A complexidade da interpretação dos dados sísmicos se deve ao fato de que, para cada tarefa, é necessário procurar uma abordagem individual, pois cada conjunto desses dados é único. O processamento manual requer custos trabalhistas significativos, e o resultado geralmente contém erros relacionados ao fator humano. O uso de redes neurais para interpretação pode reduzir significativamente o trabalho manual, mas a singularidade dos dados impõe restrições à automação deste trabalho.
Este artigo descreve um experimento para analisar a aplicabilidade de redes neurais para automatizar a alocação de camadas geológicas em imagens 2D usando dados totalmente rotulados do Mar do Norte como exemplo.
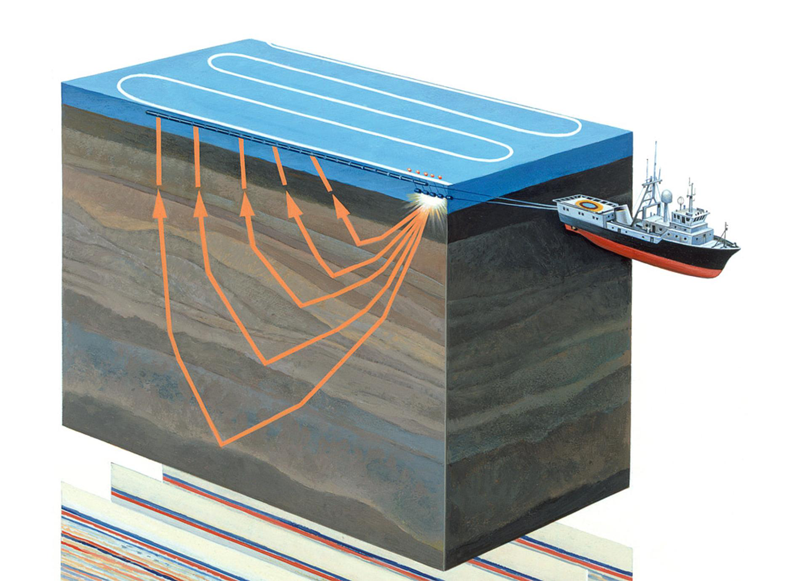
Figura 1. Levantamentos sísmicos aquatórios (
fonte )
Um pouco sobre a área de assunto
A exploração sísmica é um método geofísico para o estudo de objetos geológicos usando vibrações elásticas - ondas sísmicas. Este método baseia-se no fato de que a velocidade de propagação das ondas sísmicas depende das propriedades do ambiente geológico em que elas se propagam (composição rochosa, porosidade, fratura, saturação da umidade etc.). Passando por camadas geológicas com propriedades diferentes, as ondas sísmicas são refletidas objetos diferentes e retornados ao receptor (veja a Figura 1). Sua natureza é registrada e, após o processamento, é possível formar uma imagem bidimensional - uma seção sísmica ou um conjunto de dados tridimensionais - um cubo sísmico.
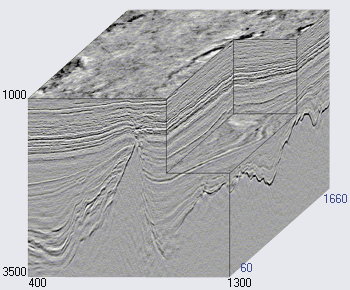
Figura 2. Um exemplo de um cubo sísmico (
origem )
O eixo horizontal do cubo sísmico está localizado ao longo da superfície da Terra e a vertical representa a profundidade ou o tempo (veja a Figura 2). Em alguns casos, o cubo é dividido em seções verticais ao longo do eixo dos geofones (as chamadas linhas internas, linhas internas) ou transversalmente (linhas transversais, linhas transversais, linhas x). Cada cubo vertical (e fatia) é um traço sísmico separado.
Assim, linhas e linhas cruzadas consistem nas mesmas trilhas sísmicas, apenas em uma ordem diferente. As trilhas sísmicas adjacentes são muito semelhantes umas às outras. Uma mudança mais dramática ocorre nos pontos de falha, mas ainda haverá semelhanças. Isso significa que as fatias vizinhas são muito semelhantes umas às outras.
Todo esse conhecimento nos será útil ao planejar experimentos.
A tarefa de interpretação e o papel das redes neurais em sua solução
Os dados obtidos são processados manualmente por intérpretes que identificam diretamente no cubo ou em cada fatia suas camadas geológicas individuais de rochas e seus limites (horizontes, horizontes), depósitos de sal, falhas e outras características da estrutura geológica da área estudada. O intérprete, trabalhando com um cubo ou fatia, inicia seu trabalho com uma seleção manual cuidadosa de camadas e horizontes geológicos. Cada horizonte deve ser despertado manualmente (da coleção “picking”) em inglês, apontando o cursor e clicando no mouse.
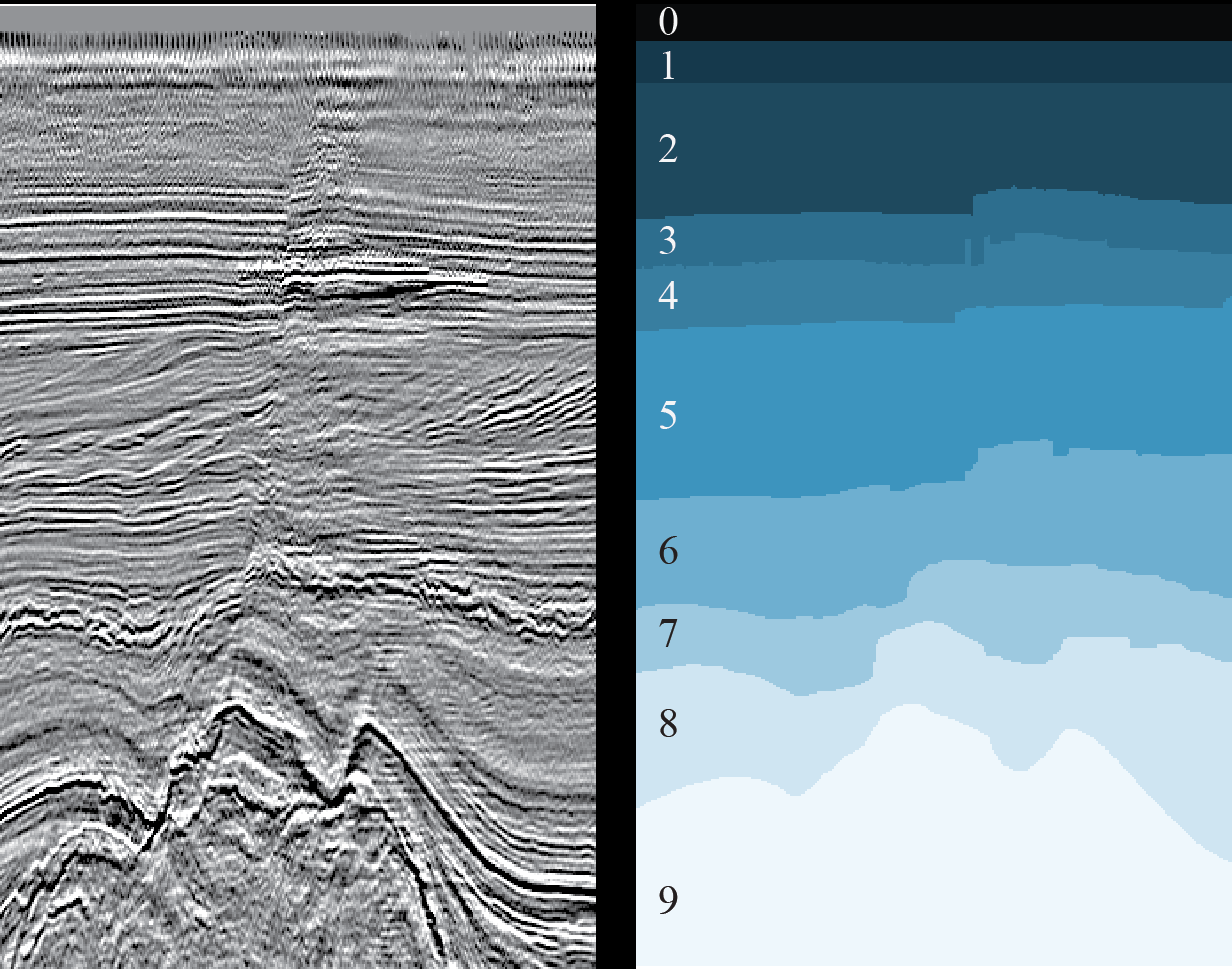
Figura 3. Um exemplo de uma fatia 2D (esquerda) e o resultado da marcação das camadas geológicas correspondentes (direita) (
origem )
O principal problema está relacionado ao crescente volume de dados sísmicos obtidos a cada ano em condições geológicas cada vez mais complexas (por exemplo, seções subaquáticas com grandes profundidades do mar) e à ambiguidade de interpretação desses dados. Além disso, em condições de prazos apertados e / ou grandes volumes, o intérprete inevitavelmente comete erros, por exemplo, perde várias características da seção geológica.
Esse problema pode ser parcialmente resolvido com a ajuda de redes neurais, reduzindo significativamente o trabalho manual, agilizando o processo de interpretação e reduzindo o número de erros. Para a operação da rede neural, é necessário um certo número de seções rotuladas prontas (seções do cubo) e, como resultado, será obtida uma marcação completa de todas as seções (ou todo o cubo), o que idealmente exigirá apenas um refinamento menor por uma pessoa para ajustar determinadas seções dos horizontes ou re-marcar pequenas áreas que a rede não pôde reconhecer corretamente.
Existem muitas soluções para os problemas de interpretação usando redes neurais, aqui estão apenas alguns exemplos:
um ,
dois ,
três . A dificuldade reside no fato de que cada conjunto de dados é único - devido às peculiaridades das rochas geológicas da região estudada, devido a vários meios e métodos técnicos de exploração sísmica, devido aos vários métodos usados para transformar dados brutos em dados prontos. Mesmo devido a ruídos externos (por exemplo, um cachorro latindo e outros sons altos), que nem sempre são possíveis de serem removidos completamente. Portanto, cada tarefa deve ser resolvida individualmente.
Mas, apesar disso, numerosos trabalhos tornam possível procurar abordagens gerais separadas para resolver vários problemas de interpretação.
Na
MaritimeAI (um projeto desenvolvido a partir da
comunidade ODS de Aprendizado de Máquina para Bens Sociais,
um artigo sobre nós ) para cada zona de nosso campo de interesse (pesquisa marítima), estudamos trabalhos já publicados e realizamos nossos próprios experimentos, permitindo esclarecer os limites e características da aplicação de certas soluções e, às vezes, encontre suas próprias abordagens.
Os resultados de um experimento que descrevemos neste artigo.
Objetivos de pesquisa de negócios
Basta que um especialista em ciência de dados dê uma olhada na Figura 3 para dar um suspiro de alívio - uma tarefa comum de segmentação de imagem semântica, para a qual muitas arquiteturas de redes neurais e métodos de ensino foram inventados. Você só precisa escolher os corretos e treinar a rede.
Mas não é tão simples.
Para obter um bom resultado com a ajuda de uma rede neural, você precisa, tanto quanto possível, de dados já marcados nos quais ela aprenderá. Mas nossa tarefa é precisamente reduzir a quantidade de trabalho manual. E raramente é possível usar dados marcados de outras regiões devido às fortes diferenças na estrutura geológica.
Traduzimos o que foi dito acima para o idioma dos negócios.
Para que o uso de redes neurais seja economicamente justificado, é necessário minimizar a quantidade de interpretação manual primária e refinamentos dos resultados obtidos. Porém, reduzir os dados para o treinamento da rede afetará negativamente a qualidade de seu resultado. Assim, uma rede neural pode acelerar e facilitar o trabalho dos intérpretes e melhorar a qualidade das imagens marcadas? Ou apenas complicar o processo usual?
O objetivo deste estudo é uma tentativa de determinar o volume mínimo suficiente de dados de cubos sísmicos marcados para uma rede neural e avaliar os resultados obtidos. Tentamos encontrar respostas para as seguintes perguntas, que devem ajudar os "proprietários" dos resultados da pesquisa sísmica a decidir sobre a interpretação manual ou parcialmente automatizada:
- Quantos dados os especialistas precisam marcar para treinar uma rede neural? E que dados devem ser escolhidos para isso?
- O que acontece com essa saída? O refinamento manual das previsões de redes neurais será necessário? Em caso afirmativo, quão complexo e volumoso?
Descrição geral do experimento e os dados utilizados
Para o experimento, selecionamos um dos problemas de interpretação, a tarefa de isolar camadas geológicas em seções 2D de um cubo sísmico (veja a Figura 3). Já tentamos resolver esse problema (veja
aqui ) e, de acordo com os autores, obtivemos um bom resultado para 1% das fatias selecionadas aleatoriamente. Dado o volume do cubo, são 16 imagens. No entanto, o artigo não fornece métricas para comparação e não há descrição da metodologia de treinamento (função de perda, otimizador, esquema para alterar a velocidade de aprendizado etc.), o que torna o experimento improdutível.
Além disso, em nossa opinião, os resultados apresentados são insuficientes para obter respostas completas às questões colocadas. Esse valor é ideal em 1%? Ou talvez para outra amostra de fatias seja diferente? Posso selecionar menos dados? Vale a pena levar mais? Como o resultado mudará? Etc.
Para o experimento, pegamos o mesmo conjunto de dados completamente rotulados do setor holandês do Mar do Norte. Os dados sísmicos de origem estão disponíveis no site do Open Seismic Repository:
Project Netherlands Offshore F3 Block . Uma breve descrição pode ser encontrada em
Silva et al. "Conjunto de dados da Holanda: um novo conjunto de dados público para aprendizado de máquina na interpretação sísmica .
"Como no nosso caso, estamos falando de fatias 2D, não usamos o cubo 3D original, mas a “fatia” já feita, disponível aqui:
Conjunto de dados de interpretação F3 da Holanda .
Durante o experimento, resolvemos as seguintes tarefas:
- Analisamos os dados de origem e selecionamos as fatias, que têm a qualidade mais próxima da marcação manual.
- Registramos a arquitetura da rede neural, a metodologia e os parâmetros do treinamento e o princípio de selecionar fatias para treinamento e validação.
- Treinamos 20 redes neurais idênticas em diferentes volumes de dados do mesmo tipo de fatias para comparar os resultados.
- Treinamos outras 20 redes neurais em uma quantidade diferente de dados de diferentes tipos de seções para comparar os resultados.
- Estimada a quantidade de refinamento manual necessário dos resultados da previsão.
Os resultados do experimento na forma de métricas estimadas e previstas pelas redes de máscaras de fatia são apresentados abaixo.
Tarefa 1. Seleção de dados
Assim, como dados iniciais, usamos linhas e linhas cruzadas prontas do cubo sísmico do setor holandês do Mar do Norte. Uma análise detalhada mostrou que tudo não está indo bem - há muitas imagens e máscaras com artefatos e até mesmo gravemente distorcidas (veja as Figuras 4 e 5).

Figura 4. Exemplo de máscara com artefatos
Figura 5. Um exemplo de uma máscara distorcida
Com a marcação manual, nada disso será observado. Portanto, simulando o trabalho do intérprete, para treinar a rede, escolhemos apenas máscaras limpas, tendo analisado todas as fatias. Como resultado, 700 linhas cruzadas e 400 linhas foram selecionadas.
Tarefa 2. Corrigindo os parâmetros do experimento
Esta seção é de interesse, antes de tudo, para especialistas em Data Science, portanto, terminologia apropriada será usada.
Como inline e crosslines consistem nos mesmos traços sísmicos, duas hipóteses mutuamente exclusivas podem ser apresentadas:
- O treinamento pode ser realizado apenas em um tipo de fatias (por exemplo, in-line), usando imagens de outro tipo como uma seleção atrasada. Isso dará uma avaliação mais adequada do resultado, porque as fatias restantes do mesmo tipo que foram usadas no treinamento ainda serão semelhantes às do treinamento.
- Para o treinamento, é melhor usar uma mistura de fatias de diferentes tipos, pois isso já é um aumento.
Confira.
Além disso, a semelhança de fatias vizinhas do mesmo tipo e o desejo de obter um resultado reproduzível nos levaram a uma estratégia para selecionar fatias para treinamento e validação, não por um princípio arbitrário, mas de maneira uniforme em todo o cubo, ou seja, para que as fatias estejam o mais afastadas possível e, portanto, cubram a variedade máxima de dados.
Para validação, foram utilizadas 2 fatias, igualmente distribuídas entre imagens adjacentes da amostra de treinamento. Por exemplo, no caso de uma amostra de treinamento de 3 linhas, a amostra de validação consistia em 4 linhas, para 3 linhas e 3 linhas cruzadas, de 8 fatias, respectivamente.
Como resultado, realizamos 2 séries de treinamentos:
- Treinamento em amostras de linhas de 3 a 20 fatias distribuídas uniformemente pelo cubo, com verificação do resultado das previsões de rede nas linhas restantes e em todas as linhas cruzadas. Além disso, foi realizado treinamento nas seções 80 e 160.
- Treinamento em amostras combinadas de linhas e linhas cruzadas de 3 a 10 seções de cada tipo distribuídas uniformemente em um cubo com verificação do resultado das previsões de rede nas imagens restantes. Além disso, o treinamento foi realizado nas seções 40 + 40 e 80 + 80.
Com essa abordagem, é necessário levar em consideração que os tamanhos das amostras de treinamento e validação variam significativamente, o que complica a comparação, mas o volume das imagens restantes não é reduzido tanto que pode ser usado para avaliar adequadamente as alterações no resultado.
Para reduzir o treinamento para a amostra de treinamento, o aumento foi utilizado com tamanho de colheita arbitrário 448x64 e imagem espelhada ao longo do eixo vertical, com probabilidade de 0,5.
Como estamos interessados na dependência da qualidade do resultado apenas no número de fatias na amostra de treinamento, o pré-processamento de imagens pode ser negligenciado. Usamos uma única camada de imagens PNG sem nenhuma alteração.
Pelo mesmo motivo, dentro da estrutura deste experimento, não há necessidade de procurar a melhor arquitetura de rede - o principal é que seja a mesma em todas as etapas. Escolhemos um UNet simples mas bem estabelecido para essas tarefas:

Figura 6. Arquitetura de rede
A função de perda consistia em uma combinação do coeficiente de Jacquard e entropia cruzada binária:
def jaccard_loss(y_true, y_pred): smoothing = 1. intersection = tf.reduce_sum(y_true * y_pred, axis = (1, 2)) union = tf.reduce_sum(y_true + y_pred, axis = (1, 2)) jaccard = (intersection + smoothing) / (union - intersection + smoothing) return 1. - tf.reduce_mean(jaccard) def loss(y_true, y_pred): return 0.75 * jaccard_loss(y_true, y_pred) + 0.25 * keras.losses.binary_crossentropy(y_true, y_pred)
Outras opções de aprendizado:
keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True) keras.callbacks.EarlyStopping(monitor = 'val_loss', patience = 10), keras.callbacks.ReduceLROnPlateau(monitor = 'val_loss', patience = 5)
Para reduzir a influência da aleatoriedade da escolha dos pesos iniciais nos resultados, a rede foi treinada em 3 linhas por 1 era. Todos os outros treinamentos começaram com esses pesos recebidos.
Cada rede foi treinada na GeForce GTX 1060 6Gb por 30 a 60 épocas. O treinamento de cada época levou de 10 a 30 segundos, dependendo do tamanho da amostra.
Tarefa 3. Treinamento em um tipo de fatias (linhas)
A primeira série consistiu em 18 treinamentos de rede independentes em 3-20 linhas. E, embora estejamos interessados apenas em estimar o coeficiente de Jacquard em fatias não utilizadas no treinamento e na validação, é interessante considerar todos os gráficos.
Lembre-se de que os resultados da interpretação para cada fatia são 10 classes (camadas geológicas), que nas figuras são marcadas com números de 0 a 9.

Figura 7. Coeficiente de jacquard para o conjunto de treinamento

Figura 8. Coeficiente de jacquard para amostra de validação
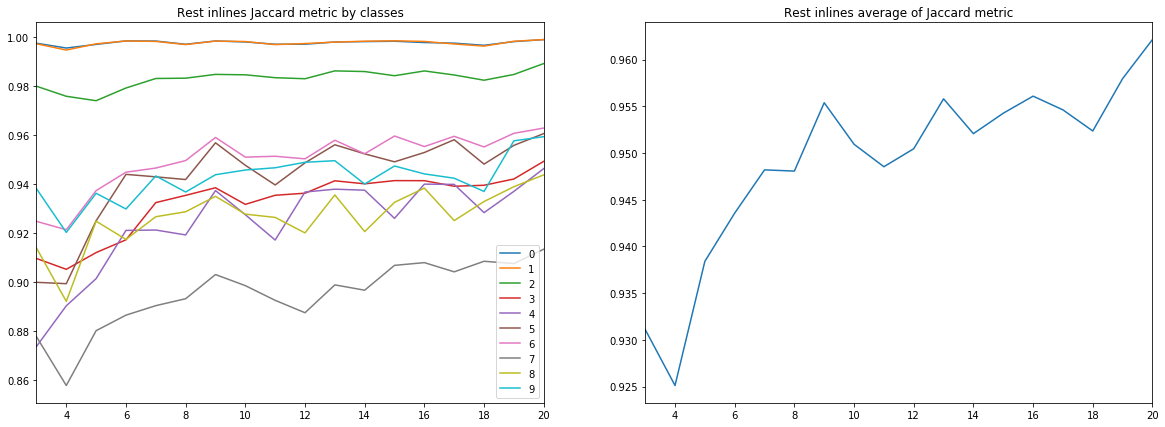
Figura 9. Coeficiente de Jacquard para as demais linhas
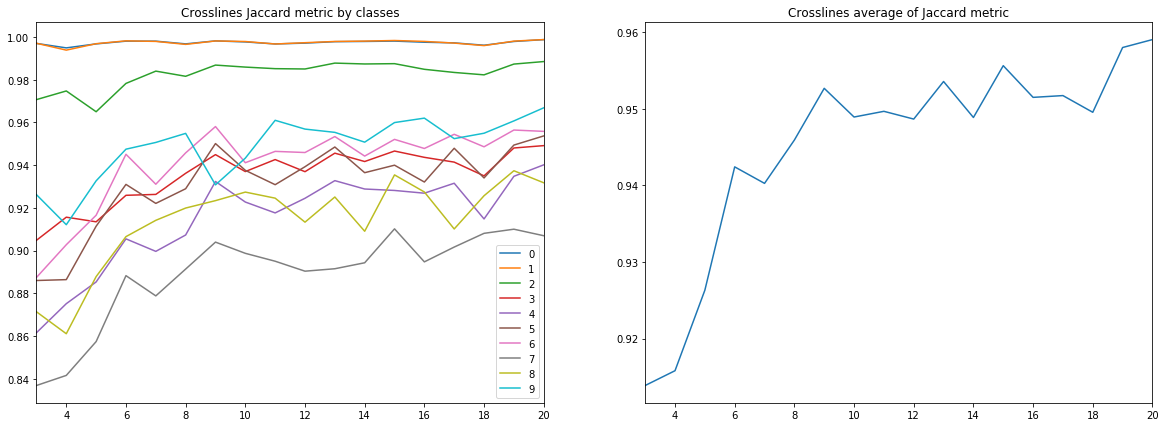
Figura 10. Coeficiente de jacquard para linhas cruzadas
Várias conclusões podem ser tiradas dos diagramas acima.
Em primeiro lugar, a qualidade da previsão, medida pelo coeficiente Jacquard, já em 9 linhas, atinge um valor muito alto, após o qual continua a crescer, mas não de forma tão intensa. I.e. a hipótese da suficiência de um pequeno número de imagens rotuladas para o treinamento de uma rede neural é confirmada.
Em segundo lugar, foi obtido um resultado muito alto para as linhas cruzadas, apesar de apenas linhas serem usadas para treinamento e validação - a hipótese da suficiência de apenas um tipo de fatias também é confirmada. No entanto, para a conclusão final, você precisa comparar os resultados com o treinamento em uma mistura de linhas e linhas cruzadas.
Em terceiro lugar, métricas para diferentes camadas, ou seja, A qualidade do seu reconhecimento é muito diferente. Isso leva à idéia de escolher uma estratégia de aprendizado diferente, por exemplo, usando pesos ou redes adicionais para turmas fracas, ou um esquema completo de “um contra todos”.
E, finalmente, deve-se notar que o coeficiente de Jacquard não pode fornecer uma descrição completa da qualidade do resultado. Para avaliar as previsões de rede nesse caso, é melhor examinar as próprias máscaras para avaliar sua adequação à revisão pelo intérprete.
As figuras a seguir mostram a marcação por uma rede treinada em 10 linhas. A segunda coluna, marcada como “máscara GT” (máscara Ground Truth), representa a interpretação do alvo, a terceira é a previsão da rede neural.


Figura 11. Exemplos de previsões de rede para linhas inline
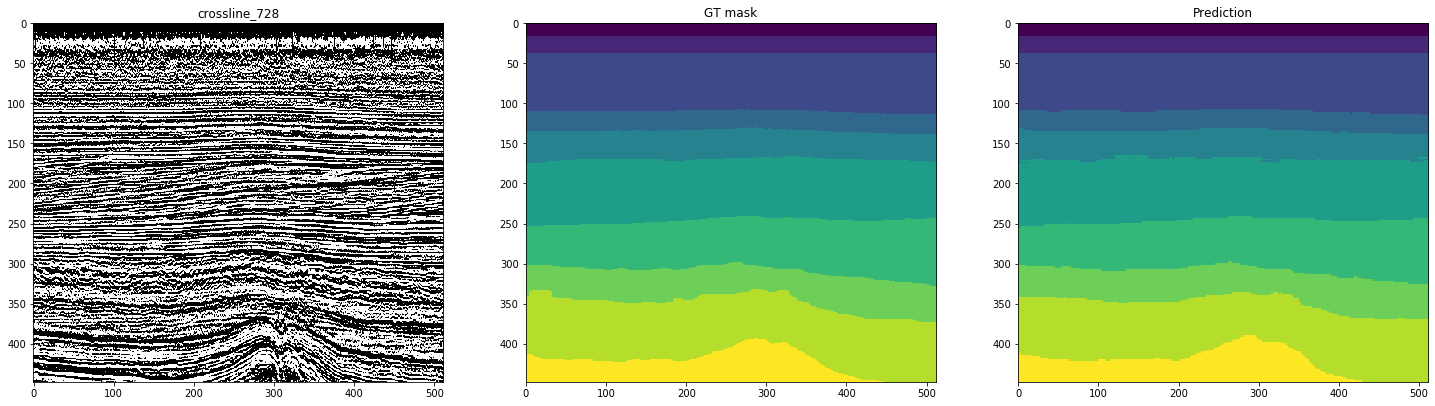

Figura 12. Exemplos de previsões de rede para linhas cruzadas
Pode-se ver pelas figuras que, junto com máscaras bastante limpas, é difícil reconhecer casos complexos na rede, mesmo nas próprias linhas. Assim, apesar da métrica alta o suficiente para 10 fatias, parte dos resultados exigirá refinamento significativo.
Os tamanhos de amostra considerados por nós flutuam em torno de 1% do volume total de dados - e isso já permite marcar parte das fatias restantes muito bem. Devo aumentar o número de seções marcadas inicialmente? Isso dará um aumento comparável na qualidade?
Considere a dinâmica das alterações nos resultados da previsão por redes treinadas nas linhas 5, 10, 15, 20, 80 (5% do volume total do cubo) e 160 (10%) usando as mesmas seções do exemplo.
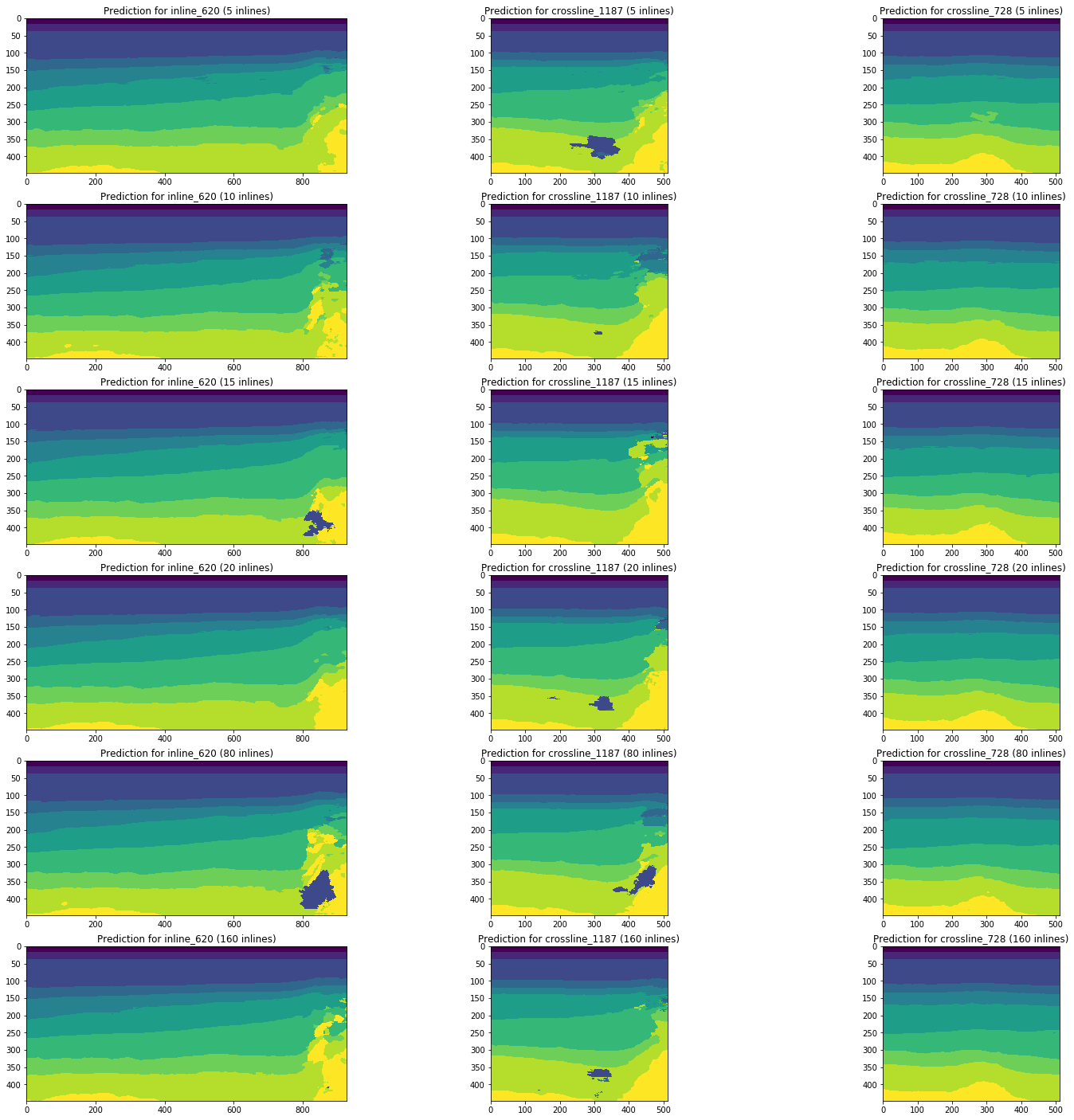
Figura 13. Exemplos de previsões de redes treinadas em diferentes volumes da amostra de treinamento
A Figura 13 mostra que um aumento no volume da amostra de treinamento em 5 ou 10 vezes não leva a uma melhoria significativa. Fatias que já são bem reconhecidas em 10 imagens de treinamento não pioram.
Assim, mesmo uma rede simples sem ajuste e pré-processamento de imagens é capaz de interpretar parte das fatias com uma qualidade suficientemente alta com um pequeno número de imagens marcadas manualmente. Consideraremos a questão da participação de tais interpretações e a complexidade de finalizar fatias mal reconhecidas.
A seleção cuidadosa da arquitetura, os parâmetros de rede e o treinamento, o pré-processamento de imagens podem melhorar esses resultados no mesmo volume de dados marcados. Mas isso já está além do escopo do experimento atual.
Tarefa 4. Treinamento em diferentes tipos de fatias (linhas e linhas cruzadas)
Agora vamos comparar os resultados desta série com as previsões obtidas pelo treinamento em uma mistura de linhas e linhas cruzadas.
Os diagramas abaixo mostram estimativas do coeficiente de Jacquard para diferentes amostras, incluindo, em comparação com os resultados das séries anteriores. Para comparação (veja os diagramas corretos nas figuras), apenas amostras do mesmo volume foram coletadas, ou seja, 10 linhas versus 5 linhas + 5 linhas cruzadas, etc.

Figura 14. Coeficiente de Jacquard para o conjunto de treinamento

Figura 15. Coeficiente de jacquard para amostra de validação

Figura 16. Coeficiente de jacquard para as demais linhas

Figura 17. Coeficiente de jacquard para as demais linhas cruzadas
Os diagramas ilustram claramente que a adição de fatias de um tipo diferente não melhora os resultados. Mesmo no contexto de classes (veja a Figura 18), a influência das linhas cruzadas não é observada para nenhum dos tamanhos de amostra considerados.

Figura 18. Coeficiente de jacquard para diferentes classes (ao longo do eixo X) e diferentes tamanhos e composição da amostra de treinamento
Para concluir a imagem, comparamos os resultados da previsão de rede nas mesmas fatias:
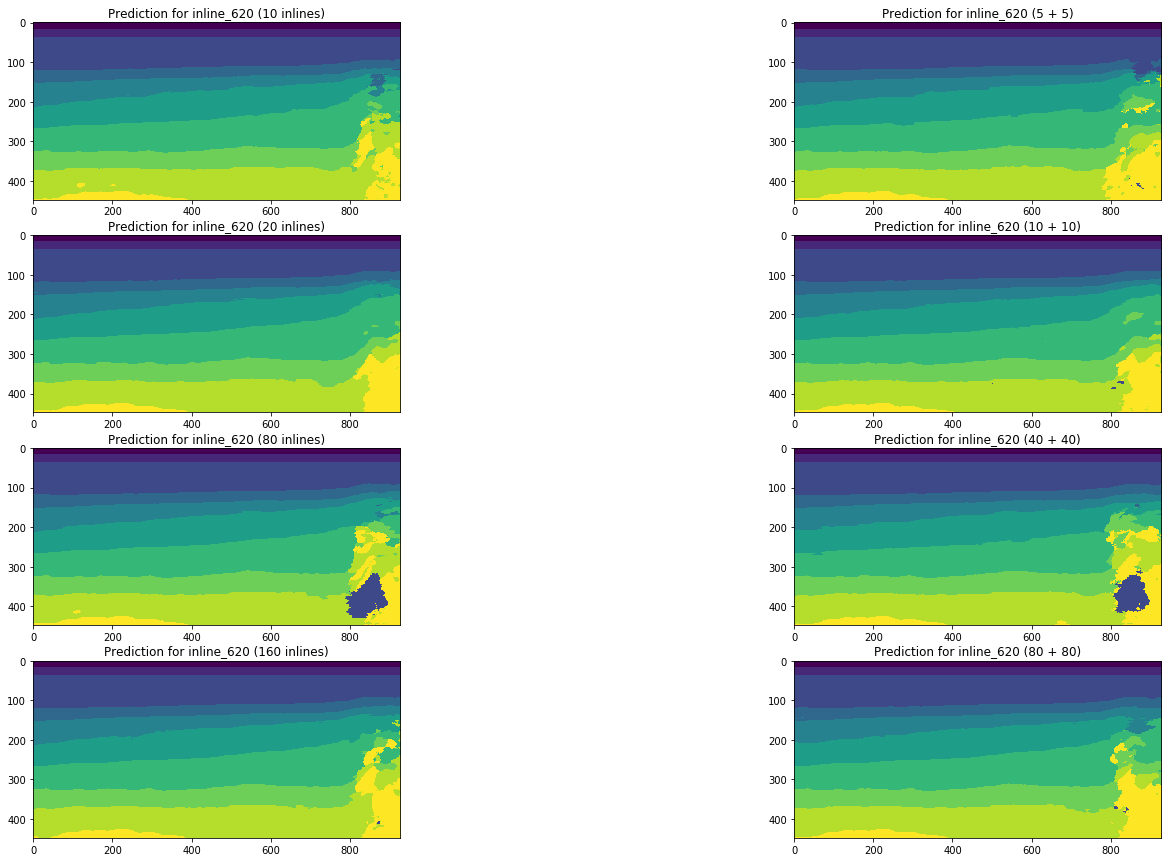
Figura 19. Comparação de previsões de rede para inline
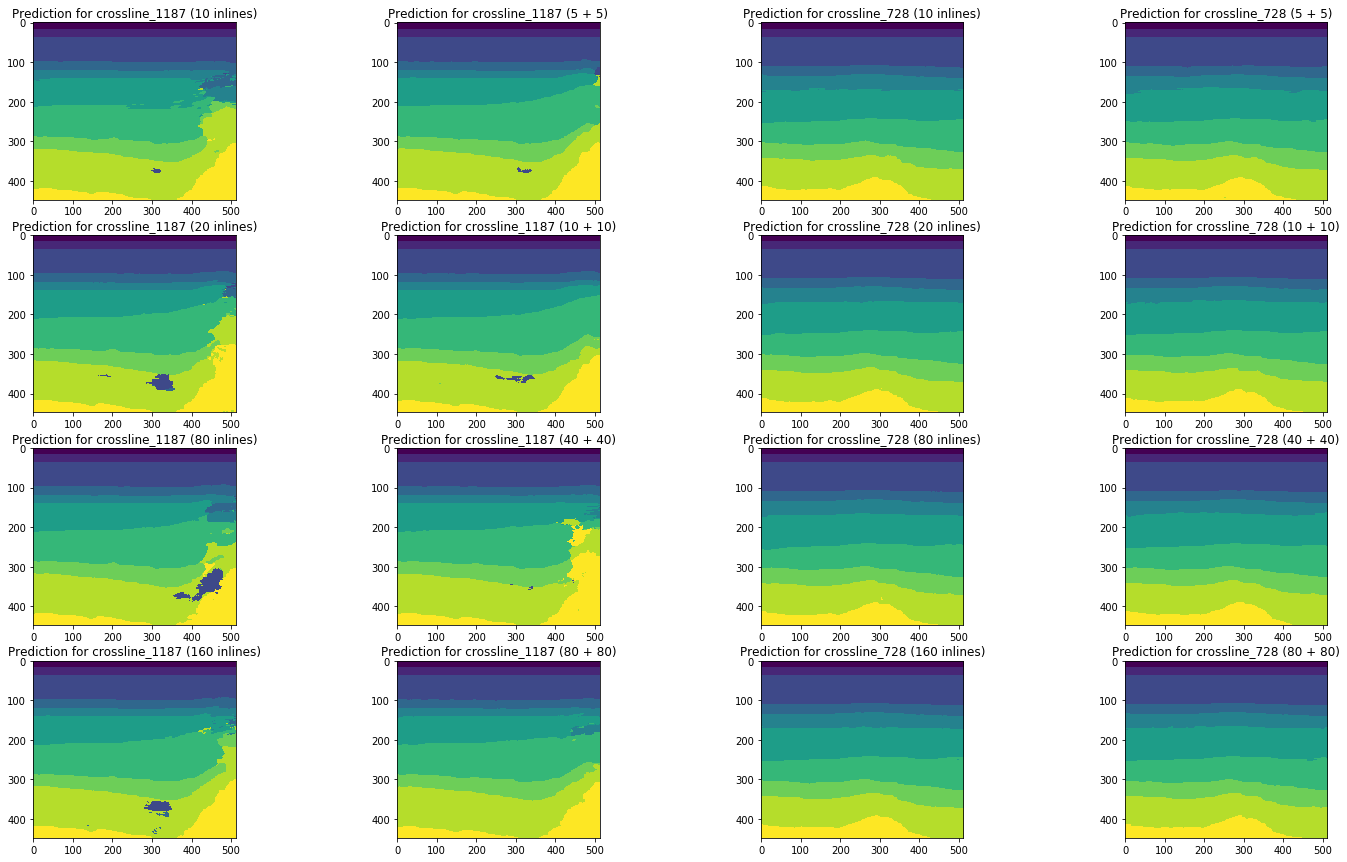
Figura 20. Comparação de previsões de rede para linhas cruzadas
Uma comparação visual confirma a suposição de que adicionar tipos diferentes de fatias ao treinamento não altera fundamentalmente a situação. Algumas melhorias só podem ser observadas para a linha cruzada esquerda, mas são globais? Vamos tentar responder mais a essa pergunta.
Tarefa 5. Avaliação do volume de refinamento manual
Para uma conclusão final sobre os resultados, é necessário estimar a quantidade de refinamento manual das previsões de rede obtidas. Para isso, determinamos o número de componentes conectados (ou seja, pontos sólidos da mesma cor) em cada previsão obtida. Se esse valor for 10, as camadas serão selecionadas corretamente e estamos falando de um máximo de correção menor do horizonte. Se não houver muito mais, você só precisará "limpar" as pequenas áreas da imagem. Se houver substancialmente mais deles, tudo está ruim e pode até precisar de um re-layout completo.
Para o teste, selecionamos 110 linhas e 360 linhas que não foram usadas no treinamento de nenhuma das redes consideradas.
Tabela 1. Estatísticas calculadas para ambos os tipos de fatias
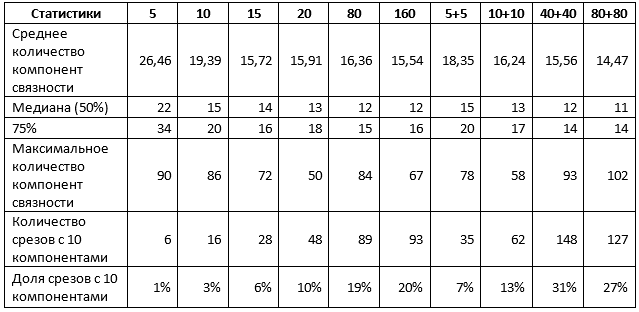
A tabela 1 confirma alguns dos resultados anteriores. Em particular, ao usar fatias de 1% para treinamento, não há diferença, use um tipo de fatias ou ambas, e o resultado pode ser caracterizado da seguinte maneira:
- cerca de 10% das previsões estão próximas do ideal, ou seja, não requerem mais do que ajustes em seções individuais dos horizontes;
- 50% das previsões não contêm mais de 15 pontos, ou seja, não mais que 5 extras;
- 75% das previsões não contêm mais de 20 pontos, ou seja, não mais que 10 extras;
- os 25% restantes das previsões exigem refinamentos mais substanciais, incluindo, possivelmente, uma reformulação completa de fatias individuais.
Um aumento no tamanho da amostra de até 5% altera a situação. Em particular, as redes treinadas em uma mistura de seções mostram indicadores significativamente mais altos, embora o valor máximo dos componentes também aumente, o que indica a aparência de interpretações separadas de qualidade muito ruim. No entanto, se você aumentar a amostra em 5 vezes e usar uma mistura de fatias:
- cerca de 30% das previsões estão próximas do ideal, ou seja, não requerem mais do que ajustes em seções individuais dos horizontes;
- 50% das previsões não contêm mais de 12 pontos, ou seja, não mais que 2 extras;
- 75% das previsões não contêm mais de 14 pontos, ou seja, não mais que 4 extras;
- os 25% restantes das previsões exigem refinamentos mais substanciais, incluindo, possivelmente, uma reformulação completa de fatias individuais.
Um aumento adicional no tamanho da amostra não leva a melhores resultados.
Em geral, para o cubo de dados que examinamos, podemos tirar conclusões sobre a suficiência de 1 a 5% do volume total de dados para obter um bom resultado de uma rede neural.
De acordo com esses dados, em conjunto com as métricas e ilustrações acima, já é possível tirar conclusões sobre a conveniência de usar redes neurais para ajudar intérpretes e sobre os resultados com os quais os especialistas lidarão.
Conclusões
Portanto, agora podemos responder às perguntas colocadas no início do artigo, usando os resultados obtidos no exemplo de um cubo sísmico do Mar do Norte:
Quantos dados os especialistas precisam marcar para treinar uma rede neural? E quais dados devo escolher?Para obter uma boa previsão da rede, basta pré-marcar de 1 a 5% do número total de fatias. Um aumento adicional no volume não leva a uma melhoria no resultado, comparável ao aumento no número de dados marcados anteriormente. Para obter uma melhor marcação em um volume tão pequeno usando uma rede neural, é necessário tentar outras abordagens, por exemplo, ajustar a arquitetura e estratégias de aprendizado, pré-processamento de imagem, etc.
Para marcação preliminar, vale a pena escolher fatias de ambos os tipos - linhas e linhas cruzadas.
O que acontece com essa saída? O refinamento manual das previsões de redes neurais será necessário? Em caso afirmativo, quão complexo e volumoso?
Como resultado, uma parte significativa das imagens rotuladas por uma rede neural não exigirá o refinamento mais significativo, consistindo na correção de zonas individuais pouco reconhecidas. Entre eles, haverá interpretações que não exigirão correções. E apenas para imagens únicas, pode ser necessário um novo layout manual.
Obviamente, ao otimizar o algoritmo de aprendizagem e os parâmetros de rede, seus recursos preditivos podem ser aprimorados. Em nosso experimento, a solução de tais problemas não foi incluída.
Além disso, os resultados de um estudo em um cubo sísmico não devem ser generalizados sem pensar - precisamente devido à singularidade de cada conjunto de dados. Mas esses resultados são a confirmação de um experimento realizado por outros autores e a base para comparação com nossos estudos subsequentes, sobre os quais também escreveremos em breve.
Agradecimentos
E, no final, gostaria de agradecer aos meus colegas da
MaritimeAI (especialmente Andrey Kokhan) e da
ODS pelos valiosos comentários e ajuda!
Lista de fontes utilizadas:
- Bas Peters, Eldad Haber, Justin Granek. Redes neurais para geofísicos e sua aplicação na interpretação de dados sísmicos
- Hao Wu, Bo Zhang. Uma profunda rede neural convolucional codificador-decodificador para auxiliar o rastreamento de horizonte sísmico
- Thilo Wrona, Indranil Pan, Robert L. Gawthorpe e Haakon Fossen. Análise sísmica de fácies usando aprendizado de máquina
- Reinaldo Mozart Silva, Lais Baroni, Rodrigo S. Ferreira, Daniel Civitarese, Daniela Szwarcman, Emilio Vital Brazil. Conjunto de dados na Holanda: um novo conjunto de dados público para aprendizado de máquina na interpretação sísmica