Em TI, um projeto saudável é um sistema ou serviço que, por um lado, é de alta qualidade, ou seja, atende aos requisitos e usuários semelhantes. Por outro lado, obtém lucro, porque o negócio sempre quer realmente ganhar dinheiro. Sem um pacote de qualidade e negócios, nada de bom resultará disso.

Sob o corte, Ruslan Ostropolsky lhe dirá tudo sobre métricas que são indicadores da saúde dos sistemas de TI. Ele analisará o que são métricas, como elas mudam à medida que o projeto se desenvolve, quais são as melhores utilizadas em qual projeto. Explica como a qualidade e os negócios se ajudam em termos de métricas e por que essa colaboração é necessária.
Sobre o palestrante e a empresa: Ruslan Ostropolsky em TI desde 2010, a principal área de interesse é a garantia de qualidade. Nos últimos 5 anos, ele trabalha na DocDoc, uma empresa que desenvolve serviços médicos na Internet. O principal produto é uma consulta on-line com um médico, mais de 2 milhões de pacientes se inscreveram para um médico através do DocDoc, há também uma linha de diagnósticos, telemedicina e seguro VHI.
Quando qualidade e negócios não são amigos
Sem garantia de qualidade, será difícil para uma empresa ganhar dinheiro a longo prazo. Precisa de um monte de qualidade e negócios. Caso contrário, as seguintes situações são possíveis.
Em primeiro lugar, há
qualidade por uma questão de qualidade : quando todos os tipos conhecidos de teste são usados em uma pequena inicialização. Você pode pensar imediatamente sobre automação e teste com cargas, mas se você exagerar, o produto ainda pode não chegar à produção. Portanto, você precisa de:
- Entendendo o negócio - o que é relevante no momento: ganhar dinheiro, entrar no mercado ou escalar rapidamente. A tarefa do negócio é transferir esses objetivos para o departamento técnico.
- Qualidade no lugar certo e na quantidade certa. Às vezes, você pode liberar versões com erros, mas entenda os riscos e, portanto, leve isso em consideração.
Em segundo lugar, há outro caso - um
negócio sem qualidade . Uma empresa de TI pode até ter um departamento de testes, mas se o controle de qualidade for leve ou existir na forma de testes em macacos, o que simplesmente apaga a regressão e pára por aí, isso não melhorará muito.
NB: O controle de qualidade não está realmente testando, mas uma abordagem geral no nível da empresa de como você cria bons produtos.
Como entender se você está desenvolvendo alta qualidade ou não?
Uma avaliação objetiva requer métricas que mostram:
- O fato dos problemas. Que você basicamente tem problemas e, se não houver problemas, precisará procurá-los com mais cuidado. Provavelmente, eles estão em algum lugar, mas você ainda não os vê.
- O fato dos resultados. Projetos são criados para ganhar dinheiro, entrar no mercado, aumentar a conversão. Esses resultados precisam ser rastreados.
- Estado atual. Onde você está no seu caminho para suas metas, quantos bugs você possui atualmente, você consegue correr, com que rapidez está se movendo.
Como escolher métricas
Você pode escolher métricas de acordo com três princípios.
Onde dói. Se um incidente acontece, ele precisa ser desmontado, ponderado com métricas e analisado a dor: como está o tratamento, qual a dinâmica, se os bugs são corrigidos.
Com uma
abordagem direcionada, obviamente focamos em objetivos, por exemplo, aceleração e automação. Anteriormente, nossos testes automatizados levavam duas horas. Estabelecemos uma meta em 10 minutos e analisamos as métricas para ver se estávamos chegando a esse valor.
Mas é impossível obter um projeto saudável se as métricas não tiverem conexão com o negócio, são apenas técnicas e o negócio não obtém resultados. Por outro lado, se não houver bugs e a empresa perder dinheiro, algo estranho está acontecendo.
É importante lembrar que existem diferentes empresas e diferentes estágios de um projeto. Uma startup, uma empresa em crescimento ou um projeto de expansão precisam de métricas diferentes. É como uma doença - se você tossir, pode medir a temperatura, beber ácido ascórbico e tudo vai passar. Se você suspeita de pneumonia, precisa tirar fotos, fazer um exame e ser tratado de maneira diferente.
Métricas nas diferentes etapas do projeto
Vou lhe dizer quais métricas medimos quando éramos uma startup e, em seguida, começamos a crescer e expandir.
Inicialização
Nesta fase, o produto está apenas em sua infância, você está testando uma hipótese, investigando se as pessoas precisam.
No estágio de inicialização de uma empresa, é importante que as idéias sejam entregues ao usuário o mais rápido possível e que possam ser verificadas. Ou seja, você precisa medir o
tempo de colocação no mercado - a velocidade de entrega de idéias aos usuários (principalmente a produção e não apenas a liberação) e o
número de clientes .
Na parte do controle de qualidade, tínhamos apenas 3-5 métricas:
- número de bugs da batalha;
- o número de bugs que atingem o lançamento;
- criticidade de bugs.
A resposta para a questão de como coletar métricas é simples: existem mãos e existe o Excel. Cerca de uma vez por mês, coloque as mãos na tabela de dados, isso deve ser suficiente.
Estão crescendo
Na próxima etapa, já aprendemos a ficar de pé, a andar um pouco.
As necessidades de negócios estão evoluindo, torna-se importante medir:
- Tráfego Quando ficou claro que os usuários precisam do produto, o máximo de tráfego possível é gerado, por exemplo, os programas afiliados aparecem.
- Escalonamento - o máximo possível para crescer tanto do lado do produto quanto do lado do desenvolvimento.
O controle de qualidade já está aumentando: 10 a 15 métricas. Se em uma startup criamos um produto de acordo com nossos sentimentos, por exemplo, o fundador disse: “Eu quero um botão azul”, e todo mundo fez isso, agora existe a primeira estatística. Você pode pular os recursos através dos
testes A / B e lembre-se de medir os resultados.
Automação aparece. O teste com macacos não é mais suficiente e faz sentido investir em uma extensão. Nesse momento, o teste automático é exibido, o que deve ajudar a tornar o teste de regressão mais rápido. Assim, a
velocidade do teste de liberação é medida
: quanta justificação é automatizada. É triste quando a automação levou seis meses e, por algum motivo, os lançamentos não foram acelerados.
O
volume do release também é medido para verificar se, por exemplo, em vez de 5 desenvolvedores, ele se tornou 15, mas, por alguma razão, o volume do release não aumentou.
Para coletar métricas no estágio de crescimento, além de mãos e Excel, aparecem sistemas especializados. Sistemas são quaisquer ferramentas que ajudam a criar um produto. Se anteriormente os mesmos casos de teste foram escritos nos documentos do Google, eles aparecerão aqui:
- gerente de sistema, por exemplo, TestRail;
- Google Analytics para coleta de dados do usuário;
- Portal de relatórios, Allure para automação.
O sistema cria dentro de si métricas e relatórios adicionais.
Gordura
Crescemos ainda mais, “superamos a gordura” - não entramos nos escritórios em que estávamos sentados e começamos a nos mover periodicamente.
O que é importante para os negócios?- LTV. Precisa manter os clientes. Se anteriormente o cliente gravou uma vez e saiu, agora, obviamente, é necessário mantê-lo, para criar um serviço ao usuário.
- Marca / Reputação. Se as pessoas que entraram em contato com o DocDoc pudessem pensar que esta é uma clínica, agora sabem que estão no serviço que as ajuda.
- SLA À medida que as pessoas começam a usar o serviço constantemente, a disponibilidade do serviço se torna crítica, porque qualquer tempo de inatividade afeta diretamente o dinheiro.
- Dados. Os primeiros dados são exibidos, produto e técnico e usuário, que devem poder processar e armazenar. Há uma pergunta de segurança.
- Conversão No estágio de dimensionamento, um produto fundamentalmente novo não é criado, mas o criado melhora.
O controle de qualidade já inclui aproximadamente 30 a 50 métricas. Medimos:
- Carga: back-end, servidor e frente, e em diferentes fatias.
- Segurança
- Taxa de liberação.
- Velocidade de automação.
- Estabilidade da automação: a velocidade e a estabilidade da automação afetam diretamente a velocidade dos lançamentos, porque a regressão manual não é o lugar nesta fase do desenvolvimento do projeto.
- Cobertura de automação.
Coletamos dados como antes, mas há mais sistemas usados.
Dificuldades
Tudo não acontece sem problemas e não somos exceção. Vou lhe dizer quais dificuldades encontramos quando o projeto cresceu o suficiente.
Existem muitos sistemas , é necessário gerenciá-los de alguma forma. Olhar para cada sistema é pelo menos muito tempo.
O número de direções , tanto de mercearia quanto de técnico,
aumentou . Além disso, cada direção se desenvolve de maneira diferente, algumas delas são lançadas como uma startup e será errado colocar métricas e garantia de qualidade em todas elas.
Os processos ficaram mais complicados : se cinco pessoas trabalharam anteriormente no projeto, foi fácil concordar e agir de acordo, agora precisamos monitorar os processos. Por exemplo, novas pessoas precisam ser introduzidas gradualmente, caso contrário, será difícil para elas entender o número acumulado de sistemas.
Dados e relatórios são exclusivos dentro do serviço. Isso decorre do fato de haver muitos sistemas e você precisar observá-los todos. Cada serviço gera seus próprios relatórios e você precisa segui-los todos. Além disso, está ficando mais difícil configurá-los para você: você precisa entrar em contato com o suporte técnico para um novo relatório ou tentar configurá-lo usando scripts.
E se houver muitos dados, o
Excel não ajudará . Especialmente se dezenas de pessoas começarem a trabalhar em um arquivo no qual tudo está configurado em fórmulas - alguém mudou alguma coisa, tudo quebrou - eles viram em uma semana.
Talvez seja assim que os analistas aparecem nas empresas - pessoas especiais que coletam e mantêm estatísticas e dados, porque leva muito tempo para serem combinadas.
E, é claro, torna-se muito
mais difícil analisar as informações devido ao fato de que novamente existem muitos sistemas, dados diferentes que você deseja relacionar.
Trate a tristeza
Você pode ir ao mar, relaxar, voltar e ver a experiência de outras empresas.
A solução lógica é reunir tudo em termos de dados e convertê-los em métricas.
Formulamos os seguintes critérios:
- Colete automaticamente para que ninguém carregue nada em qualquer lugar.
- Implemente várias representações de dados.
- Deveria haver vários sistemas: se metade dos dados forem coletados do Jira, metade do TestRail, eles deverão cair em um cofrinho, do qual será obtido um relatório exclusivo.
- Tudo deve ser gerenciável e fácil de manter. Isso significa que as próprias pessoas podem criar os relatórios necessários com base no sistema e apoiá-los.
Dashboards
Temos muitos painéis, apenas técnicos ativos agora têm cerca de 30 e cerca de 100 no total.
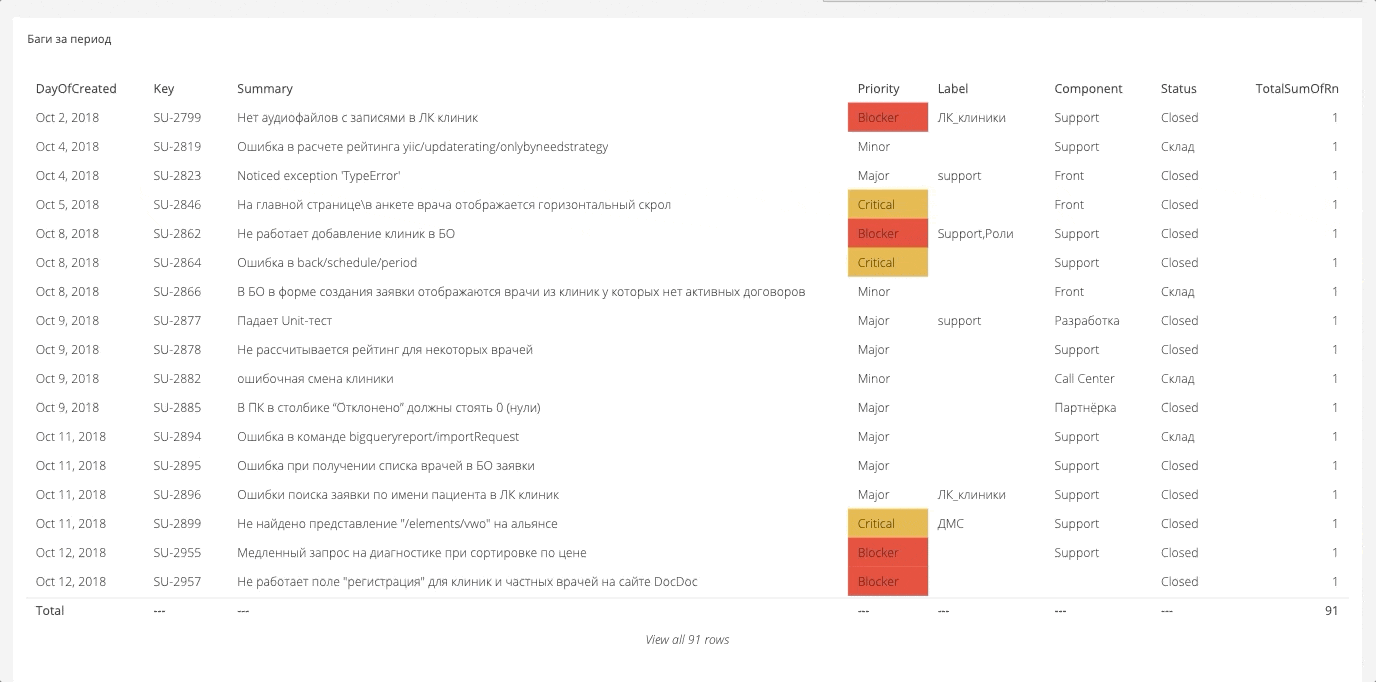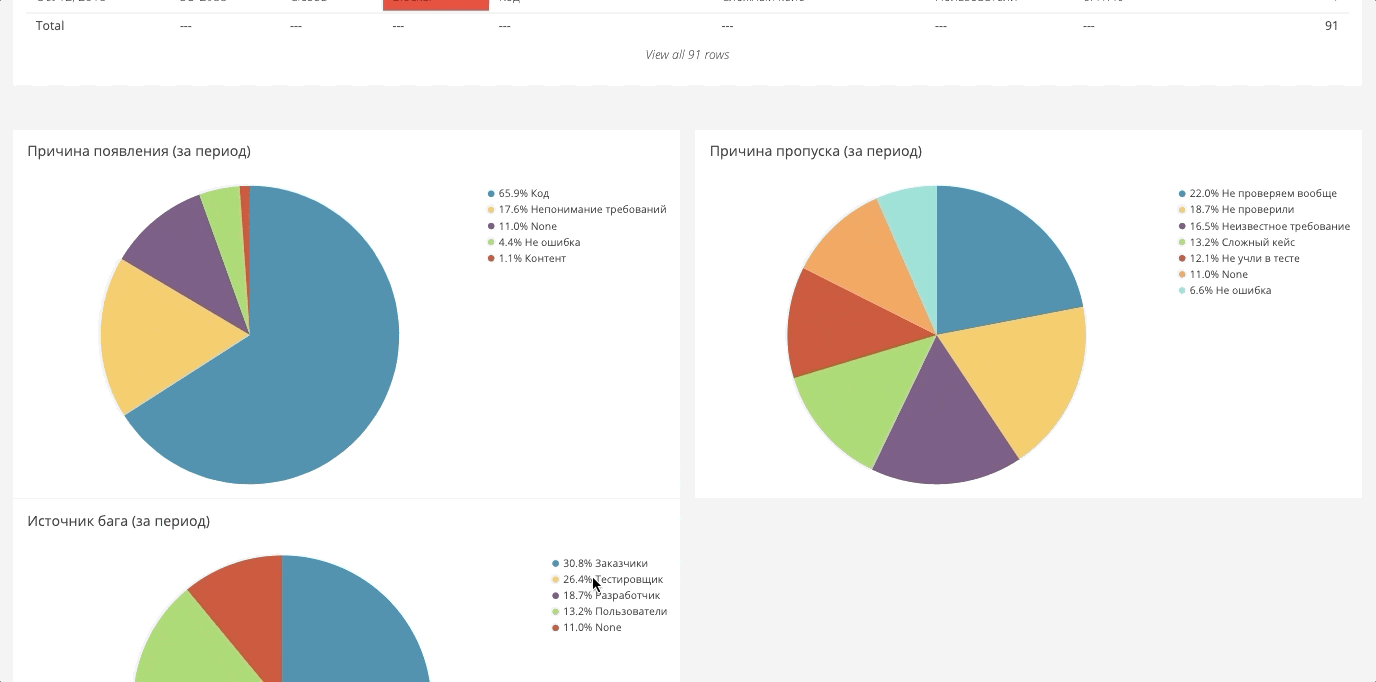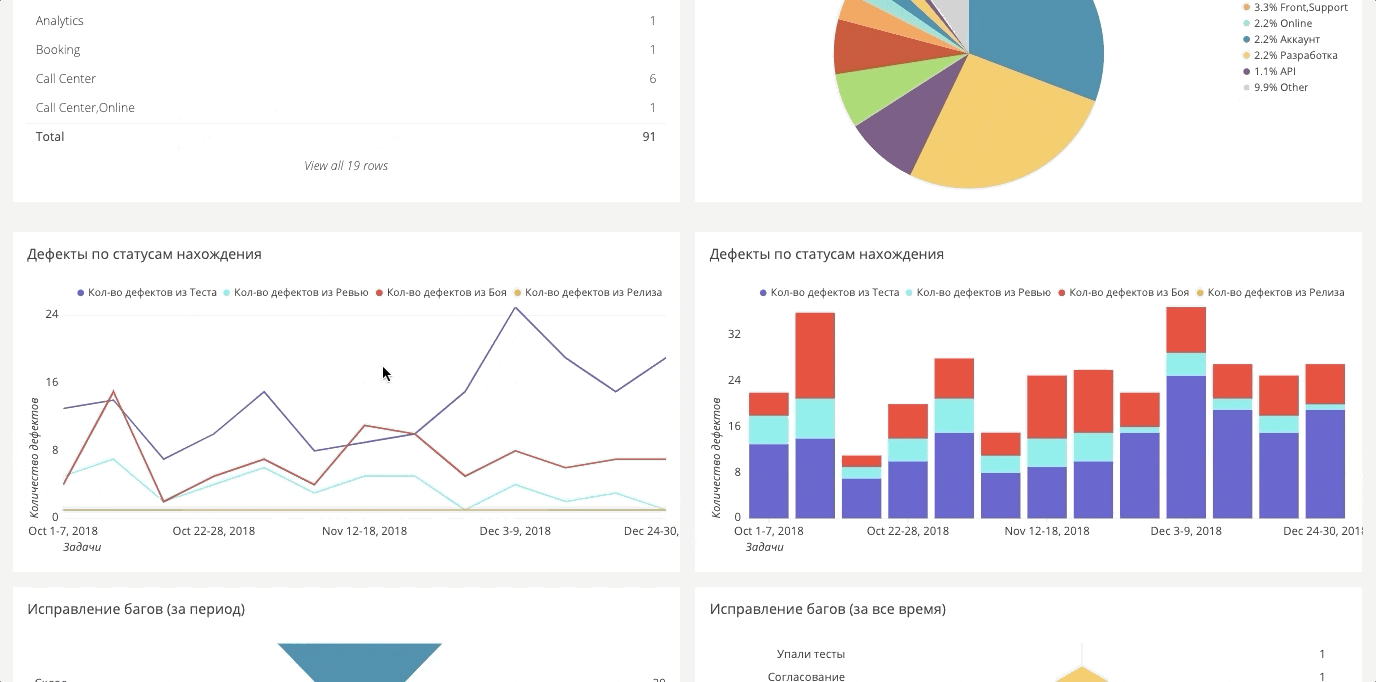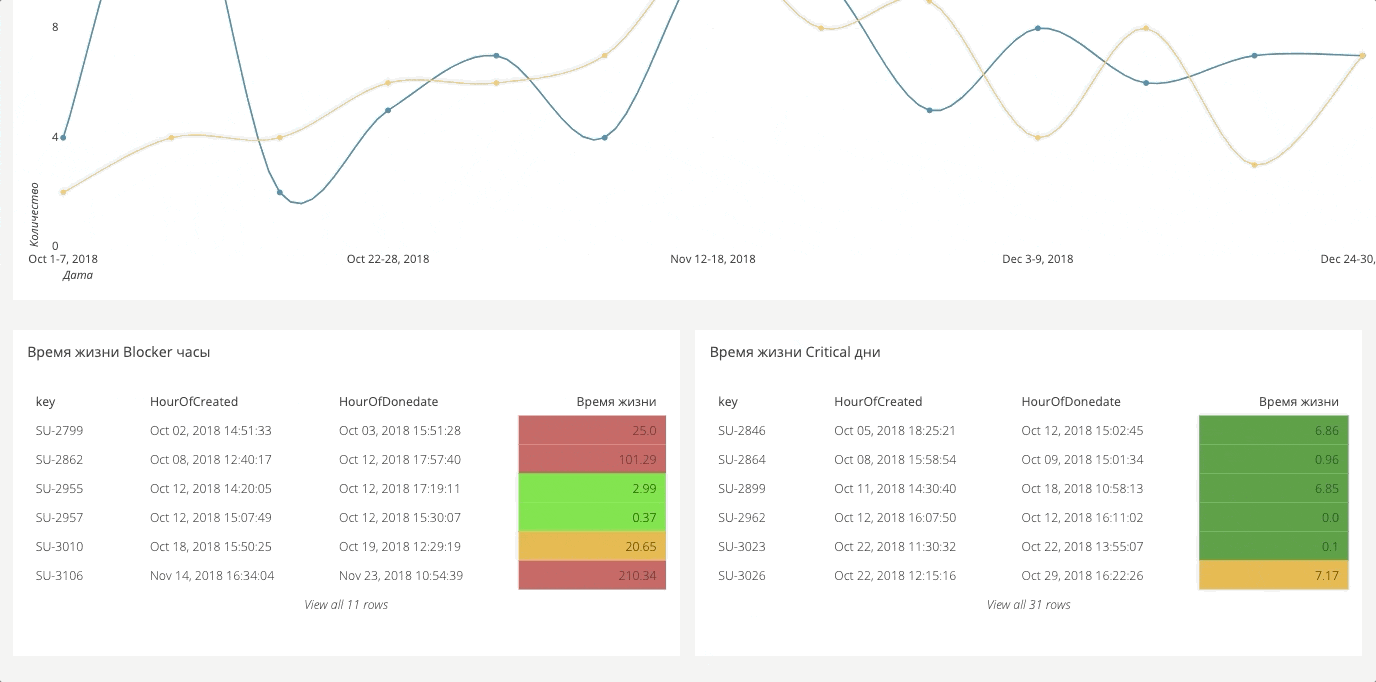
Os dados para o painel são coletados geralmente de qualquer lugar. Acontece uma tela grande a partir da qual você pode gerar os relatórios necessários. Abaixo estão alguns exemplos.
Criticality Bug Breakdown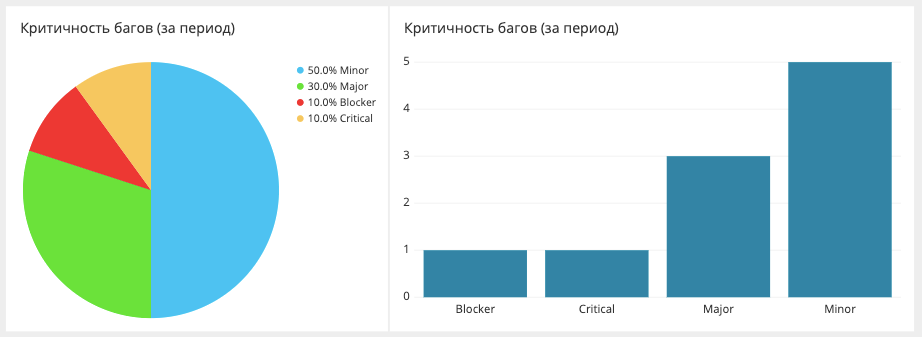
Aqui, medimos e exibimos o número de bugs por um determinado período e quão críticos eles foram. Os dados são extraídos de Jira. A própria Jira, provavelmente, pode criar um relatório desse tipo, mas não de uma forma muito conveniente.
Repartição de erros por campos própriosNo Jira, você pode compactar qualquer campo personalizado, e esses campos podem ser analíticos, que também são carregados no sistema geral. Por exemplo, abaixo estão os erros do componente.
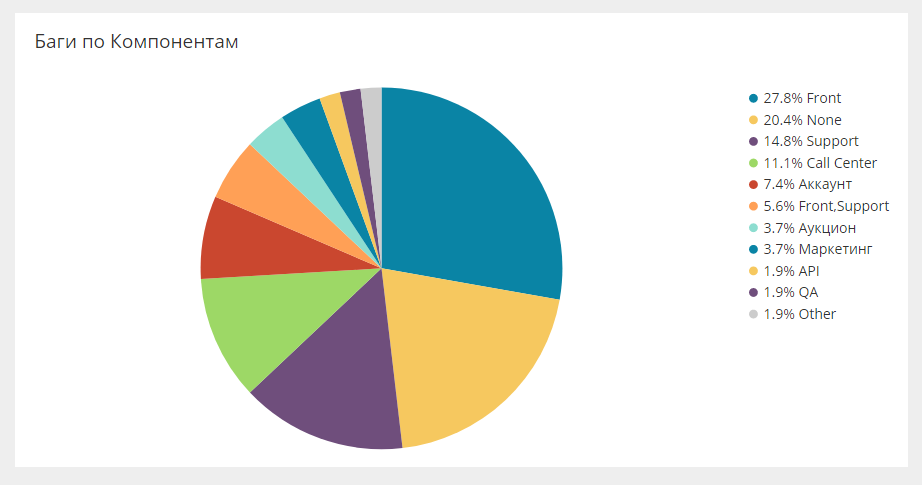
Existe o mesmo corte para equipes, pessoas, direções. Isso permite que você assista uma variedade de fatias.
A proporção de erros novos e fechadosSe criarmos 20 bugs e fecharmos apenas 5, em algum momento iremos mergulhá-los. Portanto, você precisa seguir os números e se esforçar para que a proporção seja igual a 1.
 Tendência de bug no período
Tendência de bug no períodoO sistema conveniente que introduzimos é o upload de todos os dados históricos e a dinâmica.

Em Jira, isso é um pouco complicado. Tudo funciona automaticamente para nós, e você pode escolher qualquer período e ver se conseguiu melhorar alguma coisa e se os processos e idéias introduzidos funcionaram.
Etapas para encontrar bugsSe antes medimos apenas bugs na batalha, agora nos esforçamos para garantir que não haja bugs na batalha e construímos fatias em diferentes estágios: batalha, lançamento, teste, automação, revisão, requisitos.
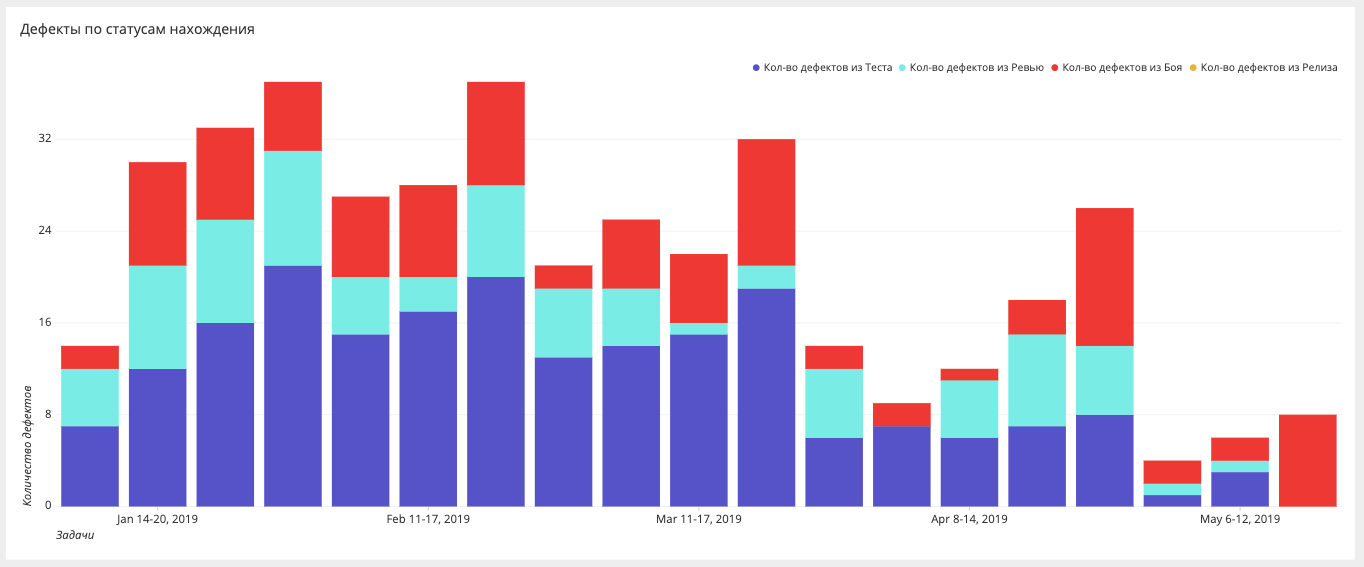 Painel de automação
Painel de automaçãoPara testes automáticos, também há um painel. É muito grande, então abaixo estão dois fragmentos separados.

Ele exibe o número de erros perdidos. Se você tem 90% de cobertura, mas na verdade metade dos erros são simplesmente comentados ou ignorados, isso é muito crítico, porque, na realidade, apenas 50% da funcionalidade funciona corretamente.
A mesma coisa com as falhas: quantos testes travam. Normalmente, destacamos as diferentes causas de travamentos: travamento do sistema, travamento de bug, a funcionalidade mudou. Separadamente, compartilhamos travamentos que dependiam do sistema e do ambiente e que eram puramente baseados em testes. O primeiro é o trabalho da equipe de operação, o segundo é a automação.
Também analisamos a cobertura de automação. Pegamos todos os pacotes do TestRial e também podemos mergulhar nos blocos de funcionalidade e determinar, por exemplo, que a pesquisa é coberta em 30%.

Além disso, os dados sobre o corte de status são refletidos aqui:
- Novo - nova funcionalidade.
- Precisa de correção - você precisa atualizar o caso.
- Não é necessário - não quero cobrir a automação.
- Feito - Coberto.
A crítica também tem seu próprio corte.
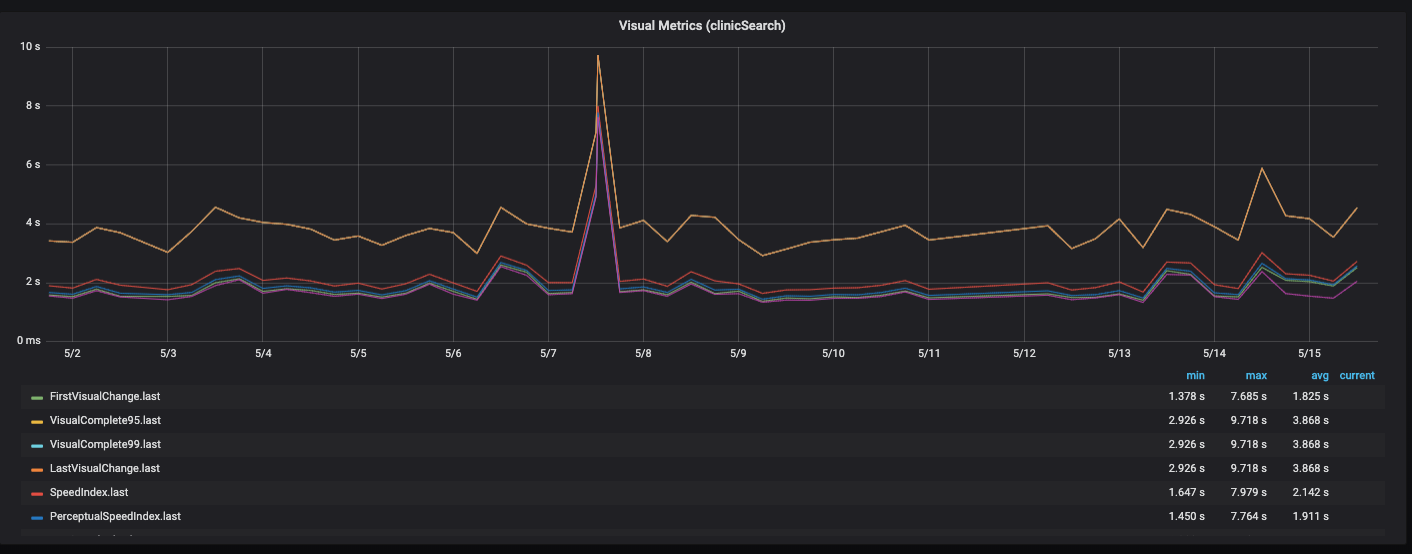
Desempenho do painelEstamos construindo esse painel na Grafana e carregando as métricas separadamente por API, front-end, back-end e servidor. Há um bloco que mostra a fatia atual da versão mais recente. Assim, você pode se enquadrar em cada uma das métricas e ver a dinâmica.

Tudo se sobrepõe a diferentes funcionalidades, diferentes páginas do site.
Voar sobre
Parece que agora está tudo bem: ela se reúne e, em um só lugar, várias métricas. Você pode seguir em frente com segurança.
Mas há novos problemas ao longo do caminho. Existem muitos gráficos e, portanto, eles são vistos com menos frequência. Quando há cinco horários, é fácil verificar todos os dias. Com um aumento no número, é obtido um regime de uma vez por semana - também bom. E, de repente, três dias atrás, houve um fakap, que ninguém notou. Portanto, a reação se torna longa e as métricas e painéis conseguem se tornar obsoletos. Existem várias razões para isso, que também precisam ser capazes de lutar.
Precisamos criar
gráficos agregados : dos 10, fazemos um que mostre o estado desses 10. Além disso, aumentamos os principais indicadores. Você abre o painel e vê imediatamente os valores desejados e todo o resto, o que revela as métricas com mais detalhes.
Compartilhamos: métricas de negócios, métricas de processo, métricas de controle de qualidade (Web / Mobile, Manual / Automation, Performance).
É assim que o gráfico agregado (NPS, CSAT) se parece.
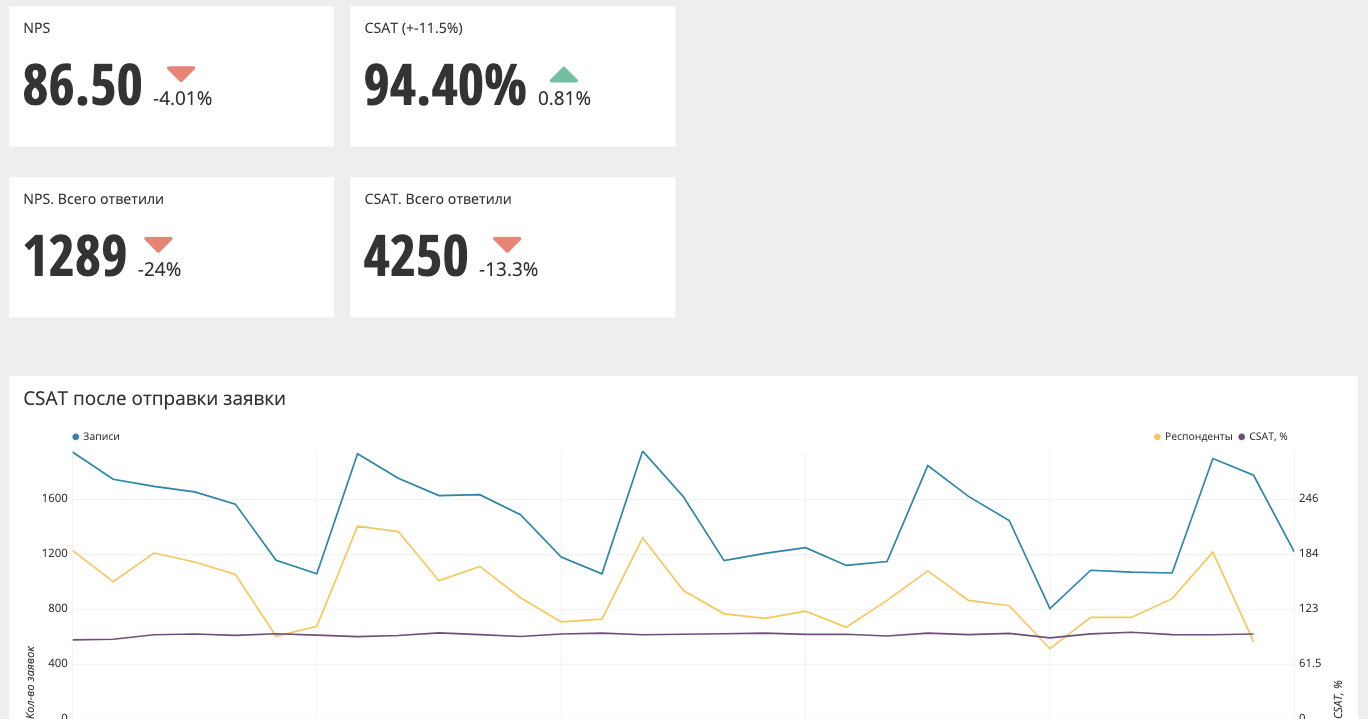
No topo estão os valores e o delta em comparação com o período anterior. Nesse caso, se a seta estiver vermelha, você precisará fazer algo, pelo menos veja os gráficos com mais detalhes. Se a seta estiver verde, tudo está bem e você não pode reagir.
Além disso, os gráficos têm a
capacidade de cair para um nível mais baixo , sem ir a lugar algum.

Os erros estão relacionados às pessoas que os permitiram (testadores ou desenvolvedores). Se você clicar separadamente em algum testador, uma tabela separada será aberta - uma fatia para tarefas.
O próximo passo é resolver o problema em que os gráficos raramente são controlados. Nomeadamente, expandiremos o esquema de trabalho com dados e métricas: adicione notificações às métricas necessárias.
Alertas
Usamos muitos alertas. Vou dar exemplos de categorias e situações específicas:
- Desempenho
- Testes automáticos. Por exemplo, se a porcentagem de erros perdidos for muito alta ou se muitas funcionalidades novas não forem cobertas por testes.
- Erros recebidos. Em nossa empresa, qualquer pessoa pode obter um bug no sistema de tickets. Anteriormente, isso era acompanhado por uma mensagem no PM, e agora existe um canal para notificações de novos bugs; além disso, os bugs são automaticamente atribuídos ao executor por sua vez. A pessoa designada deve analisar o erro, caso contrário, o bot o lembrará a cada 15 minutos.
- Velocidade de teste / Teste pendente. Se estiver claro que uma pessoa se enterrou em uma tarefa - não importa, ela a codificou, fez uma revisão, a testou - um alerta deve aparecer: "Você já está realizando três tarefas, talvez tenha sido enterrado, peça ajuda".
- Defeitos na tarefa / equipe.
- Revisão de casos de teste. Isso é apenas a automação do processo, para não fazê-lo manualmente.
Exemplos de alerta
Para tarefas que queimam, o bot grava o número, o status, a prioridade, por quanto tempo a tarefa já está sendo testada e quem a está testando.

Uma notificação, elaborada na forma de um resumo, chega a um indivíduo que analisa quais problemas ele tem. Aqui está um exemplo de alertas para o caso de teste que o TestRial envia.

Indica quais casos são atribuídos a quem, com qual status e quem precisa ser observado.
Outro exemplo é o bot Yabeda, que monitora processos.

Isso foi necessário para configurar o processo de vinculação do bug e da tarefa. O desenvolvedor, analisando o bug, deve encontrar a tarefa na qual perdemos esse bug, para uma análise mais aprofundada, para saber por que perdemos o bug. Este é um tipo de análise do incidente, mas com atraso.
Quantos alertas você precisa e com que frequência?
Se houver muitos alertas, haverá muito estresse deles. Portanto, estabelecemos regras de gerenciamento de alertas para nós mesmos.
Muitos alertas - pare de responder. 500 alertas por dia, você definitivamente vai parar para ter tempo para navegar, o que significa que você pode pular os importantes.
Muito pouco - sem problemas. Se houver muito poucas mensagens, por exemplo, apenas jogue fora metade, você poderá não encontrar algum tipo de problema.
Não tem problema - um resumo dos fatos. Na ausência de problemas, os alertas também devem ser enviados, mas na forma de um resumo: o que aconteceu durante o dia, o que funcionou, quais tarefas foram, o que aconteceu. Se você não fizer um resumo, poderá pensar que tudo acabou de quebrar e precisará procurar quais alertas caíram.
: , . , , - , . ,
:
- — , .
- — , , . , , . .
- — , , , , .
,
:- — , , .
- / . , , .
- . , .
- . , . , . , , .
. , . . , , , , . , , : , .
, :
, , . . -, , , , , 15 , . -, , . . -, . , , , , , .
Online
. , . , . , .

QA
, QA .
: , , .
: , , .
:

— , X ( ), () (). , - , ( ) : , . , . , , . , , .
: — , , ( , , ).
: « ». , , , , . - . .
, , . , , . .
-
: , , . , .
: , , , .
, 10 , 500, . , .
. , , .

,
, , . , , . «5 », .
, , , .
Sumário
— , . , . , . , , , — , .
:. , , , . .
— . , . , , - .
. , .
:- ~ 50 QA 100 .
- ~ 30 .
- — , .
- .
- .
- QA must have.
Nossa conferência, que combina todos os aspectos do desenvolvimento de produtos de alta qualidade, renascerá no próximo ano, sairá do RIT ++ e se tornará um evento independente em grande escala, TechLead Conf. Em breve anunciaremos a data e o local no canal de telegrama , mas se você viu por experiência própria que o processo de desenvolvimento não é um conjunto de tijolos desconectados e deseja compartilhar soluções para processos de engenharia de construção, solicite um relatório sem aguardar anúncios.