de sinais de luminância e diferença de cor.
a - amostragem horizontal padrão (geralmente igual a 4)
x - o número de amostras de cores na primeira linha de pixels (resolução horizontal em relação a)
y é o número de alterações nas amostras de cores entre a primeira e a segunda linha de pixels.
A exceção é 4 : 1 : 0 , que fornece uma amostra de cor em cada bloco de resolução de brilho de 4 por 4.
Esquemas comuns usados em codecs modernos:
- 4 : 4 : 4 (sem redução da amostra)
- 4 : 2 : 2
- 4 : 1 : 1
- 4 : 2 : 0
- 4 : 1 : 0
- 3 : 1 : 1
YCbCr 4: 2: 0 - Exemplo de mesclagem
Aqui está o fragmento de imagem combinado usando YCbCr 4: 2: 0. Observe que gastamos apenas 12 bits por pixel.
É assim que a mesma imagem codificada pelos principais tipos de subamostragem de cores se parece. A primeira linha é o YCbCr final, a linha inferior mostra a resolução da cor. Resultados muito decentes, dada a pequena perda de qualidade.

Lembre-se, contamos 278 GB de espaço de armazenamento para um arquivo de vídeo de uma hora com uma resolução de 720p e 30 quadros por segundo? Se usarmos YCbCr 4: 2: 0, esse tamanho será reduzido pela metade - 139 GB. Até agora, ainda está longe de ser um resultado aceitável.
Você pode obter o histograma YCbCr com FFmpeg. Nesta imagem, o azul prevalece sobre o vermelho, que é claramente visível no próprio histograma.

Cor, brilho, gama de cores - revisão de vídeo
É recomendável assistir a este vídeo incrível. Isso explica o que é brilho e, de fato, todos os pontos são colocados sobre brilho e cor.
Tipos de quadro
Nós seguimos em frente. Vamos tentar eliminar a redundância no tempo. Mas primeiro, vamos definir uma terminologia básica. Suponha que tenhamos um filme com 30 quadros por segundo, eis os quatro primeiros quadros:




Podemos ver muitas repetições nos quadros: por exemplo, um fundo azul que não muda de quadro para quadro. Para resolver esse problema, podemos abstratamente classificá-los como três tipos de quadros.
Quadro I (Quadro Intro)
O quadro I (quadro de referência, quadro chave, quadro interno) é autônomo. Independentemente do que precisa ser visualizado, o quadro I é, de fato, uma fotografia estática. O primeiro quadro geralmente é um quadro I, mas observaremos regularmente os quadros I longe dos primeiros quadros.
Moldura P (Moldura Redita P )
O quadro P (quadro previsto) tira proveito do fato de que quase sempre a imagem atual pode ser reproduzida usando o quadro anterior. Por exemplo, no segundo quadro, a única alteração é a bola para frente. Podemos obter o quadro 2 apenas modificando levemente o quadro 1, usando apenas a diferença entre esses quadros. Para criar o quadro 2, consulte o quadro 1 que o precede.
←

Quadro B (Quadro B preditivo i)
E os links não apenas para quadros passados, mas também para quadros futuros, para fornecer uma compressão ainda melhor ?! Este é basicamente um quadro B (quadro bidirecional).
←
→
Retirada intermediária
Esses tipos de quadros são usados para fornecer a melhor compactação. Discutiremos como isso acontece na próxima seção. Enquanto isso, observamos que o quadro I é o mais "caro" em termos de memória, o quadro P é muito mais barato, mas o quadro B é a opção mais rentável para o vídeo.

Redundância temporal (previsão entre quadros)
Vejamos quais oportunidades temos para minimizar as repetições de tempo. Esse tipo de redundância pode ser resolvido usando os métodos de previsão mútua.
Vamos tentar gastar o mínimo de bits possível para codificar uma sequência de quadros 0 e 1.

Podemos
subtrair , apenas subtrair o quadro 1 do quadro 0. Obtemos o quadro 1, usamos apenas a diferença entre ele e o quadro anterior; na verdade, apenas codificamos o restante resultante.

Mas e se eu lhe disser que existe um método ainda melhor que usa ainda menos bits ?! Primeiro, vamos dividir o quadro 0 em uma grade clara de blocos. E então tentamos comparar os blocos do quadro 0 com o quadro 1. Em outras palavras, avaliamos o movimento entre os quadros.
Wikipedia - bloquear compensação de movimento
A compensação de movimento do bloco divide o quadro atual em blocos disjuntos e o vetor de compensação de movimento relata a origem dos blocos (um equívoco comum é que o quadro anterior é dividido em blocos disjuntos, e os vetores de compensação de movimento informam para onde vão esses blocos. o quadro e o próximo, não é para onde os blocos estão se movendo, mas de onde eles vieram). Normalmente, os blocos de origem se sobrepõem no quadro de origem. Alguns algoritmos de compactação de vídeo coletam o quadro atual de partes não apenas de um, mas de vários quadros transmitidos anteriormente.

No processo de avaliação, vemos que a bola mudou de
( x = 0,
y = 25) para
( x = 6,
y = 26), os valores de
xey determinam o vetor de movimento. Outro passo que podemos dar para salvar os bits é codificar apenas a diferença dos vetores de movimento entre a última posição do bloco e a prevista, de modo que o vetor de movimento final será
(x = 6-0 = 6, y = 26-25 = 1).Em uma situação real, essa bola seria dividida em
n blocos, mas isso não muda a essência da questão.
Os objetos no quadro se movem em três dimensões; portanto, quando a bola se move, ela pode se tornar visualmente menor (ou mais se se mover em direção ao espectador). É normal que não haja combinação perfeita entre os blocos. Aqui está uma visão combinada de nossa avaliação e da imagem real.

Mas vemos que, quando aplicamos a estimativa de movimento, os dados para codificação são muito menores do que quando usamos o método mais simples de calcular o delta entre os quadros.

Como será a compensação de movimento real
Essa técnica se aplica imediatamente a todos os blocos. Freqüentemente, nossa bola em movimento condicional será dividida em vários blocos ao mesmo tempo.

,
Jupyter .
ffmpeg .
 ffmpeg") Intel Video Pro Analyzer
Intel Video Pro Analyzer ( , , ).
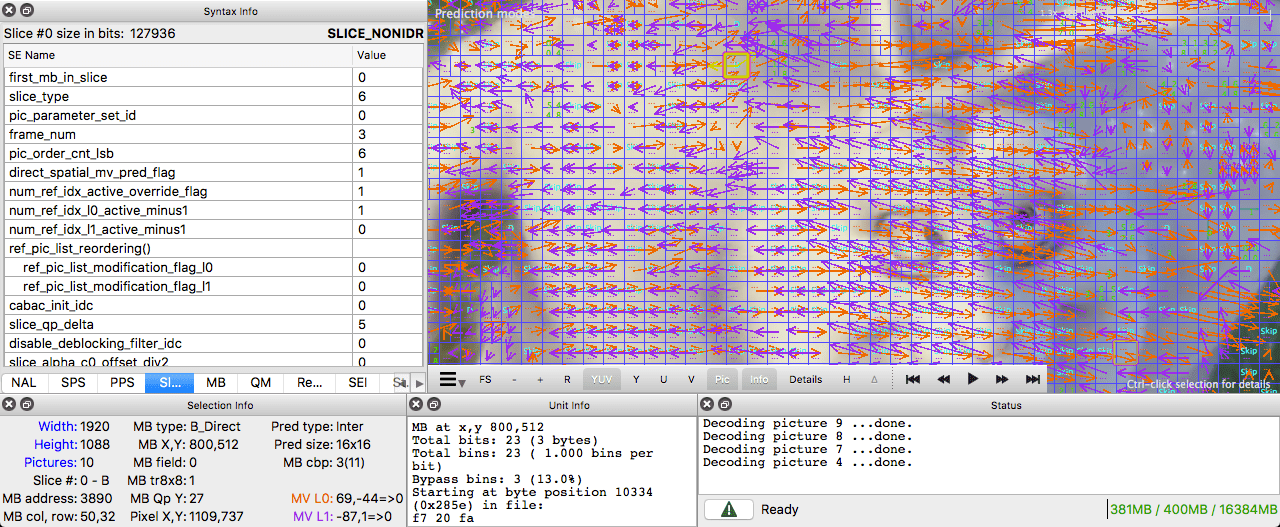
( )
, .

. .

I-. , . . , , - .
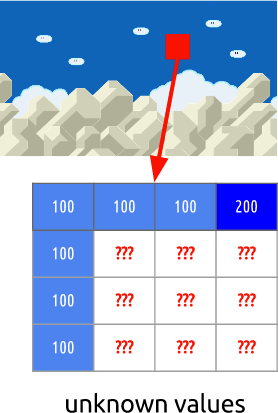
, . , .
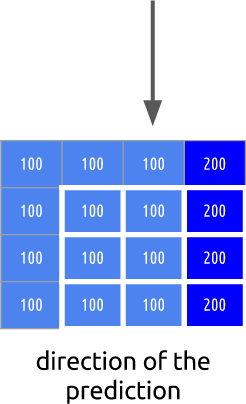
. ( ), . , .
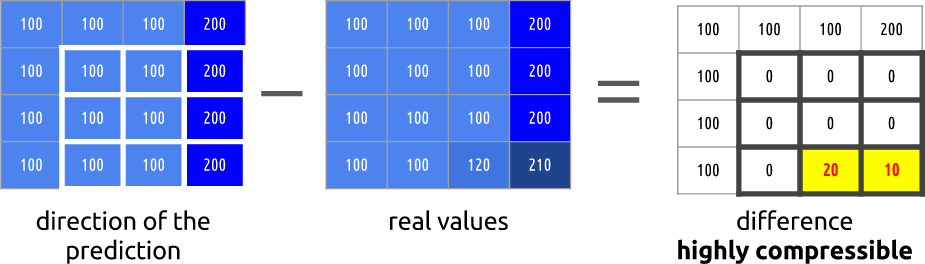
, ffmpeg. ffmpeg.
 ffmpeg")
Intel Video Pro Analyzer ( , 10 , ).

:

Leia também o blog
Empresa EDISON:
20 bibliotecas para
aplicação iOS espetacular