Para quem não gosta de longas introduções, vamos direto às conclusões - escreva testes para seus componentes. Sério, isso é tudo o que quero dizer. Mas não vamos levar isso muito a sério, imagine que essas são as conclusões de um teorema, um teorema de frontend. E agora, precisaremos apresentar evidências.
Então, vamos imaginar. O que é comum no desenvolvimento de TI, não apenas no frontend, backend ou design, linguagens de programação, gerenciamento, metodologias e assim por diante? Eu acho que existe o único princípio principal - decomposição e componentes.
Quer queiramos ou não, se entendemos o que escrevemos ou não, trabalhamos com componentes, sempre decompomos tarefas em tarefas menores.
E nos reunimos pela milionésima vez para escrever a próxima implementação da tabela para o nosso lindo kit de interface do usuário interno, pensei - que trabalho preliminar eu preciso fazer? O que exatamente deve ser escrito? E por onde começar?

Depois de conversar com colegas de equipe, ouvi algumas dicas. Eu realmente gostei de um. Como sou fã da singularidade e um pouco do graphql, me pediram para não escrever nada. Use a tag {table} e alguma rede neural processará essa tabela, criará uma consulta graphql e preencherá a tabela com dados. Fácil :).
Mas como eles dizem - "existe uma falha fatal em qualquer sistema", comecei a pensar em "como inventar minha própria roda". E pessoas inteligentes já inventaram tudo diante de nós. Nós, os millennials, só podemos reorganizar os pratos e nomear as coisas de maneira diferente.
Estou pronto para apresentar meu próprio conjunto de princípios de prototipagem de kits de interface do usuário - IDOLS! Vamos dar uma olhada!
Eu defendo segregação de interface, D defendo inversão de dependência, O significa ... apenas brincando, é claro, é SOLID
Todas as tentativas de formalizar o trabalho com componentes são reduzidas a isso. Esses princípios podem ser expandidos indefinidamente, mas tudo é sempre o resultado final reduzido a esses cinco. Se estamos falando, é claro, de OOP ou CBP (programação baseada em componentes).
Vamos carregar esses princípios em nossa “RAM” e analisar os pontos.
S - Responsabilidade Única

Hmm, por favor não ...
Use um componente especial para diferentes casos. Você NÃO deve fazer um componente que possa cortar e arrancar algo ao mesmo tempo. Faça duas peças diferentes.
O - Aberto / Fechado
O princípio diz que seus componentes devem estar abertos para aprimoramentos e fechados para modificações; em outras palavras, você pode reutilizar seu componente em outro componente, mas não deve alterá-lo se ele já obedecer ao princípio da responsabilidade única.
L - substituição de Liskov
Uma pequena extensão do princípio anterior, qualquer instância de uma subclasse pode ser usada em vez de uma instância da classe base. Não tenho certeza de como esse princípio se encaixa no contexto dos componentes, provavelmente será apenas uma duplicação do princípio anterior.
I - Segregação de interface
Falaremos sobre isso ainda mais, agora podemos dizer que é melhor oferecer ao outro desenvolvedor muitas interfaces pequenas do que uma grande, mas para tudo. Vamos comparar os exemplos abaixo.
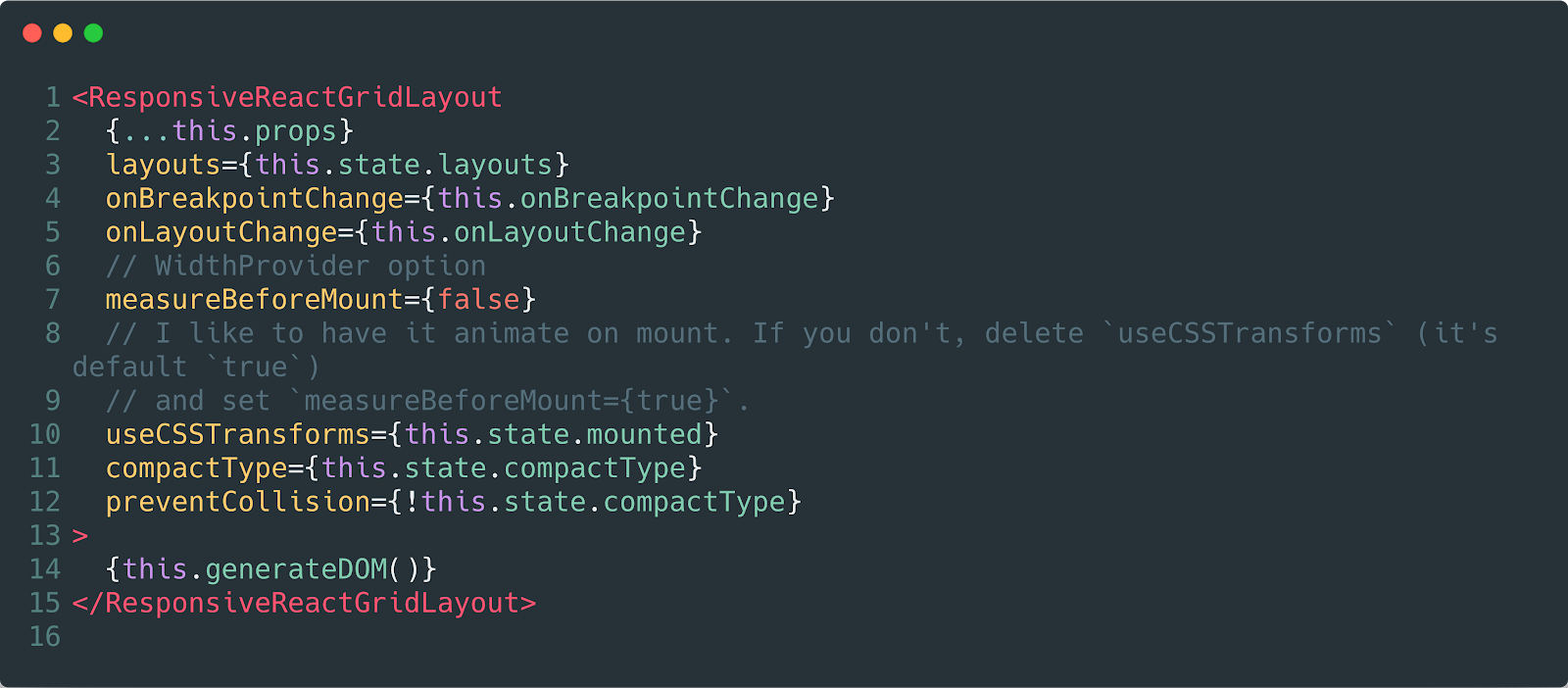
Tudo está se configurando em um só lugar, não sustentável, não reutilizável ...
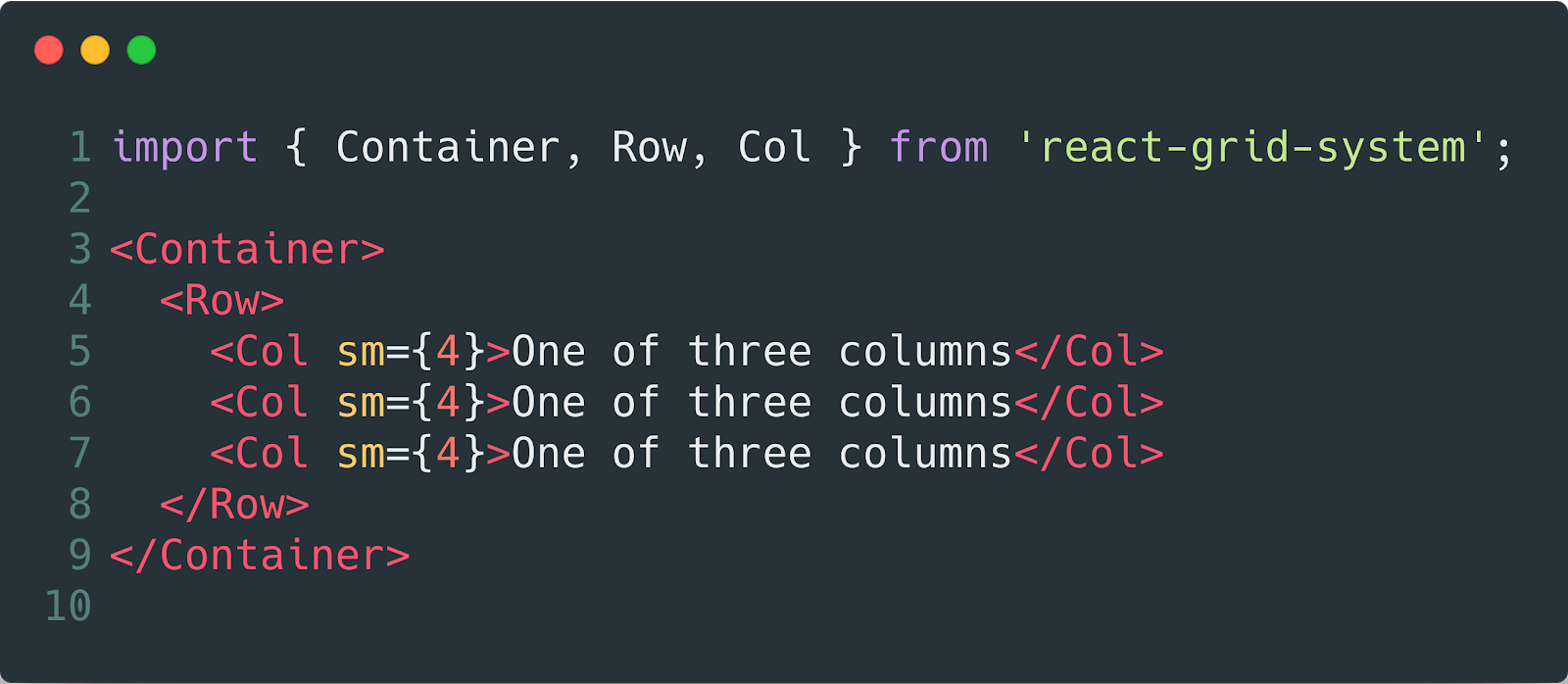
Tudo como construtor, monte como quiser e convenientemente
D - Inversão de dependência
O princípio de que as várias partes do aplicativo não devem saber nada umas das outras e devem ser herdadas apenas por meio de interfaces comuns. Aqui estamos falando mais sobre reutilização e redução da conexão de componentes. O componente da Tabela não precisa saber de onde e como os dados vêm, ele precisa apenas conhecer o DataLoader condicional, que pode ser qualquer coisa.

Mas um ponto de vista não é suficiente para nós. Como nessa situação, é muito fácil se tornar refém dessa ideia. Portanto, analisamos o desenvolvimento de componentes, por outro lado, do lado do design.
Nesse caso, consideraremos uma das abordagens de design cada vez mais populares, o design atômico. Relativamente falando, o design atômico é outra maneira de decompor os elementos da interface do usuário comparando-os com uma hierarquia da física e da biologia.
Então, vamos dar uma olhada, o que é design atômico.
Tokens
O primeiro nível é de tokens, alguém inclui isso no modelo, alguém não, mas vale a pena mencionar. Tokens (cores, tamanhos de fonte, espaçamentos, animações) são todas as primitivas que podemos reutilizar em qualquer plataforma.
Vale a pena notar que, quanto mais altos estamos na hierarquia no design atômico, mais a reutilização diminui. Mas mais sobre isso mais tarde.
Átomos
A seguir estão os átomos (componentes simples sem lógica, entradas, botões). O primeiro nível é onde os componentes aparecem e o que eles produzem. Os átomos não têm nenhum estado, apenas mostram a marcação com estilo estático.
Moléculas
Os átomos então se agrupam em moléculas (ligações componentes mais complexas). As moléculas podem ter um estado próprio, mas esse não é um estado comercial, pode ser um estado configuracional (como isOpen). Podemos supor que as moléculas são mais como um proxy entre os principais estados comerciais e como alinhamos o conteúdo de nossos átomos ou filhos, dependendo desse estado.
As moléculas são o último nível em que podemos encontrar estilos.
Organismos
As moléculas compõem organismos (grupos de trabalho integrais de componentes), por exemplo, cabeçalho, rodapé e assim por diante. Os organismos não sabem nada sobre outros organismos e estilos; esses são nossos "recipientes de DNA", nossa lógica de negócios, que sabem como mostrar isso e quando deve ser mudado.
Modelos / Páginas
O último nível de design atômico. Este nível representa os grupos de organismos incluídos na página atual.
Podemos fazer a composição dos organismos na página por meio de moléculas e depois chamá-la como "layout" e reutilizá-la, alterando nossos organismos dentro dela.
Usando essas duas abordagens (SOLID e Atomic), tentaremos formular algumas recomendações ao desenvolver componentes. Portanto, essas recomendações serão necessárias para entendermos o que exatamente estamos fazendo quando dizemos "criar outro componente".
Considerando que esses componentes trabalharão com outros desenvolvedores, teremos isso em mente quando definirmos a interface e a API.
Podemos começar a desenvolver nossa interface ideal.
A primeira coisa a começar é não começar a desenvolver uma interface ideal. A interface ideal é a sua falta. Uma interface é um obstáculo entre o que você fez e quando começa a funcionar. Isso é uma dor que deve ser evitada.
Assim, a melhor solução seria a seguinte:
Isso nos leva ao seguinte:
1. Determine o estado do componente
Se um desenvolvedor que usa esse componente o vir pela primeira vez, faça um pouco de integração, traduza o componente em novos estados à medida que a complexidade das configurações aumenta e conte ao desenvolvedor sobre isso.

Os estados podem ser completamente diferentes em momentos diferentes.
Vazio → Fazendo o download → Carregando → Carregando outra parte → Totalmente carregado → Erro, etc.
Guie os desenvolvedores por todas as combinações possíveis de estados, ensine-os enquanto eles trabalham.
Ao lidar com questões de estado, involuntariamente se depara com o problema de estados padrão. Por causa disso, a segunda recomendação.
2. Defina os valores padrão
Com esse item, você pode matar dois coelhos com uma cajadada, além de fornecer informações básicas ao desenvolvedor sobre o que está acontecendo com o aplicativo, mas para você, a ausência de uma ou outra variável não será uma surpresa que quebra tudo. Além disso, verificações feias de sua presença em princípio não são necessárias.

Além disso, se o desenvolvedor ainda deseja adicionar configurações, é necessário ajudá-lo e não interferir.
Dada a teoria de Richard Gregory, as pessoas exploram o mundo ao seu redor com base em experiências visuais anteriores. E se o seu componente mudar alguma coisa e você quiser que o desenvolvedor saiba sobre isso, ligue para ganchos e retorno de chamada de forma previsível.
3. Não há necessidade de reinventar a roda
Não changePasswordInputValue, mas onChange, porque se for sua "molécula", sempre ficará claro qual será o valor alterado.
Bem, tente seguir as regras gerais de nomenclatura, o prefixo on para eventos, verbos para ações e, se você usar o sinalizador booleano isDisabled em um local, use-o em qualquer lugar, não precisará mais do isEnabled, seja consistente.
A próxima coisa que você deve prestar atenção é que, quando você terminar de trabalhar no componente, o repassará, outros desenvolvedores continuarão trabalhando com ele. E se algo der errado com o seu componente, você terá que iniciar um novo círculo de desenvolvimento: o desenvolvedor encontra um bug ou não pode fazer o que deseja → abre um problema → está procurando um tempo para corrigi-lo → considere a consistência → consertar → atualizar pacotes → anunciar aos desenvolvedores → atualizar pacotes → tentar fazer o que eles queriam há uma semana.
4. Tente dar aos desenvolvedores o máximo controle possível
Como se eles tivessem escrito esse componente agora - uma conclusão direta de um dos princípios do SOLID
Suponha que você permita que um pedaço de texto seja passado para o seu componente. Se esse texto estiver presente, ele será exibido, mas você também se lembrará da regra sobre estados padrão e gravará a condição de que, se o texto não for transmitido, mostre o texto padrão. Portanto, em um bom tom, o desenvolvedor indicará explicitamente que o texto não é necessário aqui.
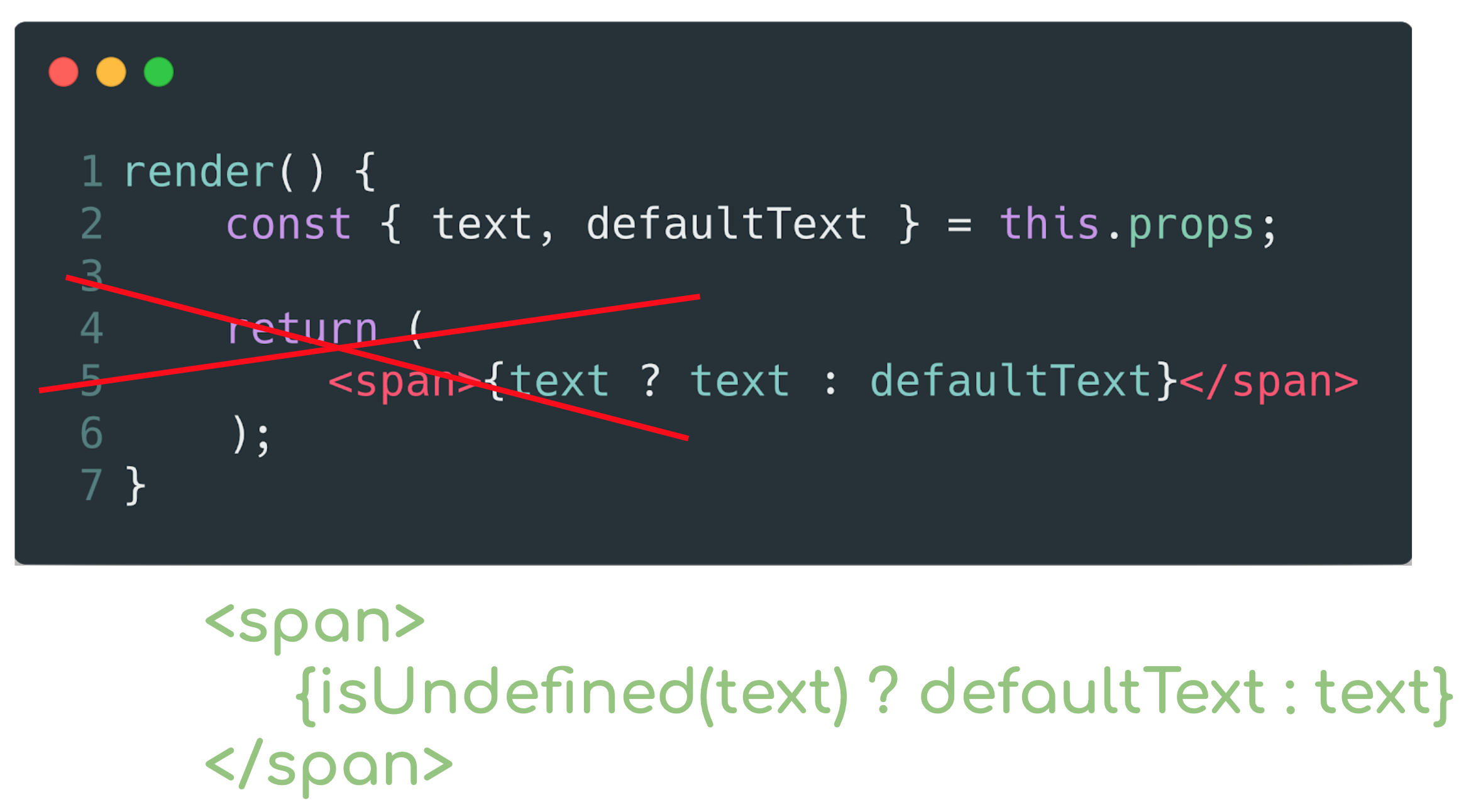
Bem, se você considera que, em primeiro lugar, começamos a trabalhar com componentes atômicos, a recomendação a seguir vem daqui.
5. Mantenha seus componentes limpos e secos para que as abstrações não vazem (KISS).
Como seguir isso? - simplesmente, não escreva código no seu componente. Somente o modelo e como ele desenha os dados de entrada. Se você precisar criar mapa, filtrar, reduzir os dados, você tem constantes que não podem ser redefinidas fora, seu modelo usa literais, o que está errado - ele não é mais um átomo, mas algo mais, é mais difícil de manter. Isso deve ser evitado.
Portanto, recebemos uma lista restrita de recomendações que seria bom seguir.
- Definir estado
- Definir valor padrão
- Não reinvente a roda
- Deixe que eles (devs) governem
- Mantenha as coisas simples, estúpidas (KISS)
Mas nosso cérebro está tão organizado que, depois de escrever alguns componentes, começamos a pensar que não precisamos examinar esta lista para verificar todos os pontos. E sabemos que, entre as tarefas mais complexas e as mais fáceis, sempre escolhemos a mais fácil, porque funciona assim. Adoramos economizar nossa energia, precisamos dela, em reserva. Portanto, essas listas são sempre perdidas na confluência até tempos melhores, e continuamos corrigindo erros no mestre.
Somente se entendermos que tornar as coisas mais inteligentes para nós, em geral, será mais fácil do que não dormir por duas semanas seguidas, corrigindo bugs na produção, tornaremos a tarefa mais difícil (por razões objetivas) e mais fácil (para nossos razões).
Como, então, enganar nosso cérebro e fazer recomendações funcionarem?
Bem, vamos tentar automatizar isso.
Automatização
Podemos usar o pacote eslint + lefthook ou qualquer outra ferramenta git-hooks.
Descrevemos as regras de como queremos ver nossas variáveis e como nosso código deve ser estilizado. Proibimos números mágicos e literais em modelos, esperamos de nós que escrevamos docas para nosso código imediatamente. Desligamos essas verificações para obter um gancho git e recebemos notificações automáticas de que nosso código está incorreto e deve ser atualizado.
Mas isso não é uma bala de prata e não podemos cumprir todas as recomendações. Apenas uma parte.

Dessa forma, não podemos lidar com nossos possíveis estados e não podemos garantir que outros desenvolvedores obtenham o que desejam. Podemos apenas assumir, por exemplo, que algo retornará de qualquer maneira (também conhecido como valor padrão), mas não mais.
Então você pode tentar de outra maneira. Desenvolva nossos componentes através do SDD. Desenvolvimento Dirigido por Livro de Histórias.
Desenvolvimento dirigido por livro de histórias
Temos um arquivo de história no formulário em que descrevemos todos os estados possíveis do componente. E um livro de histórias coletando essas histórias.
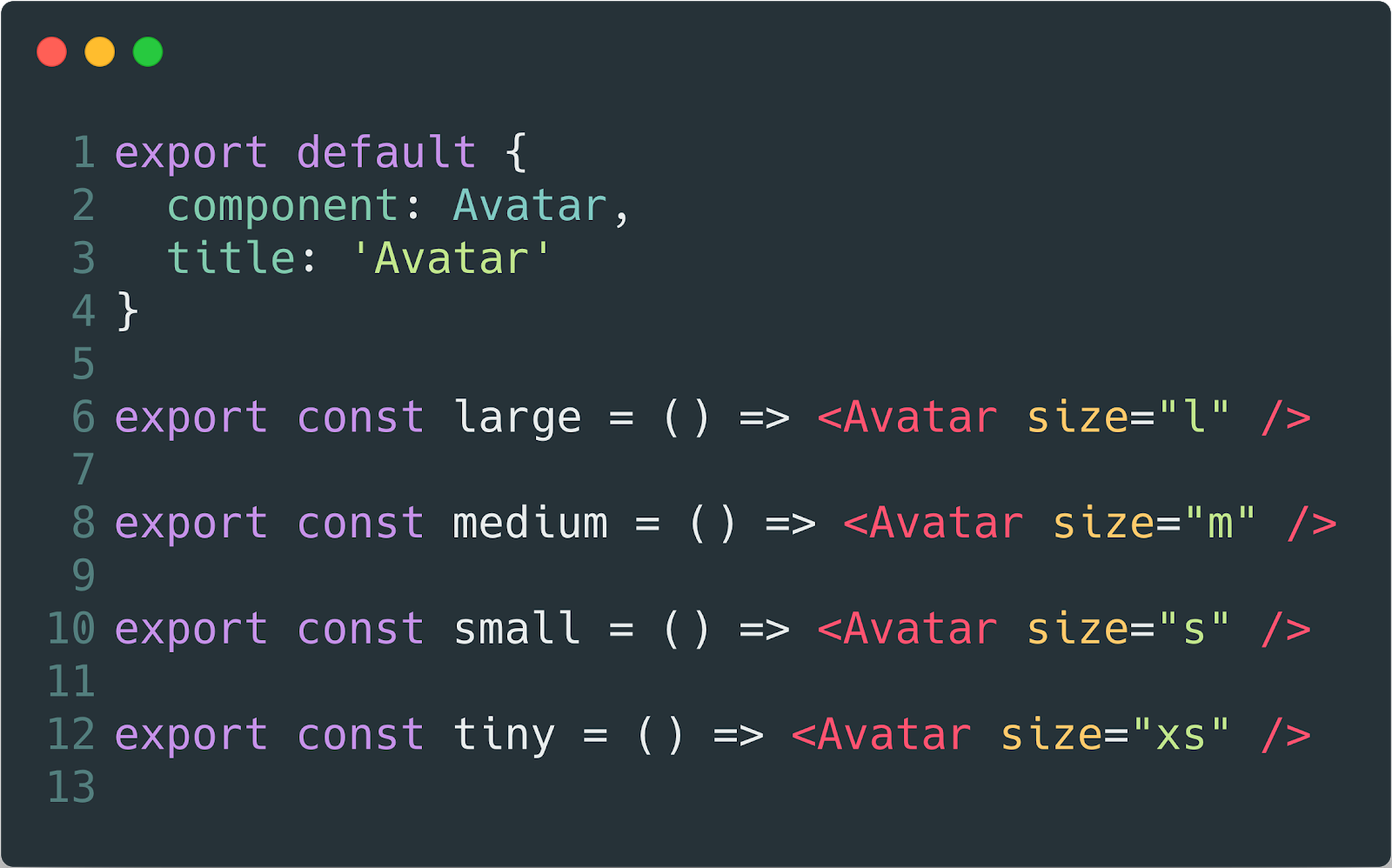
Nossas histórias sobre componentes
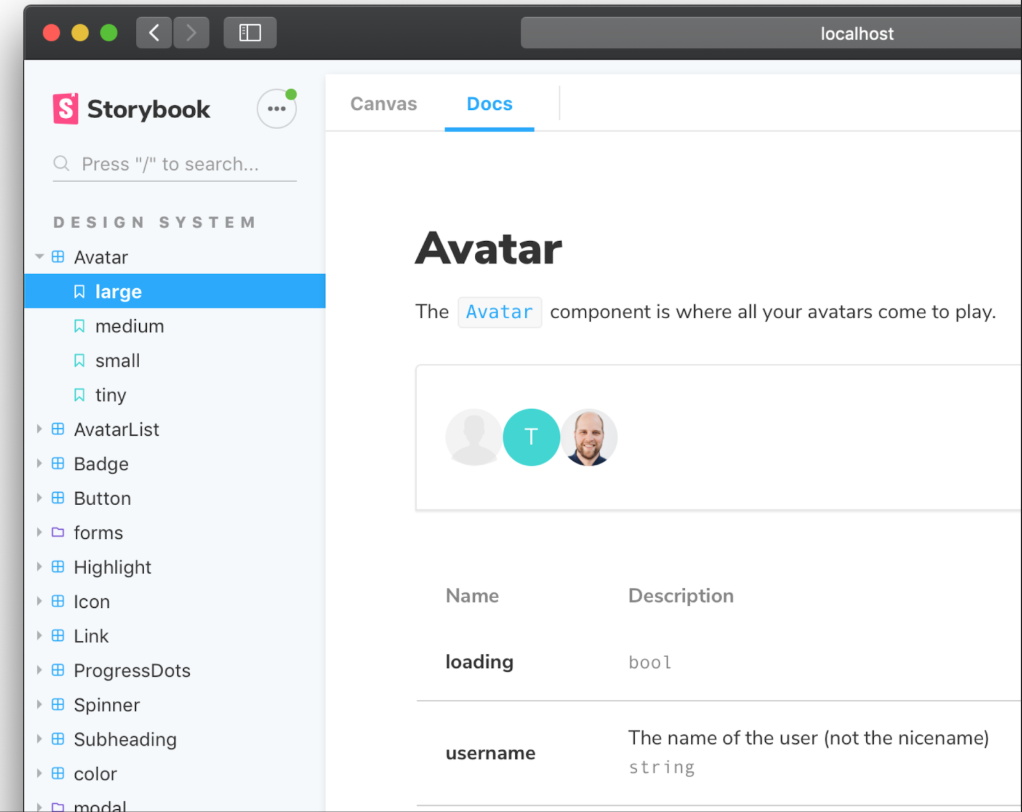
Como o livro de histórias nos mostra histórias
Desenvolver seus componentes isoladamente do ambiente de trabalho não é apenas uma vantagem à pureza dos componentes, mas também permitirá que você veja imediatamente quais estados não são cobertos pelos testes e quais, em princípio, estão ausentes.
Mas no final, isso também não vai nos dar tudo o que queremos.

Portanto, apenas uma coisa permanece.
Testes e Instantâneos
Como nossos componentes são átomos e moléculas, torna-se um prazer escrever testes de unidade, cada componente é responsável por uma funcionalidade que podemos testar facilmente descartando vários itens da lista de recomendações de uma só vez.
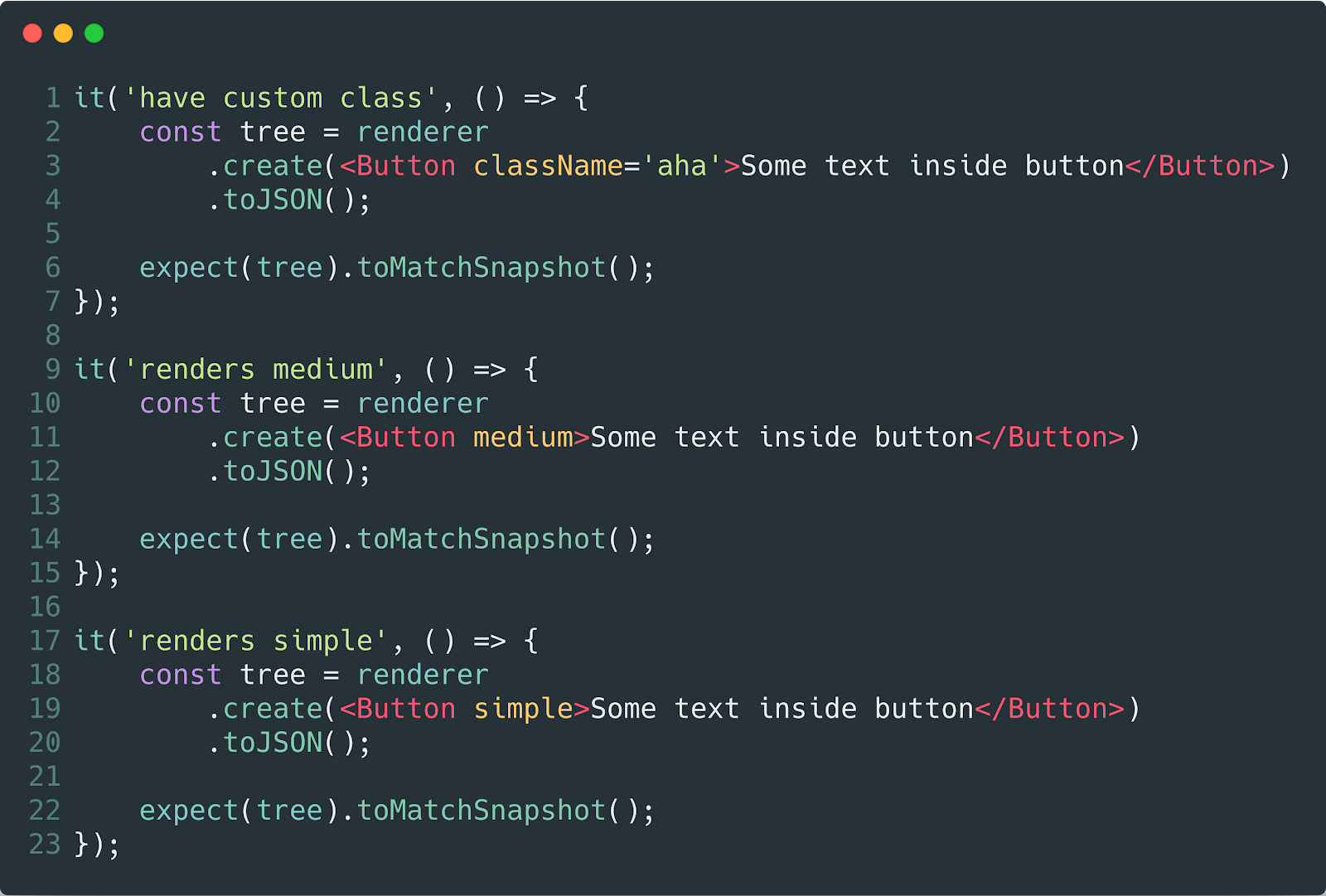
Podemos configurar verificações de instantâneo, o que nos permitirá monitorar o estado de nossos componentes e aprender todas as alterações no futuro.
Podemos usar um pacote com uma enzima para controlar nossas expectativas durante o desenvolvimento. E, estranhamente, quando se trata de recomendações nas quais esperamos algo de um desenvolvedor que escreve código, apenas testes e sua escrita podem ser adequados. Eles foram literalmente inventados para isso.
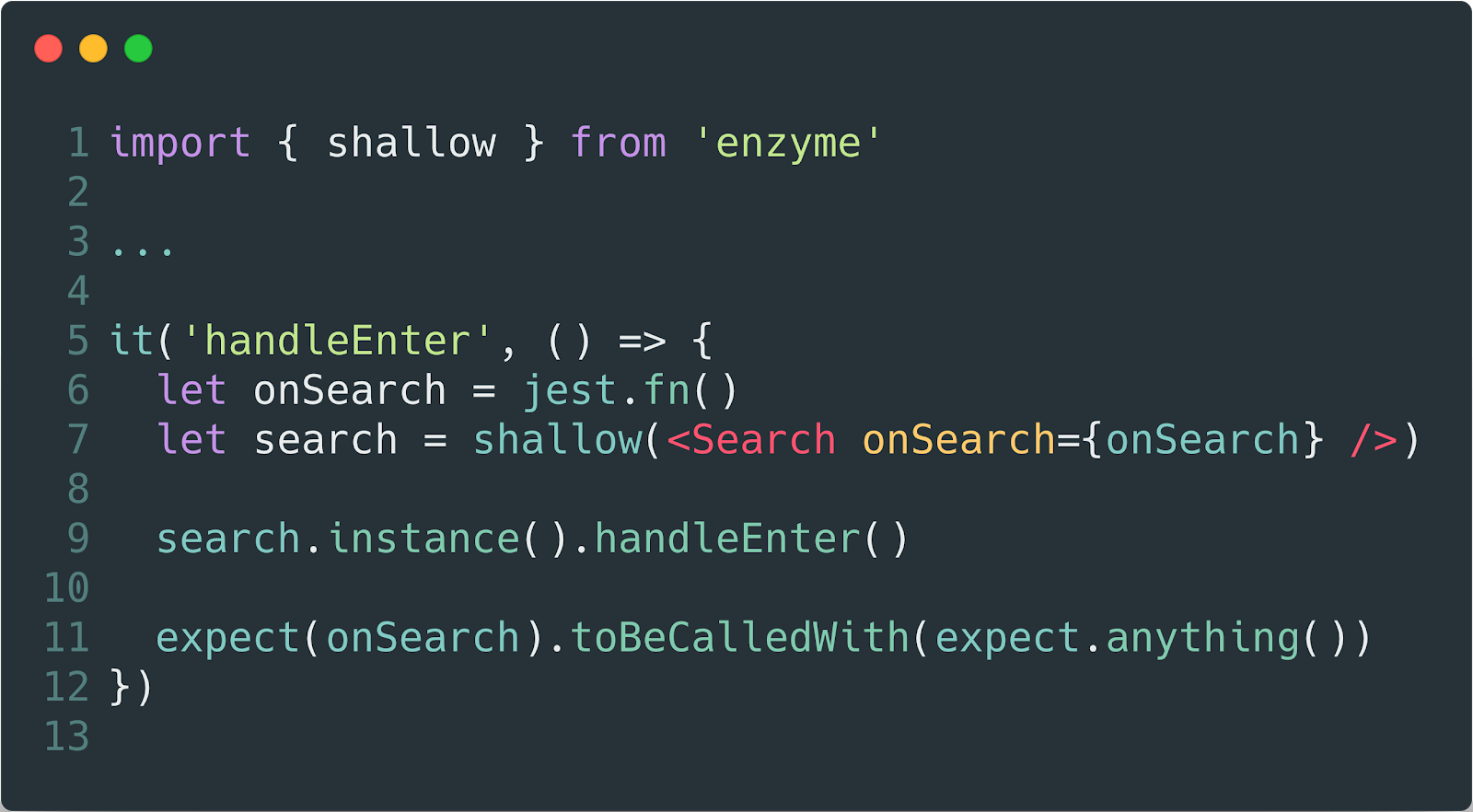
E aqui vamos nós ...

Escreva testes para seus componentes. Obrigado.