Normalmente, na véspera do ano novo, atualizamos nosso conjunto de dados na semântica aberta. Muito trabalho foi realizado este ano, mas ainda não chegou à sua conclusão lógica e continuaremos no próximo ano. Agora queremos falar sobre um conjunto de dados aberto não menos importante que despertou grande interesse em várias conferências linguísticas este ano, tanto por parte de pesquisadores quanto de representantes da indústria. Este post se concentrará no dicionário de tons aberto do idioma russo.

Porque
A tonalidade, ou em palavras simples, bom / ruim, é uma característica natural das palavras. Natural para humanos e suas percepções, mas não para compreensão por computador. A linguagem é organizada de forma a conter simetria em relação à polaridade das palavras e não é possível separar boas palavras de más sem recorrer a marcações externas. Na verdade, inicialmente a tarefa de criar um dicionário tonal surgiu da necessidade de agrupar listas de palavras recebidas automaticamente pelo algoritmo de acordo com sua polaridade.
Obviamente, a tonalidade é apenas um aspecto do significado de uma palavra, e uma compreensão real do sentimento requer uma análise semântica completa, uma compreensão dos papéis em uma situação específica e conhecimento da posição ocupada pelo observador. Assim, por exemplo, "redução no preço das ações" para diferentes partes pode ter tonalidade diferente, e "custos aumentaram" e "lucros cresceram" têm polaridade diferente, embora o verbo crescer seja usado nas duas frases, que possui uma classificação bastante positiva (de acordo com nosso conjunto de dados).
Há uma gama bastante ampla de razões pelas quais atribuímos uma palavra específica a uma chave específica. Às vezes, essas são nossas sensações imediatas - alegria e desejo; às vezes, são as qualidades de uma pessoa - profissionalismo e descuido; e outras, conceitos como educação ou empreendedorismo, associados a instituições sociais complexas e que proporcionam benefícios a longo prazo. E a avaliação de tais palavras está fortemente relacionada à cultura e ao contrato social. E, consequentemente, pode não ter uma avaliação universalmente reconhecida e universal.
No entanto, a linguagem e a comunicação não poderiam existir se os sistemas de coordenadas de pessoas diferentes dentro da mesma cultura não tivessem nada em comum. E, portanto, para grupos de palavras razoavelmente grandes, seu componente estimado é mais ou menos consistente.
Como
Existem duas maneiras principais de coletar uma grande quantidade de dados linguísticos - atraindo especialistas e entrevistando pessoas (ou uma versão mais moderna dos últimos - crowdsourcing). Não repetiremos sobre as diferenças óbvias entre essas abordagens, mas prestar atenção naquelas que têm um impacto direto nas propriedades do conjunto de dados resultante.
A marcação de especialistas implica uma orientação clara para uso futuro e, portanto, estipula um método de tomada de decisão em uma situação de ambiguidade ditada por este aplicativo. Para um conjunto de dados final, isso significa:
- fixação da área temática;
- definição clara da posição do observador.
Portanto, se um especialista compila um dicionário tonal para analisar notícias direcionadas a um público de massa, ele ocupa a posição de um leitor generalizado e aceita acordos tácitos entre a mídia e os leitores. Digamos que a “redução de custos” nessas instalações terá uma avaliação positiva e o “crescimento da tarifa” - negativo (de acordo com o conjunto de dados RusCentiLex-2017).
O crowdsourcing é privado da possibilidade de definir essa estrutura e dificilmente é a ferramenta ideal para resolver problemas aplicados altamente especializados. Mas permite capturar outro aspecto importante da avaliação da tonalidade - a consistência entre os entrevistados. Algumas palavras serão avaliadas inequivocamente como positivas ou negativas; alguns dividirão a avaliação entre as opções neutra e polar; e um pequeno grupo de palavras mostrará uma inconsistência pronunciada das classificações.
Distribuição da consistência da notaÀ esquerda no gráfico está a consistência máxima de estimativas, à direita está a inconsistência máxima.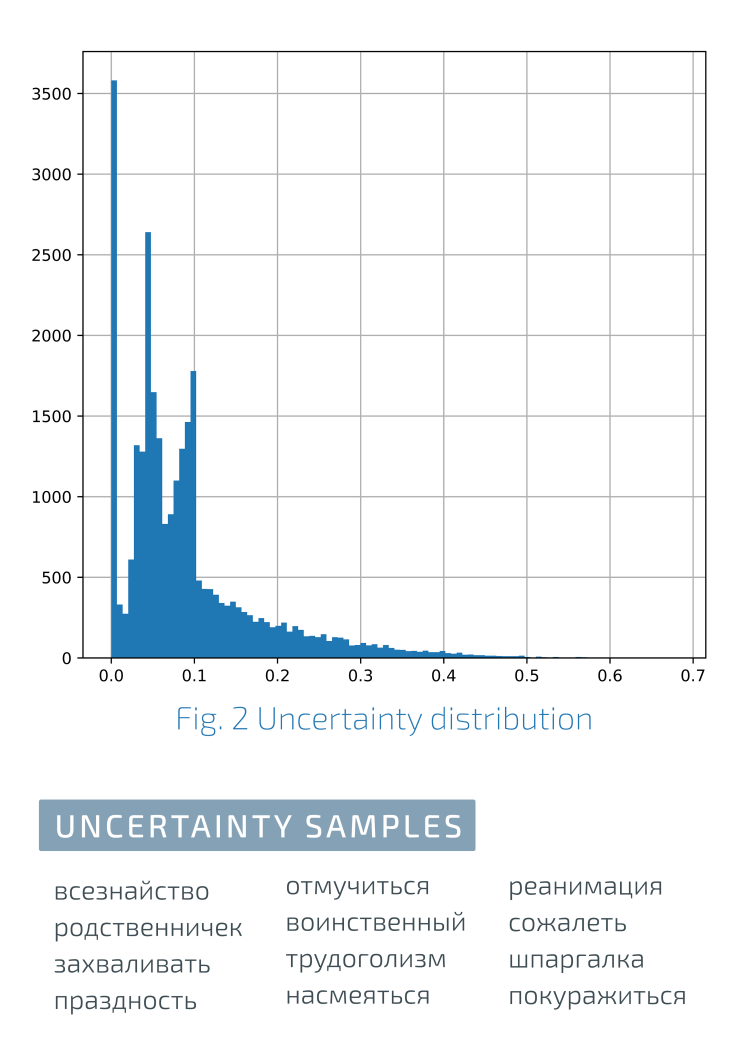
Além disso, diferentemente da avaliação de especialistas, o crowdsourcing permite obter um valor contínuo de polaridade, delimitando palavras estritamente positivas (negativas), bastante positivas (negativas) e neutras. A distribuição entre esses grupos depende, é claro, dos valores limite selecionados. No entanto, a amostragem é totalmente opcional - é possível para várias aplicações que um valor contínuo seja mais conveniente.
Estrutura do conjunto de dados
A estrutura do conjunto de dados é bastante simples: é um dicionário de tons que combina as palavras com suas avaliações no intervalo de -1 (classificação marginal negativa) a +1 (classificação marginal positiva). Por conveniência, é indicada uma etiqueta legível por humanos do conjunto de “positivo”, “neutro”, “negativo” calculado usando valores-limite.
Exemplos de palavras positivas, neutras e negativas do conjunto de dados- positivo: confiável, conciliar, bondade, perdão, consciente, inspirar-se, fotogênico, lucro, boa criação, reunião, inspirar, confiar, entusiasmo, crianças, transformar, bem-estar, boas-vindas, conforto, inteligível, bolsa de estudos, voluntário;
- neutro: abreviatura, conta, vara, túnica, poliedro, toque, móveis, residente, clique, derreter, uso, pisar, estrada, ingrediente, desinflar, enfatizar, emblema, ir para a cama, armas longas, sete, desenhar;
- negativo: trapaceiro, risonho, tagarelice, refém, caipira, arrogante, falso, poluição, invejoso, estrangular, congelar, desperdício, fraudulento, degradante, viciado, morder, pegar um resfriado, encontrar uma falha, ter medo, ladrão, ignorante;
Além disso, nesta versão do conjunto de dados (ainda existe uma primeira versão anterior), são fornecidos dados brutos - a porcentagem de votos expressos para cada uma das opções. Isso permite que você aplique modelos personalizados para calcular a polaridade total e o nível de consistência da marcação.
Nota A versão apresentada do conjunto de dados abrange as palavras mais reconhecíveis de OW (vocabulário ativo); as frases não foram rotuladas. Ao comparar com outros dicionários de tonalidade, encontramos várias palavras disponíveis no vocabulário ativo, mas não representadas em nosso conjunto de dados. Faremos mais marcação e planejamos incluir as unidades de idiomas ausentes no próximo ano.
Planos adicionais
A marcação de sentimentos é uma das tarefas especiais no âmbito do estudo do sistema semântico da linguagem. Como observamos acima, a utilidade do conjunto de dados apresentado depende diretamente da capacidade de associar os valores de polaridade apresentados nele com outras informações semânticas. Com classes de palavras, por exemplo. Iniciamos esse trabalho e planejamos desenvolvê-lo no futuro.
Outra área importante de pesquisa é o desejo de entender o motivo da coloração de certas palavras, criando palavras relacionadas a sentimentos, emoções e avaliação direta e aquelas em que o conceito ou a situação descrita por eles promete atraso ou lucro. Portanto, essas palavras são mais suscetíveis a influências culturais e sociais.
Também está planejado expandir a marcação com frases, incluindo expressões estáveis e unidades fraseológicas. Mas aqui já estamos falando de volumes de vocabulário completamente diferentes, então a tarefa geral é entender como o sentimento funciona em um nível mais geral (mais sob o spoiler).
Sentimento e semânticaApós um exame mais detalhado, fica claro que a linguagem opera com um conjunto compacto de conceitos em relação ao número de palavras e suas combinações, cada uma das quais pode ser expressa de mais de uma maneira. Essa observação foi refletida em detalhes nos trabalhos de linguistas russos e no modelo de sentido-texto que eles criaram.
Assim, por exemplo, “redução de preço”, “queda de preço”, “preços em colapso”, “preços em queda” - essas são maneiras diferentes de descrever um processo semelhante, mas expressas por vários idiomas. Ao mesmo tempo, em contextos semelhantes, pode-se encontrar outros conceitos com expressão quantitativa - “queda no nível de confiança”, “aumento no nível de renda” etc. Em cada caso, basta entender a correspondência acima / abaixo - boa / ruim (nível de conhecimento e mundo) e por que significado lexical se expressa o movimento em uma determinada direção (nível de linguagem).
Feedback e distribuição
Agradecemos qualquer feedback nos comentários - desde críticas ao trabalho e nossas abordagens a links para estudos interessantes e artigos relacionados.
Se você tiver conhecidos ou colegas que possam estar interessados no conjunto de dados publicado, envie um link para o artigo ou repositório para ajudar a disseminar dados abertos.
Link para conjunto de dados e licença
Conjunto de dados: dicionário tonal aberto do idioma russoO
conjunto de dados tem
28197 palavras .
O conjunto de dados é licenciado sob
CC BY-NC-SA 4.0 .
Links para projetos relacionados