Às vezes, pode ser necessário analisar o desempenho do programa ou o consumo de memória em um programa C ++. Infelizmente, muitas vezes isso não é tão fácil quanto parece.
Aqui, consideraremos os recursos dos programas de criação de perfil usando as
ferramentas valgrind e
google perftools . O material acabou não sendo muito estruturado, é uma tentativa de montar uma base de conhecimento "para fins pessoais", para que no futuro você não precise se lembrar freneticamente de "por que isso não funciona" ou "como fazê-lo". Provavelmente, nem todos os casos não óbvios serão afetados aqui; se você tiver algo a acrescentar, escreva nos comentários.
Todos os exemplos serão executados no sistema linux.
Perfil de Tempo de Execução
Preparação
Para analisar os recursos de criação de perfil, executarei pequenos programas, geralmente consistindo em um arquivo main.cpp e um arquivo func.cpp, juntamente com a inclusão.
Vou compilá-los com o
compilador g ++ 8.3.0 .
Como criar um perfil de programas não otimizados é uma tarefa bastante estranha, compilaremos com a opção
-Ofast e, para obter caracteres de depuração na saída, não esqueceremos de adicionar a opção
-g . No entanto, às vezes, em vez de nomes de funções normais, você pode ver apenas endereços de chamada inaudíveis. Isso significa que houve uma "randomização da alocação de espaço de endereço". Isso pode ser determinado chamando o comando
nm no binário. Se a maioria dos endereços tiver algo como 00000000000030e0 (um grande número de zeros no início), provavelmente é isso. Em um programa normal, os endereços se parecem com 0000000000402fa0. Portanto, você precisa adicionar a opção
-no-pie . Como resultado, o conjunto completo de opções ficará assim:
-Ofast -g -no-piePara visualizar os resultados, usaremos o programa
KCachegrind , que pode funcionar com o
formato de relatório de
callgrindCallgrind
O primeiro utilitário que veremos hoje é o
callgrind . Este utilitário faz parte da ferramenta valgrind. Ele emula cada instrução executável do programa e, com base em métricas internas sobre o "custo" de cada instrução, emite a conclusão de que precisamos. Por causa dessa abordagem, às vezes acontece que o callgrind não consegue reconhecer a próxima instrução e cai com um erro
Instrução não reconhecida no endereçoA única maneira de sair dessa situação é reconsiderar todas as opções de compilação e tentar encontrar as interferências.
Vamos criar um programa para testar esta ferramenta, consistindo em uma biblioteca compartilhada e uma biblioteca estática (abandonaremos as bibliotecas posteriormente em outros testes). Cada biblioteca, assim como o próprio programa, fornecerá uma função computacional simples, por exemplo, o cálculo da sequência de Fibonacci.
Compilamos o programa e executamos o valgrind da seguinte maneira:
valgrind --tool=callgrind ./test_profiler 100000000
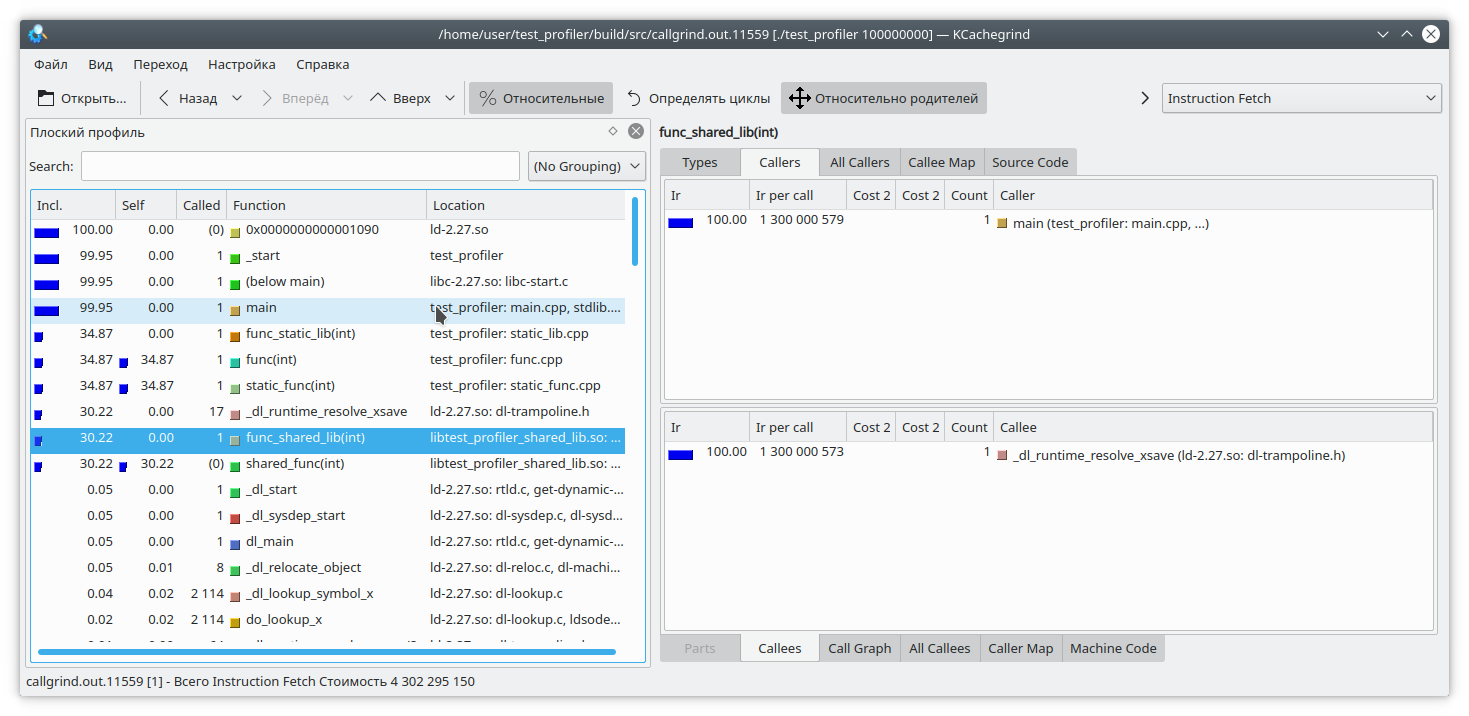
Vemos que, para uma biblioteca estática e uma função regular, o resultado é semelhante ao esperado. Mas na biblioteca dinâmica, o callgrind não pôde resolver completamente a função.
Para corrigir isso, ao iniciar o programa, você precisa definir a variável
LD_BIND_NOW como 1, assim:
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
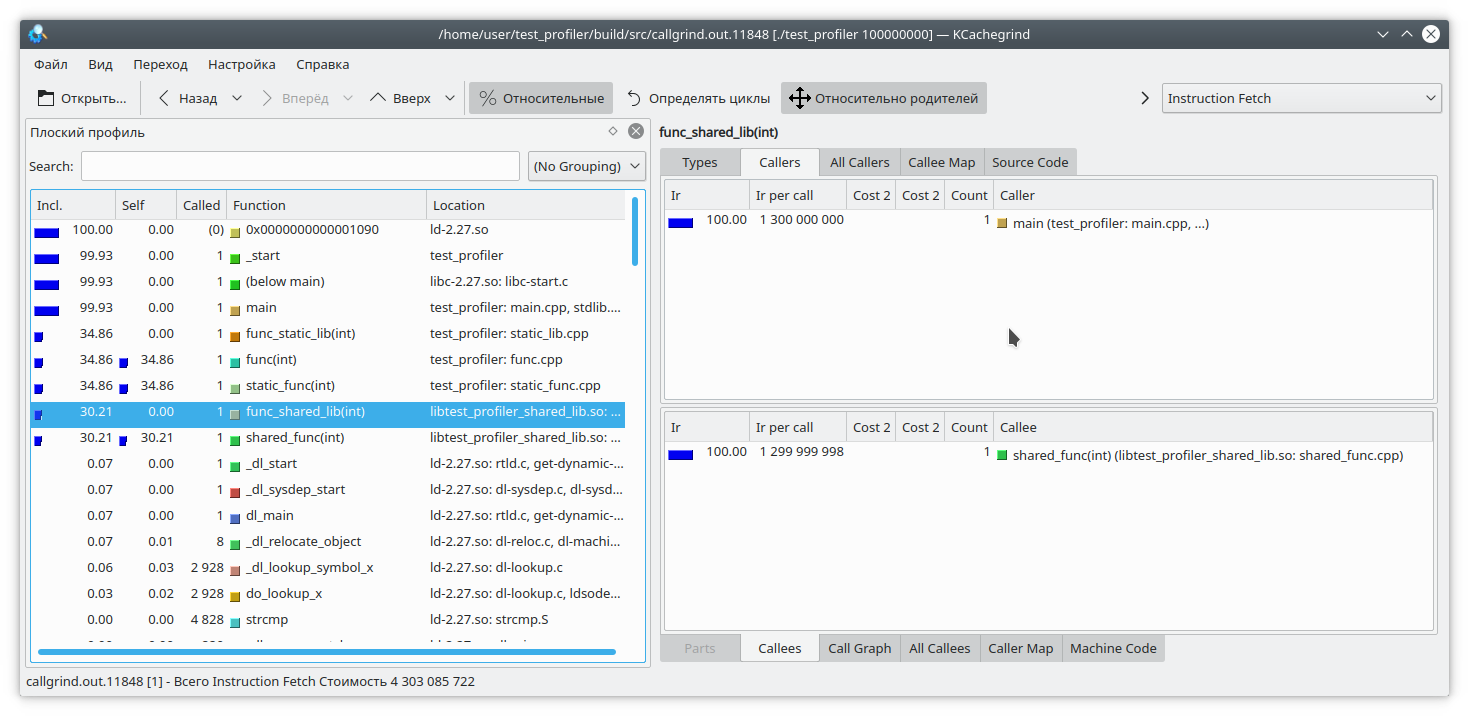
E agora, como você pode ver, está tudo bem
O próximo problema de moagem de chamada resultante da criação de perfil emulando instruções é que a execução do programa diminui bastante. Isso pode levar uma estimativa relativa incorreta do tempo de execução de várias partes do código.
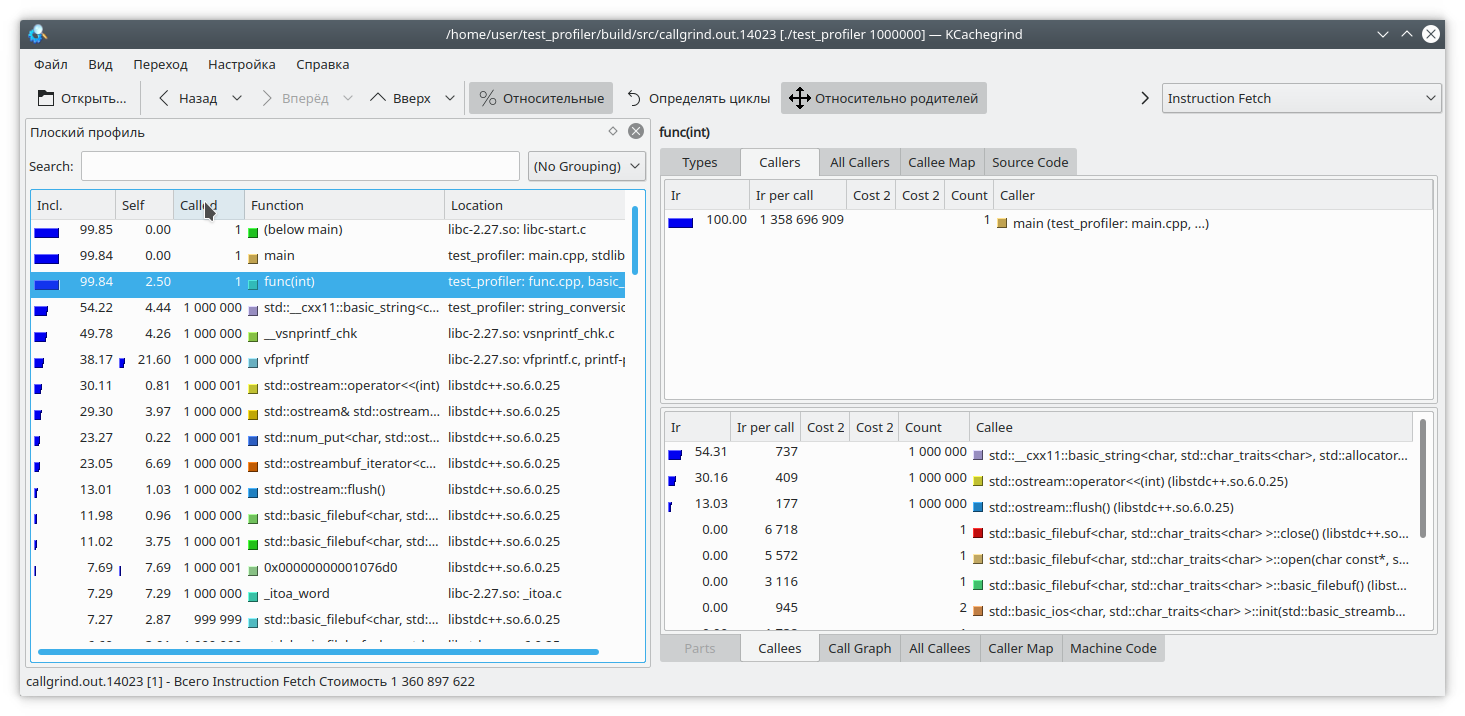
Vamos olhar para este código:
int func(int arg) { int fst = 1; int snd = 1; std::ofstream file("tmp.txt"); for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; std::string r = std::to_string(res); file << res; file.flush(); fst = snd; snd = res + r.size(); } return fst; }
Aqui, adicionei uma pequena quantidade de dados a um arquivo para cada iteração do loop. Como gravar em um arquivo é uma operação bastante demorada, como contrapeso, adicionei uma geração de linha de um número a cada iteração do loop. Obviamente, nesse caso, a operação de gravação no arquivo leva mais tempo que o restante da lógica da função. Mas o callgrind pensa de maneira diferente:
Também vale a pena considerar que o callgrind só pode medir o custo de uma função quando ela funciona. A função não funciona - portanto, o custo não aumenta. Isso complica a depuração de programas que, de tempos em tempos, entram no bloqueio ou trabalham com um sistema / rede de bloqueio de arquivos. Vamos verificar:
#include "func.h" #include <mutex> static std::mutex mutex; int funcImpl(int arg) { std::lock_guard<std::mutex> lock(mutex); int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; } int func2(int arg){ return funcImpl(arg); } int func(int arg) { return funcImpl(arg); } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); auto future = std::async(std::launch::async, &func2, arg); std::cout << "result: " << func(arg) << std::endl; std::cout << "second result " << future.get() << std::endl; return 0; }
Aqui, incluímos toda a execução da função no bloqueio do mutex e chamamos essa função de dois threads diferentes. O resultado do callgrind é bastante previsível - ele não vê problema em capturar um mutex:
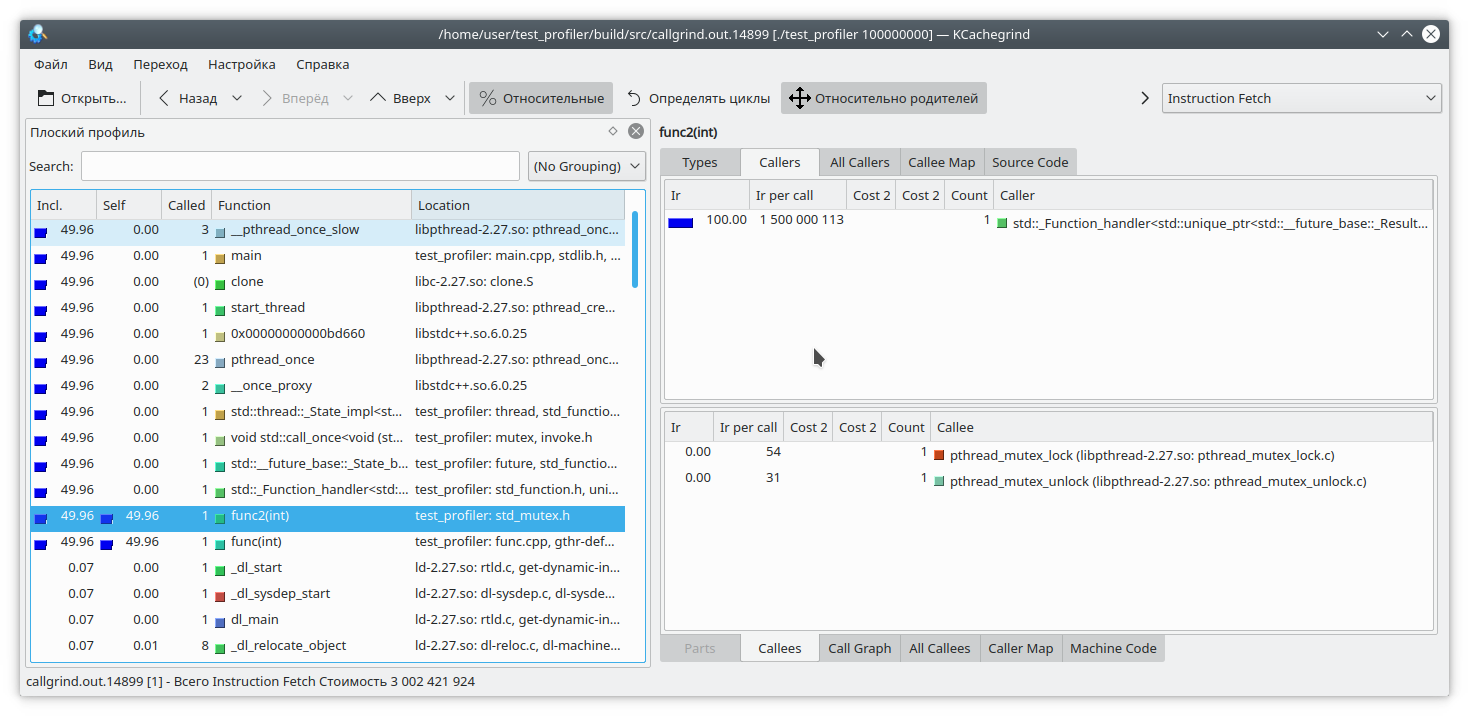
Portanto, examinamos alguns dos problemas do uso do gerador de perfil de chamada. Vamos para o próximo assunto de teste - o google perftools profiler
google perftools
Ao contrário do callgrind, o google profiler funciona com um princípio diferente.
Em vez de analisar cada instrução do programa executável, ele pausa o programa em intervalos regulares e tenta determinar em qual função ele está localizado. Como resultado, isso quase não afeta o desempenho do aplicativo em execução. Mas essa abordagem também tem suas fraquezas.
Vamos começar criando um perfil do primeiro programa com duas bibliotecas.
Como regra, para iniciar a criação de perfil com este utilitário, você deve pré-carregar a biblioteca libprofiler.so, configurar a frequência de amostragem e especificar um arquivo para salvar o dump. Infelizmente, o criador de perfil exige que o programa termine "por conta própria". O encerramento forçado do programa fará com que o relatório simplesmente não seja descartado. Isso é inconveniente ao criar um perfil de programas de longa duração que não são interrompidos, como daemons. Para contornar esse obstáculo, criei este script:
gprof.sh rnd=$RANDOM if [ $# -eq 0 ] then echo "./gprof.sh command args" echo "Run with variable N_STOP=true if hand stop required" exit fi libprofiler=$( dirname "${BASH_SOURCE[0]}" ) arg=$1 nostop=$N_STOP profileName=callgrind.out.$rnd.g gperftoolProfile=./gperftool."$rnd".txt touch $profileName echo "Profile name $profileName" if [[ $nostop = "true" ]] then echo "without stop" trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT else trap 'echo trap && kill -TERM $PID' TERM INT fi if [[ $nostop = "true" ]] then CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & else CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & fi PID=$! if [[ $nostop = "true" ]] then sleep 1 kill -12 $PID fi wait $PID trap - TERM INT wait $PID EXIT_STATUS=$? echo $PWD ${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName echo "Profile name $profileName" rm -f $gperftoolProfile*
Este utilitário precisa ser executado, passando como parâmetros o nome do arquivo executável e uma lista de seus parâmetros. Além disso, supõe-se que ao lado do script estejam os arquivos de que ele precisa libprofiler.so e pprof. Se o programa tiver vida longa e parar interrompendo a execução, você deve definir a variável N_STOP como true, por exemplo, assim:
N_STOP=true ./gprof.sh ./test_profiler 10000000000
No final do trabalho, o script gerará um relatório no meu formato de moagem de chamada favorito.
Então, vamos executar nosso programa nesse perfilador.
./gprof.sh ./test_profiler 1000000000

Em princípio, tudo está bem claro.
Como eu disse, o criador de perfil do Google funciona interrompendo a execução do programa e calculando a função atual. Como ele faz isso? Ele faz isso girando a pilha. Mas e se, no momento da promoção da pilha, o próprio programa desenrolasse a pilha? Bem, obviamente, nada de bom vai acontecer. Vamos conferir. Vamos escrever essa função:
int runExcept(int res) { if (res % 13 == 0) { throw std::string("Exception"); } return res; } int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; try { res = runExcept(res); } catch (const std::string &e) { res = res - 1; } fst = snd; snd = res; } return fst; }
E execute a criação de perfil. O programa congela rapidamente.
Há outro problema relacionado à peculiaridade da operação do criador de perfil. Suponha que conseguimos relaxar a pilha e agora precisamos combinar os endereços com as funções específicas do programa. Isso pode ser muito trivial, pois em C ++ um número bastante grande de funções está embutido. Vejamos um exemplo como este:
#include "func.h" static int func1(int arg) { std::cout << 1 << std::endl; return func(arg); } static int func2(int arg) { std::cout << 2 << std::endl; return func(arg); } static int func3(int arg) { std::cout << 3 << std::endl; if (arg % 2 == 0) { return func2(arg); } else { return func1(arg); } } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); int arg2 = func3(arg); int arg3 = func(arg); std::cout << "result: " << arg2 + arg3; return 0; }
Obviamente, se você executar o programa, por exemplo, assim:
./gprof.sh ./test_profiler 1000000000
então a função func1 nunca será chamada. Mas o criador de perfil pensa de maneira diferente:
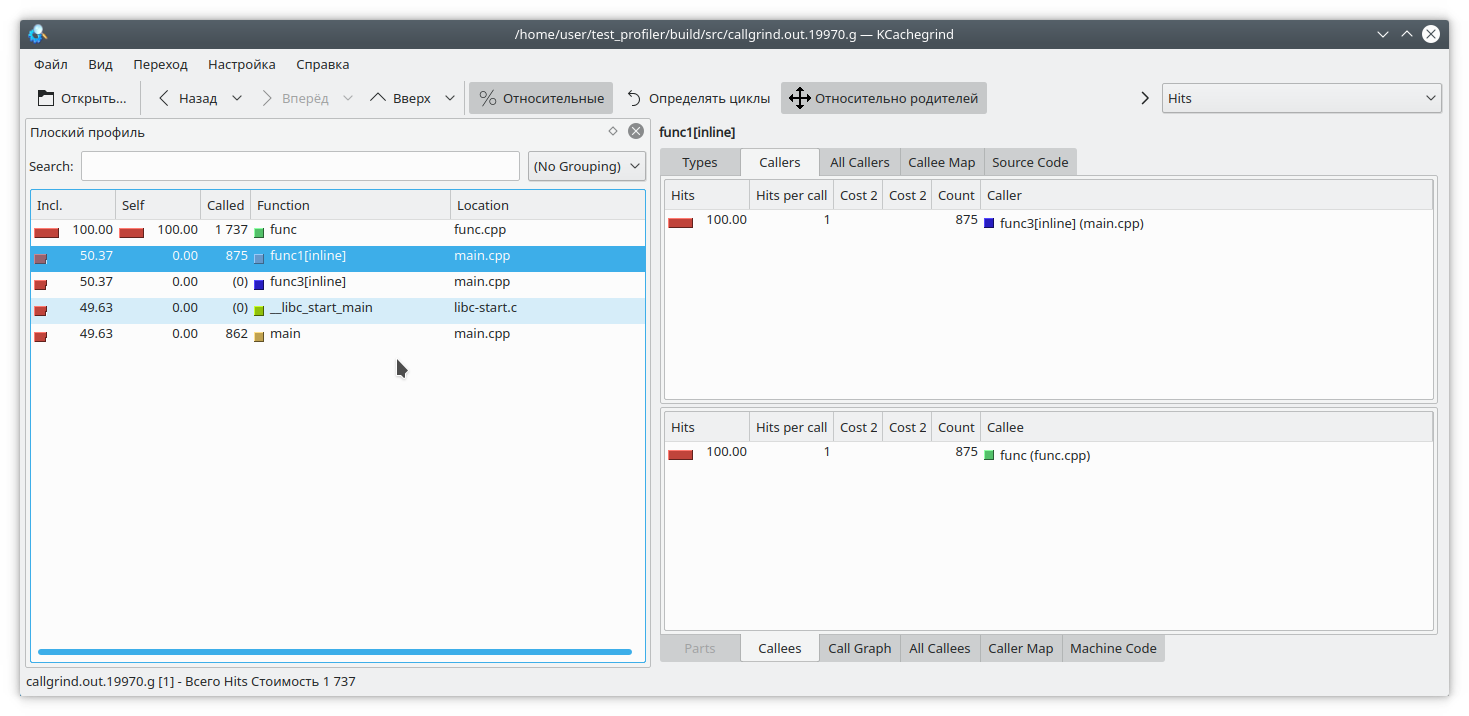
(A propósito, a valgrind aqui decidiu ficar em silêncio modestamente e não especificar de qual função específica a chamada veio).
Perfil de memória
Muitas vezes, há situações em que a memória do aplicativo em algum lugar "flui". Se isso ocorrer devido à falta de limpeza de recursos, o Memcheck deve ajudar a identificar o problema. Mas no C ++ moderno não é tão difícil fazer isso sem o gerenciamento manual de recursos. unique_ptr, shared_ptr, vetor, mapa tornam inútil a manipulação de pontos nus.
No entanto, nessas aplicações, a memória está vazando. Como está indo isso? Muito simplesmente, como regra, é algo como "colocar o valor em um mapa de longa duração, mas esqueceu de excluí-lo". Vamos tentar rastrear essa situação.
Para fazer isso, reescrevemos nossa função de teste dessa maneira
#include "func.h" #include <deque> #include <string> #include <map> static std::deque<std::string> deque; static std::map<int, std::string> map; int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; deque.emplace_back(std::to_string(res) + " integer"); map[i] = "integer " + std::to_string(res); deque.pop_front(); if (res % 200 != 0) { map.erase(i - 1); } } return fst; }
Aqui, a cada iteração, adicionamos alguns elementos ao mapa e, por acidente (verdadeiro, verdadeiro), esquecemos de removê-los às vezes. Além disso, para desviar nossos olhos, torturamos um pouco o std :: deque.
Capturaremos vazamentos de memória com duas ferramentas -
valgrind massif e
google heapdump .
Maciço
Execute o programa com este comando
valgrind --tool=massif ./test_profiler 1000000
E vemos algo como
Maciço time=1277949333 mem_heap_B=313518 mem_heap_extra_B=58266 mem_stacks_B=0 heap_tree=detailed n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 195696 0x109A69: func(int) (new_allocator.h:111) n0: 195696 0x10947A: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 42966 0x10A7EC: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (new_allocator.h:111) n1: 42966 0x10AAD9: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 42966 0x1099D4: func(int) (basic_string.h:1932) n0: 42966 0x10947A: main (main.cpp:18) n0: 0 in 2 places, all below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Pode-se ver que o maciço foi capaz de detectar um vazamento na função, mas ainda não está claro onde. Vamos reconstruir o programa com o
sinalizador -fno-inline e executar a análise novamente
maciço time=3160199549 mem_heap_B=345142 mem_heap_extra_B=65986 mem_stacks_B=0 heap_tree=detailed n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 221616 0x10CDBC: std::_Rb_tree_node<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >* std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_create_node<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .isra.81] (stl_tree.h:653) n1: 221616 0x10CE0C: std::_Rb_tree_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_emplace_hint_unique<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::_Rb_tree_const_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .constprop.87] (stl_tree.h:2414) n1: 221616 0x10CF2B: std::map<int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::operator[](int const&) (stl_map.h:499) n1: 221616 0x10A7F5: func(int) (func.cpp:20) n0: 221616 0x109F8E: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 48670 0x10B866: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317) n1: 48639 0x10BB2C: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 48639 0x10A643: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > std::operator+<char, std::char_traits<char>, std::allocator<char> >(char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [clone .constprop.86] (basic_string.h:6018) n1: 48639 0x10A7E5: func(int) (func.cpp:20) n0: 48639 0x109F8E: main (main.cpp:18) n0: 31 in 1 place, below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Agora está claro onde está o vazamento ao adicionar o elemento do mapa. O maciço pode detectar objetos de vida curta, portanto, as manipulações com std :: deque são invisíveis nesse despejo.
Heapdump
Para que o google heapdump funcione, é necessário vincular ou pré-carregar a biblioteca
tcmalloc . Esta biblioteca substitui as funções padrão de alocação de memória malloc, free, ... Além disso, pode coletar informações sobre o uso dessas funções, que usaremos ao analisar o programa.
Como esse método funciona muito lentamente (mesmo em comparação com o maciço), recomendo que você desative imediatamente a compilação de funções com a opção
-fno-inline ao compilar. Então, reconstruímos nosso aplicativo e executamos com a equipe
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
Aqui supõe-se que a biblioteca tcmalloc esteja vinculada ao nosso aplicativo.
Agora, esperamos algum tempo necessário para a formação de um vazamento perceptível e enviamos um sinal ao nosso processo 23
kill -23 <pid>
Como resultado, um arquivo chamado heap.0001.heap aparece, que convertemos para o formato callgrind com o comando
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
Preste atenção também às opções do pprof. Você pode escolher entre as opções
inuse_space ,
inuse_objects ,
assign_space ,
assign_objects , que mostram o espaço ou objetos que estão em uso, ou o espaço e os objetos alocados por toda a duração do programa, respectivamente. Estamos interessados na opção inuse_space, que mostra o espaço de memória usado atualmente.
Abra nosso kCacheGrind favorito e veja
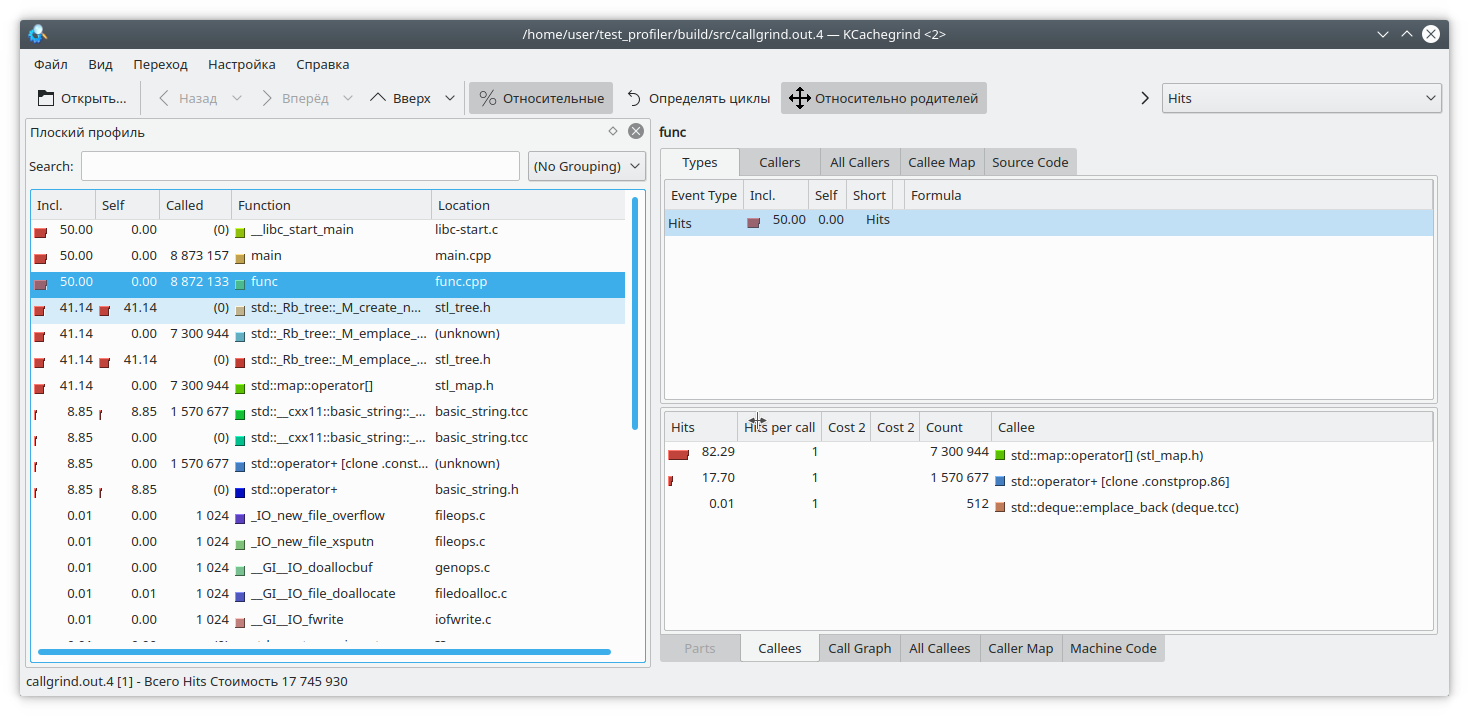
O std :: map consumiu muita memória. Provavelmente um vazamento nele.
Conclusões
A criação de perfil em C ++ é uma tarefa muito difícil. Aqui temos que lidar com funções embutidas, instruções não suportadas, resultados incorretos etc. Nem sempre é possível confiar nos resultados do criador de perfil.
Além das funções propostas acima, existem outras ferramentas projetadas para criação de perfil - perf, intel VTune e outras. Mas eles também mostram algumas dessas deficiências. Portanto, não se esqueça do método de criação de perfil "avô" medindo o tempo de execução das funções e exibindo-o no log.
Além disso, se você tiver técnicas interessantes para criar um perfil do seu código, poste-as nos comentários