Quanto mais complexo o sistema, mais cresce com todos os tipos de alertas. E é necessário responder a esses alertas, agregá-los e visualizar. Eu acho uma situação familiar para muitos antes de um tique nervoso.
A decisão que será discutida não é a mais inesperada, mas a pesquisa não produz um artigo completo sobre esse tópico.
Portanto, decidi compartilhar a experiência da FunCorp e falar sobre como o processo de serviço é construído, quem está ligando, por que e como você pode ver tudo isso.

O que é o PagerDuty?
Então, para resolver todos esses problemas, começamos a procurar uma ferramenta conveniente. Após uma breve pesquisa, optamos pelo PagerDuty. O PD nos pareceu uma solução bastante completa e concisa com muitas integrações e configurações. Como ela é?
Em resumo, o PagerDuty é uma plataforma de processamento de incidentes que pode lidar com incidentes de entrada por meio de várias integrações, ajustar a ordem das tarefas e, em seguida, alertar o engenheiro de tarefas, dependendo do nível do incidente (em chamadas de alto nível, com pouca pressão do aplicativo / sms) .
Quem é a pessoa de plantão?
Esta é provavelmente a primeira coisa a começar a configurar um PD.
A FunCorp, como outras empresas, tem uma posição honorária de serviço. É transmitido de engenheiro para engenheiro uma vez por dia. Existe a chamada primeira e segunda linha de resposta aos alertas do PagerDuty. Suponha que um alerta de alta prioridade chegue e, se 10 minutos após a chamada para o atendente da primeira linha não houver reação a ele (ou seja, ele não for transferido para o status de reconhecimento ou resolvido), a chamada será direcionada ao segundo engenheiro de serviço. Isso é configurado no próprio PagerDuty por meio de políticas de escalonamento.
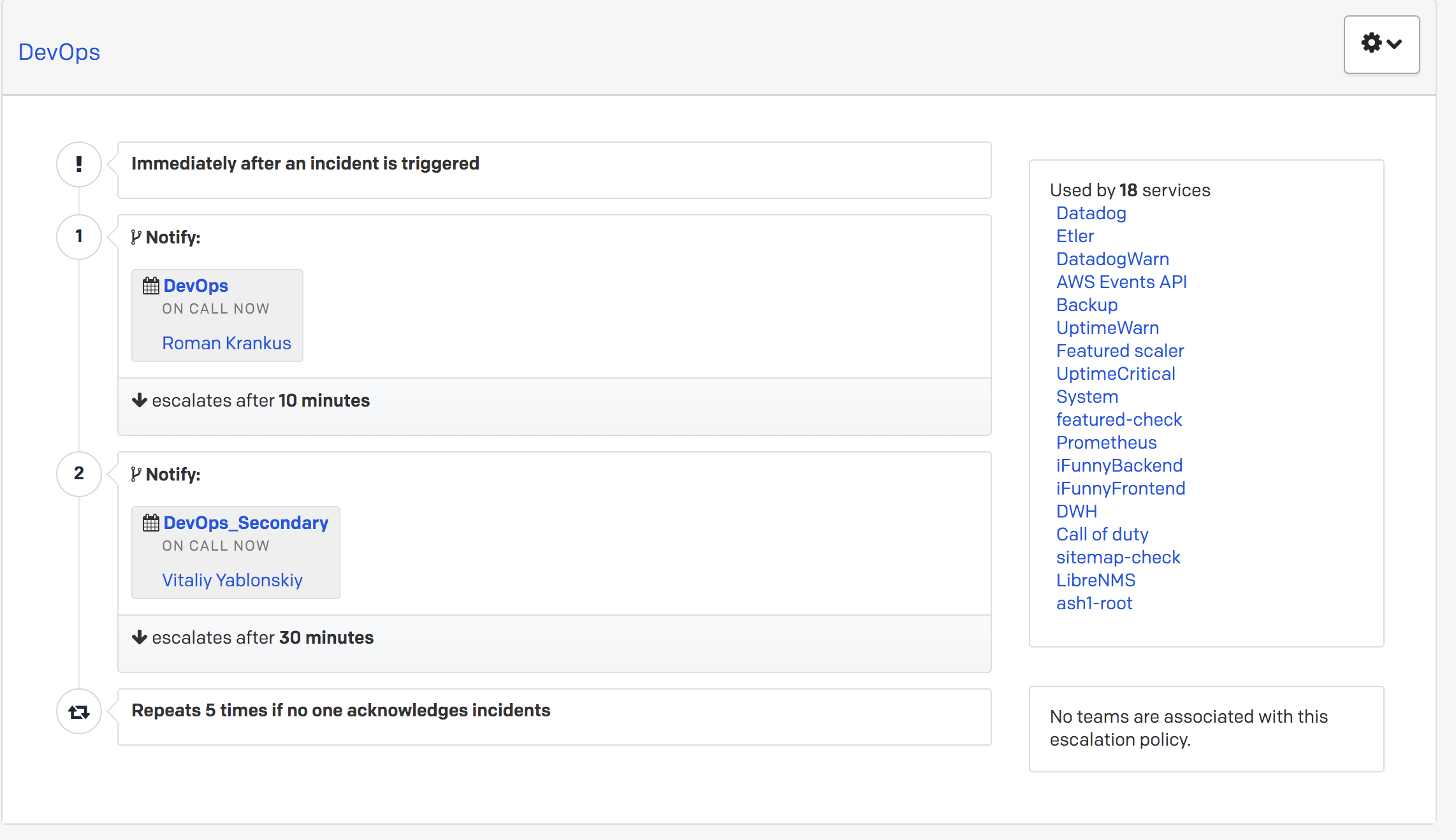
Se o segundo atendedor não responder, a notificação retornará ao atendente
principal .
Portanto, qualquer alerta de alta prioridade recebido não pode permanecer não processado.
Agora vamos ver de onde podem vir os incidentes.
Quais integrações usamos?
Muitos incidentes de vários serviços são despejados no PD. Agora, temos cerca de 25 desses serviços e, para o processamento deles, usamos algumas integrações prontas.
O sistema principal de coleta de métricas é o Prometheus. Muito foi escrito sobre isso em Habré, apenas direi que temos vários para ambientes diferentes: um coleta métricas de máquinas virtuais e estivadores, o outro de serviços da Amazon e o terceiro de "máquinas de ferro". Principalmente usado como exportador de métricas é o Telegraf.
Aqui também acho que tudo está claro com o nome. Essa integração é usada para enviar notificações de alguns scripts executados na coroa. O PD fornece um determinado endereço para o qual você envia cartas. Ao criar um serviço com essa integração, é possível definir prioridades em que ordem os incidentes recebidos serão processados, como criar um alerta (para cada letra recebida, para uma carta recebida + uma determinada regra, etc.).

Na minha opinião, uma integração muito interessante. Há momentos em que algo acontece, mas não é coberto por incidentes. Portanto, adicionamos integração do Slack para criar o incidente. Ou seja, no Slack corporativo, você pode escrever
/ chamar de tudo, tudo fica mais lento e logo ele quebra e o PD processa isso e envia o incidente ao engenheiro de serviço.
Nós fazemos:

Vemos:

Integração HTTP. Aqui, de fato, não há nada particularmente interessante, apenas uma solicitação POST com um corpo no formato JSON. Por exemplo, de um interessante: nós o usamos para monitoramento externo usando
https://www.statuscake.com/ . Este serviço verifica a disponibilidade de nossos sites em todo o mundo. No caso em que obtemos um código de resposta inaceitável (por exemplo, 502), um incidente é criado e tudo segue ao longo da cadeia descrita acima. O StatusCake em si tem a capacidade de monitorar URLs internas, a expiração de um certificado ou domínio SSL.
Este é outro sistema de monitoramento, mais sobre ele pode ser encontrado no site
https://www.librenms.org/ . Com sua ajuda, monitoramos as interfaces de rede e o iDRAC dos servidores.
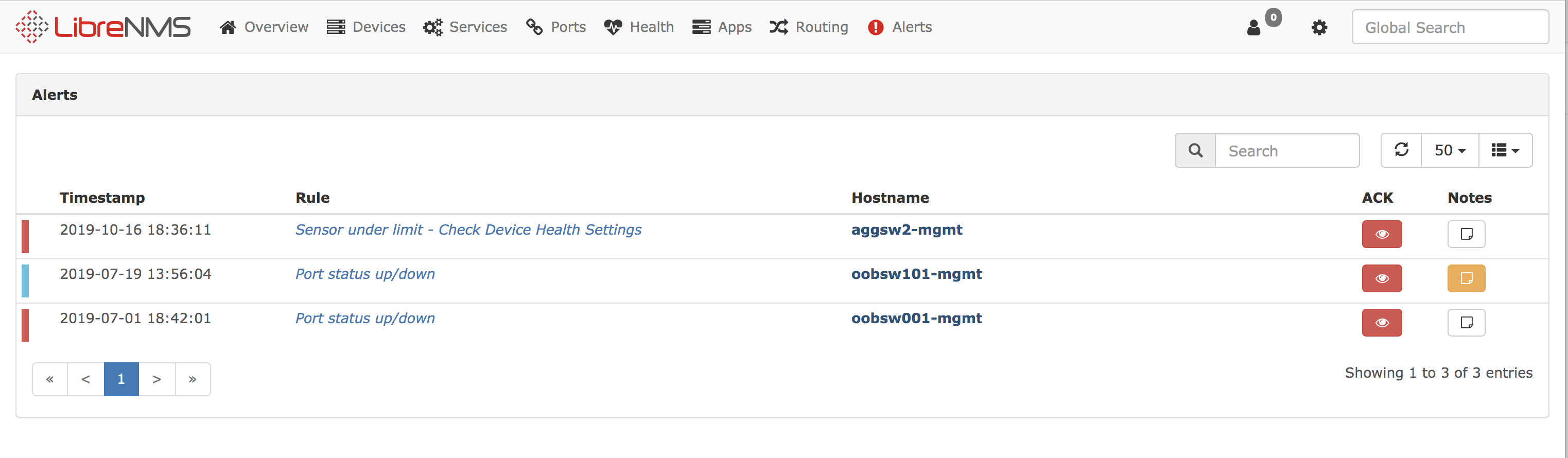
Também houve integrações como Datadog, CloudWatch. Mais sobre o que aconteceu com eles pode ser encontrado
aqui .
Visualização
O principal sistema de relatório de incidentes é o Slack. Todos os incidentes que chegam ao PD são gravados em um bate-papo especial e, se seu status mudar, isso também é exibido no bate-papo.
Quando se tornou possível exibir dados úteis nas telas dos monitores pendurados no teto, de repente percebemos que nós (no departamento de devops) não havia nada para exibir neles. Há um Grafana maravilhoso, mas ele simplesmente não pode ser coberto, e os funcionários respondem a alertas, não a gráficos.
Após uma pesquisa completa, mas sem êxito, no GitHub, por um "quadro" conciso e informativo para o PD, decidimos escrever nossos - apenas com o que precisávamos. Embora a princípio houvesse uma idéia para exibir a interface do PD, ela parecia ainda mais inconveniente.
Para escrevê-lo, tudo o que você precisa é obter a chave para o PD com direitos somente leitura.
E aqui está o que temos:
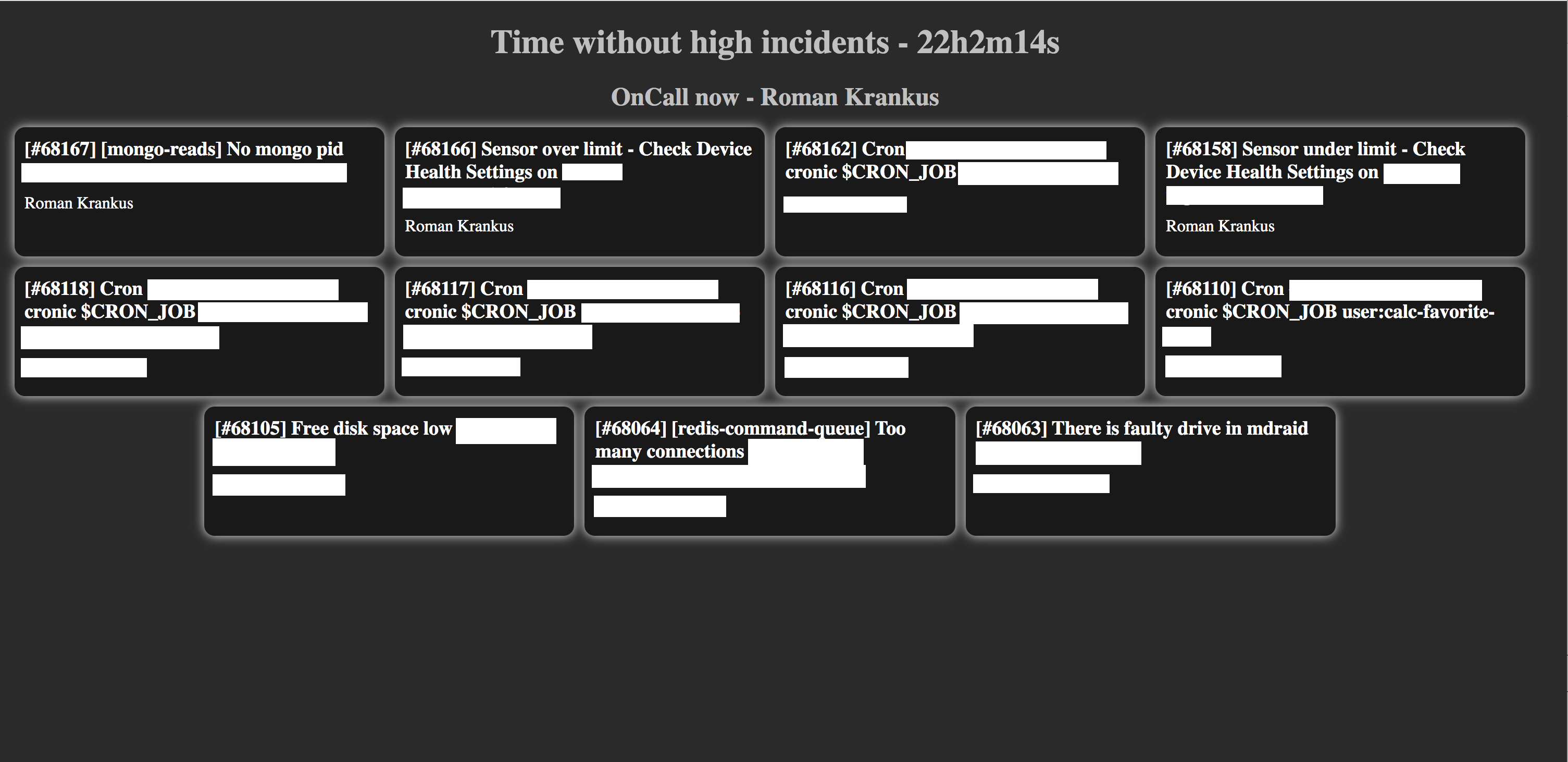
A tela exibe os incidentes abertos atuais, o nome do engenheiro de serviço atual da programação selecionada e o tempo sem um incidente de alta prioridade (um painel com um incidente de alta prioridade será destacado em vermelho).
Veja o código fonte para esta implementação aqui .
Como resultado, obtivemos um painel conveniente para visualizar todos os nossos incidentes. Ficaria feliz se algum de vocês se beneficiaria com a nossa experiência.