
Quando paramos de controlar o tamanho da tabela, manter e disponibilizar dados se torna uma tarefa não trivial. Eu já encontrei esse problema na produção, há mais dados todos os dias, a tabela não cabe na memória, os servidores respondem por um longo tempo, mas uma solução foi encontrada.
Olá Habr! Meu nome é Diamond e agora quero compartilhar um método que me ajudou a implementar o particionamento.
Particionando no PostgreSql
Particionar (ou, como chamam, particionar) é o processo de dividir uma grande tabela lógica em várias seções físicas menores. É isso que nos ajuda a gerenciar nossos dados.
Exemplo: temos uma tabela "vendas", que é particionada por um intervalo de um mês, e essas seções podem ser divididas em subseções ainda menores por região.
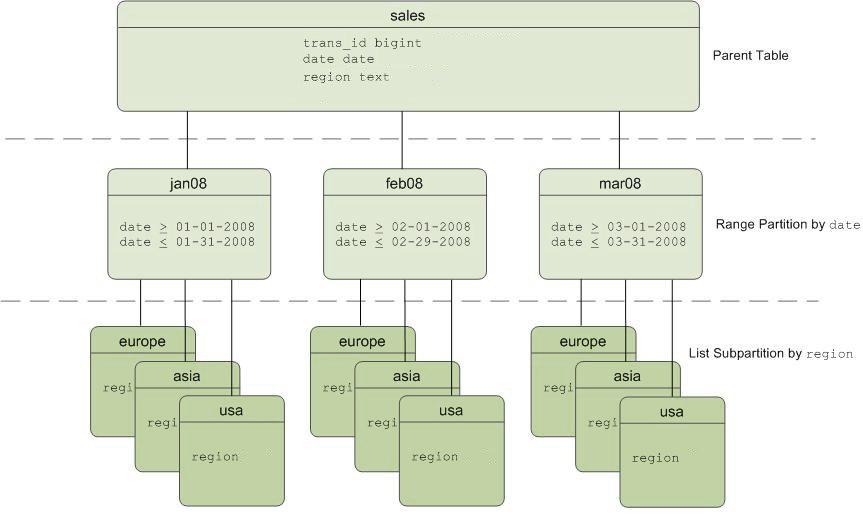 Esquema de "vendas" da tabela particionada
Esquema de "vendas" da tabela particionadaContras desta abordagem:
- Estrutura de banco de dados complicada. Cada seção nas definições de banco de dados é uma tabela, embora faça parte de uma entidade lógica.
- Você não pode converter uma tabela existente em uma tabela particionada e vice-versa.
- Não há suporte completo no Postgres versão 11.
Prós:
+ Desempenho. Em certos casos, podemos trabalhar com um conjunto limitado de seções sem percorrer a tabela inteira; até a pesquisa de índice por tabelas grandes será mais lenta. Aumenta a disponibilidade dos dados.
+ Upload em massa e exclusão de dados com os comandos ATTACH / DETACH. Isso nos salva de sobrecarga na forma de vácuo. o que permite manter o banco de dados com mais eficiência.
+ Capacidade de especificar TABLESPACE para a seção. Isso nos dá a oportunidade de transferir dados para outras seções, mas ainda trabalhamos na mesma instância e os metadados do diretório principal conterão informações sobre as seções (não devem ser confundidas com sharding)
2 maneiras de implementar o particionamento no PostgreSql:
1. Herança de tabelas (Heranças)Ao criar uma tabela, dizemos "herdar de outra tabela (pai)". Ao mesmo tempo, adicionamos restrições para o gerenciamento de dados na tabela. Por isso, apoiamos a lógica da divisão de dados, mas essas são tabelas logicamente diferentes.
Aqui deve ser notada a extensão desenvolvida pelo PostgreS Professional pg_pathman, que implementa o particionamento, também através da herança de tabelas.
CREATE TABLE orders_y2010 ( CHECK (log_date >= DATE '2010-01-01) ) INHERITS (orders);
2. Abordagem declarativa (PARTIÇÃO)Uma tabela é definida como particionada declarativamente. Esta solução apareceu na versão 10 do PostgreSql.
CREATE TABLE orders (log_date date not null, …) PARTITION BY RANGE(log_date);
Eu escolhi uma abordagem declarativa. Isso oferece uma grande vantagem: natividade, mais recursos são suportados pelo kernel. Considere o desenvolvimento do PostgreSQL nesta direção:
 Fonte
FonteMas o PostgreSql continua evoluindo e a versão 12 tem suporte para vincular a uma tabela particionada. Este é um grande avanço.
Do meu jeito
Dado o exposto, um
script foi escrito em PL / pgSQL, que cria uma tabela particionada com base na existente e "lança" todos os links para a nova tabela. Assim, obtemos uma tabela particionada com base na existente e continuamos a trabalhar com ela como em uma tabela regular.
O script não requer dependências adicionais e é executado em um circuito separado que ele próprio cria. Também registra ações de refazer e desfazer. Esse script resolve duas tarefas principais: cria uma tabela particionada e implementa links externos a ela por meio dos gatilhos de gatilho.
Requisito de script: PostgreSql v.:11 e superior.
Agora vamos analisar o script em mais detalhes. A interface é muito simples:
Existem dois procedimentos que fazem todo o trabalho.
1. O principal desafio - nesta fase, não alteramos a tabela principal, mas tudo o que é necessário para seccionar será criado em um esquema separado:
call partition_run();
2. Chame as tarefas adiadas que foram planejadas durante o trabalho principal:
call partition_run_jobs();
O trabalho pode ser iniciado em vários segmentos. O número ideal de encadeamentos é próximo ao número de tabelas particionadas.
Parâmetros de entrada para o script (registro _pt)

O script por dentro, as principais ações:
- Crie uma tabela particionada
perform _partition_create_parent_table(_pt);
- Criar seções
perform _partition_create_child_tables(_pt);
- Copie os dados na seção
perform _partition_copy_data(_pt);
- Adicionar restrições (trabalho)
perform _partition_add_constraints(_pt);
- Restaurar links para tabelas externas
perform _partition_restore_referrences(_pt);
- Restaurar gatilhos
perform _partition_restore_triggers(_pt);
- Crie um gatilho de evento
perform _partition_def_tr_on_delete(_pt);
- Criar índices (trabalho)
perform _partition_create_index(_pt);
- Substituir visualizações, links de seção (trabalho)
perform _partition_replace_view(_pt);
O tempo de execução do script depende de muitos fatores, mas os principais são o tamanho das tabelas de destino, o número de relacionamentos, índices e características do servidor. No meu caso, uma tabela de 300 GB foi particionada em menos de uma hora.
Resultado
O que conseguimos? Vejamos o plano de consulta:
EXPLAIN ANALYZE select * from “sales” where dt BETWEEN '01.01.2019'::date and '14.01.2019'::date

Obtivemos o resultado da tabela particionada mais rapidamente e utilizamos menos recursos do nosso servidor em comparação com a consulta em uma tabela regular.
Neste exemplo, as tabelas regulares e particionadas estão na mesma base e possuem cerca de 200 milhões de registros. Esse é um bom resultado, já que, sem reescrever o código do aplicativo, obtivemos aceleração. As consultas em outros índices também funcionam bem, mas lembre-se: sempre que podemos determinar uma seção, o resultado será várias vezes mais rápido, porque O PostgreSql pode descartar seções extras no estágio de planejamento da solicitação (
defina enable_partition_pruning para on ).
Sumário
Consegui implementar o particionamento em tabelas com muitos relacionamentos e garantir a integridade do banco de dados. O script é independente de estruturas de dados específicas e pode ser reutilizado.
O PostgreSQL é o banco de dados relacional de código aberto mais avançado do mundo!Obrigado a todos!
Link para a fonte