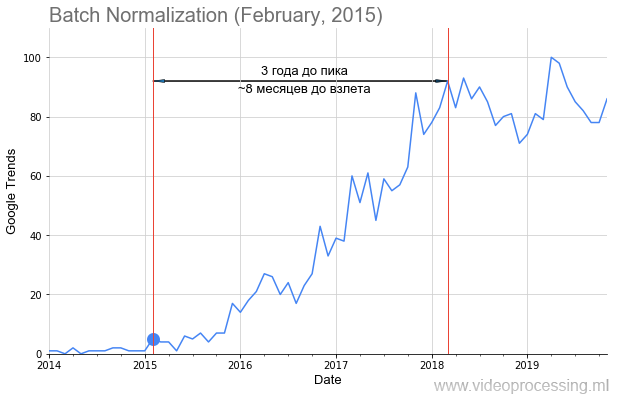
O ano novo está se aproximando, os anos 2010 terminarão em breve, dando ao mundo o renascimento sensacional das redes neurais. Fiquei perturbado
e privado de sono com um simples pensamento: “Como alguém pode estimar retrospectivamente a velocidade do desenvolvimento de redes neurais?”. Para “Quem conhece o passado conhece o futuro”. Com que rapidez decolaram diferentes algoritmos? Como se pode avaliar a velocidade do progresso nessa área e estimar a velocidade do progresso na próxima década?

É claro que você pode calcular aproximadamente o número de artigos em diferentes áreas. O método não é ideal, é necessário levar em consideração subdomínios, mas, em geral, você pode tentar. Eu dou uma idéia, no
Google Scholar (BatchNorm) é bem real! Você pode considerar novos conjuntos de dados, novos cursos. Seu humilde servo, tendo
examinado várias opções,
optou pelo
Google Trends (BatchNorm) .
Meus colegas e eu recebemos solicitações das principais tecnologias de ML / DL, por exemplo,
Normalização de lote , como na figura acima, adicionamos a data de publicação do artigo com um ponto e obtivemos uma linha do tempo para a popularidade do tópico. Mas não para todos, o
caminho está repleto de rosas, a decolagem é tão óbvia e bonita, como o batnorm. Alguns termos, como regularização ou pular conexões, não puderam ser construídos devido ao ruído de dados. Mas, em geral, conseguimos coletar tendências.
Quem se importa com o que aconteceu - bem-vindo ao corte!
Em vez de introduzir ou reconhecer imagens
Então! Os dados iniciais eram bastante barulhentos, às vezes havia picos acentuados.
 Fonte: Andrei Karpaty twitter - os alunos ficam nos corredores de uma enorme audiência para ouvir uma palestra sobre redes neurais convolucionais
Fonte: Andrei Karpaty twitter - os alunos ficam nos corredores de uma enorme audiência para ouvir uma palestra sobre redes neurais convolucionaisConvencionalmente, foi o suficiente para
Andrey Karpaty dar uma palestra do lendário
CS231n: Redes Neurais Convolucionais para Reconhecimento Visual para 750 pessoas com a popularização do conceito de como está
ocorrendo um pico agudo. Portanto, os dados foram suavizados com um simples
filtro de caixa (todas as saídas suavizadas são marcadas como Suavizadas no eixo). Como estávamos interessados em comparar a taxa de crescimento da popularidade - após a suavização, todos os dados foram normalizados. Acabou bem engraçado. Aqui está um gráfico das principais arquiteturas concorrentes no ImageNet:
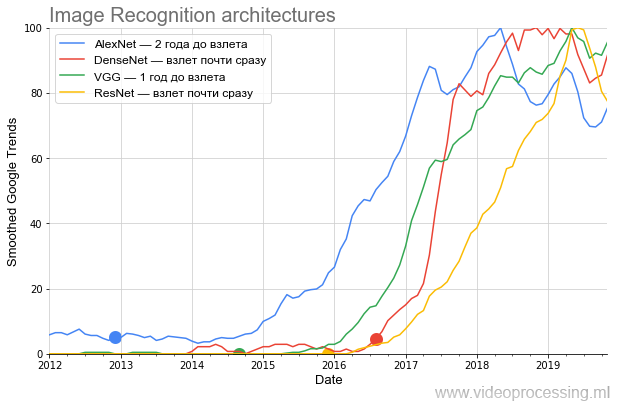 Fonte: doravante - os cálculos do autor de acordo com o Google Trends
Fonte: doravante - os cálculos do autor de acordo com o Google TrendsO gráfico mostra muito claramente que, após a sensacional publicação da
AlexNet , que produziu o mingau do hype atual das redes neurais no final de 2012, por quase dois anos estava fervendo,
ao contrário das afirmações do heap, apenas um círculo relativamente restrito de especialistas
se uniu . O tópico foi para o público em geral apenas no inverno de 2014-2015. Preste atenção em como a programação se torna periódica a partir de 2017: novos picos a cada primavera.
Na psiquiatria, isso é chamado de exacerbação da primavera ... Esse é um sinal claro de que agora o termo é usado principalmente pelos estudantes e, em média, o interesse no AlexNet diminui em comparação ao pico de popularidade.
Além disso, no segundo semestre de 2014, a
VGG apareceu. A propósito, a
VGG foi coautora do supervisor de
estudos da minha ex-aluna
Karen Simonyan , agora trabalhando no Google DeepMind (
AlphaGo ,
AlphaZero , etc.). Enquanto estudava na Universidade Estadual de Moscou, no terceiro ano, Karen implementou um bom
algoritmo de estimativa de movimento , que serve de referência para estudantes de 2 anos por 12 anos. Além disso, as tarefas são um tanto indescritivelmente semelhantes. Compare:
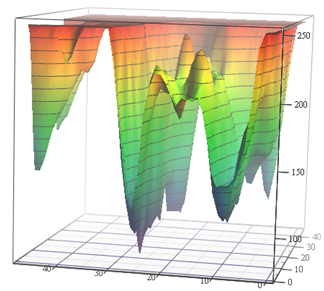
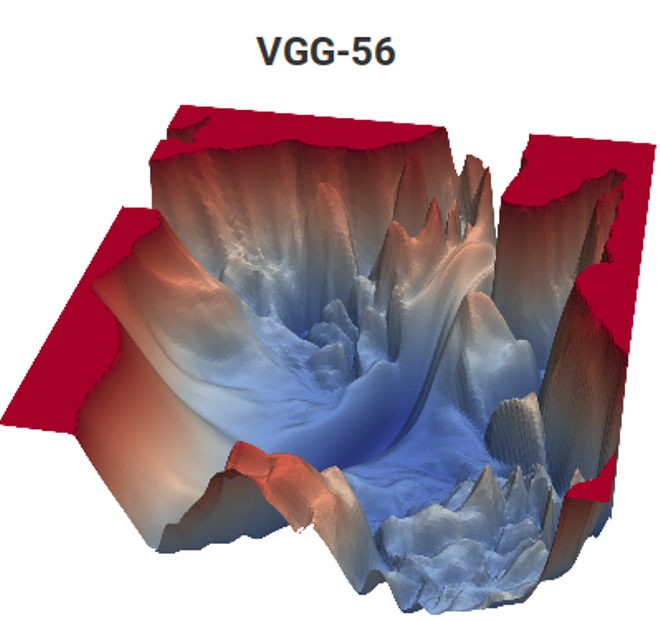 Fonte: Função de perda para tarefas de estimativa de movimento (materiais do autor) e VGG-56
Fonte: Função de perda para tarefas de estimativa de movimento (materiais do autor) e VGG-56À esquerda, você precisa encontrar o ponto mais profundo em uma superfície não trivial, dependendo dos dados de entrada para o número mínimo de medições (muitos mínimos locais são possíveis), e à direita, você precisa encontrar um ponto mais baixo com cálculos mínimos (e também vários mínimos locais, e a superfície também depende dos dados) . À esquerda, temos o vetor de movimento previsto e, à direita, a rede treinada. E a diferença é que, à esquerda, há apenas uma medida implícita do espaço de cores, e à direita há um par de medidas de centenas de milhões. Bem, a complexidade computacional à direita é cerca de 12 ordens de magnitude (!) Superior. Um pouco assim ... Mas o segundo ano, mesmo com uma tarefa simples, oscila assim ... [cortado pela censura]. E o nível de programação dos alunos de ontem por razões desconhecidas nos últimos 15 anos caiu acentuadamente. Eles precisam dizer: "Você fará bem, eles o levarão ao DeepMind!" Pode-se dizer "invente o VGG", mas "eles levarão para o DeepMind" por algum motivo motiva melhor. Obviamente, este é um análogo avançado moderno do clássico "Você comerá sêmola, se tornará um astronauta!". No entanto, no nosso caso, se contarmos o número de crianças no país e o tamanho do corpo de cosmonautas, as chances são milhões de vezes maiores, porque dois de nós já trabalhamos no DeepMind em nosso laboratório.
Em seguida, foi a
ResNet , quebrando a barreira do número de camadas e começando a decolar após seis meses. E, finalmente, o DenseNet, que surgiu no começo do hype
, decolou quase imediatamente, ainda mais do que o ResNet.
Se estamos falando de popularidade, gostaria de acrescentar algumas palavras sobre as características da rede e o desempenho, das quais a popularidade também depende. Se você observar como a classe
ImageNet é prevista, dependendo do número de operações na rede, o layout será assim (mais alto e à esquerda - melhor):
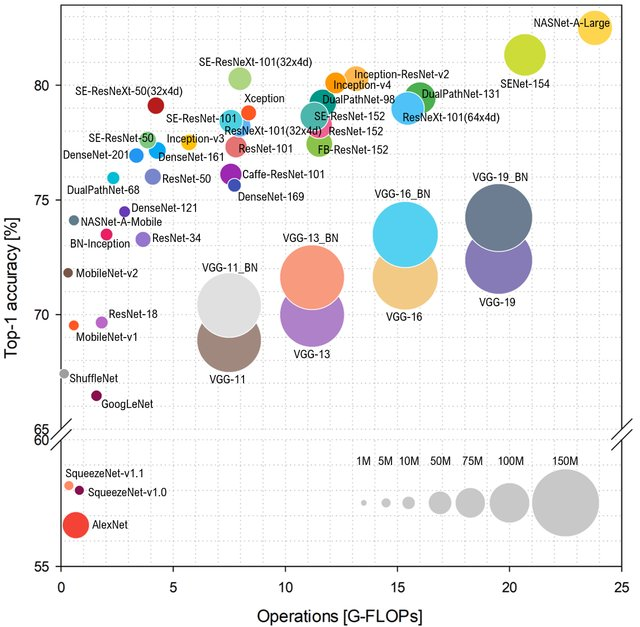 Fonte: Análise comparativa das arquiteturas de redes neurais profundas representativas
Fonte: Análise comparativa das arquiteturas de redes neurais profundas representativasO tipo AlexNet não é mais um bolo e eles governam redes baseadas no ResNet. No entanto, se você observar a avaliação prática do
FPS mais perto do meu coração, poderá ver claramente que o VGG está mais próximo do ideal aqui e, em geral, o alinhamento muda visivelmente. Incluindo o AlexNet inesperadamente no envelope ideal para Pareto (a escala horizontal é logarítmica, melhor acima e à direita):
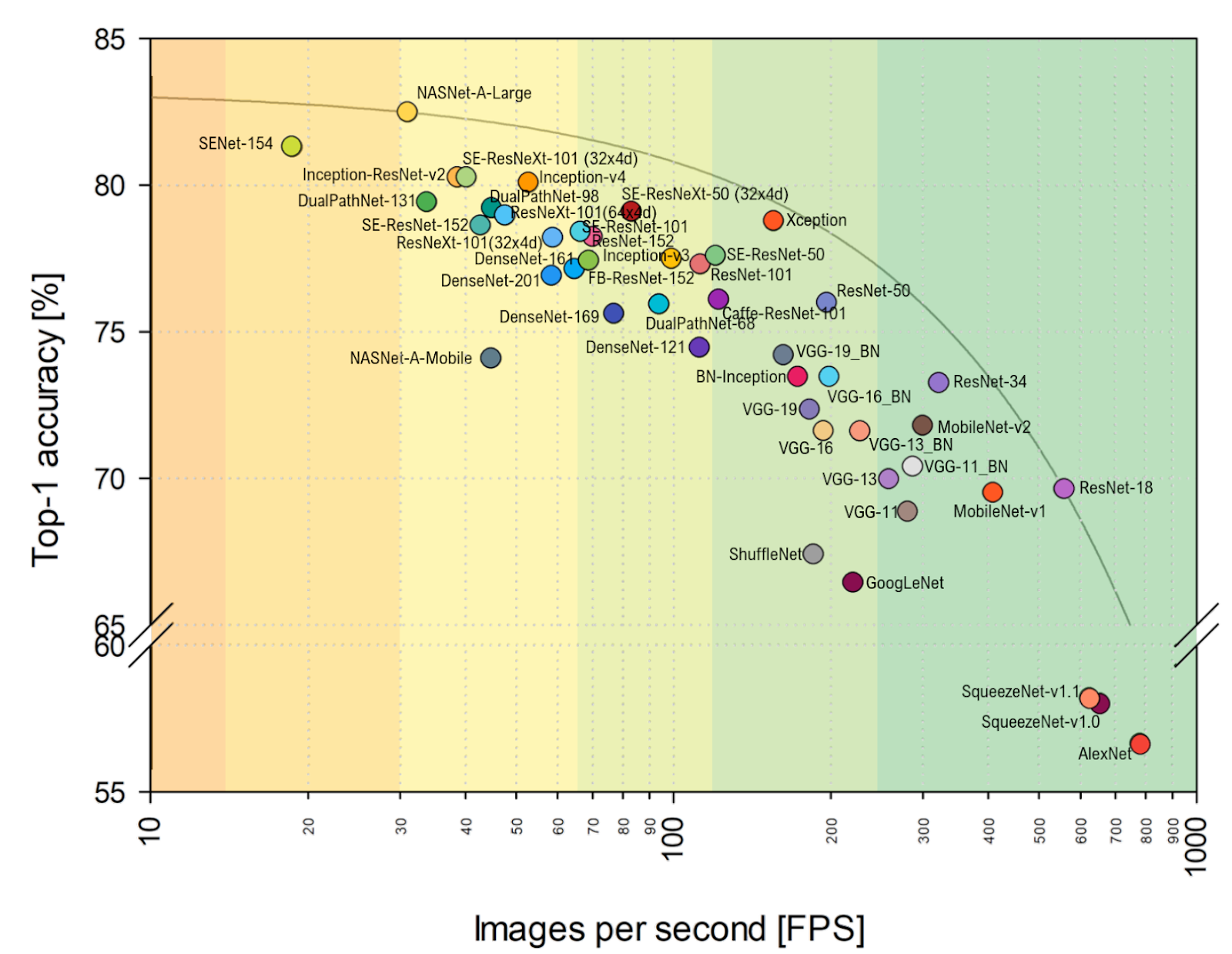 Fonte: Análise comparativa das arquiteturas de redes neurais profundas representativasTotal:
Fonte: Análise comparativa das arquiteturas de redes neurais profundas representativasTotal:
- Nos próximos anos, o alinhamento de arquiteturas com alta probabilidade mudará significativamente devido ao progresso dos aceleradores de redes neurais , quando algumas arquiteturas vão para cestas e outras decolam repentinamente, simplesmente porque é melhor optar por um novo hardware. Por exemplo, no artigo mencionado , é feita uma comparação no NVIDIA Titan X Pascal e na placa NVIDIA Jetson TX1, e o layout muda visivelmente. Ao mesmo tempo, o progresso do TPU, NPU e outros está apenas começando.
- Como profissional, não posso deixar de notar que a comparação no ImageNet é feita por padrão no ImageNet-1k, e não no ImageNet-22k, simplesmente porque a maioria treina suas redes no ImageNet-1k, onde há 22 vezes menos aulas (isso mais fácil e rápido). A mudança para o ImageNet-22k, que é mais relevante para muitas aplicações práticas, também mudará o alinhamento (para aqueles que são aguçados por 1k - muito).
Mais profundo em tecnologia e arquitetura
No entanto, de volta à tecnologia. O termo
Dropout como palavra de pesquisa é bastante barulhento, mas o crescimento em cinco vezes está claramente associado a redes neurais. E o declínio no interesse é mais provável com uma
patente do Google e o advento de novos métodos. Observe que cerca de um ano e meio passou da publicação do
artigo original para o aumento do interesse no método:
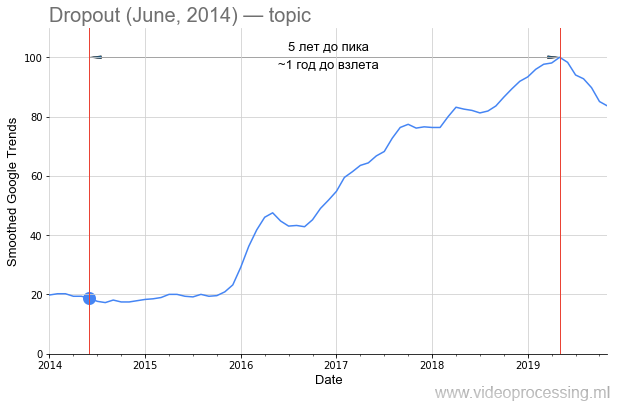
No entanto, se falarmos do período anterior ao aumento da popularidade, em DL, um dos primeiros lugares é claramente ocupado pelas
redes recorrentes e pelo
LSTM :
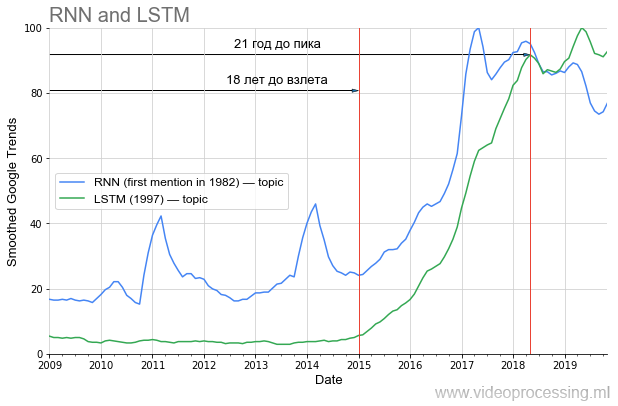
Muito 20 anos antes do atual pico de popularidade, e agora, com seu uso, a tradução automática e a análise do genoma foram drasticamente aprimoradas e, em um futuro próximo (se você tirar da minha área), o tráfego do YouTube, do Netflix com a mesma qualidade visual cairá duas vezes. Se você aprender corretamente as lições da história, é óbvio que parte das idéias do atual eixo de artigos “decolará” somente após 20 anos. Leve um estilo de vida saudável, cuide-se e você o verá pessoalmente!
Agora mais perto do hype prometido.
Os GANs decolaram assim:
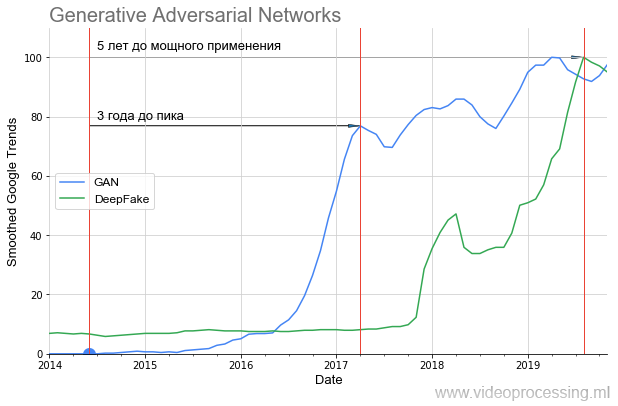
Pode-se ver claramente que por quase um ano houve silêncio total e somente em 2016, após dois anos, um aumento acentuado começou (os resultados foram visivelmente aprimorados). Essa decolagem, um ano depois, deu o sensacional DeepFake, que, no entanto, também decolou 1,5 anos. Ou seja, mesmo tecnologias muito promissoras exigem uma quantidade significativa de tempo para passar de uma ideia a aplicativos que todos possam usar.
Se você observar as imagens que a GAN gerou no
artigo original e o que pode ser construído com o
StyleGAN , torna-se bastante óbvio por que houve tanto silêncio. Em 2014, apenas especialistas puderam avaliar o quão legal foi - criar, em essência, outra rede como uma função de perda e treiná-los juntos. E em 2019, todo aluno pode apreciar o quão legal isso é (sem entender completamente como isso é feito):

Atualmente,
existem muitos problemas diferentes resolvidos com sucesso pelas redes neurais. Você pode pegar as melhores redes e criar gráficos de popularidade para cada direção, lidar com ruídos e picos de consultas de pesquisa etc. Para não espalhar meus pensamentos sobre a árvore, encerraremos esta seleção com o tópico algoritmos de segmentação, onde as idéias de
convolução atrosa / dilatada e
ASPP no último ano e meio foram disparadas
por si mesmas
no benchmark do algoritmo :
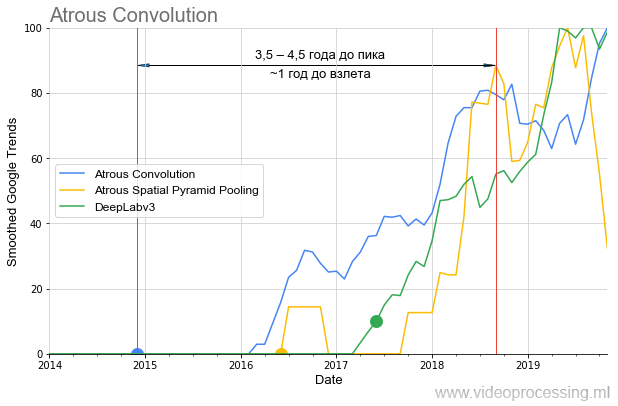
Também deve ser observado que, se o
DeepLabv1 mais de um ano "aguardava" o aumento da popularidade, o
DeepLabv2 decolava em um ano e o
DeepLabv3 quase que imediatamente. I.e. em geral, podemos falar sobre acelerar o crescimento do interesse ao longo do tempo (bem, ou acelerar o crescimento do interesse em tecnologias de autores respeitáveis).
Tudo isso levou à criação do seguinte problema global - um aumento explosivo no número de publicações sobre o tema:
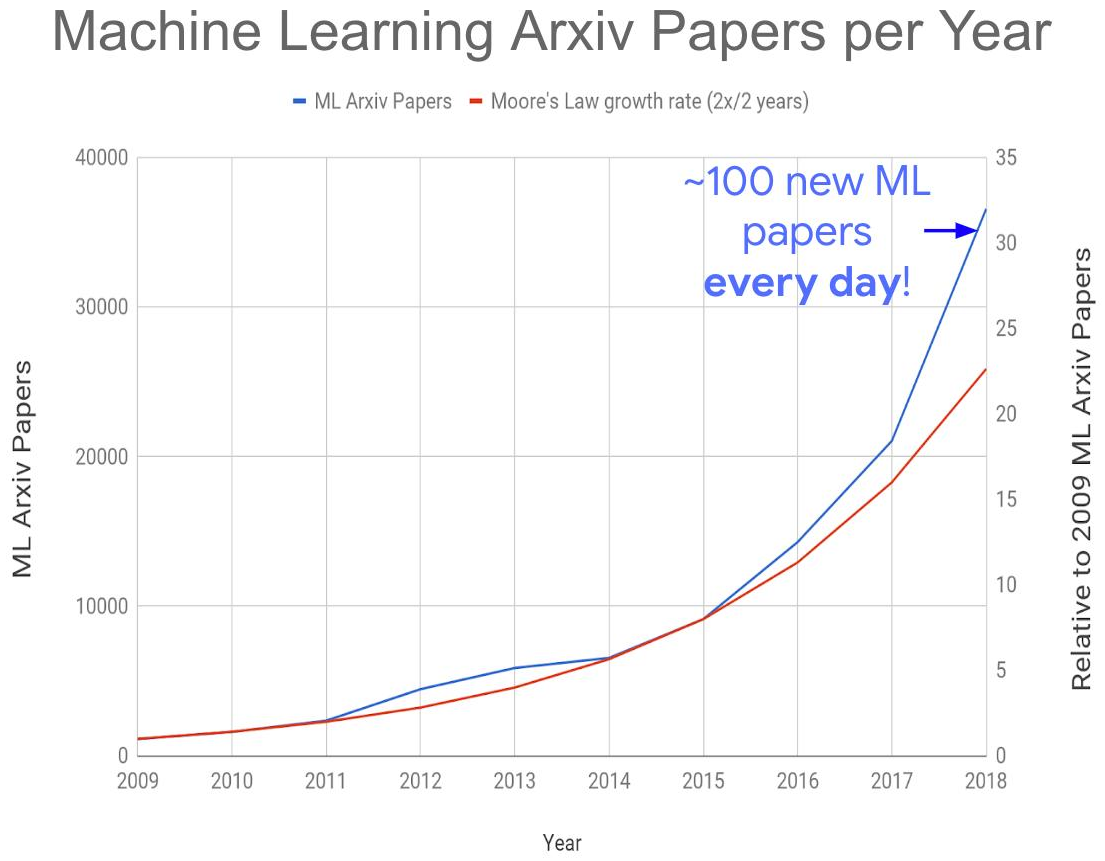 Fonte: Muitos documentos de aprendizado de máquina?
Fonte: Muitos documentos de aprendizado de máquina?Este ano, temos cerca de 150 a 200 artigos por dia, pois nem todos são publicados no arXiv-e. Hoje, ler artigos mesmo em sua própria subárea é completamente impossível. Como resultado, muitas idéias interessantes certamente serão enterradas sob os escombros de novas publicações, o que afetará o momento de sua "decolagem". No entanto, também o aumento
explosivo do número de especialistas competentes empregados na região dá
poucas esperanças de lidar com o problema.
Total:
- Além do ImageNet e da história dos bastidores dos sucessos dos jogos DeepMind, as GANs deram origem a uma nova onda de popularização de redes neurais. Com eles, era realmente possível “filmar” atores sem usar uma câmera . E se haverá mais! Sob esse ruído informacional, serão financiadas tecnologias de processamento e reconhecimento menos sonoras, mas bastante funcionais.
- Como existem muitas publicações, estamos ansiosos para o surgimento de novos métodos de redes neurais para análise rápida de artigos, porque somente eles nos salvarão (uma piada com uma fração de uma piada!).
Robôs de trabalho, homem feliz
Há 2 anos, o AutoML vem ganhando popularidade
nas páginas dos jornais . Tudo começou tradicionalmente com o ImageNet, no qual, com a Precisão Top 1, ele começou a tomar firmemente os primeiros lugares:
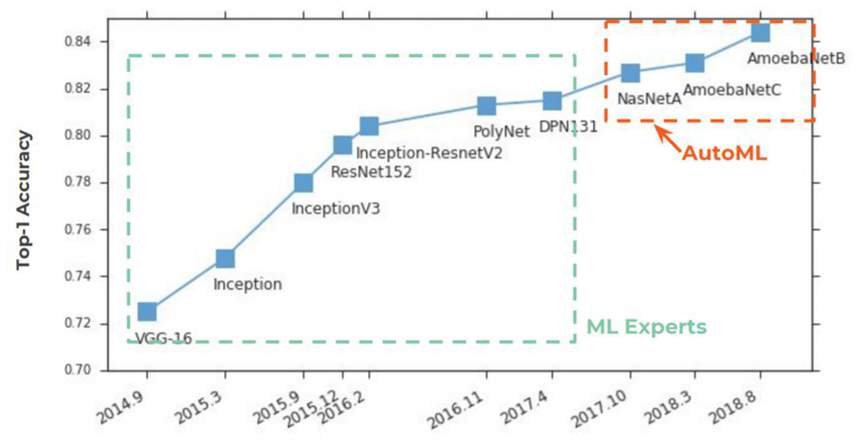
A essência do AutoML é muito simples, um sonho centenário de cientistas de dados se tornou realidade - para uma rede neural selecionar hiper parâmetros. A ideia foi recebida com um estrondo:
Abaixo no gráfico, vemos uma situação bastante rara quando, após a publicação dos artigos iniciais na
NASNet e
AmoebaNet , eles começam a ganhar popularidade pelos padrões das idéias anteriores quase instantaneamente (um grande interesse no tópico é afetado):
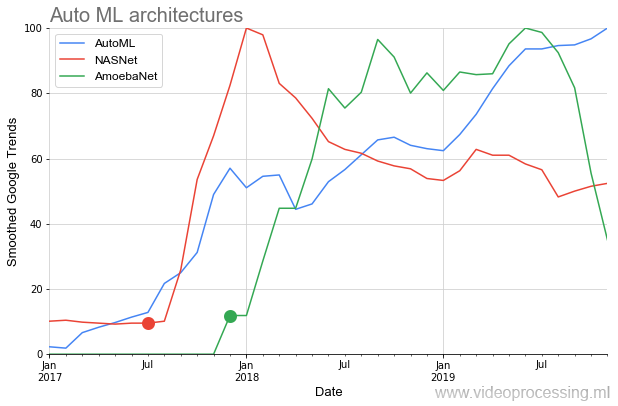
A imagem idílica é um pouco estragada por dois pontos. Em primeiro lugar, qualquer conversa sobre o AutoML começa com a frase: "Se você tem um dofigalion da GPU ...". E esse é o problema. O Google, é claro, alega que, com o
Cloud AutoML, isso é facilmente resolvido, o
principal é que você tem dinheiro suficiente , mas nem todos concordam com essa abordagem. Em segundo lugar, funciona até agora
imperfeitamente . Por outro lado, lembrando os GANs, cinco anos ainda não se passaram e a ideia em si parece muito promissora.
De qualquer forma, a principal decolagem do AutoML começará com a próxima geração de aceleradores de hardware para redes neurais e, de fato, com algoritmos aprimorados.
 Fonte: Imagem de Dmitry Konovalchuk, materiais do autorTotal: De fato, os cientistas de dados não terão um feriado eterno, é claro, porque por muito tempo permanecerá uma grande dor de cabeça com os dados. Mas antes do Ano Novo e do início da década de 2020, por que não sonhar?
Fonte: Imagem de Dmitry Konovalchuk, materiais do autorTotal: De fato, os cientistas de dados não terão um feriado eterno, é claro, porque por muito tempo permanecerá uma grande dor de cabeça com os dados. Mas antes do Ano Novo e do início da década de 2020, por que não sonhar?Algumas palavras sobre ferramentas
A eficácia da pesquisa depende muito das ferramentas. Se, para programar o AlexNet, você precisava de programação não trivial, hoje essa rede pode ser coletada em várias linhas em novas estruturas.
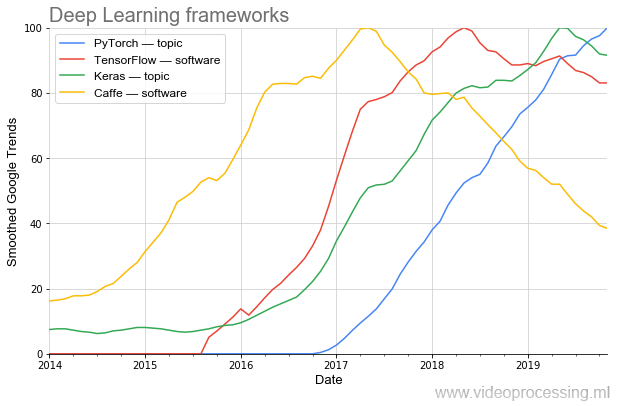
É claramente visto como a popularidade está mudando nas ondas. Hoje, o mais popular (inclusive de
acordo com PapersWithCode ) é o
PyTorch . E uma vez que o popular
Caffe lindamente sai muito bem. (Observação: tópico e software significa que a filtragem de tópicos do Google foi usada na plotagem.)
Bem, desde que abordamos as ferramentas de desenvolvimento, vale a pena mencionar bibliotecas para acelerar a execução da rede:
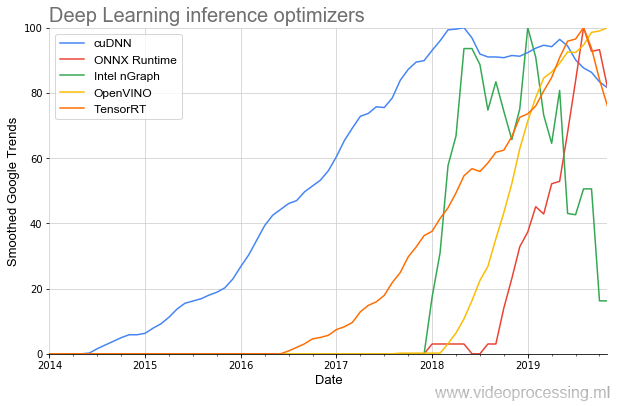
O mais antigo do tópico é (respeito à NVIDIA)
cuDNN e, felizmente para os desenvolvedores, nos últimos dois anos o número de bibliotecas aumentou várias vezes e o início de sua popularidade tornou-se visivelmente mais acentuado. E parece que tudo isso é apenas o começo.
Total: Mesmo nos últimos 3 anos, as ferramentas mudaram seriamente para melhor. E há 3 anos, pelos padrões de hoje, eles não eram de todo. O progresso é muito bom!Perspectivas de rede neural prometidas
Mas a diversão começa depois. Neste verão, em um
grande artigo separado, descrevi em detalhes por que a CPU e até a GPU não são eficientes o suficiente para trabalhar com redes neurais, por que bilhões de dólares estão fluindo para o desenvolvimento de novos chips e quais são as perspectivas. Eu não vou me repetir. Abaixo está uma generalização e adição do texto anterior.
Para começar, você precisa entender as diferenças entre os cálculos de redes neurais e os cálculos na arquitetura familiar de von Neumann (na qual eles podem, é claro, ser calculados, mas com menos eficiência):
 Fonte: Imagem de Dmitry Konovalchuk, materiais do autor
Fonte: Imagem de Dmitry Konovalchuk, materiais do autorNa época anterior, a discussão principal foi em torno de FPGA / ASIC, e os cálculos imprecisos passaram quase despercebidos, então vamos falar neles com mais detalhes. As enormes perspectivas de reduzir os chips das próximas gerações estão precisamente na capacidade de ler de forma imprecisa (e armazenar dados de coeficientes localmente). De fato, o espessamento também é usado na aritmética exata, quando os pesos da rede são convertidos em números inteiros e quantizados, mas em um novo nível. Como exemplo, considere um somador de um bit (o exemplo é bastante abstrato):
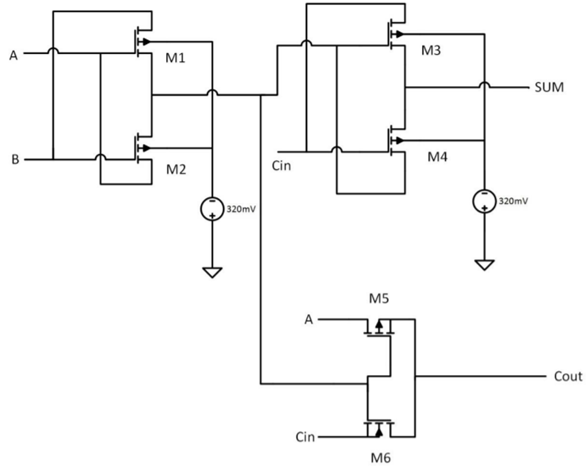 Fonte: Projeto de multiplicador de 8 bits x 8 bits de alta velocidade e baixa potência usando novas portas XOR de dois transistores (2T)
Fonte: Projeto de multiplicador de 8 bits x 8 bits de alta velocidade e baixa potência usando novas portas XOR de dois transistores (2T)Ele precisa de 6 transistores (existem abordagens diferentes, o número de transistores necessários pode ser cada vez menor, mas, em geral, algo assim). Para 8 bits,
são necessários aproximadamente
48 transistores . Nesse caso, o somador analógico requer apenas 2 (dois!) Transistores, ou seja, 24 vezes menos:
 Fonte: Multiplicadores Analógicos (Análise e Projeto de Circuitos Analógicos Integrados)
Fonte: Multiplicadores Analógicos (Análise e Projeto de Circuitos Analógicos Integrados)Se a precisão for maior (por exemplo, equivalente a 10 ou 16 bits digitais), a diferença será ainda maior. Ainda mais interessante é a situação com multiplicação! Se um multiplexador digital de 8 bits exigir cerca de
400 transistores , um analógico 6, ou seja, 67 vezes (!) Menos. Obviamente, transistores "analógicos" e "digitais" são significativamente diferentes do ponto de vista dos circuitos, mas a idéia é clara - se conseguirmos aumentar a precisão dos cálculos analógicos, chegaremos facilmente à situação em que precisaremos de duas ordens de magnitude a menos de transistores. E o objetivo não é tanto reduzir o tamanho (o que é importante em conexão com a "desaceleração da lei de Moore"), mas reduzir o consumo de eletricidade, o que é essencial para as plataformas móveis. E para data centers, não será supérfluo.
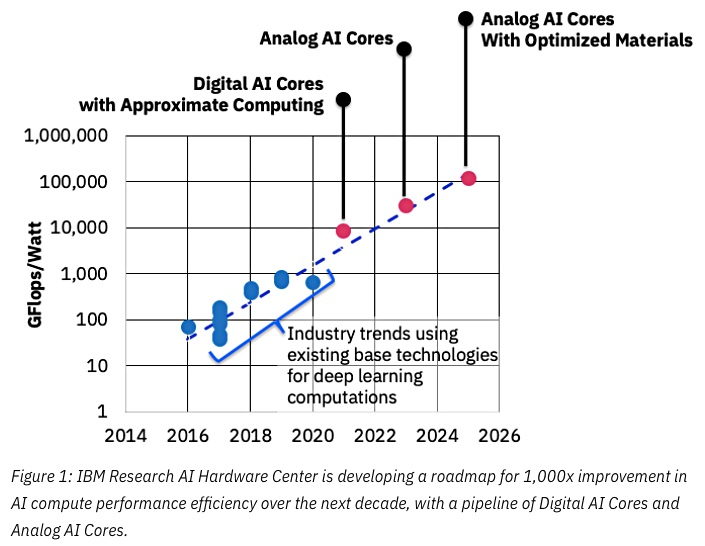 Fonte: IBM pensa em chips analógicos para acelerar o aprendizado de máquina
Fonte: IBM pensa em chips analógicos para acelerar o aprendizado de máquinaA chave do sucesso aqui será uma redução na precisão e, novamente, aqui a IBM está na vanguarda:
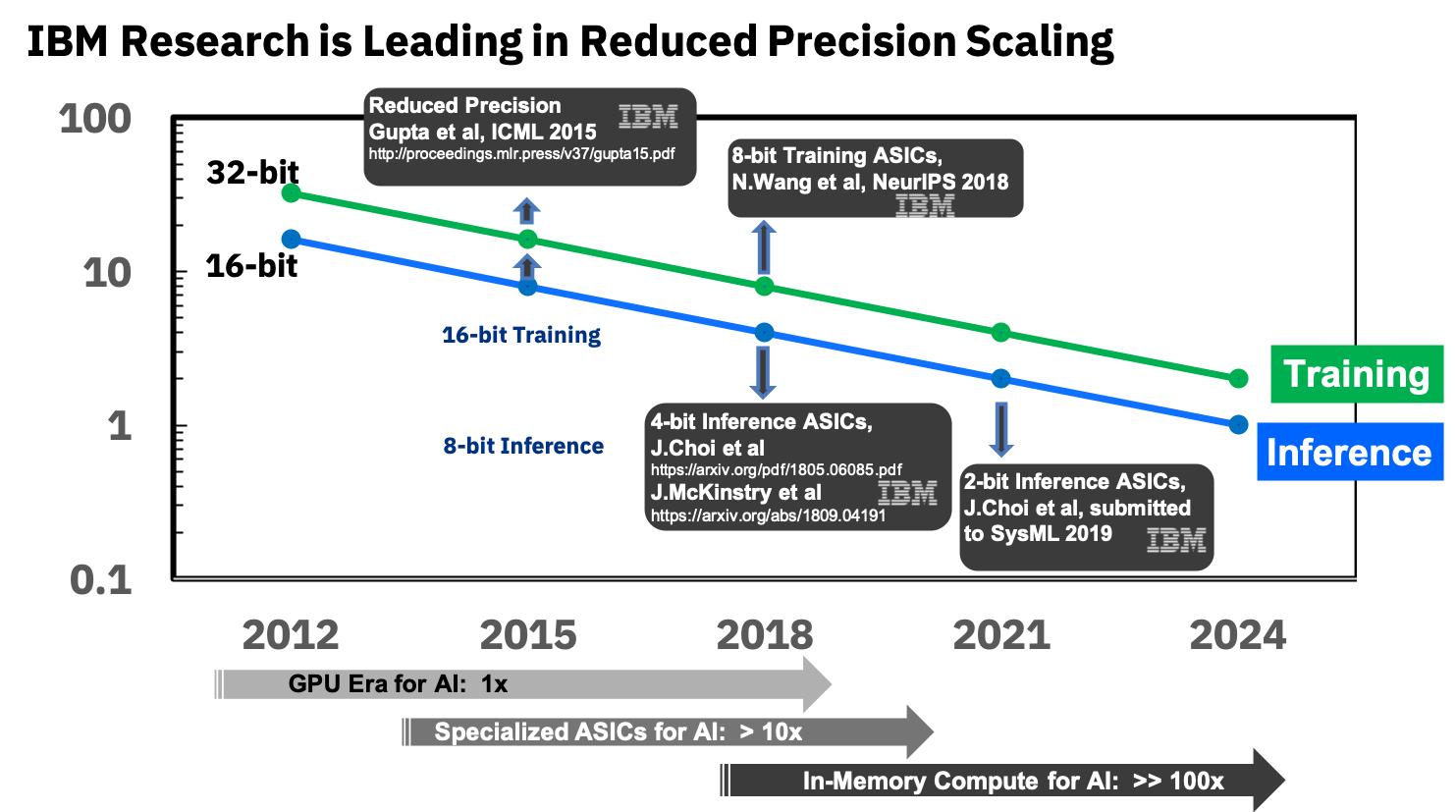 Fonte: IBM Research Blog: Precisão de 8 bits para o treinamento de sistemas de aprendizado profundo
Fonte: IBM Research Blog: Precisão de 8 bits para o treinamento de sistemas de aprendizado profundoEles já estão envolvidos em ASICs especializados para redes neurais, que mostram mais de 10 vezes superior à GPU e planejam atingir 100 vezes superior nos próximos anos. Parece extremamente encorajador, estamos realmente ansiosos por isso, porque, repito, isso será um avanço para os dispositivos móveis.
Enquanto isso, a situação não é tão mágica, embora haja sérios sucessos. Aqui está um teste interessante dos atuais aceleradores de hardware móvel das redes neurais (a imagem é clicável e novamente aquece a alma do autor, também em imagens por segundo):
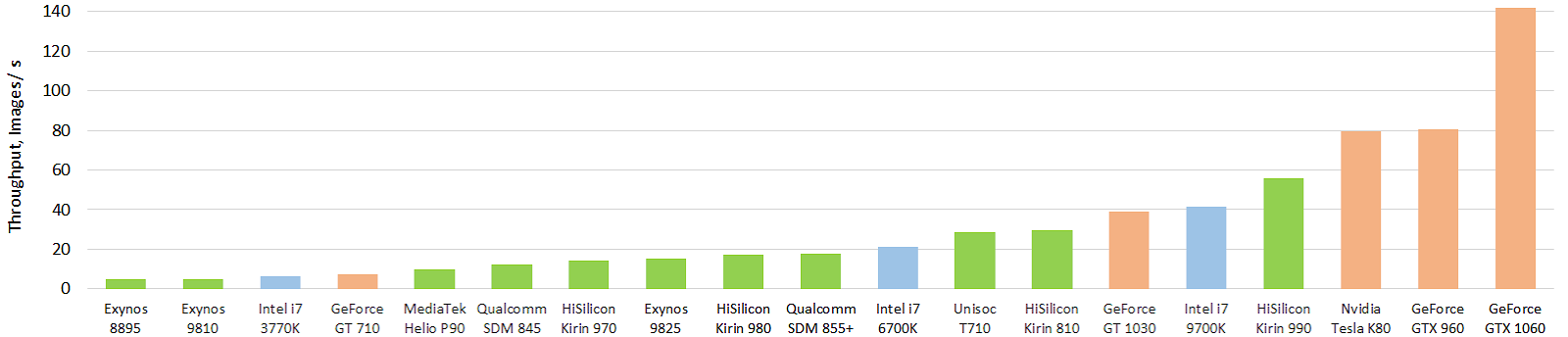 Fonte: Evolução do desempenho de aceleradores de IA móveis: taxa de transferência de imagem para o modelo float Inception-V3 (modelo FP16 usando TensorFlow Lite e NNAPI)
Fonte: Evolução do desempenho de aceleradores de IA móveis: taxa de transferência de imagem para o modelo float Inception-V3 (modelo FP16 usando TensorFlow Lite e NNAPI)Verde indica chips móveis, azul indica CPU, laranja indica GPU. É claramente visto que os chips móveis atuais e, em primeiro lugar, o chip topo de linha da Huawei, já estão superando as CPUs dezenas de vezes maiores em tamanho (e consumo de energia). E é forte! Com a GPU, até agora tudo não é tão mágico, mas haverá algo mais. Você pode ver os resultados com mais detalhes em um site separado
http://ai-benchmark.com/ , preste atenção à seção de testes, eles escolheram um bom conjunto de algoritmos para comparação.
Total: o progresso dos aceleradores analógicos hoje é bastante difícil de avaliar. Há uma corrida. Como os produtos ainda não foram lançados, existem relativamente poucas publicações. Você pode monitorar as patentes que aparecem com atraso (por exemplo, fluxo denso da IBM ) ou procurar patentes raras de outros fabricantes. Parece que será uma revolução muito séria, principalmente em smartphones e TPUs de servidores.Em vez de uma conclusão
Hoje, o ML / DL é chamado de nova tecnologia de programação, quando não escrevemos um programa, mas inserimos um bloco e o treinamos. I.e. Como no início, havia um montador, depois C, depois C ++, e agora, após 30 anos de espera, o próximo passo é o ML / DL:
Isso faz sentido. Recentemente, em empresas avançadas, os locais de tomada de decisão nos programas são substituídos por redes neurais. I.e.
se ontem houvesse soluções "nos FIs" ou em heurísticas que eram boas para o coração de um programador ou mesmo as equações de Lagrange (uau!) e outras realizações mais complexas de décadas de desenvolvimento da teoria de controle foram usadas, hoje eles colocam uma rede neural simples com 3-5 camadas com várias entradas e dezenas de chances. Ela aprende instantaneamente, trabalha significativamente com mais eficiência e o desenvolvimento de código se torna mais rápido. Se antes era necessário sentar, xamã , ligar o cérebro , agora eu o enfiei, alimentei dados e funcionou, e você está ocupado com coisas de nível superior. Apenas algum tipo de feriado!Naturalmente, a depuração agora é diferente. Se antes, quando algo não funcionava, havia uma solicitação: "Envie um exemplo em que não funcione!" E então um barbudo sério e experiente- O smartphone tira fotos do texto e o reconhece - são redes neurais,
- Um smartphone traduz bem rapidamente de um idioma para outro e fala uma tradução - redes neurais e mais uma vez redes neurais,
- O navegador e o alto-falante inteligente reconhecem muito bem a fala - novamente redes neurais,
- A TV mostra uma imagem de contraste brilhante de 8K do vídeo de entrada 2K - também uma rede neural,
- Os robôs na produção tornaram-se mais precisos, começaram a ver e reconhecer melhor as situações anormais - novamente redes neurais,
- 10 ,
- — ,
- — - — ,
- — ! )

Apenas quatro anos se passaram desde que as pessoas aprenderam a treinar redes neurais realmente profundas em muitos aspectos, graças a BatchNorm (2015) e pular conexões (2015), e três anos se passaram desde que eles "decolaram" e estamos realmente lendo os resultados de seu trabalho não viu. E agora eles chegarão aos produtos. Algo nos diz que nos próximos anos muitas coisas interessantes nos aguardam. Especialmente quando os aceleradores "decolam" ...

Era uma vez, se alguém se lembra, Prometeu roubou fogo do Olimpo e o entregou às pessoas. Zeus zangado com outros deuses criou a primeira beleza de uma mulher chamada Pandora, que foi dotada de muitas qualidades femininas maravilhosas
(de repente, percebi que a recontagem politicamente correta de alguns dos mitos da Grécia Antiga é extremamente difícil) . Pandora foi enviada às pessoas, mas Prometeu, que suspeitava que algo estava errado, resistiu ao feitiço, e seu irmão Epimeteu não. Como presente para o casamento, Zeus enviou um belo caixão com Mercúrio e Mercúrio, uma alma bondosa, cumpriu a ordem - ele entregou o caixão a Epimeteu, mas avisou-o para não abri-lo em nenhum caso. Pandora curiosa roubou o caixão do marido, abriu-o, mas havia apenas pecados, doenças, guerras e outros problemas da humanidade. Ela tentou fechar o caixão, mas já era tarde demais:
 Fonte: Igreja do artista Frederick Stuart, caixa aberta de Pandora
Fonte: Igreja do artista Frederick Stuart, caixa aberta de PandoraDesde então, a frase "abrir a caixa de Pandora" foi,
por curiosidade , realizar
uma ação irreversível, cujas consequências podem não ser tão bonitas quanto as decorações do caixão do lado de fora.
Você sabe, quanto mais eu mergulho nas redes neurais, mais distinta é a sensação de que essa é outra caixa de Pandora. No entanto, a humanidade tem a experiência mais rica em abrir essas caixas! Desde o recente recente - isto é energia nuclear e a Internet. Então, acho que podemos lidar juntos. Não é de admirar que um bando de homens
barbudos duros entre os abridores. Bem, um caixão é lindo, concorda! E não é verdade que existem apenas problemas, eles já têm um monte de coisas boas. Portanto, eles se uniram e ... nós abrimos ainda mais!
Total:
- O artigo não incluiu muitos tópicos interessantes, por exemplo, algoritmos clássicos de ML, aprendizado de transferência, aprendizado por reforço, popularidade de conjuntos de dados etc. (Senhores, vocês podem continuar o tópico!)
- Para a pergunta sobre o caixão: pessoalmente, acho que os programadores do Google que permitiram ao Google abandonar o contrato de US $ 10 bilhões com o Pentágono são ótimos e bonitos. Eles respeitam e respeitam. No entanto, observe que alguém ganhou essa grande licitação.
Leia também:
- Aceleração de hardware de redes neurais profundas: GPU, FPGA, ASIC, TPU, VPU, IPU, DPU, NPU, RPU, NNP e outras letras - o texto do autor sobre o estado atual e as perspectivas de aceleração de hardware de redes neurais em comparação com as abordagens atuais.
- Deep Fake Science, a crise da reprodutibilidade e de onde vêm os repositórios vazios - sobre os problemas na ciência gerados pelo ML / DL.
- Comparação de codecs mágicos de rua. Nós revelamos segredos - um exemplo de falsificação baseada em redes neurais.
Todo um grande número de novas descobertas interessantes na década de 2020 em geral e no Ano Novo, em particular!
Agradecimentos
Gostaria de agradecer cordialmente:
- Laboratório de Computação Gráfica e Multimídia Universidade Estadual de Moscou VMK M.V. Lomonosov por sua contribuição ao desenvolvimento da aprendizagem profunda na Rússia e não apenas
- pessoalmente Konstantin Kozhemyakov e Dmitry Konovalchuk, que fizeram muito para tornar este artigo melhor e mais visual,
- e, finalmente, muito obrigado a Kirill Malyshev, Yegor Sklyarov, Nikolai Oplachko, Andrey Moskalenko, Ivan Molodetsky, Evgeny Lyapustin, Roman Kazantsev, Alexander Yakovenko e Dmitry Klepikov por muitos comentários e correções úteis que tornaram este texto muito melhor!