Nota perev. : Este artigo do Medium é uma visão geral das principais mudanças (2010-2019) no mundo das linguagens de programação e no ecossistema de tecnologia relacionado (atenção especial é dada ao Docker e ao Kubernetes). Sua autora original é Cindy Sridharan, especializada em ferramentas para desenvolvedores e sistemas distribuídos - em particular, ela escreveu o livro “Distributed Systems Observability” - e é bastante popular no espaço da Internet entre os profissionais de TI que estão particularmente interessados no tópico nativo da nuvem.
Chegou o fim de 2019, então eu gostaria de compartilhar meus pensamentos sobre algumas das conquistas e inovações tecnológicas mais importantes da década passada. Além disso, tentarei olhar um pouco para o futuro e descrever os principais problemas e oportunidades da próxima década.
Quero fazer imediatamente uma reserva de que, neste artigo, não abordo mudanças em áreas como
ciência de dados , inteligência artificial, engenharia de front-end, etc., pois pessoalmente não tenho experiência suficiente nelas.
Digitando contra-ataques
Uma das tendências mais positivas da década de 2010 foi o renascimento de idiomas com tipificação estática. No entanto, essas linguagens não desapareceram em nenhum lugar (C ++ e Java estão em demanda hoje; elas dominam há dez anos); no entanto, linguagens com digitação dinâmica (dinâmica) experimentaram um aumento significativo na popularidade após o surgimento do movimento Ruby on Rails em 2005. Esse crescimento atingiu o pico em 2009 com a abertura do código fonte Node.js., tornando o Javascript no servidor uma realidade.
Com o tempo, as linguagens dinâmicas perderam parte de seu apelo no desenvolvimento de software para servidores. A linguagem Go, popularizada durante a revolução do contêiner, parecia melhor adaptada para criar servidores de alto desempenho e eficiência de recursos com processamento paralelo de informações (com o que o criador do Node.js
concorda ).
O Rust, introduzido em 2010, incluiu avanços na
teoria dos tipos na tentativa de se tornar uma linguagem segura e digitada. Na primeira metade da década, a atitude em relação à ferrugem na indústria foi bem legal, mas na segunda metade sua popularidade aumentou significativamente. Exemplos notáveis do uso de Rust incluem o uso do
Magic Pocket no Dropbox ,
AWS Firecracker (falamos sobre isso neste artigo - aprox. Transl.) , O compilador WebAssembly da Fastly da Fastly (agora parte da Bytecode Alliance), etc. Em uma situação em que a Microsoft está pensando em reescrever algumas partes do Windows para Rust, é seguro dizer que na década de 2020 esse idioma terá um futuro brilhante.
Até linguagens dinâmicas ganharam novos recursos, como
tipos opcionais . Eles foram implementados pela primeira vez no TypeScript, uma linguagem que permite criar código digitado e compilá-lo em JavaScript. PHP, Ruby e Python adquiriram seus próprios sistemas de digitação opcionais (
mypy ,
Hack ), que são utilizados com sucesso na
produção .
Retorno do SQL ao NoSQL
O NoSQL é outra tecnologia que era muito mais popular no início da década do que no final. Eu acho que há duas razões para isso.
Em primeiro lugar, o modelo NoSQL, com falta de esquema, transações e garantias mais fracas de consistência, mostrou-se mais difícil de implementar do que o modelo SQL. Em uma
postagem no blog intitulada "
Por que você deve escolher uma consistência forte, sempre que possível", o Google escreve:
Uma das coisas que aprendemos no Google é que o código do aplicativo é mais simples e o tempo de desenvolvimento é menor se os engenheiros puderem confiar no armazenamento existente para lidar com transações complexas e manter a ordem dos dados. Citando a documentação original do Spanner, "acreditamos que é melhor que os programadores lidem com problemas de desempenho de aplicativos devido ao abuso de transações, à medida que surgem gargalos, em vez de constantemente não ter transações em mente".
O segundo motivo está relacionado ao crescimento de bancos de dados SQL distribuídos “escaláveis” (como
Cloud Spanner e
AWS Aurora ) no espaço público em nuvem, bem como alternativas de código aberto como o CockroachDB
(também escrevemos sobre ele - aprox. Transl.) , Que muitos resolvem de problemas técnicos, devido aos quais as bases SQL tradicionais “não foram dimensionadas”. Até o MongoDB, que já foi o epítome do movimento NoSQL, agora
oferece transações distribuídas.
Para situações que exigem operações atômicas de leitura e gravação em vários documentos (em uma ou mais coleções), o MongoDB suporta transações com vários documentos. No caso de transações distribuídas, as transações podem ser usadas para muitas operações, coleções, bancos de dados, documentos e shards.
Transmissão total
Apache Kafka, sem dúvida, se tornou uma das invenções mais importantes da década passada. Seu código-fonte foi aberto em janeiro de 2011 e, ao longo dos anos, Kafka revolucionou a maneira como os negócios de dados funcionam. O Kafka foi usado em todas as empresas nas quais tive oportunidade de trabalhar, desde startups a grandes corporações. As garantias e os casos de uso fornecidos a eles (pub-sub, fluxos, arquiteturas orientadas a eventos) são usados em várias tarefas: desde a organização do armazenamento de dados até o monitoramento e a análise de streaming, que são procurados em muitas áreas, como finanças, saúde, setor público, varejo e etc.
Integração contínua (e, em menor grau, implantação contínua)
A integração contínua não apareceu nos últimos 10 anos, mas foi na última década que se
espalhou a tal ponto que se tornou parte do fluxo de trabalho padrão (execute testes em todas as solicitações de recebimento). Tornar-se um GitHub como uma plataforma para desenvolver e armazenar código e, mais importante, desenvolver um fluxo de trabalho baseado no
fluxo do GitHub significa que realizar testes antes de aceitar uma solicitação de recebimento no mestre é o
único fluxo de trabalho em desenvolvimento familiar aos engenheiros que iniciaram suas carreiras em últimos dez anos.
A Implantação Contínua (Implantação Contínua; implantar cada confirmação como está e quando entra no mestre) não é tão difundida quanto a integração contínua. No entanto, com muitas APIs baseadas em nuvem diferentes para implantação, a crescente popularidade de plataformas como Kubernetes (fornecendo uma API padronizada para implantações) e o surgimento de ferramentas de várias plataformas e múltiplas nuvens como o Spinnaker (construído sobre essas APIs padronizadas), os processos de implantação tornaram-se mais automatizados, simplificados e simplificados. geralmente mais seguro.
Contentores
Os contêineres, talvez, podem ser chamados de tecnologia mais comentada, discutida, anunciada e incompreendida dos anos 2010. Por outro lado, esta é uma das inovações mais importantes da década anterior. Parte da razão de toda essa cacofonia está nos sinais mistos que recebemos em quase todos os lugares. Agora que o hype se acalmou um pouco, alguns momentos assumiram tons mais distintos.
Os contêineres se tornaram populares não porque são a melhor maneira de executar um aplicativo que atenda às necessidades da comunidade global de desenvolvedores. Os contêineres se tornaram populares porque se encaixam com êxito em uma solicitação de marketing de uma ferramenta que resolve um problema completamente diferente. O Docker acabou sendo uma ferramenta de desenvolvimento
fantástica para resolver o problema de compatibilidade urgente ("funciona na minha máquina").
Mais precisamente, a
imagem do
Docker fez uma revolução porque resolveu o problema de paridade entre ambientes e garantiu a verdadeira portabilidade não apenas do arquivo do aplicativo, mas também de todos os seus softwares e dependências operacionais. O fato de essa ferramenta de alguma forma ter estimulado a popularidade de "contêineres", que de fato constituem um detalhe de implementação de nível muito baixo, permanece para mim talvez o principal mistério da década passada.
Sem servidor
Aposto que a aparência da computação "sem servidor" é ainda mais importante que os contêineres, porque realmente permite que você realize o sonho da computação
sob demanda . Nos últimos cinco anos, observei a expansão gradual do escopo da abordagem sem servidor (adicionando suporte para novos idiomas e tempos de execução). O surgimento de produtos como o Azure Durable Functions parece ser um passo seguro para a implementação de funções com estado (resolvendo simultaneamente
alguns problemas relacionados às restrições do FaaS). Observarei com interesse como esse novo paradigma se desenvolverá nos próximos anos.
Automação
Talvez a comunidade de engenheiros operacionais tenha se beneficiado mais dessa tendência, já que foi ele quem possibilitou a implementação de conceitos como "infraestrutura como código" (IaC). Além disso, a paixão pela automação coincidiu com o crescimento da "cultura SRE", cujo objetivo é uma abordagem de operação mais orientada ao programa.
API universal
Outra característica curiosa da década passada foi a ficção da API de várias tarefas de desenvolvimento. APIs flexíveis e boas permitem que os desenvolvedores criem fluxos de trabalho e ferramentas inovadores que, por sua vez, ajudam na manutenção e aumentam a usabilidade.
Além disso, a ficção de API é o primeiro passo para a ficção SaaS de alguma funcionalidade ou ferramenta. Essa tendência também coincidiu com a crescente popularidade dos microsserviços: o SaaS era apenas mais um serviço com o qual você pode trabalhar usando a API. Atualmente, existem muitas ferramentas SaaS e FOSS em áreas como monitoramento, pagamentos, balanceamento de carga, integração contínua, alertas,
sinalização de recursos , CDN, engenharia de tráfego (por exemplo, DNS) etc., que floresceram na década passada.
Observabilidade
É importante notar que hoje temos ferramentas
muito mais avançadas disponíveis para monitorar e diagnosticar o comportamento do aplicativo do que nunca. O sistema de monitoramento Prometheus, que recebeu o status de código aberto em 2015, pode ser chamado talvez o
melhor sistema de monitoramento daqueles com os quais trabalhei. Não é perfeito, mas um número significativo de coisas é implementado de uma maneira completamente correta (por exemplo, suporte para
dimensões no caso de métricas).
O rastreamento distribuído foi outra tecnologia que entrou no mainstream nos anos 2010, graças a iniciativas como o OpenTracing (e seu sucessor, OpenTelemetry). Embora o rastreamento ainda seja bastante difícil de usar, alguns dos desenvolvimentos mais recentes nos permitem esperar que, na década de 2020, revelemos seu verdadeiro potencial.
(Note perev.: Leia também em nosso blog a tradução do artigo " Rastreio distribuído: fizemos tudo errado " pelo mesmo autor.)Olhando para o futuro
Infelizmente, existem muitos pontos problemáticos que aguardam solução na próxima década. Aqui estão meus pensamentos sobre eles e algumas idéias em potencial sobre como se livrar deles.
Resolvendo o problema da lei de Moore
O fim da lei de escala de Dennard e o atraso da lei de Moore exigem novas inovações. John Hennessy, em
sua palestra, explica por que arquiteturas
específicas de domínio, como TPUs, podem se tornar uma das soluções para o problema de ficar atrás da lei de Moore. Kits de ferramentas como os
MLIRs do Google já parecem um bom passo nessa direção:
Os compiladores devem oferecer suporte a novos aplicativos, facilmente portar para novo hardware, vincular muitos níveis de abstração, de linguagens dinâmicas e controladas a aceleradores de vetor e dispositivos de armazenamento controlados por programa, ao mesmo tempo em que fornecem comutadores de alto nível para autoajuste, fornecendo funcionalidade just-in , diagnosticar e distribuir informações de depuração sobre o funcionamento e desempenho dos sistemas em toda a pilha e, na maioria dos casos, fornecer zvoditelnost suficientemente perto para o montador de escrita à mão. Pretendemos compartilhar nossa visão, progresso e planos em relação ao desenvolvimento e disponibilidade pública de uma infraestrutura de compilação.
CI / CD
Embora a crescente popularidade da CI tenha se tornado uma das principais tendências dos anos 2010, Jenkins ainda é o padrão-ouro da CI.
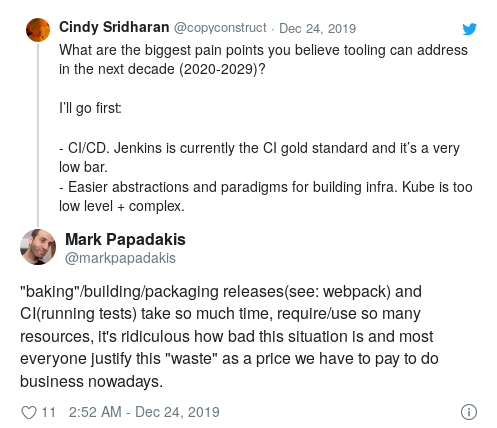
Esse espaço precisa urgentemente de inovação nas seguintes áreas:
- interface de usuário (DSL para especificações de teste de codificação);
- detalhes de implementação que o tornarão verdadeiramente escalável e rápido;
- integração com vários ambientes (estadiamento, prod, etc.) para a implementação de formas mais avançadas de teste;
- validação e implantação contínuas.
Ferramentas do desenvolvedor
Como uma indústria, começamos a criar software cada vez mais complexo e impressionante. No entanto, quando se trata de nossas próprias ferramentas, podemos dizer que a situação poderia ser muito melhor.
A edição conjunta e remota (via ssh) ganhou popularidade, mas ainda não se tornou o novo método de desenvolvimento padrão. Se você, como eu, rejeita a própria idéia da
necessidade de uma conexão permanente à Internet para poder programar, é improvável que trabalhar com o ssh em uma máquina remota seja adequado a você.
Os ambientes de desenvolvimento local, especialmente para engenheiros que trabalham em grandes arquiteturas orientadas a serviços, ainda permanecem um problema. Alguns projetos estão tentando resolvê-lo, e eu gostaria de saber como será o UX mais ergonômico para este caso de uso.
Também seria interessante desenvolver o conceito de “ambientes portáteis” para outras áreas de desenvolvimento, como a reprodução de erros (ou
testes inadequados ) encontrados em determinadas condições ou com determinadas configurações.
Também gostaria de ver mais inovações em áreas como pesquisa de código semântica e sensível ao contexto, ferramentas que permitem correlacionar incidentes de produção com partes específicas da base de código, etc.
Computações (futuro PaaS)
Em meio à propaganda geral sobre contêineres e sem servidor nos anos 2010, a gama de soluções na nuvem pública expandiu-se significativamente nos últimos anos.

Nesse sentido, surgem várias questões interessantes. Primeiro, a lista de opções disponíveis na nuvem pública está em constante crescimento. Os provedores de serviços em nuvem têm equipe e recursos para acompanhar facilmente os últimos avanços no mundo do código-fonte aberto e lançar produtos como pods sem servidor (suspeito apenas por tornar seus próprios tempos de execução do FaaS compatíveis com a OCI) ou outros coisas extravagantes semelhantes.
Quem usa essas soluções em nuvem só pode ser invejado. Em teoria, as ofertas de nuvem Kubernetes (GKE, EKS, EKS no Fargate etc.) fornecem APIs de provedor independentes da nuvem para executar cargas de trabalho. Se você usar produtos similares (ECS, Fargate, Google Cloud Run, etc.), provavelmente maximizará o uso das funções mais interessantes oferecidas pelo provedor de serviços. Além disso, com o advento de novos produtos ou paradigmas de computação, a migração provavelmente será simples e despreocupada.
Dada a rapidez com que a variedade dessas soluções está se desenvolvendo (fico surpreso se algumas novas opções não aparecerem no futuro próximo), pequenas equipes de "plataforma" (equipes relacionadas à infraestrutura e responsáveis pela criação de plataformas locais para o lançamento de cargas de trabalho nas empresas) será incrivelmente difícil competir em termos de funcionalidade, facilidade de uso e confiabilidade geral. Os anos 2010 foram marcados pelo Kubernetes como uma ferramenta para criar PaaS (plataforma como serviço), por isso parece completamente inútil criar uma plataforma interna baseada no Kubernetes que ofereça a mesma escolha, simplicidade e liberdade disponíveis em um espaço público na nuvem. O conceito de PaaS baseado em contêiner como estratégia Kubernetes equivale a abandonar intencionalmente os recursos de nuvem mais inovadores.
Se você observar os recursos de computação disponíveis
hoje em dia , torna-se óbvio que criar seu próprio PaaS apenas com base no Kubernetes equivale a se colocar em um canto (abordagem não muito ambígua, certo?). Mesmo que alguém decida criar PaaS em contêiner com base no Kubernetes hoje, em alguns anos ele parecerá desatualizado em comparação aos recursos da nuvem. Embora o Kubernetes tenha começado a existir como um projeto de código aberto, seu progenitor e inspirador ideológico é a ferramenta interna do Google correspondente. No entanto, ele foi originalmente desenvolvido no início / meados dos anos 2000, quando o cenário da computação era completamente diferente.
Além disso, em um sentido muito amplo, as empresas não devem se tornar especialistas em trabalhar com o cluster Kubernetes, nem criar e manter seus próprios datacenters. Fornecer uma base de computação confiável é o objetivo principal dos
provedores de serviços em nuvem .
Finalmente, tenho a sensação de que regredimos um pouco como indústria em termos de
experiência de interação (
UX ). O Heroku foi lançado em 2007 e continua sendo uma das plataformas
mais fáceis de usar . Sem dúvida, o Kubernetes tem muito mais poder, extensibilidade e capacidade de programação, mas sinto falta de como é fácil começar e implantar no Heroku. Para usar esta plataforma, basta conhecer o Git.
Tudo isso me leva à seguinte conclusão: para o trabalho, precisamos de abstrações melhores de nível superior (isso é especialmente verdadeiro para
abstrações de nível superior ).
A API certa ao mais alto nível
O Docker é um ótimo exemplo da necessidade de uma melhor separação de tarefas, juntamente com a
implementação correta da API de nível mais alto .
O problema com o Docker é que (pelo menos) o projeto tinha objetivos muito globais: tudo para resolver o problema de compatibilidade ("funciona na minha máquina") usando a tecnologia de contêiner. O Docker era um formato de imagem e um tempo de execução com sua própria rede virtual, uma ferramenta CLI e um daemon raiz, e muito mais. De qualquer forma, as mensagens eram
mais confusas, sem mencionar as "VMs leves", grupos de controle, namespaces, diversos problemas de segurança e recursos combinados com a chamada de marketing "criar, entregar, executar qualquer aplicativo em qualquer lugar".

Como em todas as boas abstrações, leva tempo (assim como experiência e sofrimento) para dividir os vários problemas em camadas lógicas que podem ser combinadas entre si. Infelizmente, antes que Docker conseguisse atingir essa maturidade, Kubernetes entrou na luta. Ele monopolizou tanto o ciclo do hype que agora todos tentavam acompanhar as mudanças no ecossistema Kubernetes, e o ecossistema de contêineres adquiria um status secundário.
O Kubernetes compartilha de várias maneiras os mesmos problemas que o Docker. Apesar de toda a conversa sobre abstração legal e compostável, a
separação de tarefas diferentes em camadas não
é muito encapsulada. Basicamente, é uma orquestra de contêineres que lança contêineres em um cluster de diferentes máquinas. Essa é uma tarefa de nível bastante baixo, aplicável apenas aos engenheiros que operam o cluster. O Kubernetes, por outro lado, também é uma
abstração do nível mais alto , uma ferramenta CLI com a qual os usuários interagem por meio do YAML.
O Docker era (e continua sendo) uma ferramenta
interessante de desenvolvimento, apesar de todas as suas deficiências. Na tentativa de acompanhar todas as lebres imediatamente, seus desenvolvedores conseguiram implementar corretamente a
abstração do mais alto nível .
Por abstração do nível mais alto, refiro-me a um subconjunto da funcionalidade na qual o público-alvo estava realmente interessado (nesse caso, os desenvolvedores que passavam a maior parte do tempo em seus ambientes de desenvolvimento local) e que funcionavam perfeitamente "fora da caixa" .
O Dockerfile e o utilitário CLI do
docker devem ser um exemplo de criação de uma boa "interface de usuário de nível superior". Um desenvolvedor comum pode começar a trabalhar com o Docker sem saber nada sobre os meandros da
implementação, que contribuem para a experiência operacional , como espaços para nome, grupos de controle, limitações de memória e CPU, etc. Por fim, escrever um Dockerfile não é muito diferente de escrever um script de shell.
O Kubernetes foi projetado para vários grupos-alvo:
- Administradores de Cluster
- engenheiros de software envolvidos em questões de infraestrutura, expandindo os recursos do Kubernetes e criando plataformas baseadas nele;
- usuários finais interagindo com o Kubernetes através do
kubectl .
A abordagem "uma API serve para todos" de Kubernetes é uma "montanha da complexidade" sub-encapsulada, sem indicação de como dimensioná-la. Tudo isso leva a um caminho de aprendizado irracionalmente longo. Segundo Adam Jacob, “o Docker trouxe aos usuários uma experiência transformadora que ainda não foi superada. Pergunte a qualquer um que use o K8s se deseja que ele funcione como sua primeira
docker run . A resposta será "sim":

Eu diria que a maior parte da tecnologia de infraestrutura hoje é de nível muito baixo (e, portanto, considerada "muito complexa"). O Kubernetes é implementado em um nível bastante baixo. O rastreamento distribuído em sua
forma atual (muitos spans costurados para formar uma visualização em rastreamento) também é implementado em um nível muito baixo. Ferramentas para desenvolvedores que implementam "abstrações do mais alto nível", como regra, são as mais bem-sucedidas. Essa conclusão é verdadeira em um número surpreendente de casos (se a tecnologia é muito complexa ou difícil de usar, o "API / UI de mais alto nível" dessa tecnologia ainda não foi aberto).
No momento, o ecossistema nativo da nuvem está envergonhado por seu foco em níveis baixos. Como uma indústria, precisamos inovar, experimentar e ensinar como é o nível certo de "máxima, máxima abstração".
Comércio a retalho
Nos anos 2010, a experiência do varejo digital mal mudou. Por um lado, a facilidade das compras on-line deveria ter atingido as lojas de varejo clássicas e, por outro, as compras on-line mudaram fundamentalmente em uma década.
Embora eu não tenha pensamentos concretos sobre o desenvolvimento desse setor na próxima década, ficarei muito decepcionado se, em 2030, fizermos compras da mesma maneira que em 2020.
Jornalismo
Estou cada vez mais decepcionado com o estado do jornalismo mundial. Está se tornando cada vez mais difícil encontrar recursos de notícias imparciais que transmitam objetiva e meticulosamente. Muitas vezes, a fronteira entre a notícia em si e a opinião sobre ela é apagada. Como regra, as informações são tendenciosas. Isto é especialmente verdade no caso de alguns países onde historicamente não havia separação entre notícias e opiniões sobre o assunto. Em um artigo recente publicado após a última eleição geral no Reino Unido, Alan Rusbridger, ex-editor do The Guardian,
escreve :
A idéia principal é que, durante muitos anos, olhei para os jornais americanos e senti pena dos colegas de lá, responsáveis exclusivamente pelas notícias, colocando comentários em pessoas completamente diferentes. No entanto, com o tempo, a pena se transformou em inveja. Agora, penso que todos os jornais nacionais britânicos devem separar a responsabilidade pelas notícias e a responsabilidade pelos comentários. Infelizmente, o leitor médio - especialmente o leitor on-line - é muito difícil de distinguir.
Dada a reputação bastante duvidosa do Vale do Silício quando se trata de ética, em hipótese alguma eu confiaria na tecnologia para "revolucionar" o jornalismo. Ao mesmo tempo, eu (e muitos de meus amigos) ficaria feliz em aparecer um recurso de notícias imparcial, desinteressado e confiável. Embora eu não possa imaginar como essa plataforma possa parecer, tenho certeza de que em uma época em que a verdade está se tornando cada vez mais difícil de discernir, a necessidade de um jornalismo honesto é maior do que nunca.
Redes sociais
As redes sociais e as plataformas coletivas de notícias são a principal fonte de informação para muitas pessoas em diferentes partes do mundo, e a falta de precisão e a relutância de algumas plataformas em conduzir pelo menos uma verificação básica de fatos básicos levam a conseqüências terríveis como genocídio, interferência nas eleições etc.
As redes sociais também são a ferramenta de mídia mais poderosa que já existiu. Eles mudaram radicalmente a prática política. Eles mudaram os anúncios. Eles mudaram a cultura pop (por exemplo, são as redes sociais que dão a principal contribuição ao desenvolvimento da chamada cultura de cancelamento
[ redes sociais do
ostracismo - aprox. Transl.] ). Os críticos argumentam que a mídia social acabou por ser um terreno fértil para mudanças rápidas e "caprichosas" nos valores morais, mas também proporcionaram aos representantes de grupos marginalizados a oportunidade de se unirem (eles nunca tiveram essa oportunidade antes). Em essência, as redes sociais mudaram a maneira como as pessoas se comunicam e como se expressam no século XXI.
No entanto, também estou convencido de que as redes sociais contribuem para a manifestação dos piores impulsos humanos. Atenção e consideração são muitas vezes negligenciadas por uma questão de popularidade, e torna-se quase impossível expressar um desacordo fundamentado com certas opiniões e posições. A polarização geralmente sai do controle, como resultado, o público simplesmente não ouve opiniões separadas, enquanto os absolutistas controlam questões de etiqueta e aceitabilidade on-line.
Eu me pergunto, é possível criar uma plataforma “melhor” que possa ajudar a melhorar a qualidade das discussões? Afinal, é exatamente o que impulsiona o "engajamento" que muitas vezes traz o principal lucro para essas plataformas. Como Kara Swisher
escreve no New York Times:
O engajamento digital pode ser desenvolvido sem provocar ódio e intolerância. A razão pela qual a maioria das redes sociais parece tão tóxica é porque elas foram criadas para velocidade, viralidade e atenção, e não para conteúdo e precisão.
Seria realmente lamentável se, em algumas décadas, o único legado das redes sociais fosse a erosão de nuances e a adequação no discurso público.
PS do tradutor
Leia também em nosso blog: