Olá pessoal. Abaixo está uma transcrição do relatório com o Big Monitoring Meetup 4 .
O Prometheus é um sistema de monitoramento para vários sistemas e serviços, com o qual os administradores de sistemas podem coletar informações sobre os parâmetros atuais dos sistemas e configurar alertas para receber notificações de desvios na operação dos sistemas.
O relatório comparará Thanos e VictoriaMetrics , projetos para o armazenamento de longo prazo das métricas do Prometheus.


Primeiro, vou falar sobre Prometeu. Este é um sistema de monitoramento que coleta métricas de determinados destinos e as salva no armazenamento local. O Prometheus pode gravar métricas em um repositório remoto, pode gerar alertas e regras de gravação.

Limitações do Prometheus:
- Não possui uma visualização de consulta global. É quando você tem várias instâncias independentes do prometheus. Eles coletam métricas. E você deseja fazer uma solicitação além de todas essas métricas coletadas de diferentes instâncias do prometheus. Prometeu não permite isso.
- Com o prometheus, o desempenho é limitado a apenas um servidor. O Prometheus não pode ser dimensionado automaticamente para vários servidores. Você só pode dividir manualmente seus destinos entre vários Prometheus.
- O volume de métricas no Prometheus é limitado a apenas um servidor pelo mesmo motivo que não pode ser dimensionado automaticamente para vários servidores.
- No Prometheus, não é tão fácil organizar a segurança dos dados.

Resolvendo esses problemas / desafios?
As soluções são:
Todas essas soluções de armazenamento remoto coletadas pela Prometheus. Eles resolvem o problema do armazenamento remoto do slide anterior de diferentes maneiras. Nesta apresentação, falarei apenas das duas primeiras soluções: Thanos e VictoriaMetrics .
Pela primeira vez, informações sobre Thanos apareceram neste link . Ele descreve a arquitetura de Thanos e como funciona.

Thanos pega os dados que o Prometheus salvou no disco local e os copia para o S3, para o GCS ou para outro armazenamento de objeto.

Dessa forma, o Thanos fornece uma visão de consulta global. Você pode solicitar dados armazenados no armazenamento de objetos de várias instâncias do Prometheus.

Thanos suporta PromQL e a API de consulta do Prometheus .

Thanos usa o código Prometheus para armazenar dados.

Thanos está sendo desenvolvido pelos mesmos desenvolvedores que o Prometheus.
Sobre a VictoriaMetrics . Aqui está o link em que conversamos sobre o VictoriaMetrics .

O VictoriaMetrics recebe dados de vários prometheus por meio do protocolo API de gravação remota suportado pelo Prometheus.
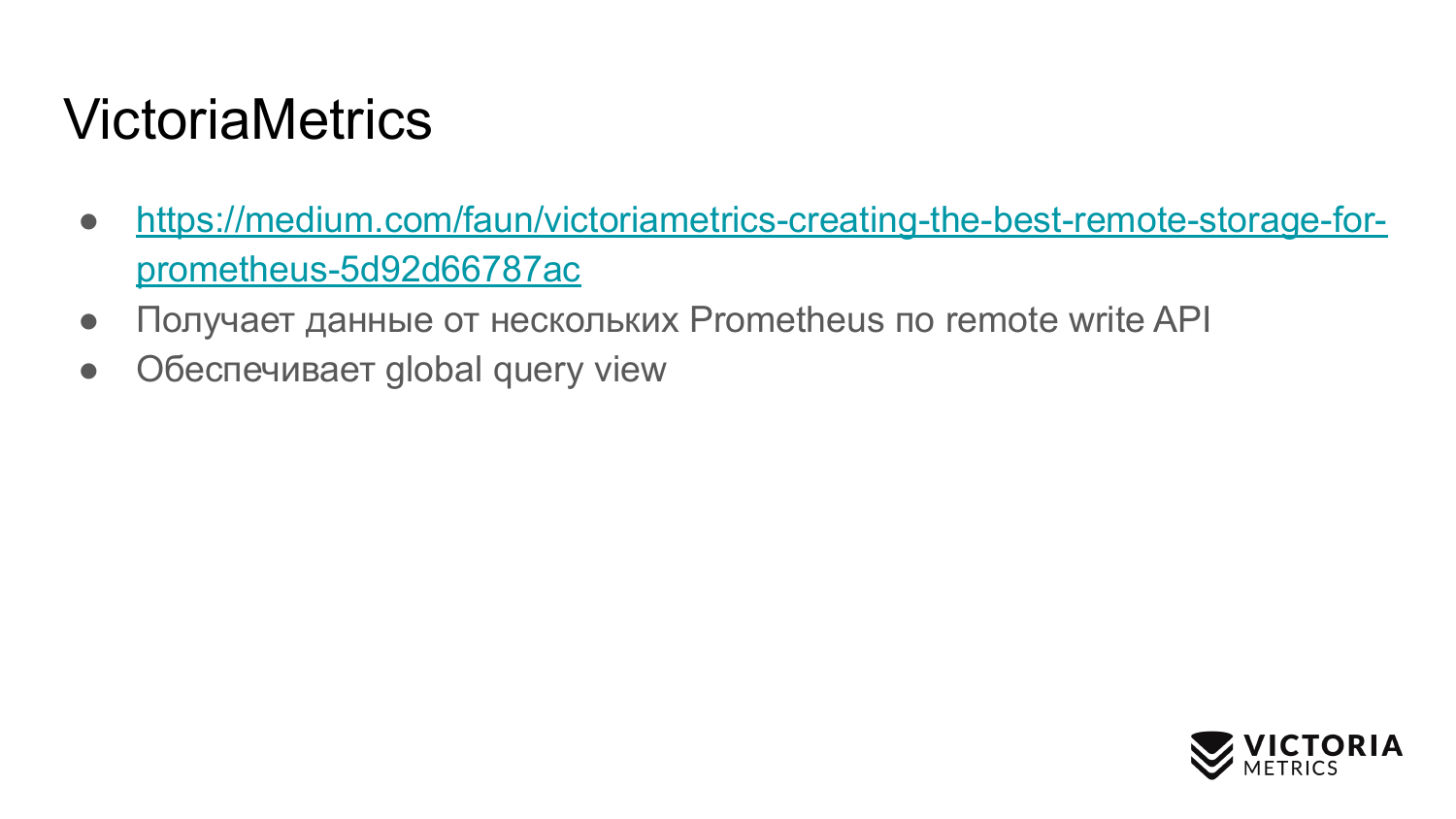
O VictoriaMetrics fornece uma visualização de consulta global, pois várias instâncias do Prometheus podem gravar dados em um VictoriaMetrics. Assim, você pode fazer solicitações para todos esses dados.

O VictoriaMetrics também suporta, como Thanos, PromQL e a API de consulta do Prometheus.

Ao contrário de Thanos, o código fonte do VictoriaMetrics é escrito do zero e otimizado para velocidade e recursos.

O VictoriaMetrics, diferentemente de Thanos, é dimensionado vertical e horizontalmente. Há uma versão de nó único que é dimensionada verticalmente. Você pode começar com um processador e 1 GB de memória e aumentar gradualmente para centenas de processadores e 1 TB de memória. VictoriaMetrics pode usar todos esses recursos. Seu desempenho aumentará cerca de 100 vezes em comparação com um sistema de núcleo único.

A história de Thanos começou em novembro de 2017, quando o primeiro commit público apareceu. Antes disso, o Thanos foi desenvolvido internamente pelo improbable.io .

Em junho de 2019, houve um marco de lançamento 0.5.0, no qual o protocolo de fofocas foi removido . Ele foi removido de Thanos porque não fez o seu melhor. Frequentemente, o cluster Thanos não funcionava corretamente, os nós conectados a ele incorretamente devido ao protocolo de fofocas. Portanto, eles decidiram removê-lo de lá. Eu acho que essa é a decisão certa.

Também em junho de 2019, eles enviaram o aplicativo número 256 à Cloud Native Computing Foundation .

Depois de alguns meses, Thanos ingressou na Cloud Native Computing Foundation , que inclui Prometheus, Kubernetes e outros projetos populares.

Em janeiro de 2018, o desenvolvimento do VictoriaMetrics começou.

Em setembro de 2018, mencionei publicamente o VictoriaMetrics.

Em dezembro de 2018, a versão de nó único foi publicada.

Em maio de 2019 , as fontes da versão do nó único e da cluster foram publicadas .

Em junho de 2019, como Thanos, aplicamos a fundação CNCF no número 255 . Nós aplicamos um dia antes da Thanos.

Infelizmente, ainda não fomos aceitos lá. Precisa de ajuda da comunidade.

Considere os slides mais importantes que mostram a arquitetura de Thanos e VictoriaMetrics.

Vamos começar com Thanos. Componentes amarelos são componentes do Prometheus. Tudo o resto são os componentes Thanos. Vamos começar com o componente mais importante. O Thanos Sidecar é um componente instalado ao lado de cada Prometheus. Ele está comprometido em carregar dados do Prometheus do armazenamento local no S3 ou em outro Object Storage.
Também existe um componente como o Thanos Store Gateway, que pode ler esses dados do Object Storage após solicitações recebidas da Thanos Query. O Thanos Query implementa o PromQL e a API do Prometheus. Ou seja, do lado de fora parece um Prometeu. Ele aceita consultas PromQL, as envia para o Thanos Store Gateway, o Thanos Store Gateway recupera os dados necessários do Object Storage, os envia de volta.
Mas nós armazenamos dados no Object Storage sem as duas últimas horas devido à peculiaridade da implementação do Thanos Sidecar, que não pode carregar as últimas duas horas no Object Storage S3, porque nessas duas horas o Prometheus ainda não criou arquivos no armazenamento local.
Como eles decidiram contornar isso? A Consulta Thanos, além de solicitações do Thanos Store Gateway, envia solicitações paralelas a todos os Thanos Sidecar localizados ao lado de Prometheus.
E o Thanos Sidecar, por sua vez, solicita proxies adicionais no Prometheus e obtém dados pelas últimas duas horas.
Além desses componentes, há também um componente opcional sem o qual Thanos não se sentirá bem. Este é o Thanos Compact, que mescla arquivos pequenos no Armazenamento de Objetos em arquivos maiores que foram carregados aqui pelo Thanos Sidecar. O Thanos Sidecar carrega arquivos de dados lá em duas horas. Esses arquivos, se você não os mesclar em arquivos maiores, o número deles poderá aumentar significativamente. Quanto mais esses arquivos, mais memória é necessária para o Thanos Store Gateway, mais recursos são necessários para transferir dados pela rede, metadados. O Thanos Store Gateway está se tornando ineficiente. Portanto, você deve definitivamente executar o Thanos Compact, que mescla arquivos pequenos em arquivos maiores, para que haja menos arquivos e reduza a sobrecarga no Thanos Store Gateway.
Também existe um componente como o Thanos Ruler. Ele segue as regras de alerta do Prometheus e pode calcular as regras de gravação do Prometheus para gravar dados no Armazenamento de Objetos. Mas este componente não é recomendado, porque ele está inclinado a retornar dados incompletos .
Este é um esquema simples para Thanos.
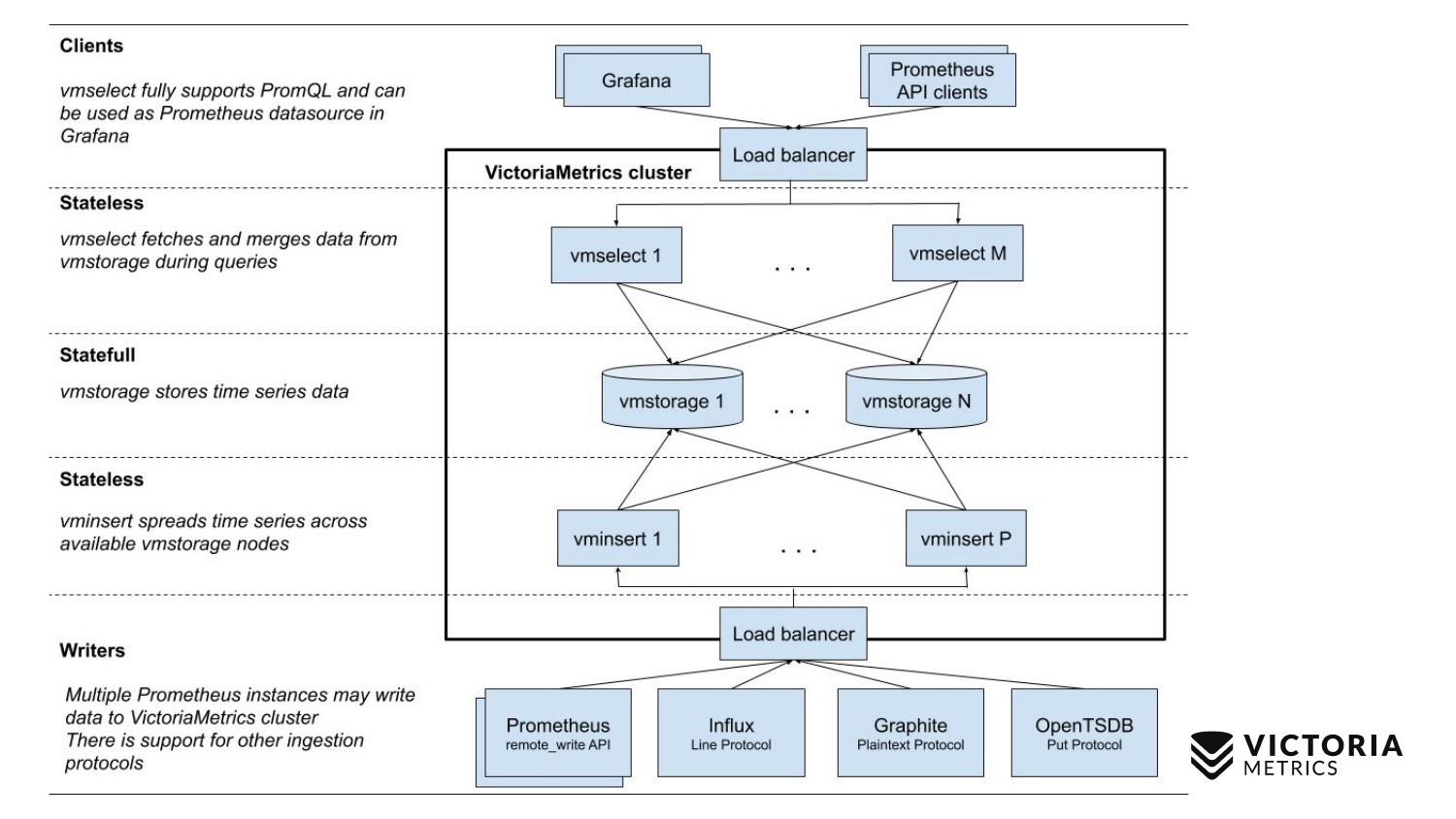
Agora compare com o esquema VictoriaMetrics.
O VictoriaMetrics possui 2 versões: Versão de nó único e cluster. O nó único é executado em um único computador. O nó único não possui esses componentes, apenas um binário. Esse binário no slide se parece com esse quadrado. Tudo o que está dentro do quadrado é o conteúdo do arquivo binário da versão de nó único. Você não precisa saber sobre ele. Basta iniciar o binário - e tudo funciona para nós.
A versão do cluster é mais complicada. Dentro dele, existem três componentes diferentes: vmselect, vminsert e vmstorage. Pelo nome, deve ficar claro o que cada um deles faz. O componente Inserir aceita dados em diferentes formatos: da API de gravação remota Prometheus, protocolo de linha de influxo, protocolo de grafite e protocolo OpenTSDB. O componente Inserir os aceita, analisa e distribui entre os componentes de armazenamento existentes, onde os dados já estão armazenados. O componente Select, por sua vez, aceita consultas PromQL. Ele implementa o PromQL , bem como a API de consulta do Prometheus, e pode ser usado como um substituto para o Prometheus no Grafana ou em outros clientes da API do Prometheus. O Select aceita uma solicitação promql, analisa-a, lê os dados necessários para executar essa solicitação no nó de armazenamento, processa esses dados e retorna uma resposta.

Compare a dificuldade de instalar o Thanos e o VictoriaMetrics.

Vamos começar com Thanos. Antes de começar a trabalhar com o Thanos, você precisa criar um bucket no Object Storage, como S3 ou GCS, para que o Thanos Sidecar possa gravar dados lá.

Então, para cada Prometheus, você precisará instalar o Thanos Sidecar. Antes disso, lembre-se de desativar a compactação de dados no Prometheus. A compactação de dados compacta periodicamente os dados no armazenamento local do Prometheus para reduzir o consumo de recursos.
Ao instalar o Thanos Sidecar no Prometheus, você deve desativar essa compactação de dados, porque o Thanos Sidecar não pode funcionar normalmente quando a compactação de dados está ativada. Isso significa que seu Prometheus começa a salvar dados em blocos de duas horas e para de mesclar esses blocos em blocos maiores. Portanto, se você fizer solicitações superiores às últimas duas horas, elas não funcionarão da maneira mais eficiente possível se a compactação de dados estiver ativada.

Portanto, a Thanos recomenda reduzir o tempo de retenção de dados no armazenamento local para 6-8 horas, a fim de reduzir essa sobrecarga de um grande número de pequenos blocos.
Depois de instalar o Thanos Sidecar, você deve instalar dois componentes para cada Object Storage Bucket. Estes são o Thanos Compactor e o Thanos Store Gateway.

Depois disso, é necessário instalar o Thanos Query e configurá-lo para que ele saiba como se conectar a todo o Thanos Store Gateway que você possui e também saiba como se conectar a todos os Thanos Sidecar.
Pode haver um pequeno problema.

Você precisa configurar uma conexão confiável e segura do Thanos Query para esses componentes. E se o seu Prometheus estiver localizado em diferentes data centers ou em diferentes VPCs, as conexões externas a eles serão proibidas. Mas, para que o Thanos Query funcione, é necessário configurar a conexão de alguma forma e é preciso criar uma maneira.
Se você possui muitos desses datacenters, a confiabilidade de todo o sistema diminui. Como o Thanos Query deve estar constantemente conectado a todos os Thanos Sidecar localizados em diferentes datacenters. A cada solicitação recebida, ele encaminhará solicitações para todos os Thanos Sidecar. Se a conexão for interrompida, você receberá um conjunto incompleto de dados ou a resposta "o cluster não funciona".

No VictoriaMetrics, as coisas são um pouco mais fáceis. Para a versão de nó único, basta executar um binário e tudo funciona.

Em uma versão em cluster, basta executar todos os três tipos de componentes acima em qualquer quantidade que você precisar ou usar o gráfico de comando para automatizar o lançamento de componentes no Kubernetes. Ainda estamos planejando fazer um operador Kubernetes. O gráfico do leme não cobre alguns casos e permite que você atire na perna. Por exemplo, permite reduzir o número de nós de armazenamento, o que levará à perda de dados.

Depois de iniciar uma versão binária ou de cluster, basta adicionar a configuração do URL de gravação remota à configuração do Prometheus para que ela comece a gravar dados em paralelo ao armazenamento local e armazenamento remoto. Como você notou, essa configuração deve funcionar muito mais confiável em comparação com a configuração Thanos. Não precisamos manter o VictoriaMetrics conectado a todo o Prometheus, porque o próprio Prometheus se conecta ao VictoriaMetrics e transmite os dados.

Considere as escoltas Thanos e VictoriaMetrics.

Thanos precisa ficar de olho no Sidecar para que ele não pare de carregar dados no Object Storage. Eles podem interromper o carregamento desses dados devido a erros de carregamento, por exemplo, sua conexão de rede com o Armazenamento de Objetos está temporariamente desconectada ou o Armazenamento de Objetos está temporariamente indisponível. O Thanos Sidecar notará isso neste momento, reportará um erro, poderá cair e parar de funcionar. Se você não o monitorar, seus dados não serão mais transferidos para o Armazenamento de Objetos. Se o tempo de retenção passar (recomenda-se de 6 a 8 horas), você perderá dados que não caíram no Armazenamento de Objetos.

Os compactadores Thanos podem parar de funcionar devido à corrida com o Sidecar . Os compactadores pegam dados do Object Storage e os mesclam em pedaços maiores de dados. Como os compactadores não estão sincronizados com o Sidecar, isso pode acontecer: o Sidecar ainda não terminou de escrever o bloco, o Compactador decide que esse bloco está completamente gravado. O compactador começa a lê-lo. Ele não lê o bloco na íntegra e para de funcionar. Veja detalhes aqui .

O Store Gateway pode fornecer dados inconsistentes devido à corrida entre o Compactador e o Sidecar. É a mesma coisa, porque o Gateway de loja não está de forma alguma sincronizado com o Compactor e o Sidecar. Consequentemente, uma condição de corrida pode ocorrer quando o Store Gateway não vê parte dos dados ou vê dados em excesso.

O componente Consulta no Thanos é padronizado para resultados parciais se alguns Sidecar ou Store Gateway não estiverem disponíveis no momento. Você receberá uma parte dos dados e nem saberá que nem todos os dados foram recebidos. Que funciona assim por padrão. Em uma situação semelhante, o VictoriaMetrics retorna os dados marcados como parciais.

Ao contrário de Thanos, o VictoriaMetrics raramente perde dados. Mesmo que a conexão do Prometheus ao VictoriaMetrics seja interrompida, isso não é um problema, pois o Prometheus continua registrando novos dados recebidos no Write Ahead Log, que tem 2 horas de tamanho. Se você se reconectar ao VictoriaMetrics dentro de duas horas, os dados não serão perdidos. O Prometheus pode adicionar dados após se reconectar ao VictoriaMetrics .

Diferentemente do Thanos, que grava dados apenas no armazenamento de objetos após duas horas, o Prometheus replica automaticamente os dados por meio do protocolo de gravação remota no armazenamento remoto, como o VictoriaMetrics. Você não tem medo de perder armazenamento local no Prometheus. Se, de repente, ele perdeu o armazenamento local, na pior das hipóteses, você perderá os últimos segundos de dados que não tiveram tempo de gravar no armazenamento remoto.

O Kubernetes gerencia automaticamente o cluster, ao contrário de Thanos. É difícil colocar todos os componentes Thanos em um único cluster Kubernetes, ao contrário dos componentes de cluster VictoriaMetrics.

O VictoriaMetrics possui uma atualização muito simples para a nova versão. Basta parar o VictoriaMetrics, atualizar os binários e executar. Ao parar através de um sinal SIGINT, todos os binários VictoriaMetrics fazem um desligamento completo. Eles salvam corretamente os dados necessários, fecham corretamente as conexões de entrada para não perder nada. Portanto, você não perderá nada ao atualizar.

O VictoriaMetrics possui uma maneira muito simples de expandir um cluster. Basta adicionar os componentes necessários e continuar trabalhando.

Sobre as armadilhas em Thanos e Victoria Metrics.

Thanos tem as seguintes armadilhas. O Prometheus deve armazenar dados nas últimas duas horas. Se eles forem perdidos, você os perderá completamente, pois eles ainda não conseguiram se registrar no Object Storage, como o S3.

O componente Store Gateway e o componente compactador podem exigir muita memória para funcionar com o Armazenamento de Objetos grande, se muitos arquivos pequenos estiverem armazenados lá. Quanto maior o número e o volume de arquivos, mais o Store Gateway e a memória do compactador são necessários para armazenar as meta-informações. Thanos tem muitos problemas com o Store Gateway e o compactador caindo com a média de dados gravados .

Thanos é elogiado por poder escalar indefinidamente pela quantidade de seu Prometeu. Na verdade, isso não é verdade. Como todas as solicitações passam pelo componente Consulta, que deve pesquisar simultaneamente todos os componentes do Gateway de Loja e todos os componentes do Sidecar, retire os dados de lá e os processe previamente. Obviamente, a velocidade da consulta é limitada pelo link fraco mais lento, pelo Gateway de Loja mais lento ou pelo Sidecar mais lento.
Esses componentes podem ser carregados de maneira desigual. Por exemplo, você tem um Prometheus que coleta milhões de métricas por segundo. E há o Prometheus, que coleta milhares de métricas por segundo. O Prometheus, que coleta milhões de métricas por segundo, carrega o servidor em que executa muito mais. Consequentemente, o Sidecar é mais lento lá. Em geral, tudo funciona lentamente lá. E o componente Query extrairá dados muito lentamente a partir daí. Assim, o desempenho de todo o cluster será limitado por esse Sidecar lento.

Por padrão, Thanos retorna dados parciais se alguns Sidecar e o Store Gateway estiverem indisponíveis. Por exemplo, se você tiver o Sidecar espalhado pelo mundo em diferentes datacenters, a probabilidade de desconexão e indisponibilidade de componentes aumentará bastante. Consequentemente, na maioria dos casos, você receberá dados parciais sem nem mesmo saber.

VictoriaMetrics também tem armadilhas. A primeira armadilha é uma opção que limita a quantidade de RAM usada para o cache do VictoriaMetrics. Por padrão, é igual a 60% da RAM na máquina em que o VictoriaMetrics está sendo executado ou 60% da RAM do pod VictoriaMetrics no Kubernetes.
Se você alterar incorretamente esse valor, poderá prejudicar o desempenho do VictoriaMetrics. Por exemplo, se você definir o valor muito baixo, os dados poderão não caber mais no cache do VictoriaMetrics. Por isso, ela terá que fazer um trabalho extra e carregar o processador com o disco. Se você tornar essa opção muito grande, aumentará, em primeiro lugar, a probabilidade de o VictoriaMetrics travar com erro de falta de memória e, em segundo lugar, isso levará a pouquíssima memória operacional restante no sistema operacional memória para o cache do arquivo. E o VictoriaMetrics conta com um cache de arquivos para desempenho. Se não for suficiente, a carga no disco poderá aumentar bastante. Portanto, uma dica: não altere o parâmetro, a menos que seja absolutamente necessário.
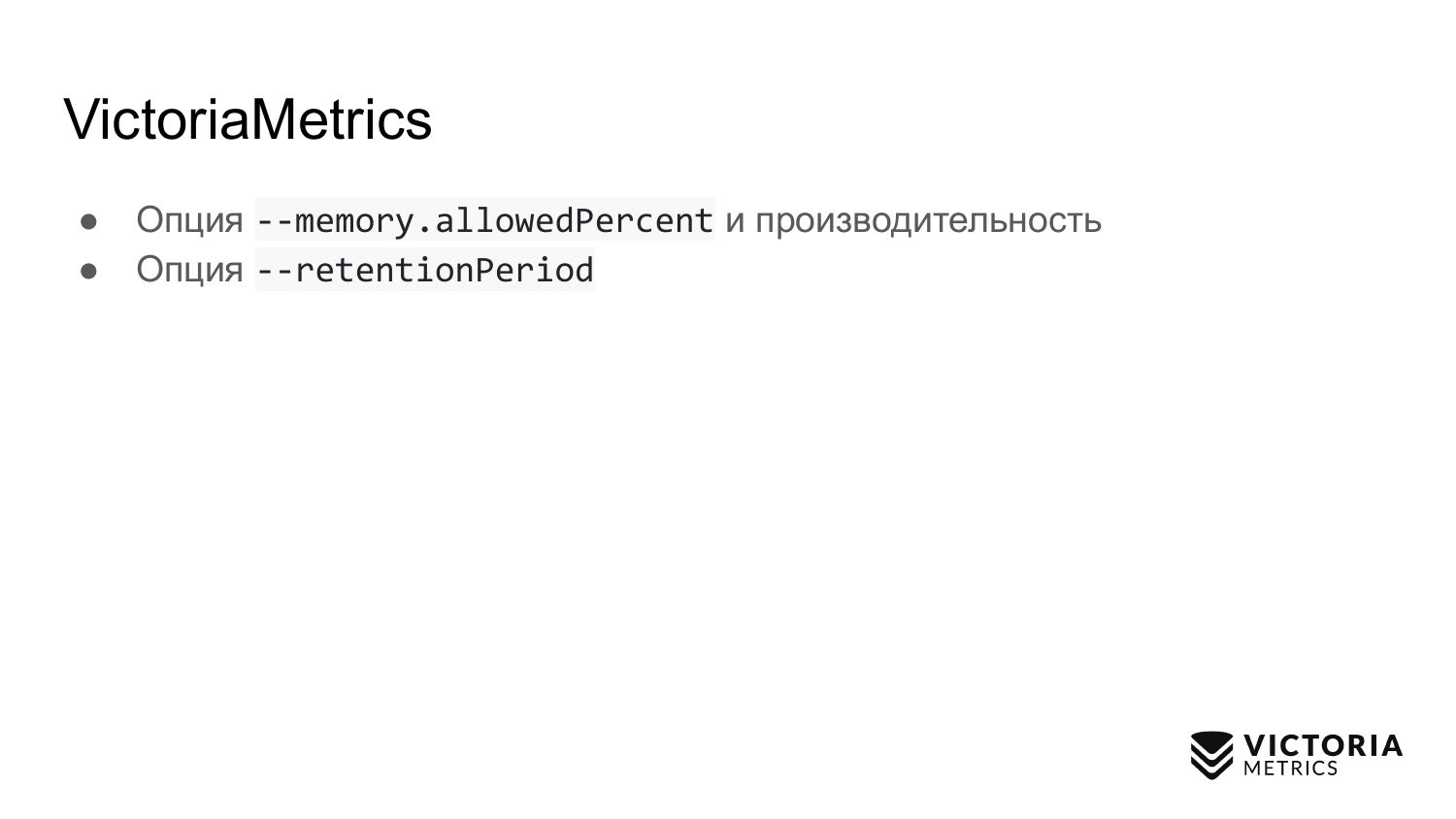
A segunda opção Este é retentionPeriod - o período definido como 1 mês por padrão. Este é o momento em que o VictoriaMetrics armazena dados. Após esse período, o VictoriaMetrics exclui os dados.
Muitos executam o VictoriaMetrics sem esse parâmetro, eles registram dados por um mês. E então perguntam: por que os dados desapareceram no mês anterior? Como retentionPeriod é de 1 mês por padrão. Portanto, você precisa conhecer e definir o retentionPeriod correto.

.

Thanos , downsampling: 5- , . issue github, issues, downsampling, , , .

Thanos Prometheus HA pairs. Prometheus' target' Thanos Object Storage. Thanos , VictoriaMetrics.

Thanos alert , Thanos. production .

Thanos , Thanos Prometheus — . Thanos Prometheus . Thanos Prometheus .

VictoriaMetrics — MetricsQL. VictoriaMetrics PromQL, big monitoring metup.

VictoriaMetrics . VictoriaMetrics Prometheus, Influx, OpenTSDB Graphite.

VictoriaMetrics Thanos Prometheus.
, 2-5 Prometheus Thanos.

VictoriaMetrics — .

.

Thanos , object storage, .
object storage, ($10 ). object storage, , AWS — . , $10 $230 1. , Thanos .

Thanos Compact, Store Gateway, Query , , .

VictoriaMetrics . GCE HDD , $40 1. VictoriaMetrics HDD , SSD, . VictoriaMetrics HDD.

O VictoriaMetrics precisa de servidores para componentes: componente único ou componentes de cluster, que, diferentemente dos componentes Thanos, exigem muito menos CPU, RAM - será mais barato em conformidade.

Exemplos de implementação.

O exemplo de implementação de Thanos é o Gitlab. O Gitlab é totalmente alimentado por Thanos. Mas não é tão suave. Se você olhar para os problemas deles, poderá ver que eles constantemente têm algum tipo de problema operacional com o Thanos : não há memória suficiente para os componentes Store Gateway ou Query. Eles constantemente precisam aumentar a quantidade de memória.
Por esse motivo, os custos de solução desses problemas aumentam.
A segunda implementação, que pode ter mais sucesso, é a empresa Improvável, que iniciou o desenvolvimento de Thanos. Eles publicaram a fonte de Thanos. Improvável é uma empresa que desenvolve mecanismos de jogos.

Os exemplos públicos de implementação do VictoriaMetrics são:
- construtor de sites wix.com
- A Adidas apresenta o VictoriaMetrics e até fez uma apresentação no mais recente PromCon 2019
- TrafficStars - rede de anunciantes
- O Seznam.cz é um popular mecanismo de pesquisa tcheco.
E depois fui para o nome da empresa, que não posso citar agora. Eles não concordaram.
- Um grande desenvolvedor de jogos. Maior que eles Improvável.
- Um importante desenvolvedor de software gráfico.
- Grande banco russo.
- Fabricante europeu de turbinas eólicas que testou com sucesso o VictoriaMetrics. Este fabricante implementa o VictoriaMetrics para monitorar dados de turbinas eólicas a uma velocidade de 50 amostras por segundo por sensor. Cada turbina eólica possui várias centenas de sensores. Eles têm várias centenas de turbinas eólicas.
- Companhias aéreas russas que querem introduzir VictoriaMetrics, mas ainda não podem. Estamos na fase de contrato com eles.
 Conclusões
Conclusões
VictoriaMetrics e Thanos resolvem problemas semelhantes, mas de maneiras diferentes:
- Visualização de consulta global
- escala horizontal
- retenção arbitrária

Obrigada
Estamos esperando por você no nosso canal de telegrama .
