
Antes de você novamente, a tarefa de detectar objetos. Prioridade - velocidade com precisão aceitável. Você pega a arquitetura do YOLOv3 e a treina. A precisão (mAp75) é maior que 0,95. Mas a velocidade de execução ainda é baixa. Inferno
Hoje vamos ignorar a quantização. E, por baixo do corte, considere a poda de modelos - aparar peças de rede redundantes para acelerar a inferência sem perder a precisão. Visualmente - onde, quanto e como cortar. Vamos descobrir como fazer isso manualmente e onde você pode automatizar. No final, há um repositório no keras.
1. Introdução
No último local de trabalho, Perm Macroscop, eu tenho um hábito - sempre monitorar o tempo de execução dos algoritmos. E o tempo de execução da rede sempre deve ser verificado através do filtro de adequação. Normalmente, o estado da arte no produto não passa nesse filtro, o que me levou à poda.
A poda é um tema antigo sobre o qual falamos nas palestras de 2017 em Stanford . A idéia principal é reduzir o tamanho da rede treinada sem perder a precisão, removendo vários nós. Parece legal, mas eu raramente ouço sobre o seu uso. Provavelmente, não há implementações suficientes, não há artigos em russo ou apenas todos consideram o poda e o silêncio.
Mas vá desmontar
Um olhar sobre a biologia
Adoro quando, nas idéias do Deep Learning, vêm da biologia. Eles, como a evolução, podem ser confiáveis (você sabia que a ReLU é muito semelhante à função de ativar neurônios no cérebro ?)
O processo de poda do modelo também está próximo da biologia. A resposta da rede aqui pode ser comparada com a plasticidade do cérebro. Alguns exemplos interessantes estão no livro de Norman Dodge :
- O cérebro de uma mulher que tinha apenas metade do nascimento reprogramava-se para desempenhar as funções da metade desaparecida
- O cara se matou na parte do cérebro responsável pela visão. Com o tempo, outras partes do cérebro assumiram essas funções. (não tente novamente)
Portanto, no seu modelo, você pode cortar alguns dos pacotes fracos. Em casos extremos, os pacotes restantes ajudarão a substituir os pacotes cortados.
Você gosta de Transfer Learning ou aprende do zero?
Opção número um. Você está usando o Transfer Learning no Yolov3. Retina, Mask-RCNN ou U-Net. Mas, na maioria das vezes, não precisamos reconhecer 80 classes de objetos, como no COCO. Na minha prática, tudo é limitado a 1-2 aulas. Pode-se supor que a arquitetura para 80 classes seja redundante aqui. Implora o pensamento de que a arquitetura precisa ser reduzida. Além disso, eu gostaria de fazer isso sem perder os pesos pré-treinados existentes.
Opção número dois. Talvez você tenha muitos dados e recursos de computação ou apenas precise de uma arquitetura super personalizada. Isso não importa. Mas você aprende a rede do zero. A ordem usual é olhar para a estrutura de dados, selecionar uma arquitetura que seja REDUZIDA em termos de energia e impedir que os desistentes sejam treinados novamente. Vi desistências 0,6, Carl.
Nos dois casos, a rede pode ser reduzida. Promovido. Agora vamos descobrir que tipo de circuncisão poda
Algoritmo geral
Decidimos que poderíamos remover a convolução. Parece muito simples:
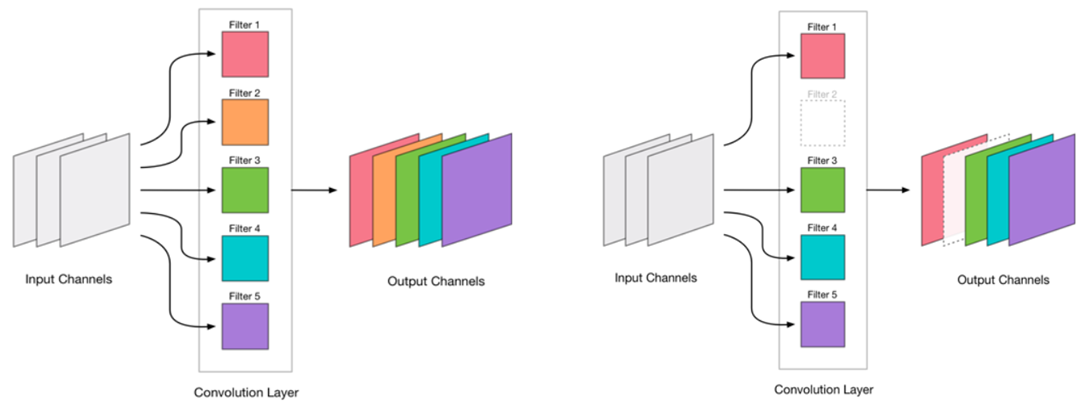
A remoção de qualquer convolução é um estresse para a rede, o que geralmente leva a um aumento no erro. Por um lado, esse crescimento de erro é um indicador de como removemos corretamente a convolução (por exemplo, um grande crescimento indica que estamos fazendo algo errado). Mas um pequeno crescimento é bastante aceitável e é frequentemente eliminado por um treinamento posterior fácil e subsequente com uma pequena RL. Adicionamos uma etapa de reciclagem:
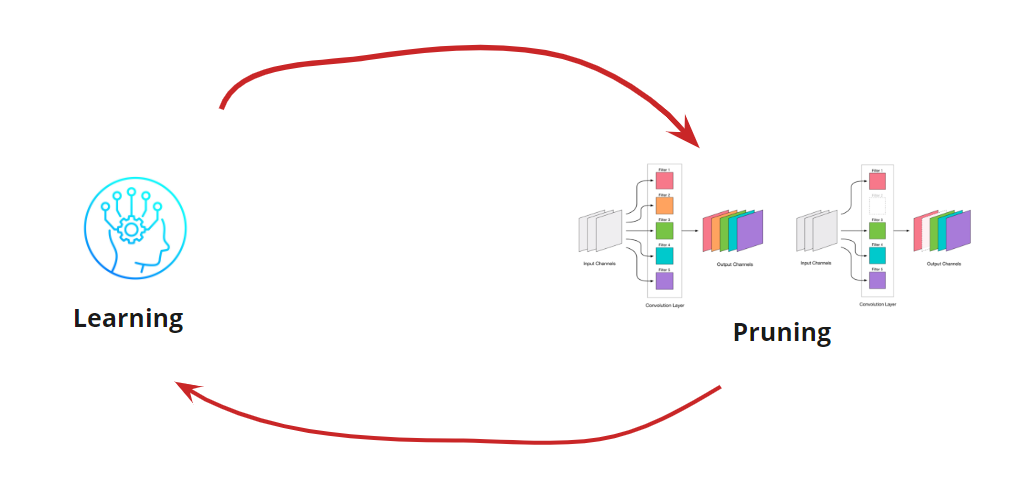
Agora precisamos entender quando queremos interromper nosso ciclo de aprendizagem <-> Poda. Pode haver opções exóticas quando precisamos reduzir a rede para um determinado tamanho e velocidade de execução (por exemplo, para dispositivos móveis). No entanto, a opção mais comum é continuar o ciclo até que o erro se torne mais alto do que o permitido. Adicionar condição:
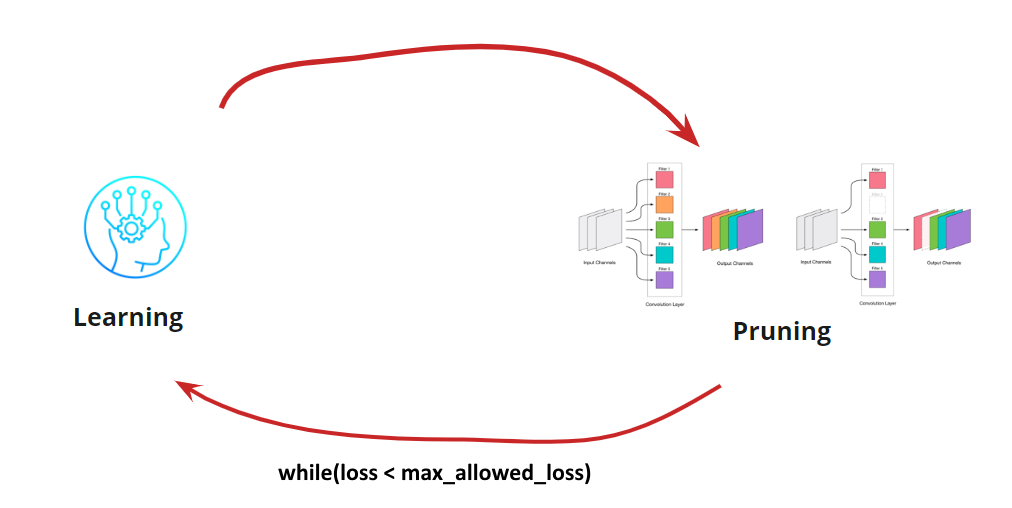
Então, o algoritmo fica claro. Resta desmontar como determinar as convoluções excluídas.
Pesquisa por convolução a ser excluída
Precisamos remover algumas convoluções. Ir adiante e "disparar" qualquer uma é uma má idéia, embora funcione. Mas se você tem cabeça, pode pensar e tentar selecionar convoluções "fracas" para remoção. Existem várias opções:
- A menor medida L1 ou poda_de_magnitude_ baixa . A ideia de que convoluções com pesos pequenos contribuem pouco para a decisão final
- A menor medida L1, levando em consideração a média e o desvio padrão. Complementamos a avaliação da natureza da distribuição.
- Mascarar as convoluções e eliminar o mínimo que afeta a precisão resultante . Uma definição mais precisa de convulsões insignificantes, mas que consomem muito tempo e consomem muitos recursos.
- Outros
Cada uma das opções tem direito à vida e seus próprios recursos de implementação. Aqui consideramos a variante com a menor medida L1
Processo manual para YOLOv3
A arquitetura original contém blocos residuais. Mas, por mais legais que sejam em redes profundas, eles nos atrapalham um pouco. A dificuldade é que você não pode excluir reconciliações com diferentes índices nessas camadas:

Portanto, selecionamos as camadas das quais podemos remover livremente reconciliações:
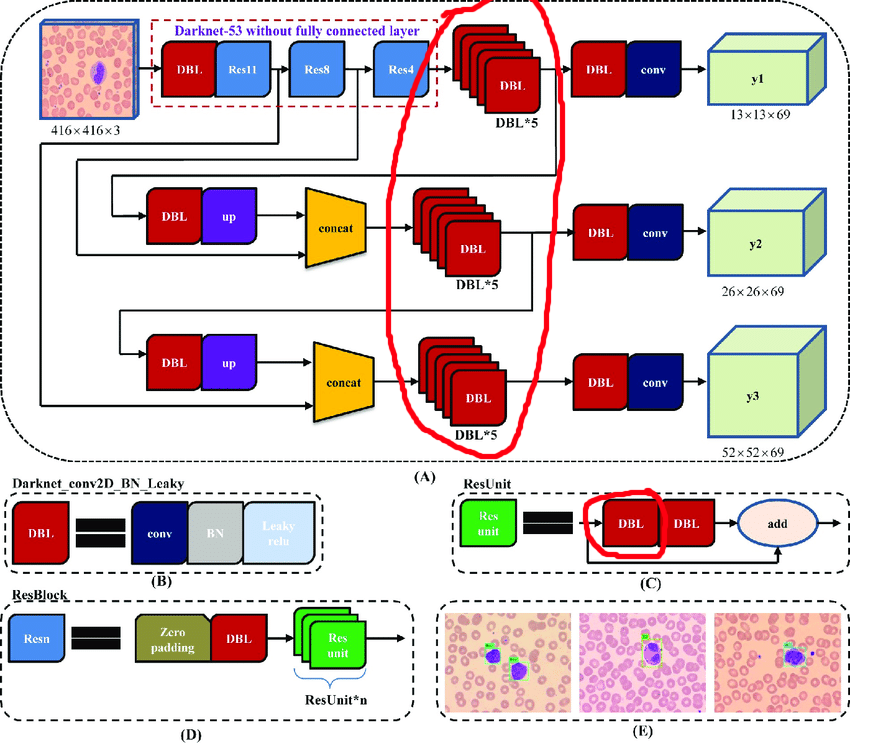
Agora vamos construir um ciclo de trabalho:
- Descarregar a ativação
- Queremos saber quanto cortar
- Cortar
- Aprenda 10 eras com LR = 1e-4
- Teste
A descarga de convoluções é útil para avaliar qual parte podemos remover em uma determinada etapa. Exemplos de descarregamento:

Vemos que em quase todos os lugares 5% das convoluções têm uma norma L1 muito baixa e podemos removê-las. Em cada etapa, esse descarregamento era repetido e uma avaliação era feita de quais camadas e quanto poderia ser cortado.
Todo o processo foi concluído em 4 etapas (aqui e em toda parte os números do RTX 2060 Super):
Na etapa 2, um efeito positivo foi adicionado - o tamanho do patch 4 entrou na memória, o que acelerou bastante o processo de reciclagem.
Na etapa 4, o processo foi interrompido porque mesmo o ensino superior prolongado não elevou o mAp75 a valores antigos.
Como resultado, conseguimos acelerar a inferência em 15% , reduzir o tamanho em 35% e não perder a precisão.
Automação para arquiteturas mais simples
Para arquiteturas de rede mais simples (sem adição condicional, blocos concatenados e residuais), é bem possível se concentrar no processamento de todas as camadas convolucionais e automatizar o processo de corte de convoluções.
Eu implementei essa opção aqui .
É simples: você só tem uma função de perda, um otimizador e geradores de lote:
import pruning from keras.optimizers import Adam from keras.utils import Sequence train_batch_generator = BatchGenerator... score_batch_generator = BatchGenerator... opt = Adam(lr=1e-4) pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt) pruner.prune(train_batch, valid_batch)
Se necessário, você pode alterar os parâmetros de configuração:
{ "input_model_path": "model.h5", "output_model_path": "model_pruned.h5", "finetuning_epochs": 10, # the number of epochs for train between pruning steps "stop_loss": 0.1, # loss for stopping process "pruning_percent_step": 0.05, # part of convs for delete on every pruning step "pruning_standart_deviation_part": 0.2 # shift for limit pruning part }
Além disso, uma restrição baseada no desvio padrão é implementada. O objetivo é limitar uma parte dos excluídos, excluindo convoluções com medidas L1 já "suficientes":
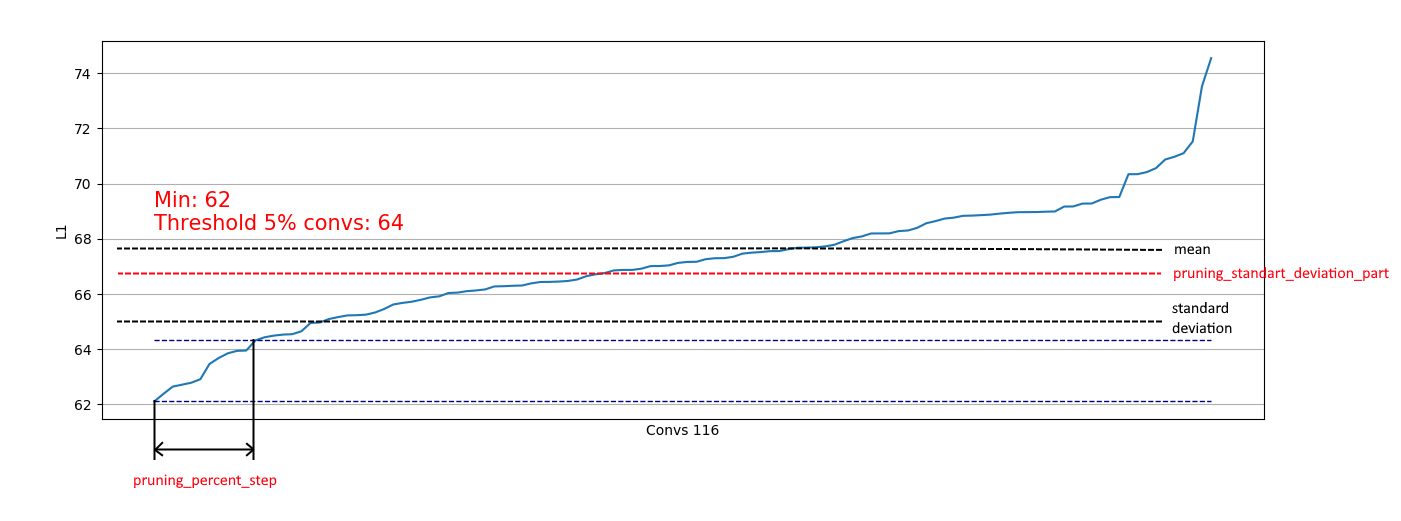
Assim, podemos remover apenas convoluções fracas de distribuições semelhantes à direita e não afetar a remoção de distribuições como a esquerda:

Quando a distribuição se aproxima do normal, o coeficiente pruning_standart_deviation_part pode ser selecionado em:

Eu recomendo uma suposição de 2 sigma. Ou você não pode se concentrar nesse recurso, deixando o valor <1.0.
A saída é um gráfico do tamanho da rede, perda e tempo de execução da rede para todo o teste, normalizado para 1,0. Por exemplo, aqui o tamanho da rede foi reduzido quase duas vezes sem perda de qualidade (uma pequena rede de convolução para pesos de 100k):
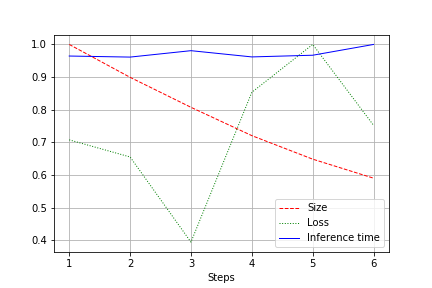
A velocidade de operação está sujeita a flutuações normais e não mudou muito. Há uma explicação para isso:
- O número de convoluções muda de conveniente (32, 64, 128) para não o mais conveniente para placas de vídeo - 27, 51 etc. Aqui posso estar enganado, mas provavelmente isso afeta.
- A arquitetura não é ampla, mas consistente. Reduzindo a largura, não tocamos na profundidade. Assim, reduzimos a carga, mas não alteramos a velocidade.
Portanto, a melhoria foi expressa em uma redução na carga de CUDA durante a execução em 20 a 30%, mas não em uma diminuição no tempo de execução
Sumário
Reflita. Consideramos duas opções de remoção - para o YOLOv3 (quando você precisa trabalhar com as mãos) e para redes com arquiteturas mais fáceis. Pode-se observar que em ambos os casos é possível obter uma redução no tamanho e na aceleração da rede sem perda de precisão. Resultados:
- Downsizing
- Executar aceleração
- Redução de carga CUDA
- Como resultado, respeito pelo meio ambiente (otimizamos o uso futuro dos recursos de computação. Em algum lugar, Greta Tunberg se alegra sozinho)
Apêndice
- Após a etapa de remoção, você também pode torcer a quantização (por exemplo, com TensorRT)
- O Tensorflow fornece recursos para poda de baixa magnitude . Isso funciona.
- Quero desenvolver o repositório e terei prazer em ajudar