As redes neurais cresceram de um estado de curiosidade acadêmica para uma indústria massiva

Na última década, os computadores melhoraram significativamente sua capacidade de entender o mundo ao seu redor. O software para equipamento fotográfico reconhece automaticamente o rosto das pessoas. Os smartphones convertem a fala em texto. Os robomobiles reconhecem objetos na estrada e evitam colisões com eles.
No centro de todas essas descobertas está a tecnologia da inteligência artificial (IA) chamada aprendizado profundo (GO). GO é baseado em redes neurais (NS), estruturas de dados inspiradas em redes compostas por neurônios biológicos. Os NS são organizados em camadas e as entradas de uma camada são conectadas às saídas da vizinha.
Os cientistas da computação vêm experimentando o NS desde os anos 50. No entanto, a base da vasta indústria de GO de hoje foi lançada por dois grandes avanços - um ocorrido em 1986 e o segundo em 2012. O avanço de 2012 - a revolução do GO - foi associado à descoberta de que o uso de NS com um grande número de camadas nos permitirá melhorar significativamente sua eficiência. A descoberta foi facilitada pelos volumes crescentes de dados e poder de computação.
Neste artigo, apresentaremos você ao mundo da Assembléia Nacional. Explicaremos o que é o NS, como eles funcionam e de onde vieram. E estudaremos por que - apesar de muitas décadas de pesquisas anteriores - os SNs se tornaram algo realmente útil apenas em 2012.
As redes neurais apareceram nos anos 50
 Frank Rosenblatt está trabalhando em seu perceptron - um modelo inicial de NS
Frank Rosenblatt está trabalhando em seu perceptron - um modelo inicial de NSA idéia da Assembléia Nacional é bastante antiga - pelo menos para os padrões da ciência da computação. Em 1957,
Frank Rosenblatt, da Cornell University, publicou um
relatório descrevendo um conceito inicial de NS chamado perceptron. Em 1958, com o apoio da Marinha dos EUA, ele criou um sistema primitivo capaz de analisar 20x20 pixels e reconhecer formas geométricas simples.
O principal objetivo de Rosenblatt não era criar um sistema prático de classificação de imagens. Ele tentou entender como o cérebro humano funciona, criando sistemas de computador organizados à sua imagem. No entanto, esse conceito gerou entusiasmo excessivo de terceiros.
"Hoje, a Marinha dos EUA revelou ao mundo o germe de um computador eletrônico, que deve andar, conversar, ver, escrever, se reproduzir e estar ciente de sua existência", escreveu o New York Times.
De fato, cada neurônio no NS é apenas uma função matemática. Cada neurônio calcula a soma ponderada dos dados de entrada - quanto maior o peso de entrada, mais fortemente esses dados de entrada afetam a saída do neurônio. Em seguida, a soma ponderada é alimentada com a função de "ativação" não linear - nesta etapa, os NSs podem simular fenômenos não lineares complexos.
As habilidades dos perceptrons iniciais com os quais Rosenblatt experimentou - e NS em geral - decorrem de sua capacidade de "aprender" com exemplos. Os NS são treinados ajustando os pesos de entrada dos neurônios com base nos resultados da rede com os dados de entrada selecionados, por exemplo. Se a rede classificar corretamente a imagem, os pesos que contribuem para a resposta correta aumentam, enquanto outros diminuem. Se a rede estiver errada, os pesos serão ajustados na outra direção.
Tal procedimento permitiu que os primeiros SNs “aprendessem” de uma maneira que lembra o comportamento do sistema nervoso humano. O hype em torno dessa abordagem não parou na década de 1960. Contudo, o
influente livro de 1969 dos autores dos cientistas da computação Marvin Minsky e Seymour Papert mostrou que esses NA iniciais tinham limitações significativas.
Os primeiros Rosenblatt NSs tinham apenas uma ou duas camadas treinadas. Minsky e Papert mostraram que esses NSs são matematicamente incapazes de modelar fenômenos complexos do mundo real.
Em princípio, NSs mais profundos eram mais capazes. No entanto, esse NS sobrecarregaria os miseráveis recursos de computação que os computadores tinham na época. Os algoritmos de
pesquisa ascendente mais simples usados nos primeiros NSs não foram dimensionados para NSs mais profundos.
Como resultado, a Assembléia Nacional perdeu todo o apoio na década de 1970 e no início da década de 1980 - fazia parte da era do "inverno da IA".
Algoritmo inovador
 Minha própria rede neural baseada em "equipamentos leves" acredita que a probabilidade de ter um cachorro-quente nesta foto é 1. Vamos ficar ricos!
Minha própria rede neural baseada em "equipamentos leves" acredita que a probabilidade de ter um cachorro-quente nesta foto é 1. Vamos ficar ricos!A sorte voltou-se novamente para o NS graças ao famoso
trabalho de 1986, que introduziu o conceito de propagação traseira - um método prático de ensino do NS.
Suponha que você trabalhe como programador em uma empresa de software imaginária e tenha sido instruído a criar um aplicativo que determine se há um cachorro-quente na imagem. Você começa a trabalhar com um NS inicializado aleatoriamente, que obtém uma imagem de entrada e gera um valor de 0 a 1 - onde 1 significa "cachorro-quente" e 0 significa "cachorro-quente".
Para treinar a rede, você coleta milhares de imagens, em cada uma das quais há um rótulo indicando se existe um cachorro-quente nessa imagem. Você alimenta a primeira imagem - e há um cachorro-quente - na rede neural. Ele fornece um valor de saída de 0,07, que significa "sem cachorro-quente". Esta é a resposta errada; a rede deve ter retornado uma resposta próxima a 1.
O objetivo do algoritmo de retropropagação é ajustar os pesos de entrada para que a rede produza um valor mais alto se receber novamente essa imagem - e, preferencialmente, outras imagens onde houver cachorro-quente. Para isso, o algoritmo de retropropagação começa examinando os neurônios de entrada da camada de saída. Cada valor possui uma variável de peso. O algoritmo de retropropagação ajusta cada peso em uma direção que o NS fornece um valor mais alto. Quanto maior o valor de entrada, mais seu peso aumenta.
Até agora, estou descrevendo a subida mais simples ao topo, familiar aos pesquisadores nos anos 1960. O avanço da retropropagação foi o próximo passo: o algoritmo usa derivadas parciais para distribuir a “falha” para a saída incorreta entre as entradas dos neurônios. O algoritmo calcula como uma pequena alteração em cada valor de entrada afetará a saída final de um neurônio e se essa alteração aproximará o resultado da resposta correta ou vice-versa.
O resultado é um conjunto de valores de erro para cada neurônio na camada anterior - na verdade, um sinal que avalia se o valor de cada neurônio é muito grande ou muito pequeno. Em seguida, o algoritmo repete o processo de sintonia de novos neurônios da segunda camada [do final]. Altera ligeiramente os pesos de entrada de cada neurônio para aproximar a rede da resposta correta.
Em seguida, o algoritmo novamente usa derivadas parciais para calcular como o valor de cada entrada da camada anterior afetou os erros de saída dessa camada - e propaga esses erros de volta à camada pré-anterior, onde o processo se repete novamente.
Este é apenas um modelo simplificado de retropropagação. Se você precisar de detalhes matemáticos detalhados, recomendo o livro de Michael Nielsen sobre esse assunto [
e temos a tradução dela / aprox. transl.]. Para nossos propósitos, basta que a distribuição reversa altere radicalmente a faixa de NS treinada. As pessoas não estavam mais limitadas a redes simples com uma ou duas camadas. Eles poderiam criar redes com cinco, dez ou cinquenta camadas, e essas redes poderiam ter uma estrutura interna arbitrariamente complexa.
A invenção da retropropagação lançou o segundo boom da Assembléia Nacional, que começou a produzir resultados práticos. Em 1998, um grupo de pesquisadores da AT&T mostrou como as redes neurais podem ser usadas para reconhecer números manuscritos, o que tornou possível automatizar o processamento de cheques.
"A principal mensagem deste trabalho é que podemos criar sistemas aprimorados para reconhecer padrões, confiando mais no aprendizado automático e menos nas heurísticas desenvolvidas manualmente", escreveram os autores.
E, no entanto, nessa fase, os NSs eram apenas uma das muitas tecnologias à disposição dos pesquisadores de aprendizado de máquina. Quando estudei em um curso de IA no instituto em 2008, as redes neurais eram apenas um dos nove algoritmos MO, dos quais poderíamos escolher a opção adequada para a tarefa. No entanto, a GO já estava se preparando para ofuscar o restante da tecnologia.
Big data demonstra o poder da aprendizagem profunda
 Relaxamento detectado. Possibilidade de praia 1.0. Iniciamos o procedimento de uso do Mai Tai.
Relaxamento detectado. Possibilidade de praia 1.0. Iniciamos o procedimento de uso do Mai Tai.A retropropagação facilitou o processo de cálculo do NS, mas as redes mais profundas ainda precisavam de mais recursos de computação do que as pequenas. Os resultados de estudos realizados nas décadas de 1990 e 2000 mostraram frequentemente que era possível obter cada vez menos benefícios de complicações adicionais da SN.
Então o pensamento das pessoas foi mudado pelo famoso trabalho de 2012, que descreveu o NS sob o nome AlexNet, em homenagem ao pesquisador Alex Krizhevsky. Muito parecido com redes mais profundas, poderia proporcionar eficiência revolucionária, mas apenas em combinação com uma abundância de energia do computador e uma enorme quantidade de dados.
A AlexNet desenvolveu um trio de cientistas da computação da Universidade de Toronto para participar do concurso de ciências da ImageNet. Os organizadores do concurso coletaram um milhão de imagens na Internet, cada uma delas rotulada e atribuída a uma das milhares de categorias de objetos, por exemplo, “cereja”, “navio porta-contêineres” ou “leopardo”. Foi pedido aos pesquisadores de IA que treinassem seus programas de MO em partes dessas imagens e tentassem colocar os rótulos corretos para outras imagens que o software não havia encontrado antes. O software teve que selecionar cinco rótulos possíveis para cada imagem, e a tentativa foi considerada bem-sucedida se um deles coincidisse com o real.
Essa foi uma tarefa difícil e até 2012 os resultados não foram muito bons. Para o vencedor de 2011, a taxa de erro foi de 25%.
Em 2012, a equipe AlexNet superou todos os concorrentes, dando respostas com 15% de erros. Para o concorrente mais próximo, esse número foi de 26%.
Pesquisadores de Toronto combinaram várias técnicas para alcançar resultados inovadores. Um deles foi o uso de
neuroses convolucionais (SNS). De fato, o SNA, por assim dizer, treina pequenas redes neurais - cujos dados de entrada são quadrados com um lado de 7 a 11 pixels - e depois os "sobrepõe" a uma imagem maior.
"É como se você pegasse um pequeno modelo ou estêncil e tentasse compará-lo com cada ponto da imagem", nos disse no ano passado a pesquisadora de IA Jie Tan. - Você tem um estêncil de cachorro e o anexa à imagem e vê se há um cachorro ali? Caso contrário, mova o estêncil. E assim para toda a imagem. E não importa onde o cachorro apareça na foto. O estêncil irá coincidir com ele. Cada subseção de rede não deve se tornar um classificador de cães separado. ”
Outro fator importante para o sucesso da AlexNet foi o uso de placas gráficas para acelerar o processo de aprendizado. As placas gráficas têm poder de processamento paralelo, adequado para a computação repetitiva necessária para treinar uma rede neural. Transferindo a carga da computação para um par de GPUs - a Nvidia GTX 580, com 3 GB de memória cada -, os pesquisadores foram capazes de desenvolver e treinar uma rede extremamente grande e complexa. AlexNet tinha oito camadas treináveis, 650.000 neurônios e 60 milhões de parâmetros.
Por fim, o sucesso do AlexNet também foi garantido pelo grande tamanho do banco de dados de imagens de treinamento da ImageNet: um milhão de peças. Muitas imagens são necessárias para ajustar 60 milhões de parâmetros. Para alcançar uma vitória decisiva, a AlexNet foi ajudada por uma combinação de uma rede complexa e um grande conjunto de dados.
Eu me pergunto por que esse avanço não ocorreu anteriormente:
- O par de GPU de nível de consumidor usado pelos pesquisadores da AlexNet estava longe de ser o dispositivo de computação mais poderoso para 2012. Cinco e até dez anos antes disso, havia computadores mais poderosos. Além disso, a tecnologia de acelerar o aprendizado do NS usando placas gráficas é conhecida desde pelo menos 2004.
- A base de um milhão de imagens era extraordinariamente grande para o ensino de algoritmos MO em 2012, no entanto, a coleta desses dados não era uma tecnologia nova para aquele ano. Uma equipe de pesquisa bem financiada poderia facilmente montar um banco de dados desse tamanho cinco ou dez anos antes.
- Os principais algoritmos usados no AlexNet não eram novos. O algoritmo de retropropagação até 2012 já existia há cerca de um quarto de século. As principais idéias relacionadas às redes neurais convolucionais foram desenvolvidas nas décadas de 1980 e 1990.
Portanto, cada um dos elementos de sucesso do AlexNet existia separadamente muito antes do avanço. Obviamente, nunca ocorreu a ninguém combiná-los - na maior parte porque ninguém sabia o quão poderosa essa combinação seria.
Aumentar a profundidade do NS praticamente não melhorou a eficiência de seu trabalho se eles não usassem conjuntos de dados de treinamento grandes o suficiente. E expandir o conjunto de dados não melhorou o desempenho de pequenas redes. Para ver o aumento da eficiência, precisávamos de redes mais profundas e de conjuntos de dados maiores - além de um poder computacional significativo que nos permitiu conduzir o processo de treinamento em um período de tempo razoável. A equipe AlexNet foi a primeira a reunir os três elementos em um programa.
O boom da aprendizagem profunda

A demonstração de todo o poder da NS profunda, fornecida por uma quantidade suficiente de dados de treinamento, foi observada por muitas pessoas - tanto entre cientistas, pesquisadores quanto entre representantes da indústria.
O primeiro concurso ImageNet a mudar. Até 2012, a maioria dos participantes usava outras tecnologias além do aprendizado profundo. Na competição de 2013, como escreveram os patrocinadores, "a maioria" dos participantes usou o GO.
A porcentagem de erros entre os vencedores diminuiu gradualmente - de impressionantes 16% na AlexNet em 2012 para 2,3% em 2017:
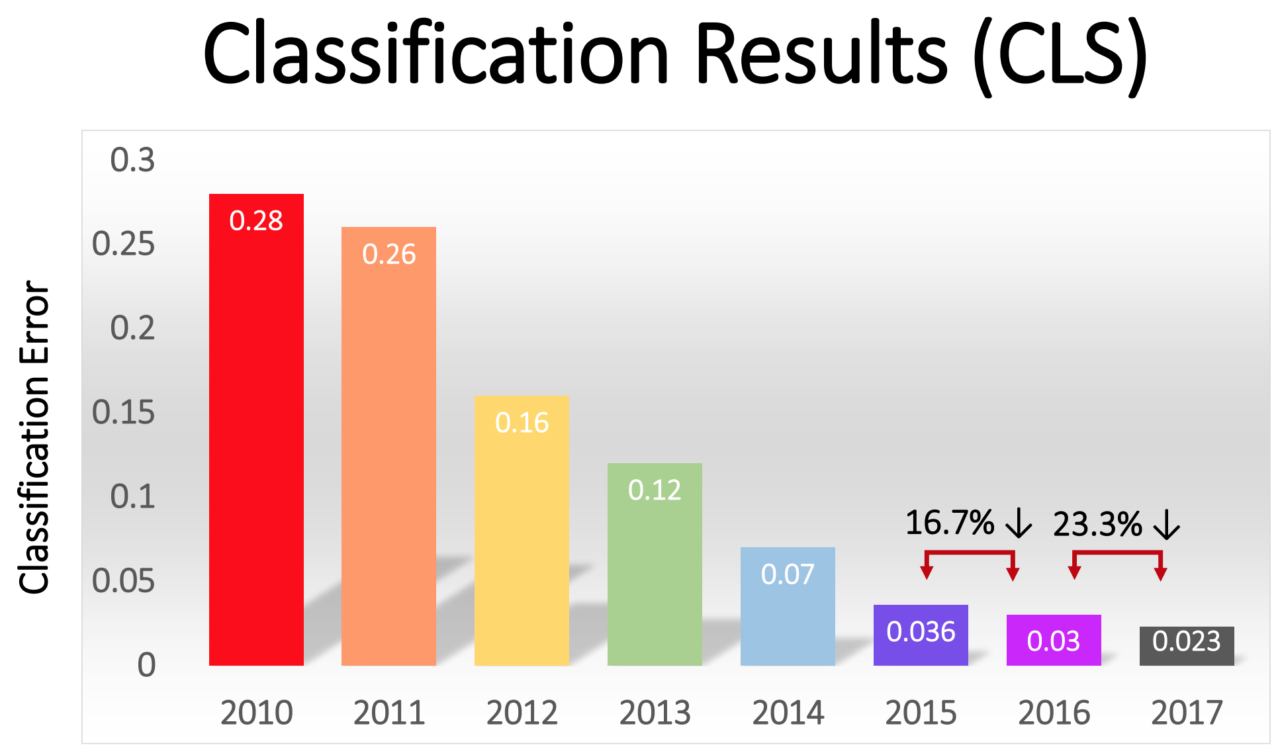
A revolução GO se espalhou rapidamente por todo o setor. Em 2013, o Google adquiriu uma startup formada pelos autores da AlexNet e usou sua tecnologia como base para a função de pesquisa de imagens no Google Fotos. Em 2014, o Facebook divulgava seu próprio software que reconhece imagens usando o GO. A Apple usa o GO para reconhecimento de rosto no iOS desde pelo menos 2016.
O GO também está subjacente à recente melhoria na tecnologia de reconhecimento de voz. Siri da Apple, Alexa da Amazon, Cortana da Microsoft e o assistente do Google usam o GO - para entender as palavras de uma pessoa ou para gerar uma voz mais natural, ou ambas.
Nos últimos anos, surgiu uma tendência auto-sustentável no setor, na qual o aumento no poder da computação, no volume de dados e na profundidade da rede se sustentam. A equipe da AlexNet usou a GPU porque ofereceu computação paralela por um preço razoável. Mas, nos últimos anos, mais e mais empresas começaram a desenvolver seus próprios chips, projetados especificamente para uso no campo da MO.
O Google anunciou o lançamento do chip Tensor Processing Unit projetado especificamente para o NS em 2016. No mesmo ano, a Nvidia anunciou o lançamento de uma nova GPU chamada Tesla P100, otimizada para o NS. A Intel respondeu à chamada com seu chip de IA em 2017. Em 2018, a Amazon anunciou o lançamento de seu próprio chip de AI, que pode ser usado como parte dos serviços em nuvem da empresa. Dizem que até a Microsoft está trabalhando em seu chip de IA.
Os fabricantes de smartphones também estão trabalhando em chips que permitirão que os dispositivos móveis façam mais computação usando o NS localmente, sem precisar enviar dados para os servidores. Essa computação em dispositivos reduz a latência e melhora a privacidade.
Até Tesla entrou neste jogo com fichas especiais. Este ano, a Tesla mostrou um novo computador poderoso, otimizado para o cálculo do NS. A Tesla nomeou-o como Computador Autônomo Completo e o apresentou como um momento-chave na estratégia da empresa de transformar a frota da Tesla em veículos robóticos.
A disponibilidade das capacidades do computador otimizadas para IA gerou uma solicitação dos dados necessários para treinar NSs cada vez mais complexos. Essa dinâmica é mais evidente no setor de automóveis, onde as empresas coletam dados sobre milhões de quilômetros de estradas reais. A Tesla pode coletar esses dados automaticamente dos carros dos usuários e seus concorrentes Waymo e Cruise pagaram aos motoristas que dirigiam seus carros nas vias públicas.

A solicitação de dados oferece uma vantagem para grandes empresas online que já têm acesso a grandes volumes de dados do usuário.
O aprendizado profundo conquistou muitas áreas diferentes devido à sua extrema flexibilidade. Décadas de tentativa e erro permitiram que os pesquisadores desenvolvessem os elementos básicos para as tarefas mais comuns no campo da MO - como redes de convolução para reconhecimento eficiente de imagens. No entanto, se você tiver uma rede de alto nível adequada ao esquema e dados suficientes, o processo de treinamento será simples. Os NSs profundos são capazes de reconhecer uma variedade excepcionalmente ampla de padrões complexos sem a orientação especial de desenvolvedores humanos.
Existem limitações, é claro. Por exemplo, algumas pessoas se entregaram à idéia de treinar robomobiles com a ajuda de apenas GO - ou seja, alimentar imagens recebidas de uma câmera, uma rede neural e receber instruções dela para girar o volante e o pedal. Eu sou cético em relação a essa abordagem.
A Assembléia Nacional ainda não demonstrou a capacidade de conduzir um raciocínio lógico complexo, necessário para entender certas condições que surgem na estrada. Além disso, os NSs são "caixas pretas", cujo fluxo de trabalho é praticamente invisível. Seria difícil avaliar e confirmar a segurança desse sistema.No entanto, o GO permitiu dar saltos muito amplos em uma variedade inesperadamente grande de aplicativos. Nos próximos anos, pode-se esperar o próximo progresso nessa área.