Há muito tempo é uma ideia ver o que você pode fazer com o ELK e fontes improvisadas de logs e estatísticas. Nas páginas do Habr, pretendo mostrar um exemplo prático de como, usando um mini-servidor doméstico, você pode criar, por exemplo, honeypot com um sistema de análise de logs baseado na pilha ELK. Neste artigo, mostrarei o exemplo mais simples de análise de logs de firewall usando a pilha ELK. No futuro, gostaria de descrever as configurações do ambiente para analisar o tráfego do Netflow e os dumps de pcap do Zeek.
Se você tiver um endereço IP público e um dispositivo mais ou menos inteligente como gateway / firewall, poderá organizar um honeypot passivo configurando solicitações de entrada para “deliciosas” portas TCP e UDP. Há um exemplo de configuração de um roteador Mikrotik sob um gato, mas se você tiver um roteador de fornecedor diferente (ou algum outro sistema de segurança) em mãos, precisará descobrir alguns formatos de dados e configurações específicas do fornecedor, e obterá o mesmo resultado.
Isenção de responsabilidade
O artigo não pretende ser original, não trata de questões de tolerância a falhas de serviços, segurança, práticas recomendadas etc. É necessário considerar este material como acadêmico, adequado para familiarizar-se com a funcionalidade básica da pilha ELK e o mecanismo de análise de log do dispositivo de rede. No entanto, também pode ser interessante para um iniciante.
O projeto é iniciado a partir do arquivo docker-compose, e é muito fácil implantar seu ambiente semelhante, mesmo que você tenha um roteador de outro fornecedor disponível, você só precisa entender um pouco sobre os formatos de dados e as configurações específicas do fornecedor. De resto, tentei descrever o máximo possível todas as nuances associadas à configuração dos pipelines do Logstash e dos mapeamentos do Elasticsearch na versão atual do ELK. Todos os componentes deste sistema estão hospedados no
github , incluindo configurações de serviço. No final do artigo, farei a seção Solução de problemas, que descreverá as etapas para diagnosticar os problemas populares recém-chegados a esse negócio.
1. Introdução
No próprio servidor, instalei o sistema de virtualização Proxmox, nele, na máquina KVM, os contêineres Docker são iniciados. Supõe-se que você saiba como o docker e o docker-componham funcionam, pois há exemplos de configuração suficientes sobre o uso da Internet. Não falarei sobre os problemas de instalação do Docker, vou escrever um pouco sobre o docker-compone.
A idéia de lançar o honeypot surgiu no processo de estudo do Elasticsearch, Logstash e Kibana. Na minha carreira profissional, nunca estive envolvido na administração e no uso geral dessa pilha, mas tenho projetos de hobby, graças aos quais desenvolvi um grande interesse em explorar as possibilidades oferecidas pelo mecanismo de pesquisa Elasticsearch e Kibana, com o qual é possível analisar e visualizar dados.
Meu não é o mais novo servidor mini NUC com 8 GB de RAM é suficiente para iniciar a pilha ELK com um nó Elastic. Em ambientes de produção, isso, obviamente, não é recomendado, mas apenas adequado para treinamento. Em relação à questão da segurança, há uma observação no final do artigo.
A Internet está cheia de instruções para instalar e configurar a pilha ELK para tarefas semelhantes (por exemplo,
analisar ataques de força bruta no ssh usando o Logstash versão 2 ,
analisando os logs do Suricata usando o Filebeat versão 6 ), mas, na maioria dos casos, não é dada a devida atenção aos detalhes. 90% do material será das versões 1 a 6 (no momento da redação deste documento, a versão atual do ELK é 7.5.0). Isso é importante porque, a partir da versão 6, o Elasticsearch
decidiu remover a entidade do tipo de mapeamento, alterando a sintaxe da consulta e a estrutura de mapeamento. O modelo de mapeamento no Elastic geralmente é um objeto muito importante e, para que mais tarde não haja problemas com a amostragem e visualização de dados, aconselho que você não se envolva em copiar e colar e tente entender o que está fazendo. Além disso, tentarei explicar claramente o significado das operações e configurações descritas.
Configuração do roteador
Para a rede doméstica, eu uso o Mikrotik como roteador, então um exemplo será para ele. Mas quase qualquer sistema pode ser configurado para enviar syslog para um servidor remoto, seja um roteador, um servidor ou algum outro sistema de segurança que possa registrar.
Enviando mensagens syslog para um servidor remoto
No Mikrotik, para configurar o registro em um servidor remoto através da CLI, basta digitar alguns comandos:
/system logging action add remote=192.168.88.130 remote-port=5145 src-address=192.168.88.1 name=logstash target=remote /system logging add action=logstash topics=info
Configurando regras de firewall com log
Estamos interessados apenas em determinados dados (nome do host, endereço IP, nome de usuário, URL etc.), dos quais você pode obter uma bela visualização ou seleção. No caso mais simples, para obter informações sobre varreduras de portas e tentativas de acesso, você precisa configurar o componente do firewall para registrar os acionadores de regras. No Mikrotik, configurei as regras na tabela NAT, não no Filter, já que no futuro vou colocar chanipots que emularão o trabalho dos serviços, isso permitirá que eu investigue mais informações sobre o comportamento das redes bot, mas esse é um cenário mais avançado e não sobre esse momento.
Atenção! Na configuração abaixo, a porta TCP padrão do serviço SSH (22) é colocada em loop na rede local. Se você usar o SSH para acessar o roteador de fora e as configurações tiverem a porta 22 (
serviço IP impresso nos
serviços CLI e
ip> no Winbox), você deve atribuir novamente a porta ao SSH de gerenciamento ou não inserir a última regra na tabela.
Além disso, dependendo do nome da interface WAN (se a ponte WAN não for usada), você precisará alterar o parâmetro
in-interface para o apropriado.
/ip firewall nat add action=netmap chain=dstnat comment="HONEYPOT RDP" dst-port=3389 in-interface=bridge-wan log=yes log-prefix=honeypot_rdp protocol=tcp to-addresses=192.168.88.201 to-ports=3389 add action=netmap chain=dstnat comment="HONEYPOT ELASTIC" dst-port=9200 in-interface=bridge-wan log=yes log-prefix=honeypot_elastic protocol=tcp to-addresses=192.168.88.201 to-ports=9211 add action=netmap chain=dstnat comment=" HONEYPOT TELNET" dst-port=23 in-interface=bridge-wan log=yes log-prefix=honeypot_telnet protocol=tcp to-addresses=192.168.88.201 to-ports=2325 add action=netmap chain=dstnat comment="HONEYPOT DNS" dst-port=53 in-interface=bridge-wan log=yes log-prefix=honeypot_dns protocol=udp to-addresses=192.168.88.201 to-ports=9953 add action=netmap chain=dstnat comment="HONEYPOT FTP" dst-port=21 in-interface=bridge-wan log=yes log-prefix=honeypot_ftp protocol=tcp to-addresses=192.168.88.201 to-ports=9921 add action=netmap chain=dstnat comment="HONEYPOT SMTP" dst-port=25 in-interface=bridge-wan log=yes log-prefix=honeypot_smtp protocol=tcp to-addresses=192.168.88.201 to-ports=9925 add action=netmap chain=dstnat comment="HONEYPOT SMB" dst-port=445 in-interface=bridge-wan log=yes log-prefix=honeypot_smb protocol=tcp to-addresses=192.168.88.201 to-ports=9445 add action=netmap chain=dstnat comment="HONEYPOT MQTT" dst-port=1883 in-interface=bridge-wan log=yes log-prefix=honeypot_mqtt protocol=tcp to-addresses=192.168.88.201 to-ports=9883 add action=netmap chain=dstnat comment="HONEYPOT SIP" dst-port=5060 in-interface=bridge-wan log=yes log-prefix=honeypot_sip protocol=tcp to-addresses=192.168.88.201 to-ports=9060 add action=dst-nat chain=dstnat comment="HONEYPOT SSH" dst-port=22 in-interface=bridge-wan log=yes log-prefix=honeypot_ssh protocol=tcp to-addresses=192.168.88.201 to-ports=9922
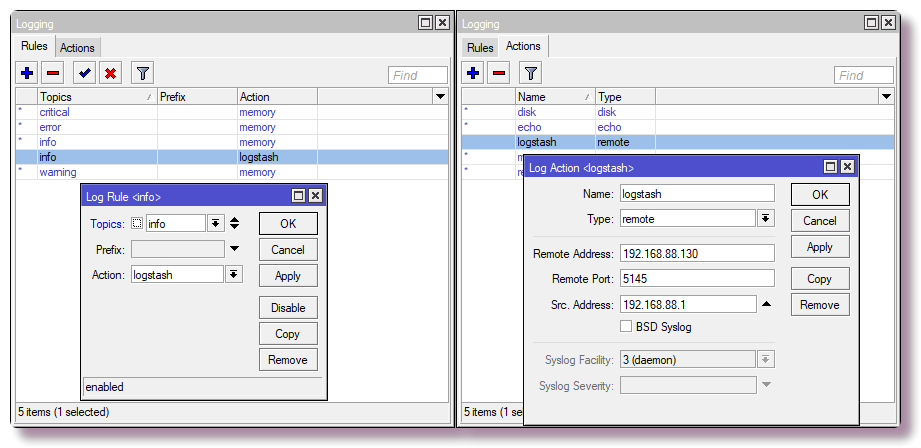
No Winbox, o mesmo está configurado na
guia IP> Firewall> NAT .
Agora, o roteador redirecionará os pacotes recebidos para o endereço local 192.168.88.201 e a porta personalizada. No momento, ninguém está ouvindo essas portas, portanto as conexões serão interrompidas. No futuro, na janela de encaixe, você poderá executar o honeypot, dos quais existem muitos para cada serviço. Se isso não for planejado, em vez das regras NAT, você deve escrever uma regra com a ação de queda na cadeia Filtro.
Iniciando o ELK com docker-compose
Em seguida, você pode começar a configurar o componente que processará os logs. Eu aconselho você a praticar imediatamente e clonar o repositório para ver os arquivos de configuração completamente. Todas as configurações descritas podem ser vistas lá. No texto do artigo, copiarei apenas parte das configurações.
❯❯ git clone https://github.com/mekhanme/elk-mikrot.git
Em um ambiente de teste ou desenvolvimento, é mais conveniente executar contêineres do docker usando o docker-compose. Neste projeto, eu uso o arquivo docker-compose da
versão mais
recente 3.7 no momento, ele requer o mecanismo docker versão 18.06.0+, portanto, vale a pena atualizar o
docker , bem como o
docker-compose .
❯❯ curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose ❯❯ chmod +x /usr/local/bin/docker-compose
Como nas versões recentes do docker-compose, o parâmetro mem_limit foi
cortado e a
implementação foi adicionada, que é executada apenas no modo enxame (
implantação da pilha do docker ), o lançamento da configuração do
docker-compose com limites leva a um erro. Como não uso o enxame e quero ter limites de recursos, tenho que iniciá-lo com a opção
--compatibility , que converte os limites de novas versões do docker-componha para o equivalente não-soldável.
Execução de teste de todos os contêineres (no segundo plano -d):
❯❯ docker-compose --compatibility up -d
Você terá que esperar até que todas as imagens sejam baixadas e, após a conclusão da inicialização, você pode verificar o status dos contêineres com o comando:
❯❯ docker-compose --compatibility ps
Devido ao fato de todos os contêineres estarem na mesma rede (se você não especificar explicitamente a rede, uma nova ponte será criada, o que é adequado nesse cenário) e o docker-compose.yml contém o parâmetro container_name para todos os
contêineres , os contêineres já terão conectividade por meio do DNS interno janela de encaixe. Como resultado, não é necessário registrar endereços IP nas configurações de contêiner. Na configuração do Logstash, a sub-rede 192.168.88.0/24 é registrada como local. Além disso, na configuração, haverá explicações mais detalhadas, segundo as quais você pode desviar o exemplo da configuração antes de iniciar.
Configurar serviços ELK
Além disso, haverá explicações sobre como configurar a funcionalidade dos componentes ELK, além de mais algumas ações que precisarão ser executadas no Elasticsearch.
Para determinar as coordenadas geográficas por endereço IP, você precisará fazer o download do banco de dados
GeoLite2 gratuito do MaxMind:
❯❯ cd elk-mikrot && mkdir logstash/geoip_db ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-City-CSV.zip && unzip GeoLite2-City-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-City-CSV.zip ❯❯ curl -O https://geolite.maxmind.com/download/geoip/database/GeoLite2-ASN-CSV.zip && unzip GeoLite2-ASN-CSV.zip -d logstash/geoip_db && rm -f GeoLite2-ASN-CSV.zip
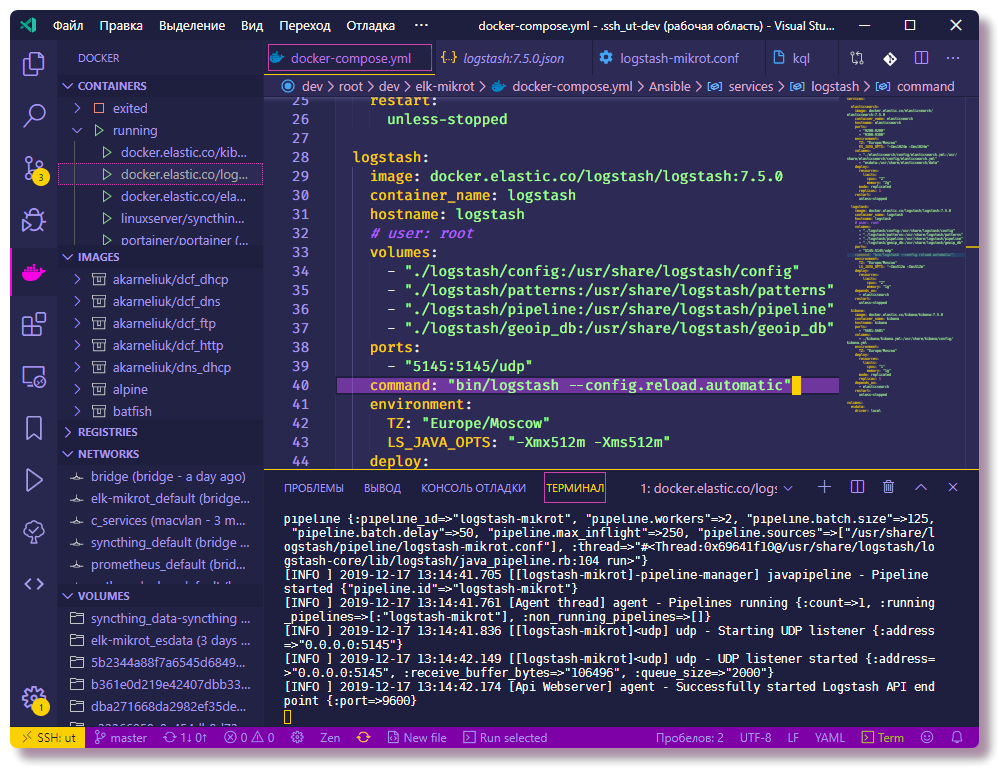
Configuração do Logstash
O arquivo de configuração principal é
logstash.yml , onde registrei a opção de recarregar automaticamente a configuração, o restante das configurações do ambiente de teste não são significativas. A configuração do processamento de dados (logs) no Logstash é descrita em arquivos
conf separados, geralmente armazenados no diretório de
pipeline . No esquema, quando
vários pipelines são usados, o arquivo
pipelines.yml descreve os
pipelines ativados. Um pipeline é uma cadeia de ações em dados não estruturados para receber dados com uma estrutura específica na saída. Um esquema com
pipelines.yml configurado separadamente é opcional, você pode fazer isso sem fazer o download de todas as configurações do diretório de
pipeline montado, no entanto, com um arquivo
pipelines.yml específico, a configuração é mais flexível, pois é possível ativar e desativar os arquivos
conf do diretório de
pipeline configurações necessárias. Além disso, recarregar configurações só funciona no esquema de vários pipelines.
❯❯ cat logstash/config/pipelines.yml - pipeline.id: logstash-mikrot path.config: "pipeline/logstash-mikrot.conf"
Em seguida, vem a parte mais importante da configuração do Logstash. A descrição do pipeline consiste em várias seções - no início, os plugins são indicados na seção
Entrada com a ajuda da qual o Logstash recebe dados. A maneira mais fácil de coletar o syslog de um dispositivo de rede é usar os plugins de entrada
tcp /
udp . O único parâmetro necessário para esses plug-ins é
porta , ele deve ser especificado da mesma forma que nas configurações do roteador.
A segunda seção é
Filtro , que prescreve ações adicionais com dados que ainda não foram estruturados. No meu exemplo, mensagens syslog desnecessárias de um roteador com determinado texto são excluídas. Isso é feito usando a condição e a ação de descarte padrão, que descarta a mensagem inteira se a condição for atendida. Na
condição , o campo da
mensagem é verificado quanto à presença de determinado texto.
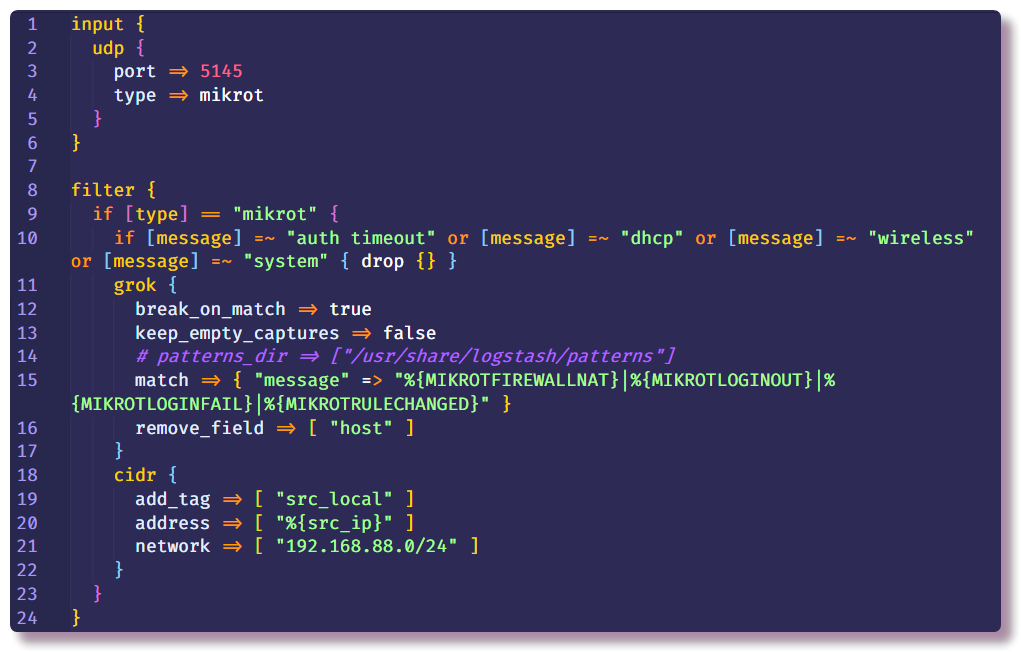
Se a mensagem não cair, ela desce mais a corrente e entra no filtro do
grok . Como a documentação diz, o
grok é uma ótima maneira de analisar dados de log não estruturados em algo estruturado e consultável . Este filtro é usado para processar logs de vários sistemas (syslog linux, servidor web, banco de dados, dispositivos de rede, etc.). Com base em
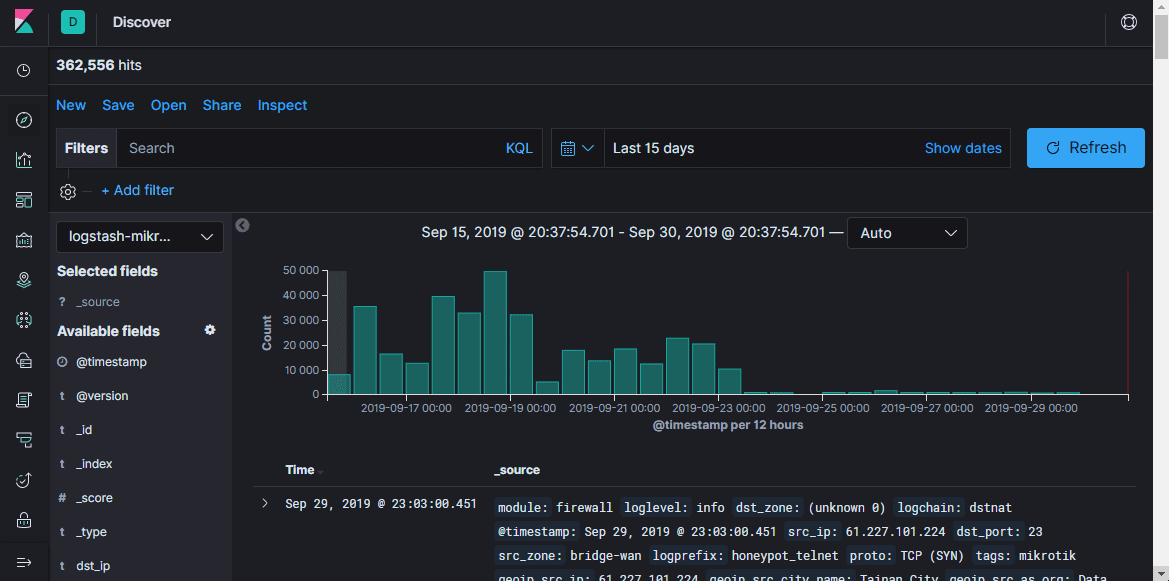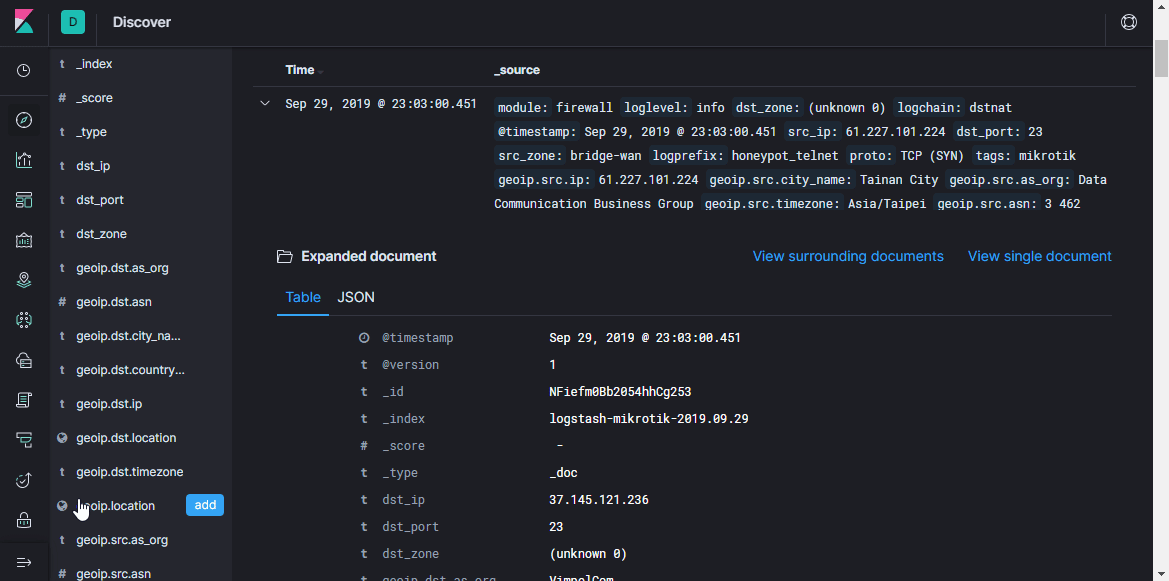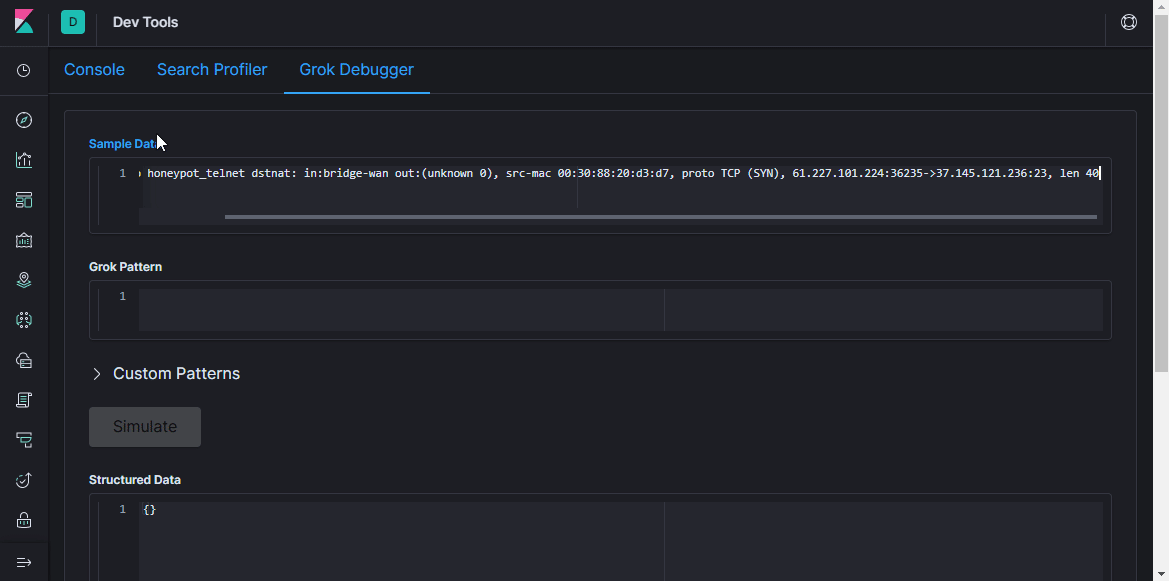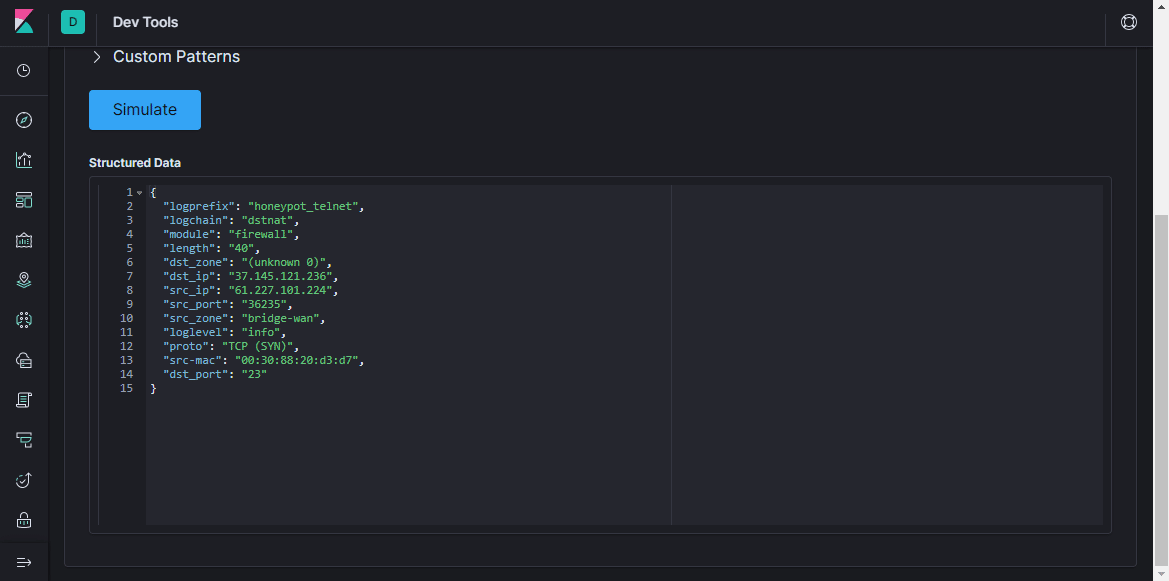
padrões prontos, você pode, sem gastar muito tempo, criar um analisador para qualquer sequência mais ou menos repetitiva. É conveniente usar um
analisador online para validação (na versão mais recente do Kibana, funcionalidade semelhante está na seção
Ferramentas de Desenvolvimento ).
O volume
"./logstash/patterns:/usr/share/logstash/patterns" está registrado no
docker-compose.yml , no diretório
patterns existe um arquivo com padrões da comunidade padrão (apenas por conveniência, veja se eu esqueci), bem como um arquivo com padrões de vários tipos de mensagens Mikrotik (módulos
Firewall e
Auth) , por analogia, você pode adicionar seus próprios modelos para mensagens de uma estrutura diferente.
As opções padrão
add_field e
remove_field permitem adicionar ou remover campos da mensagem que está sendo processada dentro de qualquer filtro. Nesse caso, o campo
host é excluído, que contém o nome do host do qual a mensagem foi recebida. No meu exemplo, há apenas um host, portanto não há nenhum ponto nesse campo.
Além disso, na mesma seção
Filtro , registrei o filtro
cidr , que verifica o campo com o endereço IP quanto à conformidade com a condição de entrada na sub-rede fornecida e coloca a tag. Com base na tag na cadeia adicional, as ações serão executadas ou não (se especificamente, isso é para não fazer uma pesquisa geográfica para endereços locais no futuro).
Pode haver qualquer número de seções
Filtro , para que haja menos condições em uma seção. Na nova seção, defini ações para mensagens sem a tag
src_local , ou seja, os eventos do firewall são processados aqui, nos quais estamos interessados no endereço de origem.
Agora precisamos conversar um pouco mais sobre de onde o Logstash obtém as informações do GeoIP. O Logstash suporta bancos de dados GeoLite2. Existem várias opções de banco de dados, eu uso dois bancos de dados: GeoLite2 City (que contém informações sobre o país, cidade, fuso horário) e GeoLite2 ASN (informações sobre o sistema autônomo ao qual o endereço IP pertence).

O plug-in
geoip também está envolvido na adição de informações de GeoIP à mensagem. A partir dos parâmetros, você deve especificar o campo que contém o endereço IP, a base usada e o nome do novo campo no qual as informações serão gravadas. No meu exemplo, o mesmo é feito para o endereço IP de destino, mas até agora neste cenário simples essas informações não serão interessantes, pois o endereço de destino sempre será o endereço do roteador. No entanto, no futuro, será possível adicionar logs a esse pipeline não apenas do firewall, mas também de outros sistemas em que será relevante examinar os dois endereços.
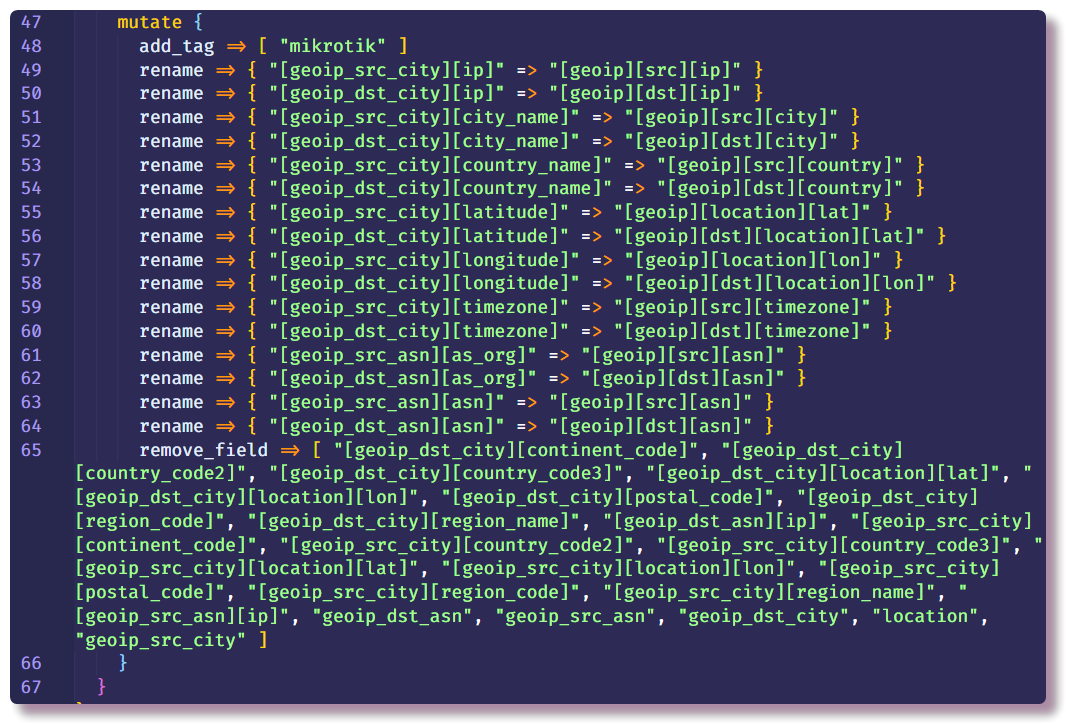
O filtro
mutate permite alterar os campos da mensagem e modificar o texto nos próprios campos; a documentação descreve em detalhes muitos exemplos do que você pode fazer. Nesse caso, é usado para adicionar uma tag, renomear campos (para visualização adicional de logs no Kibana, é necessário um determinado formato do objeto de
ponto geográfico , tocarei nesse tópico mais adiante) e excluir campos desnecessários.
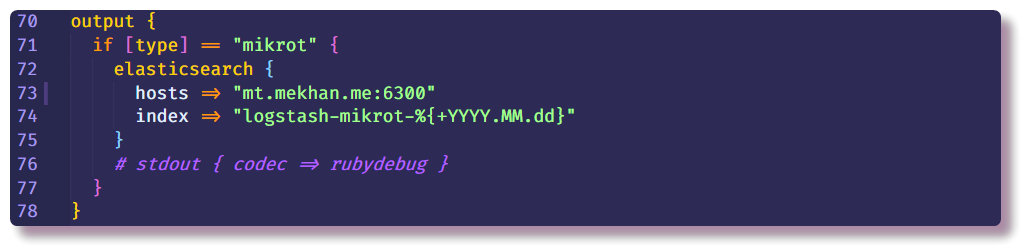
Isso encerra a seção de processamento de dados e pode indicar apenas para onde enviar uma mensagem estruturada. Nesse caso, o Elasticsearch coletará dados; você só precisará inserir o endereço IP, a porta e o nome do índice. É recomendável que você insira o índice com um campo de data variável, para que um novo índice seja criado todos os dias.
Configurando o Elasticsearch
Voltar para Elasticsearch. Primeiro, você precisa se certificar de que o servidor esteja em funcionamento. O Elastic é interagido com mais eficiência por meio da API Rest na CLI. Usando curl, você pode ver o estado do nó (substitua localhost pelo endereço IP do docker do host):
❯❯ curl localhost:9200
Depois, você pode tentar abrir o Kibana em
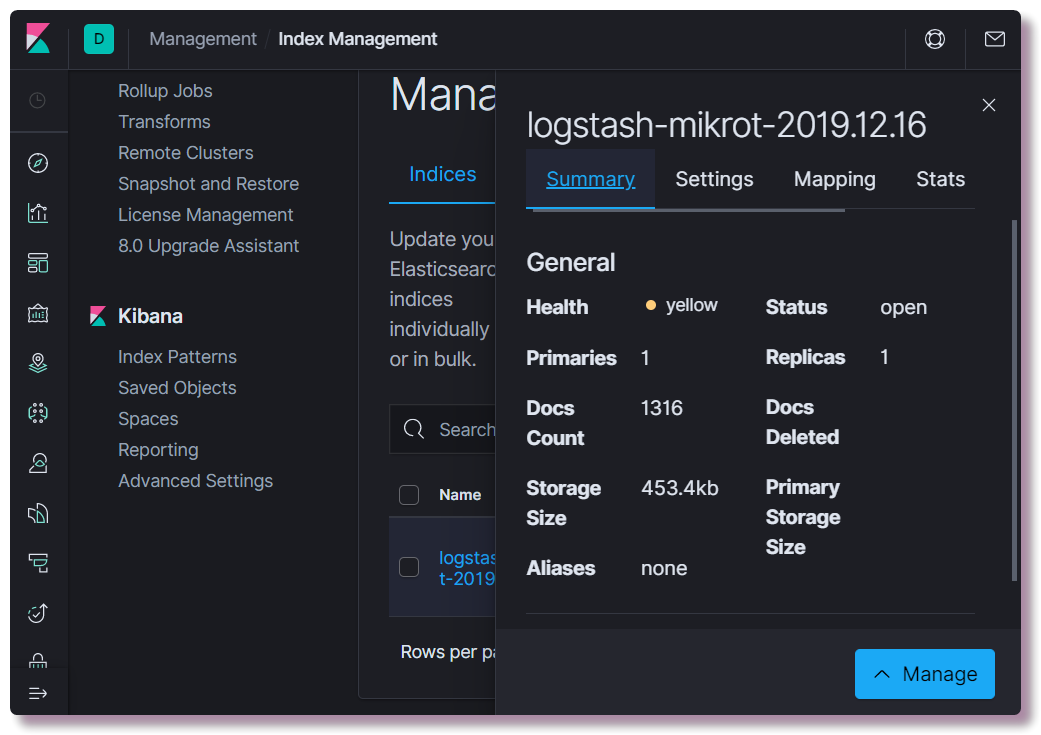
localhost : 5601. Não há necessidade de configurar nada na interface da web do Kibana (a menos que mude o tema para escuro). Estamos interessados em ver se um índice foi criado.Para fazer isso, abra a seção
Gerenciamento e selecione
Elasticsearch Index Management no canto superior esquerdo. Aqui você pode ver quantos documentos estão indexados, quanto ocupa espaço em disco, além de informações úteis sobre mapeamento de índice.
Nesse momento, você precisa registrar o modelo de mapeamento correto. Essas informações são necessárias para o Elastic para que ele entenda quais tipos de dados e quais campos pertencem. Por exemplo, para fazer seleções especiais baseadas em endereços IP, para o campo
src_ip ,
você deve especificar explicitamente o tipo de dados
ip e para determinar a localização geográfica, é necessário definir o campo
geoip.location em um formato específico e registrar o tipo
geo_point . Todos os campos possíveis não precisam ser descritos, pois para novos campos o tipo de dados é determinado automaticamente com base em padrões dinâmicos (
longo para números e
palavra -
chave para cadeias).
Você pode escrever um novo modelo usando curl ou diretamente no console do Kibana (seção
Dev Tools ).
❯❯ curl -X POST -H "Content-Type: application/json" -d @elasticsearch/logstash_mikrot-template.json http://192.168.88.130:9200/_template/logstash-mikrot
Após alterar o mapeamento, você precisa excluir o índice:
❯❯ curl -X DELETE http://192.168.88.130:9200/logstash-mikrot-2019.12.16
Quando pelo menos uma mensagem chegar no índice, verifique o mapeamento:
❯❯ curl http://192.168.88.130:9200/logstash-mikrot-2019.12.16/_mapping
Para uso adicional dos dados no Kibana, você precisa criar um
padrão em
Gerenciamento> Padrão de Índice Kibana . Digite o
nome do
índice com o símbolo * (
logstash-mikrot *) para que todos os índices correspondam, selecione o campo de
registro de data e hora como o campo com a data e a hora. No campo
ID do padrão de índice customizado , é possível inserir o ID do padrão (por exemplo,
logstash-mikrot ); no futuro, isso pode simplificar o acesso ao objeto.
Análise e visualização de dados em Kibana
Depois de criar o
padrão de índice , você pode prosseguir para a parte mais interessante - análise e visualização de dados. O Kibana tem muitas funcionalidades e seções, mas até agora estaremos interessados em apenas dois.
Descobrir
Aqui você pode visualizar documentos em índices, filtrar, pesquisar e visualizar as informações recebidas. É importante não esquecer a linha do tempo, que define o período nas condições de pesquisa.
Visualize
Nesta seção, você pode criar a visualização com base nos dados coletados. O mais simples é exibir as fontes das redes de bots de varredura em um mapa geográfico, pontilhado ou na forma de um mapa de calor. Também existem muitas maneiras de criar gráficos, fazer seleções etc.
No futuro, pretendo contar com mais detalhes sobre processamento de dados, possivelmente visualização, talvez algo mais interessante. No processo de estudo, tentarei complementar o tutorial.
Solução de problemas
Se o índice não aparecer no Elasticsearch, verifique primeiro os logs do Logstash:
❯❯ docker logs logstash --tail 100 -f
O Logstash não funcionará se não houver conectividade com o Elasticsearch, ou se um erro na configuração do pipeline for o principal motivo e isso se tornar claro após um estudo cuidadoso dos logs que são gravados no json docker por padrão.
Se não houver erros no log, você precisará garantir que o Logstash capture mensagens no soquete configurado. Para fins de depuração, você pode usar
stdout como
saída :
stdout { codec => rubydebug }
Depois disso, o Logstash gravará informações de debag quando a mensagem for recebida diretamente no log.
A verificação do Elasticsearch é muito simples - basta fazer uma solicitação GET se curvar no endereço IP e na porta do servidor ou em um terminal de API específico. Por exemplo, observe o status dos índices em uma tabela legível por humanos:
❯❯ curl -s 'http://192.168.88.130:9200/_cat/indices?v'
O Kibana também não será iniciado se não houver conexão com o Elasticsearch; é fácil ver isso pelos logs.
Se a interface da web não abrir, verifique se o firewall está configurado ou desativado corretamente no Linux (no Centos houve problemas com o
iptables e o
docker , eles foram resolvidos com base nas recomendações do
tópico ). Também vale a pena considerar que, em equipamentos pouco produtivos, todos os componentes podem carregar por vários minutos. Com falta de memória, os serviços podem não carregar. Exibir o uso de recursos do contêiner:
❯❯ docker stats
Se de repente alguém não souber como alterar corretamente a configuração de contêineres no
arquivo docker-compose.yml e reiniciar os contêineres, isso será feito editando o
docker-compose.yml e usando o mesmo comando com os mesmos parâmetros, reinicie:
❯❯ docker-compose --compatibility up -d
Ao mesmo tempo, nas seções alteradas, objetos antigos (contêineres, redes, volumes) são apagados e novos são recriados de acordo com a configuração. Os dados dos serviços não são perdidos ao mesmo tempo, uma vez que
são usados volumes nomeados , que não são excluídos com o contêiner e as configurações são montadas no sistema host, o Logstash pode até monitorar os arquivos de configuração e reiniciar a configuração do pipeline quando o arquivo é alterado.
Você pode reiniciar o serviço separadamente com o
comando docker restart (não é necessário estar no diretório com
docker-compose.yml) :
❯❯ docker restart logstash
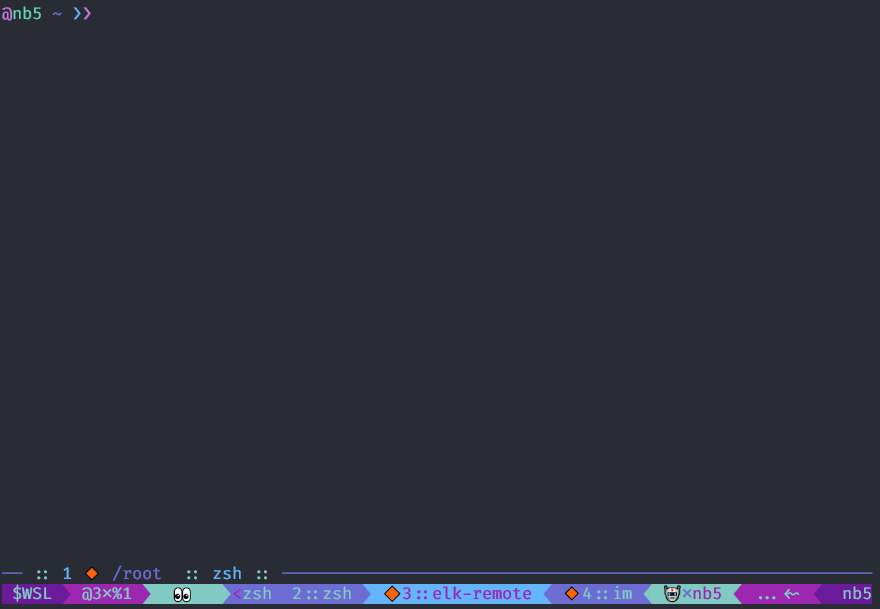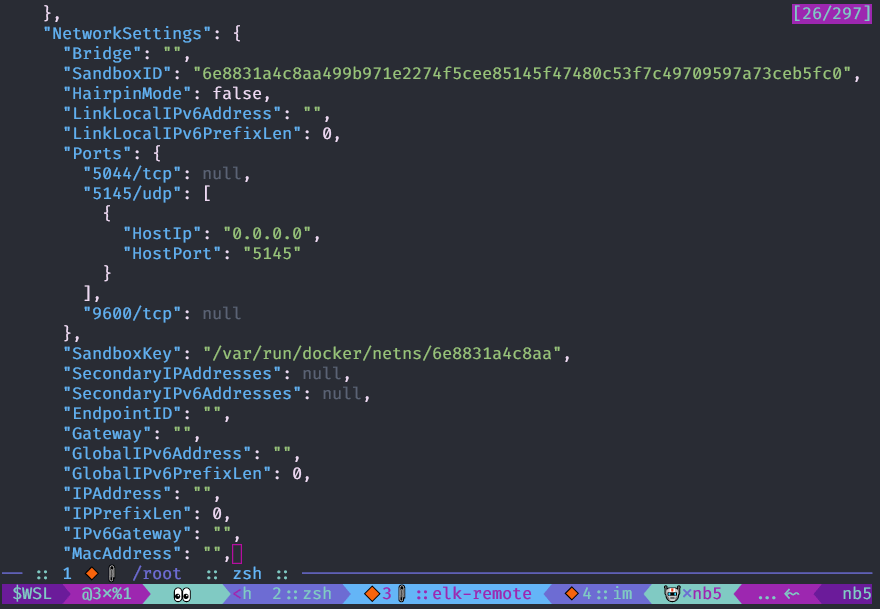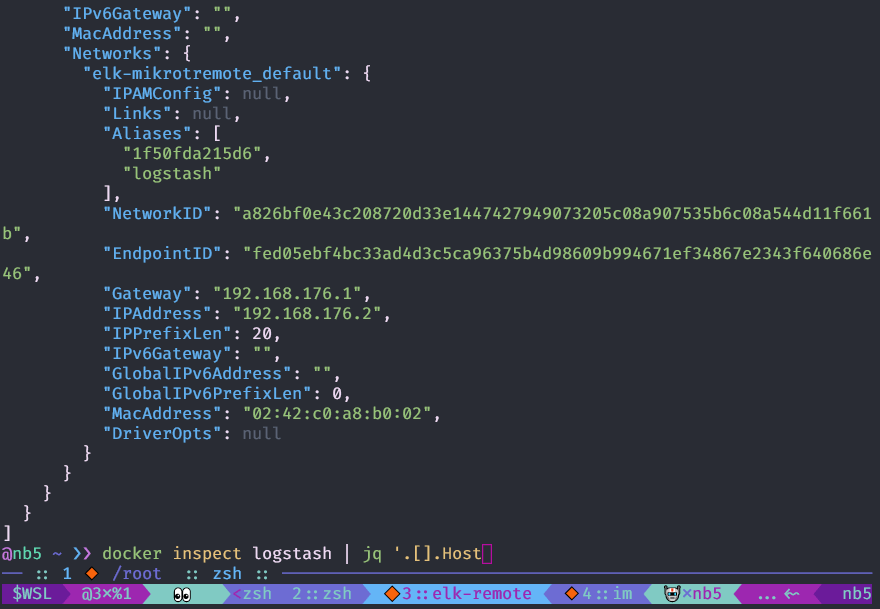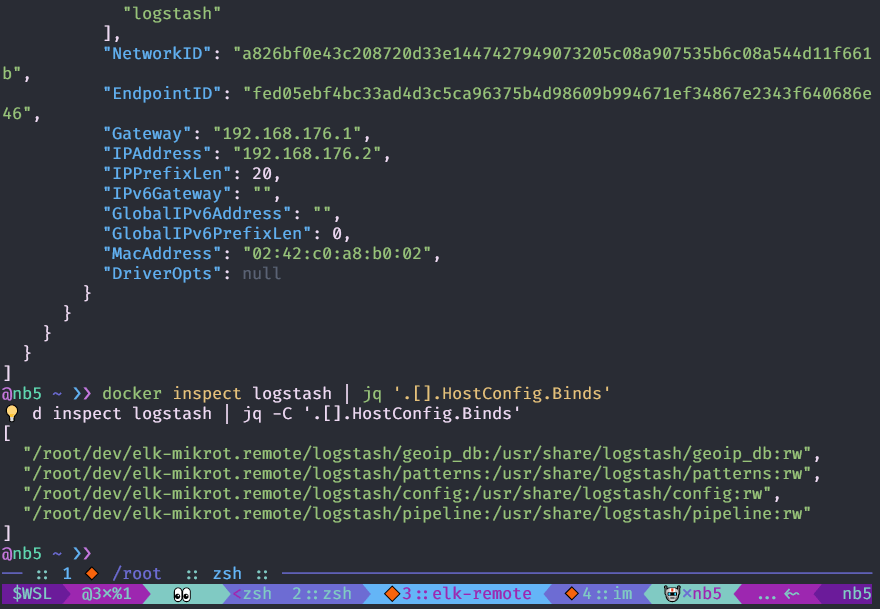
Você pode ver a configuração do objeto
docker com o
comando docker inspecionar ; é mais conveniente usá-lo com
jq .
Conclusão
Quero observar que a segurança neste projeto não foi relatada porque é um ambiente de teste (dev) e não está planejada para ser lançada fora do roteador. Se você implantá-lo para uso mais sério, precisará seguir as práticas recomendadas, instalar certificados para HTTPS, fazer backups, monitoramento normal (que não inicia próximo ao sistema principal). A propósito, o Traefik é executado na minha janela de encaixe no meu servidor, que é um proxy reverso para alguns serviços, e também encerra o TLS em si mesmo e faz autenticação. Ou seja, graças ao DNS configurado e ao proxy reverso, é possível acessar a interface da web do Kibana da Internet com HTTPS não configurado e uma senha (como eu o entendo, na versão da comunidade, o Kibana não suporta proteção de senha para a interface da web). Pretendo descrever melhor minha experiência na configuração do Traefik para uso em uma rede doméstica com o Docker.