Olá, Habrovsk. Hoje, as aulas começarão no primeiro grupo do curso PostgreSQL . Nesse sentido, queremos informar sobre como ocorreu o seminário on-line aberto para este curso.
Na
próxima lição aberta, falamos sobre os desafios que os bancos de dados SQL enfrentavam na era das nuvens e do Kubernetes. E, ao mesmo tempo, examinamos como os bancos de dados SQL se adaptam e se modificam sob a influência dessas chamadas.
O webinar foi realizado por
Valery Bezrukov , gerente de entrega de práticas em nuvem do Google na EPAM Systems.
Quando as árvores eram pequenas ...
Para começar, vamos relembrar como a escolha de um SGBD começou no final do século passado. No entanto, isso não será difícil, porque a escolha de um DBMS naquela época começou e terminou com o
Oracle .

No final dos anos 90 - o começo dos anos 1930, de fato, não havia escolha especial, se falássemos de bancos de dados industriais escaláveis. Sim, houve IBM DB2, Sybase e alguns outros bancos de dados que apareceram e desapareceram, mas em geral eles não eram tão perceptíveis no Oracle. Consequentemente, as habilidades dos engenheiros da época estavam de alguma forma ligadas à única opção que existia.
O DBA do Oracle deve ser capaz de:
- Instale o Oracle Server a partir da distribuição
- configure o Oracle Server:
- criar:
- espaços de tabela
- Esquemas
- usuários
- faça backup e restaure;
- realizar monitoramento;
- lidar com solicitações abaixo do ideal.
Ao mesmo tempo, o Oracle DBA não era particularmente necessário:
- ser capaz de escolher o DBMS ideal ou outra tecnologia de armazenamento e processamento de dados;
- fornecer alta disponibilidade e escalabilidade horizontal (isso nem sempre foi um problema de DBA);
- Bons conhecimentos da área temática, infraestrutura, arquitetura aplicada, SO;
- realizar carregamento e descarregamento de dados, migração de dados entre diferentes DBMS.
Em geral, se falamos sobre a escolha naqueles dias, ela se assemelha a uma escolha em uma loja soviética no final dos anos 80:

Nosso tempo
Desde então, é claro, as árvores cresceram, o mundo mudou e, de alguma forma, ficou assim:

O mercado de DBMS também mudou, o que pode ser visto claramente no último relatório do Gartner:

E aqui deve-se notar que as nuvens ocupavam seu nicho, cuja popularidade está crescendo. Se você ler o mesmo relatório do Gartner, veremos as seguintes conclusões:
- Muitos clientes estão no caminho de mover aplicativos para a nuvem.
- As novas tecnologias aparecem pela primeira vez na nuvem e não o fato de que alguma vez elas serão migradas para uma infraestrutura livre de nuvem.
- O modelo de preços de pagamento conforme o uso se tornou familiar. Todo mundo quer pagar apenas pelo que usa, e isso nem é uma tendência, mas simplesmente uma declaração de fato.
O que agora
Hoje estamos todos na nuvem. E essas perguntas que temos são questões de escolha. E é enorme, mesmo se falarmos apenas sobre a escolha de tecnologias DBMS no formato Local. Também temos serviços gerenciados e SaaS. Assim, a escolha está se tornando mais complicada a cada ano.
Juntamente com as questões de escolha,
fatores restritivos também se aplicam:
- o preço Muitas tecnologias ainda custam dinheiro;
- habilidades . Se estamos falando de software livre, surge a questão das habilidades, porque o software livre requer pessoas que o implantem e operem com competência suficiente;
- funcional . Nem todos os serviços disponíveis na nuvem e criados, por exemplo, mesmo com base no mesmo Postgres, têm os mesmos recursos que o Postgres local. Esse é um fator essencial que você precisa conhecer e entender. Além disso, esse fator se torna mais importante do que o conhecimento de alguns recursos ocultos de um único DBMS.
O que está esperando do DA / DE:- um bom entendimento da área de assunto e arquitetura aplicada;
- a capacidade de escolher a tecnologia DBMS correta, levando em consideração a tarefa;
- a capacidade de selecionar o método ideal para implementar a tecnologia selecionada no contexto das limitações existentes;
- capacidade de realizar migração e migração de dados;
- a capacidade de implementar e operar as soluções selecionadas.
O exemplo a seguir,
baseado no GCP, demonstra como a escolha de uma determinada tecnologia para trabalhar com dados é organizada, dependendo de sua estrutura:

Observe que o PostgreSQL está ausente no esquema, e tudo porque está oculto sob a terminologia do
Cloud SQL . E quando entramos no Cloud SQL, precisamos fazer uma escolha novamente:

Deve-se notar que essa opção nem sempre é clara; portanto, os desenvolvedores de aplicativos geralmente são guiados pela intuição.
Total:- Quanto mais longe, mais relevante é a questão da escolha. E mesmo se você olhar apenas para o GCP, serviços gerenciados e SaaS, algumas menções ao RDBMS aparecerão apenas na quarta etapa (e há uma chave inglesa por perto). Além disso, a escolha do PostgreSQL aparece em geral na 5ª etapa e, ao lado, também existem o MySQL e o SQL Server, ou seja, há muito, mas você precisa escolher .
- Não devemos esquecer as restrições ao fundo das tentações. Todo mundo quer uma chave inglesa, mas é caro. Como resultado, uma consulta típica é mais ou menos assim: "Por favor, faça o Spanner para nós, mas pelo preço do Cloud SQL, bem, vocês são profissionais!"

O que fazer?
Sem pretender ser a verdade última, digamos o seguinte:
Precisa mudar a abordagem do aprendizado:- aprender, como ensinado antes do DBA, não faz sentido;
- o conhecimento de um produto não é mais suficiente;
- mas conhecer dezenas no nível de um é impossível.
Você precisa saber não apenas e quanto o produto, mas:
- caso de uso de sua aplicação;
- diferentes métodos de implantação;
- vantagens e desvantagens de cada método;
- produtos similares e alternativos para fazer escolhas informadas e ideais e nem sempre em favor de um produto familiar.
Você também precisa poder migrar dados e entender os princípios básicos da integração com o ETL.
Caso real
No passado recente, você precisava fazer um back-end para um aplicativo móvel. Quando começou a trabalhar, o back-end já estava desenvolvido e estava pronto para implementação, e a equipe de desenvolvimento passou cerca de dois anos nesse projeto. As seguintes tarefas foram definidas:
- construir CI / CD;
- revisar arquitetura;
- coloque tudo em operação.
O aplicativo em si era microsserviço e o código Python / Django foi desenvolvido do zero e imediatamente no GCP. Quanto ao público-alvo, assumiu-se que haveria duas regiões - EUA e UE, e o tráfego foi distribuído através do balanceador de carga global. Todas as cargas de trabalho e cargas de trabalho computacionais funcionaram no Google Kubernetes Engine.
Quanto aos dados, havia três estruturas:
- Armazenamento na nuvem
- Datastore;
- Cloud SQL (PostgreSQL).
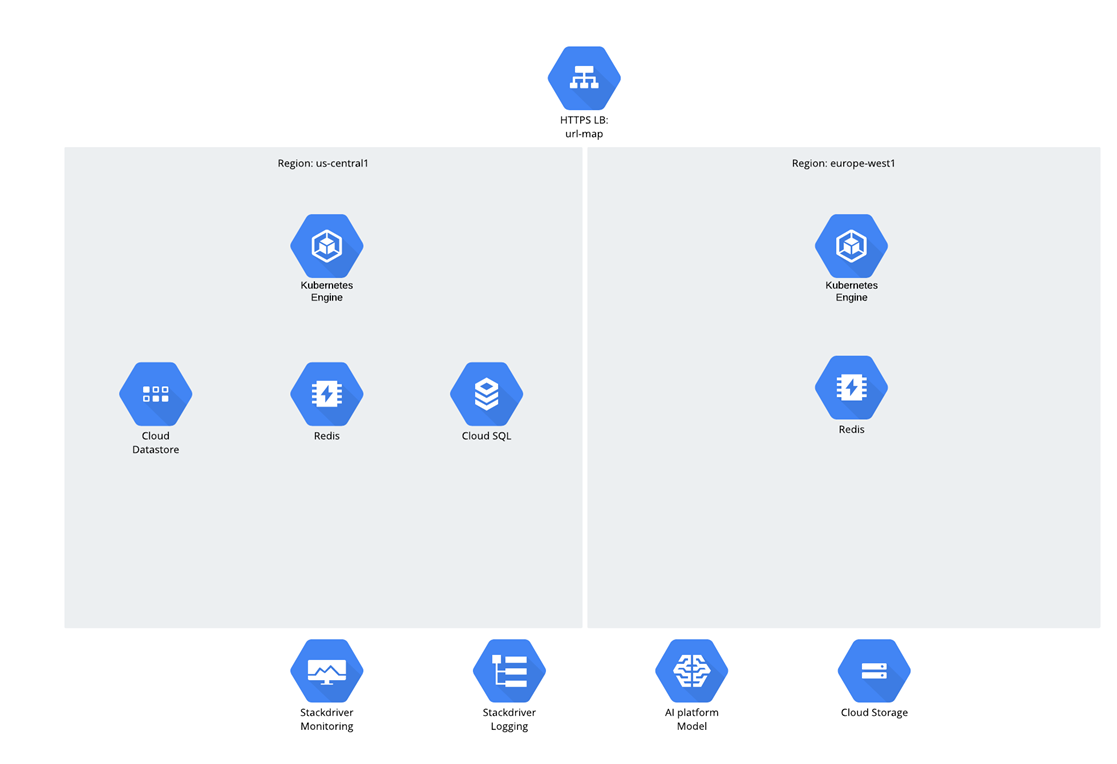
Você pode se perguntar por que o Cloud SQL foi selecionado? Para dizer a verdade, essa pergunta nos últimos anos causou uma pausa incômoda - há um sentimento de que as pessoas começaram a ter vergonha de bancos de dados relacionais, mas, mesmo assim, continuam a usá-los ativamente ;-).
Para o nosso caso, o Cloud SQL foi escolhido pelos seguintes motivos:
- Como mencionado, o aplicativo foi desenvolvido usando o Django e possui um modelo para mapear dados persistentes de um banco de dados SQL para objetos Python (Django ORM).
- A própria estrutura suportava uma lista bastante finita de DBMSs:
- PostgreSQL
- MariaDB;
- MySQL
- Oracle
- SQLite
Consequentemente, o PostgreSQL foi escolhido intuitivamente nesta lista (bem, na verdade não é o Oracle).
O que estava faltando:- o aplicativo foi implantado apenas em duas regiões e os planos apareceram em terceiro (Ásia);
- O banco de dados estava na região norte-americana (Iowa);
- por parte do cliente, houve preocupações com possíveis atrasos no acesso da Europa e na Ásia e interrupções no serviço no caso de um tempo de inatividade do DBMS.
Apesar do próprio Django poder trabalhar com vários bancos de dados em paralelo e dividi-los pela leitura e gravação, não havia muitos registros no aplicativo (mais de 90% - leitura). E, em geral, e em geral, se você pudesse fazer uma
réplica de leitura da base principal na Europa e na Ásia , essa seria uma solução de compromisso. Bem, o que é tão complicado?
E a dificuldade era que o cliente não queria se recusar a usar serviços gerenciados e o Cloud SQL. E as possibilidades do Cloud SQL atualmente são limitadas. O Cloud SQL suporta Alta disponibilidade (HA) e Réplica de Leitura (RR), mas o mesmo RR é suportado em apenas uma região. Após criar um banco de dados na região americana, é impossível fazer uma réplica de leitura na região européia usando o Cloud SQL, embora o próprio postgres não interfira. A correspondência com os funcionários do Google não levou a nada e terminou com promessas no estilo de "conhecemos o problema e estamos trabalhando nele, algum dia o problema será resolvido".
Se você listar as possibilidades de tese do Cloud SQL, será algo como isto:
1. Alta disponibilidade (HA):- dentro de uma região;
- através da replicação de disco
- Os mecanismos do PostgreSQL não são utilizados;
- possível controle automático e manual - failover / failback;
- ao alternar, o DBMS fica indisponível por vários minutos.
2. Leia a réplica (RR):- dentro de uma região;
- espera quente;
- Replicação de streaming PostgreSQL.
Além disso, como é habitual, ao escolher uma tecnologia, você sempre encontra algumas
limitações :
- o cliente não queria produzir entidades e usar IaaS, exceto através do GKE;
- o cliente não gostaria de implantar o autoatendimento PostgreSQL / MySQL;
- bem, em geral, o Google Spanner seria bastante adequado se não fosse pelo preço, no entanto, o Django ORM não pode trabalhar com ele e, portanto, a coisa é boa.
Dada a situação, o cliente recebeu uma pergunta de preenchimento:
"Você pode fazer algo semelhante para se parecer com o Google Spanner, mas também funciona com o Django ORM?"Opção nº 0
A primeira coisa que veio à mente:
- Fique dentro do CloudSQL
- não haverá replicação integrada entre regiões de nenhuma forma;
- tente parafusar a réplica no Cloud SQL existente do PostgreSQL;
- em algum lugar e de alguma forma inicie a instância do PostgreSQL, mas pelo menos o master não toca.
Infelizmente, aconteceu que isso não pode ser feito, porque não há acesso ao host (ele está em outro projeto em geral) - pg_hba e assim por diante, e ainda não há acesso no superusuário.
Opção nº 1
Após uma reflexão mais aprofundada e levando em consideração as circunstâncias anteriores, a linha de pensamento mudou um pouco:
- ainda estamos tentando permanecer no escopo do CloudSQL, mas estamos mudando para o MySQL, porque o Cloud SQL by MySQL possui um mestre externo, que:
- é um proxy para MySQL externo;
- parece uma instância do MySQL;
- inventado para migração de dados de outras nuvens ou no local.
Como configurar a replicação do MySQL não requer acesso ao host, basicamente tudo funcionou, mas é muito instável e inconveniente. E quando fomos mais longe, tornou-se completamente assustador, porque implantamos toda a estrutura com terraform e, de repente, verificou-se que o mestre externo não era suportado por terraform. Sim, o Google tem uma CLI, mas, por algum motivo, tudo funcionava de vez em quando - ele é criado, não é criado. Talvez porque a CLI foi inventada para migração de dados para fora e não para réplicas.
Na verdade, isso deixou claro que o Cloud SQL não se encaixa na palavra. Como se costuma dizer, fizemos tudo o que pudemos.
Opção 2
Como não funcionou para permanecer no Cloud SQL, tentamos formular requisitos para uma solução de compromisso. Os requisitos foram os seguintes:
- trabalho no Kubernetes, uso máximo dos recursos e capacidades do Kubernetes (DCS, ...) e GCP (LB, ...);
- a falta de lastro de uma pilha de coisas desnecessárias na nuvem como proxy de alta disponibilidade;
- a capacidade de executar o HA PostgreSQL ou MySQL na região principal; em outras regiões - HA do RR da região principal mais sua cópia (para confiabilidade);
- multi mestre (não quis entrar em contato com ele, mas não era muito importante)
.
Como resultado desses requisitos, no horizonte finalmente apareceram
opções e ligações DBMS adequadas :
- MySQL Galera;
- CockroachDB;
- Ferramentas PostgreSQL
:
- pgpool-II;
Patroni.
MySQL Galera
A tecnologia MySQL Galera foi desenvolvida pela Codership e é um plugin para o InnoDB. Características:
- multi mestre;
- replicação síncrona
- leitura de qualquer nó;
- gravar para qualquer nó;
- mecanismo integrado de alta disponibilidade;
- Existe um gráfico Helm da Bitnami.
Barata
De acordo com a descrição, a coisa é completamente bombástica e é um projeto de código aberto escrito em Go. O principal participante é o Cockroach Labs (fundado por imigrantes do Google). Esse DBMS relacional foi criado originalmente para ser distribuído (com escala horizontal pronta para uso) e tolerante a falhas. Seus autores da empresa delinearam o objetivo de "combinar a riqueza da funcionalidade SQL com a disponibilidade horizontal familiar das soluções NoSQL".
O bônus agradável é o suporte ao protocolo de conexão do postgres.
Pgpool
Este é um complemento para o PostgreSQL, de fato, uma nova entidade que assume todas as conexões e as processa. Possui seu próprio balanceador e analisador de carregador, licenciado sob a licença BSD. Ele oferece amplas oportunidades, mas parece um pouco assustador, porque a presença de uma nova entidade pode se tornar uma fonte de algumas aventuras adicionais.
Patroni
Esta é a última coisa em que os olhos caíram e, como se viu, não em vão. O Patroni é um utilitário de código aberto que, em essência, é um daemon Python que mantém automaticamente os clusters do PostgreSQL com vários tipos de replicação e alternância automática de funções. A peça acabou sendo muito interessante, pois se integra bem ao cubador e não possui novas entidades.
O que finalmente escolheu
A escolha não foi fácil:
- CockroachDB - fogo, mas burro;
- O MySQL Galera também não é ruim, é usado muito onde, mas o MySQL;
- Pgpool - muitas entidades extras, mais ou menos integração com a nuvem e K8s;
- Patroni - excelente integração com K8s, sem entidades extras, integra-se bem ao GCP LB.
Assim, a escolha recaiu sobre Patroni.
Conclusões
Chegou a hora de resumir. Sim, o mundo da infraestrutura de TI mudou significativamente e este é apenas o começo. E se as nuvens anteriores eram apenas outro tipo de infraestrutura, agora tudo é diferente. Não apenas isso, as inovações nas nuvens estão aparecendo constantemente, elas aparecerão e, talvez, elas aparecerão apenas nas nuvens e só então, com a ajuda de startups, elas serão transferidas para o Local.
Quanto ao SQL, o SQL viverá. Isso significa que o PostgreSQL e o MySQL devem ser conhecidos e você precisa poder trabalhar com eles, mas o mais importante, para poder aplicá-los corretamente.