Hoje, existem soluções prontas (proprietárias) para monitorar fluxos de IP (TS), por exemplo, VB e iQ , elas têm um conjunto bastante rico de funções e geralmente essas soluções estão disponíveis para grandes operadoras que lidam com serviços de TV. Este artigo descreve uma solução baseada no projeto de código aberto TSDuck , projetado para controle mínimo de fluxos de IP (TS) pelo contador CC (contador de continuidade) e taxa de bits. Uma aplicação possível é controlar a perda de pacotes ou o fluxo inteiro através de um canal L2 alugado (que não pode ser monitorado normalmente, por exemplo, lendo os contadores de perda nas filas).
Muito breve sobre o TSDuck
O TSDuck é um software de código aberto (licença BSD de 2 cláusulas) (um conjunto de utilitários de console e uma biblioteca para desenvolver seus utilitários ou plug-ins) para manipular fluxos de TS. Como entrada, ele pode trabalhar com IP (multicast / unicast), http, hls, sintonizadores dvb, demodec dvb-asi demodulador, existe um gerador interno de fluxo TS e leitura de arquivos. A saída pode ser um arquivo, IP (multicast / unicast), hls, dektec dvb-asi e moduladores HiDes, players (mplayer, vlc, xine) e drop. Entre a entrada e a saída, você pode ativar vários processadores de tráfego, por exemplo, remapeamento do PID, embaralhamento / desembaralhamento, análise de contadores CC, cálculo de taxa de bits e outras operações típicas de fluxos TS.
Neste artigo, os fluxos IP (multicast) serão usados como entrada, os processadores bitrate_monitor serão usados (a partir do nome fica claro o que é) e a continuidade (análise dos contadores CC). Sem problemas, você pode substituir o multicast IP por outro tipo de entrada suportado pelo TSDuck.
Existem compilações / pacotes oficiais do TSDuck para a maioria dos sistemas operacionais atuais. Para o Debian, eles não são, mas foi possível montar sem problemas no debian 8 e no debian 10.
Em seguida, é usada a versão TSDuck 3.19-1520, o Linux é usado como sistema operacional (o debian 10 foi usado para preparar a solução, o CentOS 7 foi usado para uso real)
Preparando TSDuck e OS
Antes de monitorar os fluxos reais, é necessário garantir que o TSDuck esteja funcionando corretamente e que não haja quedas no nível da placa de rede ou do SO (soquete). Isso é necessário para não adivinhar mais tarde onde as quedas ocorreram - na rede ou "dentro do servidor". Você pode verificar as quedas no nível da placa de rede com o comando ethtool -S ethX, o ajuste é feito com o mesmo ethtool (geralmente, você precisa aumentar o buffer RX (-G) e às vezes desativar algumas descargas (-K)). Como recomendação geral, você pode recomendar o uso de uma porta separada para receber o tráfego analisado, se possível, isso minimiza os falsos positivos associados ao fato de que a queda ocorreu de forma coerente na porta do analisador devido à presença de outro tráfego. Se isso não for possível (um mini computador / NUC com uma única porta é usado), é altamente desejável priorizar o tráfego analisado em relação ao restante no dispositivo no qual o analisador está conectado. Em relação aos ambientes virtuais, aqui você precisa ter cuidado e encontrar quedas de pacotes começando na porta física e terminando com o aplicativo dentro da máquina virtual.
Geração e recepção de um fluxo dentro do host
Como primeiro passo na preparação do TSDuck, geraremos e receberemos tráfego dentro do mesmo host usando netns.
Ambiente de cozimento:
ip netns add P
O ambiente está pronto. Iniciamos o analisador de tráfego:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
onde "-p 1 -t 1" significa que você precisa calcular a taxa de bits a cada segundo e exibir informações sobre a taxa de bits a cada segundo
Iniciamos o gerador de tráfego com uma velocidade de 10 Mbps:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
onde "-p 7 -e" significa que você precisa compactar 7 pacotes TS em 1 pacote IP e fazê-lo com força (-e), ou seja, sempre aguarde 7 pacotes TS do último processador antes de enviar um pacote IP.
O analisador começa a exibir as mensagens esperadas:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
Agora adicione algumas gotas:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
e mensagens como estas aparecem:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
o que é esperado. Desative a perda de pacotes (exec netns ip Ptables-F) e tente aumentar a taxa de bits do gerador para 100 Mbps. O analisador relata vários erros de CC e cerca de 75 Mbit / s em vez de 100. Tentamos descobrir quem é o culpado - o gerador não tem tempo ou o problema não existe, por isso começamos a gerar um número fixo de pacotes (700.000 pacotes TS = 100.000 pacotes IP):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Como você pode ver, exatamente 100.000 pacotes IP foram gerados (151925460-151825460). Então, entendemos o que acontece com o analisador; para isso, verificamos com o contador RX no veth1, é estritamente igual ao contador TX no veth0, e depois examinamos o que acontece no nível do soquete:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
Aqui você pode ver o número de quedas = 24355. Nos pacotes TS, é 170485 ou 24,36% de 700000; portanto, vemos que os 25% da taxa de bits perdida são quedas no soquete udp. As quedas em um soquete UDP geralmente ocorrem devido à falta de um buffer, observe qual é o tamanho do buffer de soquete padrão e o tamanho máximo do buffer de soquete:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
Portanto, se os aplicativos não solicitarem explicitamente o tamanho do buffer, os soquetes serão criados com um buffer de 208 KB, mas se solicitarem mais, ainda assim não receberão o que é solicitado. Como no tsp você pode definir o tamanho do buffer (--buffer-size) para a entrada IP, não tocaremos no tamanho do soquete por padrão, apenas configuramos o tamanho máximo do buffer do soquete e especificamos o tamanho do buffer explicitamente através dos argumentos tsp:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
Com esse ajuste do buffer de soquete, a taxa de bits agora relatada é de aproximadamente 100 Mbit / s, não há erros de CC.
Pelo consumo de CPU pelo próprio aplicativo TSP. Em relação a um núcleo da CPU i5-4260U a 1.40GHz, a análise de um fluxo de 10Mbit / s requer 3-4% de CPU, 100Mbit / s - 25%, 200Mbit / s - 46%. Ao definir% de perda de pacotes, a carga na CPU praticamente não aumenta (mas pode diminuir).
Em um hardware mais produtivo, foi possível gerar e analisar fluxos de mais de 1 Gb / s sem problemas.
Teste em placas de rede reais
Após o teste em um par veth, é necessário pegar dois hosts ou duas portas de um host, conectar as portas uma à outra, executar o gerador em uma e o analisador na segunda. Não houve surpresas, mas, na realidade, tudo depende do ferro, quanto mais fraco, mais interessante será.
Uso dos dados recebidos pelo sistema de monitoramento (Zabbix)
O Tsp não possui uma API legível por máquina, como SNMP ou similar. As mensagens CC precisam ser agregadas por pelo menos 1 segundo (com uma alta porcentagem de perda de pacotes, pode haver centenas / milhares / dezenas de milhares por segundo, dependendo da taxa de bits).
Assim, para salvar informações e desenhar gráficos de erros de CC e taxa de bits e causar algum tipo de acidente, as seguintes opções podem ser ainda mais:
- Analise e agregue (de acordo com CC) a saída de TSP, ou seja, converta-o para a forma desejada.
- Adicione TSP e / ou plugins de processador bitrate_monitor e a continuidade em si para que o resultado seja exibido em um formato legível por máquina adequado para um sistema de monitoramento.
- Escreva seu aplicativo na parte superior da biblioteca tsduck.
Obviamente, do ponto de vista dos custos de mão-de-obra, a opção 1 é a mais simples, especialmente considerando que o próprio tsduck é escrito em uma linguagem de baixo nível (pelos padrões modernos) (C ++)
Um protótipo simples do analisador + agregador no bash mostrou que, em um fluxo de 10 Mbits / s e 50% de perda de pacotes (o pior caso), o processo do bash consumia 3-4 vezes mais CPU que o próprio processo de TSP. Este cenário é inaceitável. Na verdade, um pedaço deste protótipo abaixo
Além do fato de funcionar inaceitavelmente devagar, não há threads normais no bash, os trabalhos do bash são processos independentes e eu tive que registrar o valor dePackets ausentes no efeito colateral uma vez por segundo (quando recebo mensagens de taxa de bits que aparecem a cada segundo). Como resultado, o bash foi deixado sozinho e foi decidido escrever um wrapper (analisador + agregador) no golang. O consumo de CPU de código golang semelhante é 4-5 vezes menor que o próprio processo de colher de chá. Acelerar o wrapper substituindo bash por golang resultou em cerca de 16 vezes e, em geral, o resultado é aceitável (sobrecarga na CPU em 25% no pior caso). O arquivo de origem no golang está aqui .
Lançamento do Wrapper
Para executar o wrapper, foi criado o modelo de serviço mais simples para systemd ( aqui ). Supõe-se que o próprio wrapper seja compilado em um arquivo binário (vá compilar tsduck-stat.go), localizado em / opt / tsduck-stat /. Supõe-se que o golang seja usado com suporte ao relógio monotônico (> = 1.9).
Para criar uma instância do serviço, você precisa executar o comando systemctl enable tsduck-stat@239.0.0.1: 1234 e começar a usar systemctl start tsduck-stat@239.0.0.1: 1234.
Descoberta do Zabbix
Para que o zabbix possa descobrir serviços em execução, foi criado um gerador de lista de grupos (discovery.sh), no formato necessário para a descoberta do Zabbix, presume-se que ele esteja localizado lá - em / opt / tsduck-stat. Para iniciar a descoberta via zabbix-agent, você precisa adicionar o arquivo .conf ao diretório com as configurações do zabbix-agent para adicionar o parâmetro do usuário.
Zabbix Template
O modelo criado (tsduck_stat_template.xml) contém a regra de descoberta automática, protótipos de elementos de dados, gráficos e acionadores.
Uma lista curta (bem, e se alguém decidir usá-la)
- Verifique se o TSP não descarta pacotes nas condições "ideais" (o gerador e o analisador estão conectados diretamente); se houver descargas, consulte a seção 2 ou o texto do artigo sobre este assunto.
- Faça o ajuste do buffer máximo de soquete (net.core.rmem_max = 8388608).
- Compile tsduck-stat.go (vá para compilar tsduck-stat.go).
- Coloque o modelo de serviço em / lib / systemd / system.
- Inicie os serviços usando systemctl, verifique se os contadores começaram a aparecer (grep "" / dev / shm / tsduck-stat / *). Número de serviços pelo número de fluxos multicast. Aqui você pode precisar criar uma rota para o grupo multicast, talvez desativar o rp_filter ou criar uma rota para o IP de origem.
- Execute o discovery.sh, verifique se ele gera json.
- Anexe a configuração do agente zabbix, reinicie o agente zabbix.
- Faça o download do modelo no zabbix, aplique-o no host no qual o zabbix-agent é monitorado e instalado, aguarde cerca de 5 minutos, veja se novos elementos de dados, gráficos e gatilhos apareceram.
Resultado
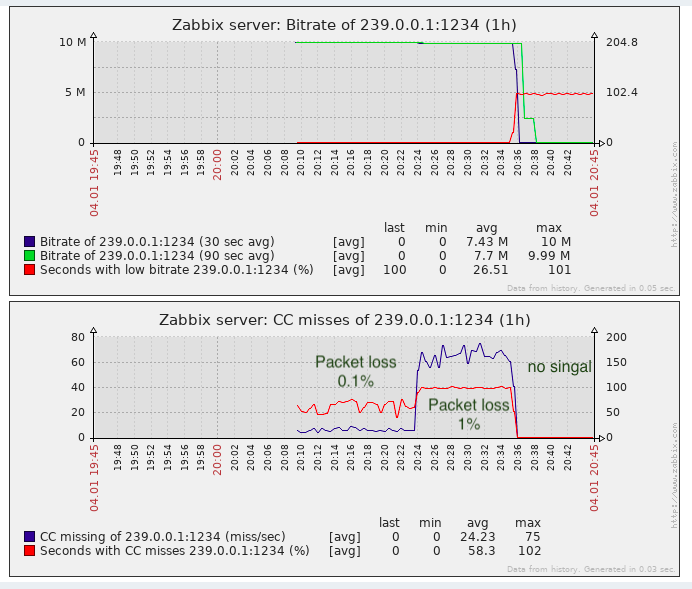
Para a tarefa de detectar a perda de pacotes é quase suficiente, pelo menos é melhor do que a falta de monitoramento.
De fato, podem ocorrer “perdas” de CC ao colar clipes de vídeo (até onde eu sei, inserções são feitas em telecentros locais na Federação Russa, isto é, sem contar o contador de CC), isso deve ser lembrado. Em soluções proprietárias, esse problema é parcialmente contornado pela detecção de rótulos de etiqueta SCTE-35 (se eles forem adicionados pelo gerador de fluxo).
UPD: suporte adicionado para tags SCTE-35 no modelo wrapper e zabbix
Do ponto de vista do monitoramento da qualidade do transporte, não há jitter de monitoramento (IAT) suficiente, porque O equipamento de TV (moduladores ou dispositivos finais) possui requisitos para esse parâmetro e nem sempre é possível inflar o jitbuffer ao infinito. E o jitter pode flutuar quando equipamentos com buffers grandes são usados em trânsito e a QoS não está configurada ou não está bem configurada para transmitir esse tráfego em tempo real.