Oi Habr! Os conjuntos de dados para Big Data e aprendizado de máquina estão crescendo exponencialmente e precisam ser processados. Nossa postagem sobre mais uma tecnologia inovadora em High Performance Computing (HPC), apresentada no estande da Kingston na
Supercomputing 2019 . Esta é a aplicação dos sistemas de armazenamento Hi-End (SHD) em servidores com processadores gráficos (GPU) e tecnologia de barramento GPUDirect Storage. Graças à troca direta de dados entre armazenamento e GPUs, ignorando a CPU, o carregamento de dados nos aceleradores de GPU é acelerado por uma ordem de magnitude; portanto, os aplicativos de Big Data são executados com o desempenho máximo que a GPU oferece. Por sua vez, os desenvolvedores de sistemas HPC estão interessados em avanços no armazenamento com a maior velocidade de E / S - como as versões da Kingston.

Desempenho da GPU antes do carregamento de dados
Desde a criação da CUDA, uma arquitetura de computação paralela de hardware e software baseada em GPU para o desenvolvimento de aplicativos de uso geral, em 2007, os recursos de hardware das próprias GPUs cresceram incrivelmente. Hoje, as GPUs são cada vez mais usadas no campo de aplicativos HPC, como Big Data, aprendizado de máquina e aprendizado profundo.
Observe que, apesar da semelhança de termos, os dois últimos são tarefas algoritmicamente diferentes. ML ensina um computador com base em dados estruturados e DL ensina um computador com base na resposta de uma rede neural. Um exemplo que ajuda a entender as diferenças é bastante simples. Suponha que um computador deva distinguir fotos de gatos e cães carregados do armazenamento. Para o ML, você deve enviar um conjunto de imagens com muitas tags, cada uma das quais define um recurso específico do animal. Para DL, basta carregar um número muito maior de imagens, mas com apenas uma tag "isto é um gato" ou "este é um cachorro". O DL é muito semelhante ao modo como as crianças são ensinadas - elas são simplesmente mostradas imagens de cães e gatos nos livros e na vida (na maioria das vezes, sem explicar a diferença detalhada), e o próprio cérebro da criança começa a determinar o tipo de animal após um certo número crítico de fotos para comparação ( de acordo com estimativas, estamos falando de uma centena ou duas impressões durante todo o tempo da primeira infância). Os algoritmos de DL ainda não são tão perfeitos: para trabalhar com êxito na definição de imagens de uma rede neural, é necessário enviar e processar milhões de imagens na GPU.
O resultado da introdução: com base na GPU, você pode criar aplicativos HPC no campo de Big Data, ML e DL, mas há um problema - os conjuntos de dados são tão grandes que o tempo gasto no download de dados do sistema de armazenamento para a GPU começa a reduzir o desempenho geral do aplicativo. Em outras palavras, as GPUs rápidas permanecem pouco carregadas devido à lenta entrada / saída de dados de outros subsistemas. A diferença na velocidade de entrada / saída da GPU e do barramento para a CPU / SHD pode ser uma ordem de magnitude.
Como funciona a tecnologia GPUDirect Storage?
O processo de entrada / saída é controlado pela CPU, bem como o processo de carregamento de dados do armazenamento nas GPUs para processamento subsequente. Isso levou a uma solicitação de tecnologia que forneceria acesso direto entre as unidades GPU e NVMe para interação rápida entre si. A primeira dessas tecnologias foi proposta pela NVIDIA e denominada GPUDirect Storage. De fato, essa é uma variação da tecnologia GPUDirect RDMA (endereço de memória direta remota) que eles desenvolveram anteriormente.
 Jensen Huang, CEO da NVIDIA, apresenta o GPUDirect Storage como uma variação do GPUDirect RDMA no SC-19. Fonte: NVIDIA
Jensen Huang, CEO da NVIDIA, apresenta o GPUDirect Storage como uma variação do GPUDirect RDMA no SC-19. Fonte: NVIDIAA diferença entre o GPUDirect RDMA e o GPUDirect Storage está nos dispositivos entre os quais o endereçamento é realizado. A tecnologia GPUDirect RDMA é reatribuída para mover dados diretamente entre a placa de interface de rede (NIC) e a memória GPU, e o GPUDirect Storage fornece um caminho direto de transferência de dados entre o armazenamento local ou remoto, como NVMe ou NVMe via Fabric (NVMe-oF) e memória GPU.
As duas opções, GPUDirect RDMA e GPUDirect Storage, evitam a movimentação desnecessária de dados através de um buffer na memória da CPU e permitem que o mecanismo Direct Memory Access (DMA) transfira dados de uma placa de rede ou armazenamento diretamente para ou da memória da GPU - tudo sem carga na central processador Para o GPUDirect Storage, o local de armazenamento não importa: ele pode ser um disco NVME dentro de uma unidade GPU, dentro de um rack ou conectado via rede como NVMe-oF.
 Esquema de operação de armazenamento GPUDirect. Fonte: NVIDIA
Esquema de operação de armazenamento GPUDirect. Fonte: NVIDIAArmazenamento NVMe Hi-End necessário no mercado de aplicativos HPC
Entendendo que, com o advento do GPUDirect Storage, o interesse de grandes clientes estará voltado para oferecer sistemas de armazenamento com uma velocidade de entrada / saída correspondente à largura de banda da GPU, a Kingston mostrou um sistema de demonstração que consiste em sistemas de armazenamento baseados em discos NVMe e uma unidade com GPU no SC-19 que analisou milhares de imagens de satélite por segundo. Já escrevemos sobre esse armazenamento com base em 10 unidades DC1000M U.2 NVMe
em um relatório da exposição de supercomputadores .
 O armazenamento baseado em 10 unidades DC1000M U.2 NVMe complementa adequadamente o servidor com aceleradores gráficos. Fonte: Kingston
O armazenamento baseado em 10 unidades DC1000M U.2 NVMe complementa adequadamente o servidor com aceleradores gráficos. Fonte: KingstonEsse armazenamento é realizado na forma de uma unidade de rack 1U ou mais e pode ser dimensionado dependendo do número de discos DC1000M U.2 NVMe, onde cada um tem capacidade de 3,84-7,68 TB. O DC1000M é o primeiro modelo de SSD NVMe no formato U.2 na linha de unidades Kingston para data centers. Ele possui uma classificação de resistência (DWPD, Drive escreve por dia), que permite sobrescrever dados com capacidade total uma vez por dia para garantir uma vida útil garantida.
No teste fio v3.13 no sistema operacional Ubuntu 18.04.3 LTS, Linux kernel 5.0.0-31 genérico, o modelo de armazenamento de exibição mostrou uma velocidade de leitura sustentada de 5,8 milhões de IOPS com uma largura de banda sustentada de 23,8 Gb / s.
Ariel Perez, gerente de negócios de SSD da Kingston, descreveu os novos sistemas de armazenamento da seguinte forma: “Estamos prontos para fornecer à próxima geração de servidores os SSDs U.2 NVMe para resolver muitos dos gargalos de transferência de dados que tradicionalmente têm sido associados ao armazenamento. A combinação de SSDs NVMe e nossa DRAM Server Premier premium faz da Kingston um dos mais abrangentes provedores de processadores de dados de ponta a ponta do setor. ”
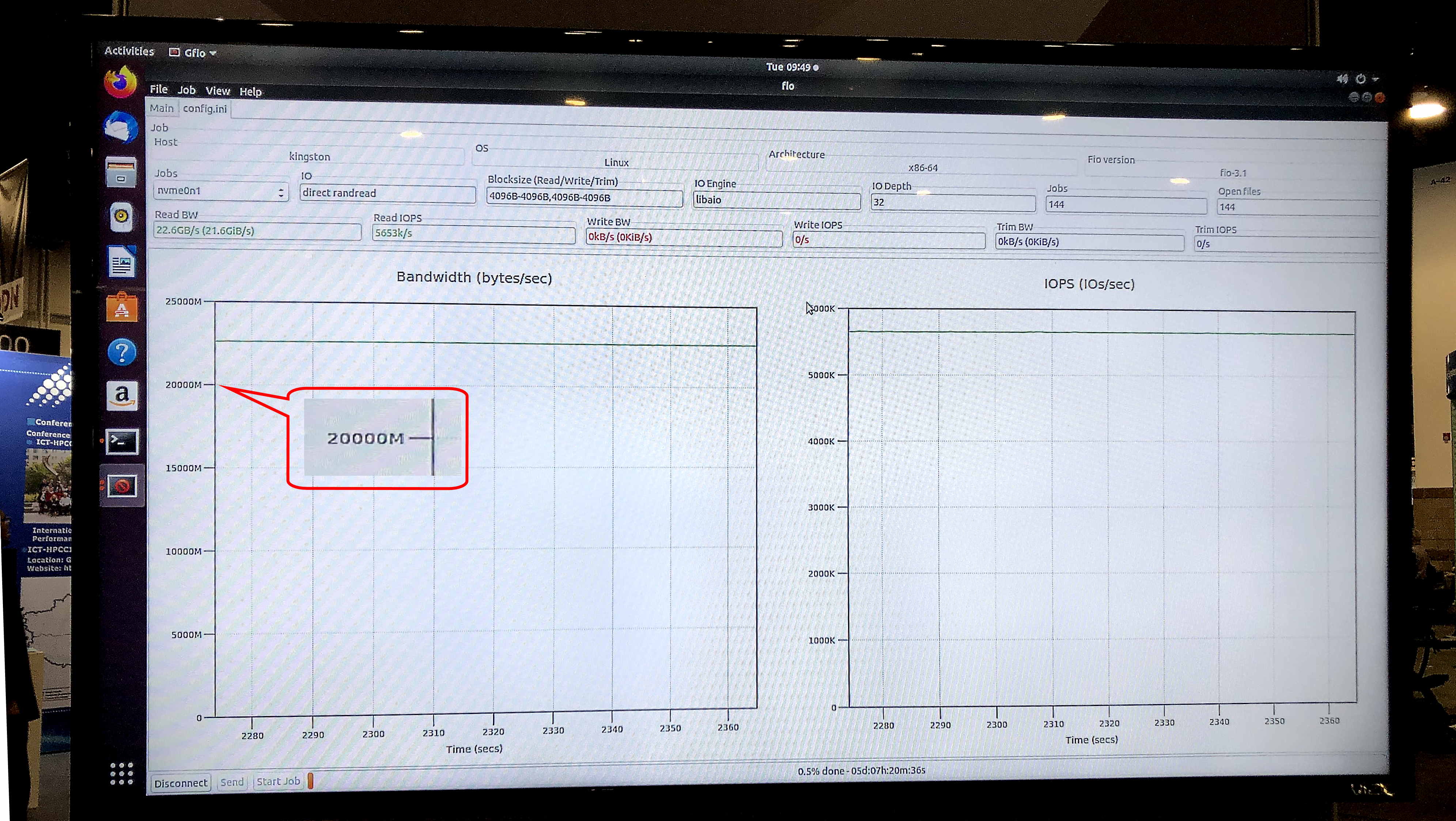 O teste gfio v3.13 mostrou uma largura de banda de 23,8 Gb / s para armazenamento de demonstração em unidades DC1000M U.2 NVMe. Fonte: Kingston
O teste gfio v3.13 mostrou uma largura de banda de 23,8 Gb / s para armazenamento de demonstração em unidades DC1000M U.2 NVMe. Fonte: KingstonComo será um sistema típico para aplicativos HPC que usam a tecnologia GPUDirect Storage ou similar? Essa é uma arquitetura com separação física de blocos funcionais em um rack: uma ou duas unidades para RAM, mais algumas para nós de computação de GPU e CPU e uma ou mais unidades para armazenamento.
Com o anúncio do GPUDirect Storage e o possível surgimento de tecnologias semelhantes em outros fornecedores de GPU, a Kingston expande sua demanda por sistemas de armazenamento projetados para uso em computação de alto desempenho. O marcador será a velocidade de leitura dos dados do sistema de armazenamento, comparável à largura de banda das placas de rede de 40 ou 100 Gbit na entrada de uma unidade de computação com uma GPU. Assim, sistemas de armazenamento ultrarrápidos, incluindo o NVMe externo através do Fabric, do exotic tornar-se-ão populares para aplicativos HPC. Além dos cálculos científicos e financeiros, eles encontrarão aplicação em muitas outras áreas práticas, como sistemas de segurança no nível da cidade segura da megalópole ou centros de vigilância em veículos onde é necessária a velocidade de reconhecimento e identificação de milhões de imagens em HD por segundo ”, o nicho de mercado entre os principais SHD
Informações adicionais sobre os produtos Kingston podem ser encontradas no
site oficial da empresa.